
這篇文章是優化工作站端到端人工智能系列文章的第三篇。有關更多信息,請參見第 1 部分, 工作站端到端 AI :優化簡介?和第 2 部分, 工作站端到端 AI :使用 ONNX 轉換 AI 模型?.
當您的模型轉換為 ONNX 格式時,有幾種方法可以部署它,每種方法都有優缺點。
一種方法是使用 ONNX Runtime 。 ONNX 運行時充當后端,從中間表示( ONNX )讀取模型,處理推理會話,并在能夠調用硬件特定庫的執行提供程序上調度執行。有關詳細信息,請參見 Execution Providers 。
在這篇文章中,我將討論如何在高級別上使用 ONNX 運行時。我還深入探討了如何優化模型。
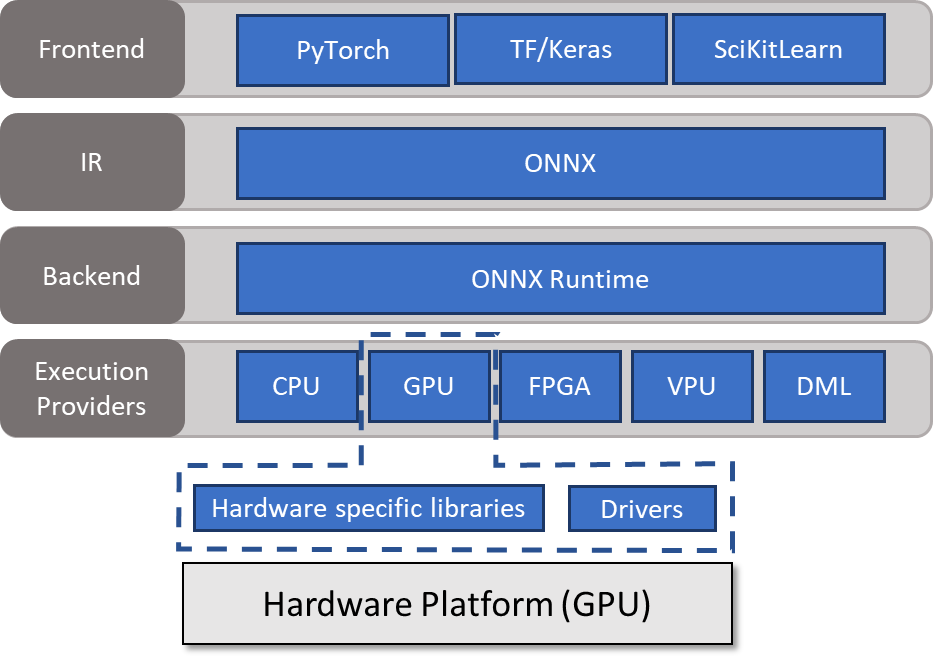
使用 ONNX 運行時運行模型
ONNX Runtime 與大多數編程語言兼容。與另一篇文章一樣,本文使用 Python 是為了簡潔和易讀。這些例子只是為了介紹關鍵思想。有關所有流行操作系統、編程語言和執行提供程序的庫的更多信息,請參閱 ONNX Runtime 。
要使用 ONNX Runtime 推斷模型,必須創建InferenceSession類的對象。此對象負責分配緩沖區并執行實際的推理。將加載的模型和要使用的執行提供程序列表傳遞給構造函數。在本例中,我選擇了 CUDA 執行提供程序。
import onnxruntime as rt
# Create a session with CUDA and CPU ep
session = rt.InferenceSession(model,
providers=['CUDAExecutionProvider',
'CPUExecutionProvider']
)您可以定義會話和提供程序選項。 ONNX 運行時的全局行為可以使用日志記錄、分析、內存策略和圖形參數的會話選項進行修改。有關所有可用標志的更多信息,請參見 SessionOptions 。
以下代碼示例將日志記錄級別設置為 verbose :
# Session Options
import onnxruntime as rt
options = rt.SessionOptions()
options.log_severity_level = 0
# Create a session with CUDA and CPU ep
session = rt.InferenceSession(model,
providers=['CUDAExecutionProvider',
'CPUExecutionProvider'],
sess_options = options
)使用提供程序選項更改已選擇用于推斷的執行提供程序的行為。有關詳細信息,請參見 ONNX Runtime Execution Providers 。
您還可以通過在新創建的會話上執行get_provider_options來獲得可用選項:
provider_options = session.get_provider_options()
print(provider_options)運行模型
構建會話后,必須生成輸入數據,然后才能將其綁定到 ONNX 運行時。然后,您可以在會話上調用run,向其傳遞一個輸出名稱列表以及一個包含輸入名稱作為鍵和 ONNX 運行時綁定作為值的字典。
# Generate data and bind to ONNX Runtime
input_np = np.random.rand((1,3,256,256))
input_ort = rt.OrtValue.ortvalue_from_numpy(input_np)
# Run model
results = session.run(["output"], {"input": input_ort})默認情況下, ONNX Runtime 始終將輸入和輸出放置在 CPU 上。因此,在主機和設備之間不斷復制緩沖區,您應該盡可能避免這種情況。使用和重用設備生成的緩沖區是可行的。
模型優化
為了從推理中獲得最佳性能,我建議您使用硬件專用加速器: Tensor Cores 。
在 NVIDIA RTX 硬件上,從 NVIDIA Volta 架構(計算能力 7.0 +)向前, GPU 包括 Tensor 核心,以加速深度學習所涉及的一些重載操作。
本質上, Tensor 核心支持一種稱為扭曲矩陣乘法累加( WMMA )的操作,為基于 FP16 的( HMMA )和基于整數的乘法累加( IMMA )提供優化路徑。
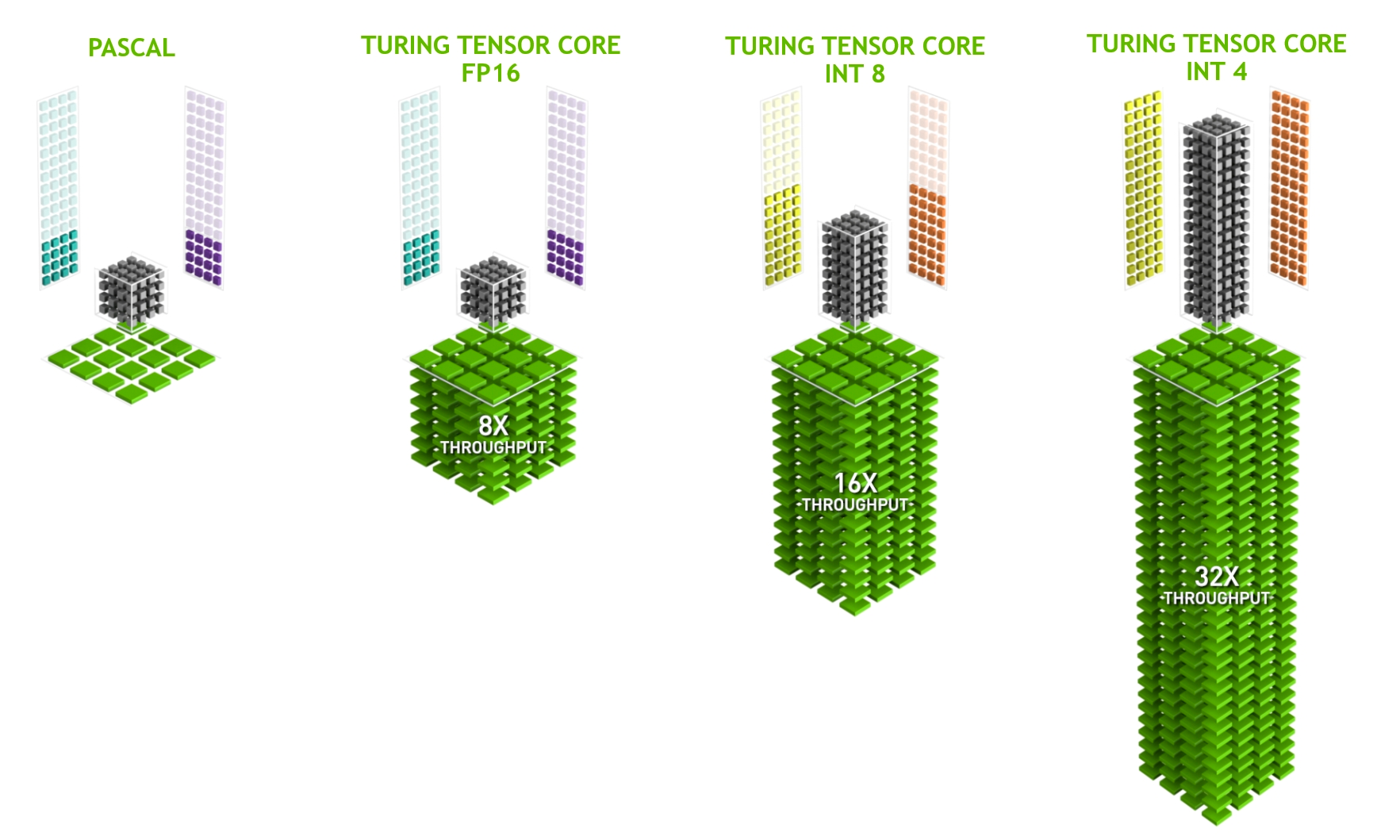
精度轉換
使用 Tensor Core 的第一步是將模型導出到 FP16 或 INT8 的較低精度。在大多數情況下, INT8 提供最佳性能,但它有兩個缺點:
- 您必須重新校準或量化權重。
- 精度可能更差。
第二點取決于您的應用程序。然而,當使用 INT8 輸入和輸出數據(如照片)時,其后果往往可以忽略不計。
另一方面, FP16 不需要重新校準重量。在大多數情況下,其精度與 FP32 相似。要將給定的 ONNX 模型轉換為 FP16 ,請使用 onnx_converter_common 工具箱。
import onnx
from onnxconverter_common.float16 import convert_float_to_float16
model_fp32 = onnx.load("model.onnx")
model_fp16 = convert_float_to_float16(copy.deepcopy(model_fp32))
onnx.save(model_fp16, "model_fp16.onnx")如果原始模型中的權重超過 FP16 的動態范圍,則會出現溢出。使用自動混合精度(amp)導出器可以克服任何不希望的行為。這會將模型的 Ops 逐一轉換為 FP16 ,在每次更改后檢查其準確性,以確保增量在預定義的公差范圍內。否則, Op 保存在 FP32 中。
這種類型的轉換還需要兩件事:
- 一個 輸入饋送字典 ,包含作為鍵的輸入名稱和作為值的數據。重要的是,提供的數據在正確的數據范圍內,盡管最好使用實際的推斷數據。
- A validation function 以比較結果是否在可接受的誤差范圍內。在本例中,我實現了一個簡單的函數,如果兩個數組在公差范圍內按元素相等,則返回 true 。
import onnx
import numpy as np
from onnxconverter_common.auto_mixed_precision import auto_convert_mixed_precision
# Could also use rtol/atol attributes directly instead of this
def validate(res1, res2):
for r1, r2 in zip(res1, res2):
if not np.allclose(r1, r2, rtol=0.01, atol=0.001):
return False
return True
model_fp32 = onnx.load("model.onnx")
feed_dict = {"input": 2*np.random.rand(1, 3, 128, 128).astype(np.float32)-1.0}
model_amp = auto_convert_mixed_precision(model_fp32, feed_dict, validate)
onnx.save(model_amp, "model_amp.onnx")在從 FP32 到 FP16 的轉換過程中,除了動態范圍之外,仍然存在可能的問題。可能會在模型中插入不必要或不需要的強制轉換操作。您必須手動檢查。
體系結構注意事項
數據和權重必須采用正確的布局。 Tensor Core 使用 NHWC 格式的數據。正如我前面提到的, ONNX 只支持 NCHW 格式。然而,這不是問題,因為后端在 Tensor Core 合格操作之前插入轉換內核。
讓后端處理布局可能會導致性能損失。由于并非所有操作都支持 NHWC 格式,因此在整個模型中可能存在多個 NCHW-NHWC 轉換和相反的轉換。它們的運行時間很短,但在重復執行時,弊大于利。嘗試通過分析模型來避免模型中的顯式布局轉換。
所有操作都應使用尺寸倍數為 8 (最佳為 32 )的過濾器,以滿足 Tensor Core 的要求。這涉及到實際的模型體系結構,在設計模型時應記住這一點。
當您使用 NVIDIA TensorRT 時,過濾器會自動填充,以適合 Tensor Core 消費。盡管如此,調整模型架構可能會更好。無論如何,額外的維度都是計算出來的,可能會提供改進特征提取的潛力
作為第三項要求, GEM 運營必須大步向前。這意味著步幅不能超過過濾器大小。
全體的
ONNX 運行時包括幾個圖形優化以提高性能。圖形優化本質上是圖形級別的改變,從簡單的圖形簡化和節點消除到更復雜的節點融合和布局轉換。
在 ONNX 運行時中,它們分為以下級別:
- Basic: 這些優化涵蓋了所有保留語義的修改,如常量折疊、冗余節點消除和有限數量的節點融合。
- Extended: 擴展優化僅在運行 CPU 或 CUDA 執行提供程序時適用。它們包括更復雜的融合。
- Layout optimizations: 這些布局轉換僅適用于在 CPU 上運行。
有關可用融合和適用優化的更多信息,請參見 Graph Optimizations in ONNX Runtime 。
當在 TensorRT 執行提供程序上運行時,這些優化并不相關,因為[ZDK4 使用內置優化器,該優化器使用多種融合和內核調諧器。
聯機或脫機
所有優化都可以在線或離線執行。當以聯機模式啟動推理會話時, ONNX 運行時會在模型推理開始之前運行所有已啟用的圖形優化。
每次會話啟動時應用所有優化可能會增加模型啟動時間,特別是對于復雜模型。在這種情況下,離線模式可能是有益的。圖形優化完成后, ONNX 運行時將最終模型以脫機模式保存到磁盤。使用現有的優化模型并刪除所有優化可以減少每次連續啟動的啟動時間。
總結
本文介紹了使用 ONNX 運行時運行模型、模型優化和體系結構考慮。如果您對這些主題有任何進一步的問題,請聯系 NVIDIA Developer Forums 或加入 NVIDIA Developer Discord 。
要閱讀本系列的第一篇文章,請參見 End-to-End AI for Workstation: An Introduction to Optimization .
注冊 learn more about accelerating your creative application with NVIDIA technologies 。
?





