這篇文章是優化工作站端到端人工智能系列文章的第一篇。有關更多信息,請參見第 2 部分, 工作站端到端 AI : 使用 ONNX 轉換 AI 模型 和第 3 部分, 工作站端到端 AI : ONNX 運行時和優化?.
GPU 的偉大之處在于它提供了巨大的并行性;它允許您同時執行許多任務。在最精細的層面上,這歸結為有數千個微小的處理內核同時運行同一條指令。但這并不是這種并行性停止的地方。還有其他方法可以利用經常被忽視的并行性,特別是在人工智能方面。
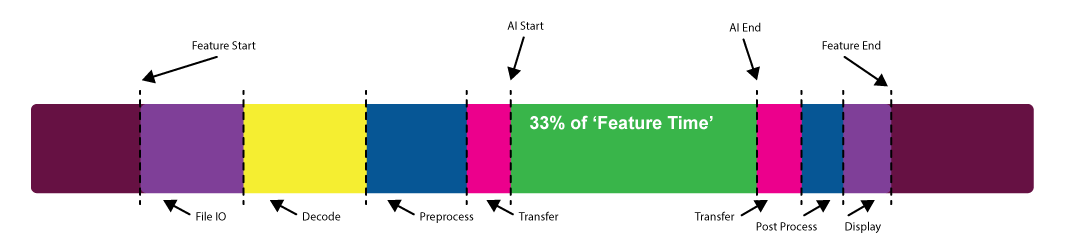
當你考慮人工智能功能的性能時,你到底是什么意思?您是否只是在考慮模型本身運行所需的時間,還是在考慮加載數據、預處理數據、傳輸數據以及寫回磁盤或顯示所需時間?
這個問題可能最好由體驗該功能的用戶來回答。通常會發現,實際的模型執行時間只是整個體驗的一小部分。
這篇文章是本系列文章的第一篇,它將引導您了解幾個特定于 API 的用例,包括:
- ONNX 運行時和 Microsoft WinML
- NVIDIA TensorRT
- NVIDIA cuDNN
- Microsoft DirectML
工作站上的人工智能是一種相對較新的現象。傳統上是服務器和云的東西,但這正在發生變化,尤其是在內容創建領域。因此,現在有許多現有的代碼庫被新的人工智能功能所補充。
在實現 AI 功能時首先要問的問題之一是,如何運行推理?約束條件是什么?您需要支持哪些平臺?
根據您確定的約束條件,您可以選擇基于 DirectML 和 WinML 的方法或基于 CUDA 和 TensorRT 的方法。無論您選擇何種方法,您還應考慮如何將您的功能集成到現有工作流或管道中。
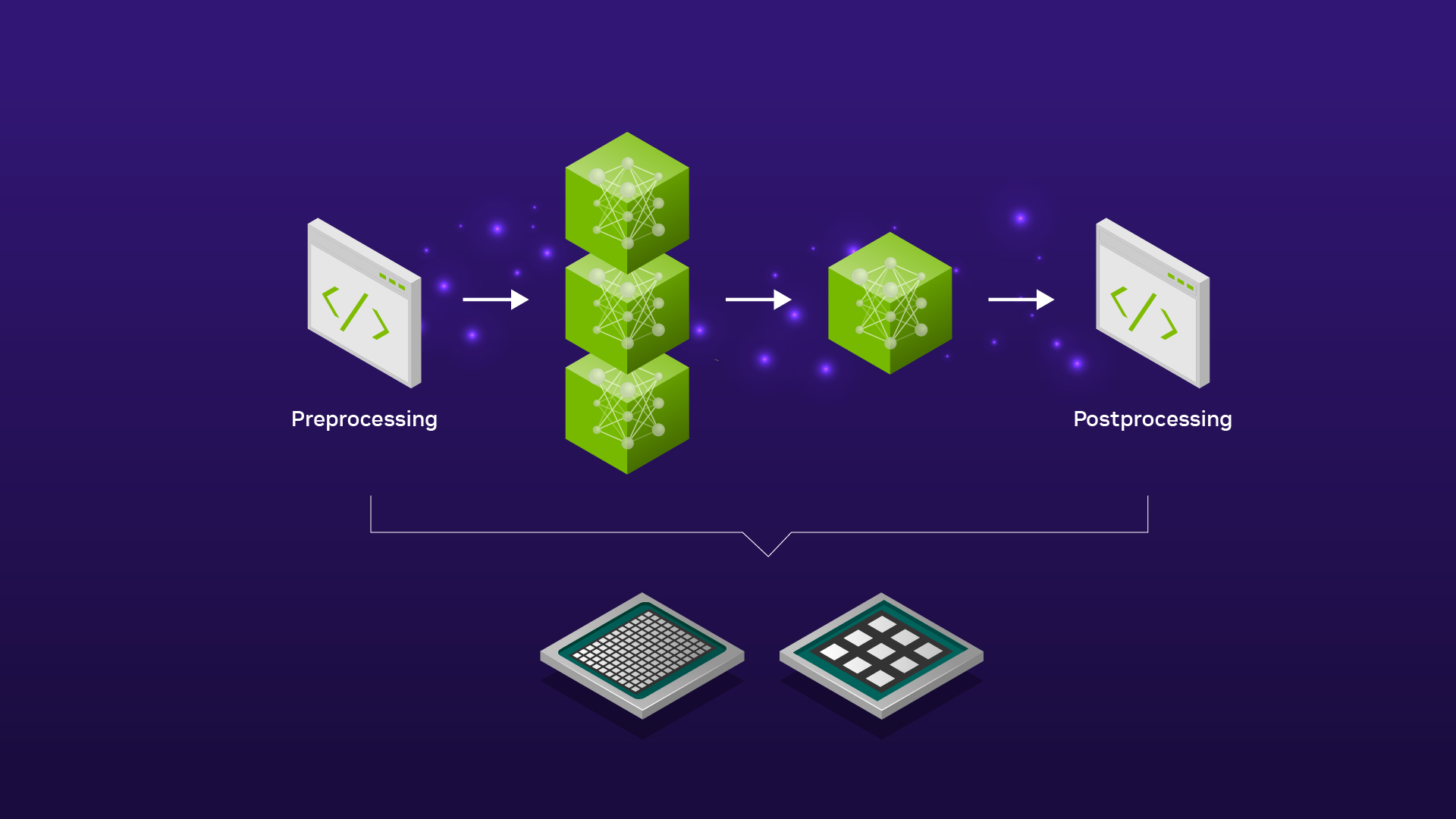
考慮在內容創建空間中生成 AI 的一個相對常見的工作流:去噪功能。要運行此去噪器,必須執行以下步驟:
- 將模型加載到 GPU 存儲器中。
- 使輸入數據可用于模型。
- 通過模型傳遞輸入數據。
- 對輸出數據執行某些操作。
這個列表中有很多歧義,所以我想討論每一步。
將模型加載到 GPU 存儲器中
你什么時候、怎么做?
模型有各種形狀和大小,從幾千字節到幾千字節。如果您的模型作為長時間運行的管道的一部分執行,則可能無法持久地將大型模型保存在內存中。
理想情況下,您將使模型加載盡可能遠離性能路徑,但有時這很難做到。您可能必須在管道運行時加載和卸載模型。
最好的情況是一次加載一個模型,并盡可能多次使用它。在無法做到這一點的情況下,大多數框架都可以相對快速地卸載序列化模型并將其流式傳輸回 GPU 。
使輸入數據可用于模型

這一步是讓事情變得有趣的地方。通常,這是一個有很多低掛的水果來提高你的表現的地方。
最終,模型期望以特定格式使用輸入數據。這幾乎總是意味著特定的縮放和偏移、格式轉換(例如, UINT8 到 FP16 ),以及可能的一些布局轉換。在 NVIDIA 硬件上, Tensor Core 更喜歡 NHWC 布局。
通常,還必須進行其他預處理。可能存在從頻率空間到頻率空間的轉換或從某種壓縮格式解碼。
這是 GPU 可以有效完成的所有工作,因此允許 GPU 來完成這項工作非常重要。允許 CPU 完成這項任務或將工作卸載到第三方庫都是很有誘惑力的。后者是一種非常明智的做法。在任何一種情況下,您都必須確保盡量減少與 GPU 之間的傳輸,并加快操作本身。如果您正在使用第三方 GPU 解決方案進行預處理和后處理,您能否確保數據盡可能長時間保留在 GPU 上?
在許多情況下,可能存在預處理和格式轉換的解決方案,這些解決方案可以由模型本身使用本機運算符執行。在大多數情況下,通過將這些運算符添加到模型的開頭和結尾,可以執行到 FP16 的轉換、縮放和偏移。
無論您如何進行預處理,在某些時候,您當然必須將輸入數據傳輸到 GPU ,以便模型可以使用它。這引發了另一個重要的考慮。
當您的輸入數據很大時,如果可以的話,您必須在平鋪中執行推斷。這意味著要加載一個或多個平鋪的批次,并在加載下一個批次之前運行推斷。
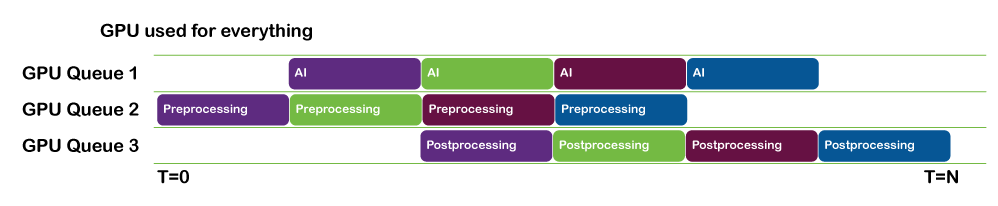
加載數據和運行推斷可以并行完成。您可以對這項工作進行流水線處理,以便在批處理 N 完成推斷時,批處理 N + 1 已完成加載并準備運行。
- 如果您使用的是 NVIDIA CUDA 或 NVIDIA TensorRT ,請使用 CUDA 流來實現這一點。
- 如果您使用的是基于 DML 的推理解決方案,請并行使用 DirectX 隊列以保持事情的進展。
像這樣的平鋪操作是高度并行的,是在 GPU 本身上執行的良好候選。如果難以處理 GPU 內存中的整個圖像,您可以將圖像分割為多個部分,這些部分可以平鋪,而下一個部分將流式傳輸到 GPU 。
通過模型傳遞輸入數據
要在運行推斷本身時獲得模型的最佳性能,請確保以下所有語句均為真:
- 輸入數據在最快的設備本地存儲器中提供
- 您正在利用 NVIDIA 硬件提供的功能,例如 Tensor Core 。
- GPU 是完全飽和的,我的意思是 GPU 被賦予了足夠的工作以使其保持忙碌。
使用正確的內存
大多數 GPU 可以訪問幾個物理堆。一般來說,可編程堆通常是以下之一:
- Host-visible
- 駐留在系統內存中,并通過 PCI 系統上的 PCI 總線讀取
- 您可以寫入此內存,但可能不是 GPU 訪問的最快速度
- Device-local
- 駐留在設備( GPU )內存中
- 內存很快,但不能直接寫入
獲得最快內存訪問的一般工作流程是將數據寫入主機可見內存。然后,發出 GPU 命令,將數據從主機復制到設備本地存儲器
如果您使用的是基于 CUDA 的平臺,如 TensorRT 或 cuDNN ,那么這相對容易管理,因為驅動程序會為您執行此操作。然而,在主機上可以做的一件事就是在主機上使用固定內存。也就是說,在分配主機內存時,請使用hostAlloc而不是malloc。這使得 GPU DMA 能夠直接調度存儲器傳輸,而不必涉及到到 DMA 存儲器池中的單獨 CPU 傳輸,從而導致較低的延遲。
如果您使用的是基于 DirectML 的方法,則必須自己管理向快速內存的傳輸。這是值得的,因為它可以讓您完全控制數據傳輸的確切時間,以及與其他工作并行執行傳輸的機會。
使 GPU 飽和
在進行任何 GPU 相關工作時,一個通常被忽略的瓶頸是沒有給 GPU 足夠的工作。當這種情況發生時,您可能會發現沒有足夠的工作來保持 GPU 上的所有流式多處理器( SM )忙碌。
在這種情況下,增加空間維度或批量大小等策略可以顯著幫助。您可能會發現,批量大小為 8 的運行速度與批量大小為 1 的運行速度相同。
正如模型的大小和復雜性可能不同一樣, GPU 也是如此。一種 GPU 的最佳批量大小對另一種可能不是最佳的。使用 NVIDIA NSight 系統進行評測可以幫助您識別給定系統上利用率低的情況,并幫助您相應地設計推理策略。
保持 GPU 忙碌的其他策略是使用多個 CUDA 流或 DirectX 命令隊列并行執行其他計算甚至 AI 工作。
每種情況都是獨一無二的,但 CUDA 和 DirectML 以及 DirectX 都為您提供了使 GPU 在給定問題上盡可能忙碌的方法。
對輸出數據執行某些操作
當推斷完成并且有了輸出時,可以應用與輸入數據類似的原則。也就是說,您可以以與輸入數據類似的方式對數據進行后處理,方法是向圖形中添加節點或使用自定義計算步驟。
如果必須將數據讀回主機內存,也可以與下一個推理批并行執行。如果您的數據必須直接顯示,則應通過使用相關平臺的適當互操作功能(例如, CUDA 到 OpenGL ),避免任何不必要的往返 CPU 。
結論
請記住,每個用例都是不同的,對于一個特定用例來說很好的方法可能不適用于另一個用例。
要閱讀本系列的下一篇文章,請參閱 End-to-End AI for Workstation: Transitioning AI Models with ONNX 和 End-to-End AI for Workstation: ONNX Runtime and Optimization .
注冊 了解有關使用 NVIDIA 技術加速您的創意應用程序的更多信息?。
?