
這篇文章是優化工作站端到端人工智能系列文章的第二篇。有關更多信息,請參見第 1 部分, 工作站端到端 AI : 優化簡介 和第 3 部分, 工作站端到端 AI : ONNX 運行時和優化?.
在這篇文章中,我討論了如何使用 ONNX 將人工智能模型從研究過渡到生產,同時避免常見錯誤。考慮到 PyTorch 已經成為最流行的機器學習框架,我的所有示例都使用它,但我也提供了 TensorFlow 教程的參考。
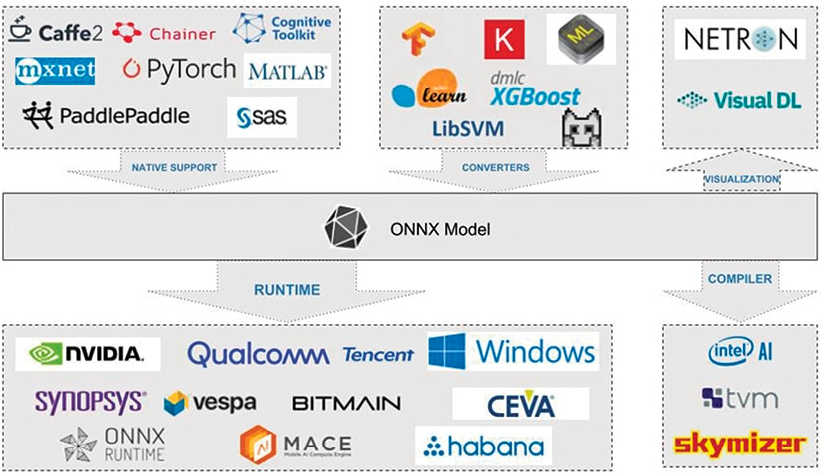
與 ONNX 的互操作性
ONNX (開放式神經網絡交換)是描述深度學習模型的開放標準,旨在促進框架兼容性。
考慮以下場景:您可以在 PyTorch 中訓練神經網絡,然后在將其部署到生產環境之前通過 TensorRT 優化編譯器運行它。這只是許多可互操作的深度學習工具組合中的一種,包括可視化、性能分析器和優化器。
研究人員和 DevOps 不再需要將就一個未優化建模和部署性能的單一工具鏈。
為此, ONNX 定義了一組標準運算符以及基于 Protocol Buffers serialization format 的標準文件格式。該模型被描述為具有邊的有向圖,邊指示各種節點輸入和輸出之間的數據流,以及表示運算符及其參數的節點。
導出模型
我為以下情況定義了一個由兩個Convolution-BatchNorm-ReLu塊組成的簡單模型。
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = torch.nn.Sequential(
torch.nn.Conv2d(3, 16, 3, 2),
torch.nn.BatchNorm2d(16),
torch.nn.ReLU(),
torch.nn.Conv2d(16, 64, 3, 2),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
def forward(self, x):
return self.model(x)您可以使用 PyTorch 內置導出器,通過創建模型實例并調用torch.onnx.export將此模型導出到 ONNX 。還必須為虛擬輸入提供適當的輸入維度和數據類型,以及給定輸入和輸出的符號名稱。
在代碼示例中,我定義輸入和輸出的index 0是動態的,以便在運行時以不同的批大小運行模型。
import torch
model = Model().eval().to(device="cpu")
dummy_input = torch.rand((1, 3, 128, 128), device="cpu")
torch.onnx.export(
model,
dummy_input,
"model.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "N"}, "output": {0: "N"}},
opset_version=13
)在內部, PyTorch 調用torch.jit.trace,它使用給定的參數執行模型,并將執行期間的所有操作記錄為有向圖。
跟蹤展開循環和 if 語句,生成與跟蹤運行相同的靜態圖。沒有捕獲依賴于數據的控制流。這種導出類型適用于許多用例,但要記住這些限制。
如果需要動態行為,可以使用 scripting 。因此,在轉換為 ONNX 之前,必須將模型導出到ScriptModule對象,如下例所示。
import torch
model = Model().eval().to(device="cpu")
dummy_input = torch.rand((1, 3, 128, 128), device="cpu")
scripted_model = torch.jit.script(model)
torch.onnx.export(
scripted_model,
dummy_input,
"model.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "N"}, "output": {0: "N"}},
opset_version=13
)將模型轉換為ScriptModule對象并不總是簡單的,通常需要一些代碼更改。有關詳細信息,請參見 Avoiding Pitfalls 和 TorchScript 。
由于前向調用中沒有數據依賴關系,因此可以將模型轉換為可編寫腳本的模型,而無需對代碼進行任何更改。
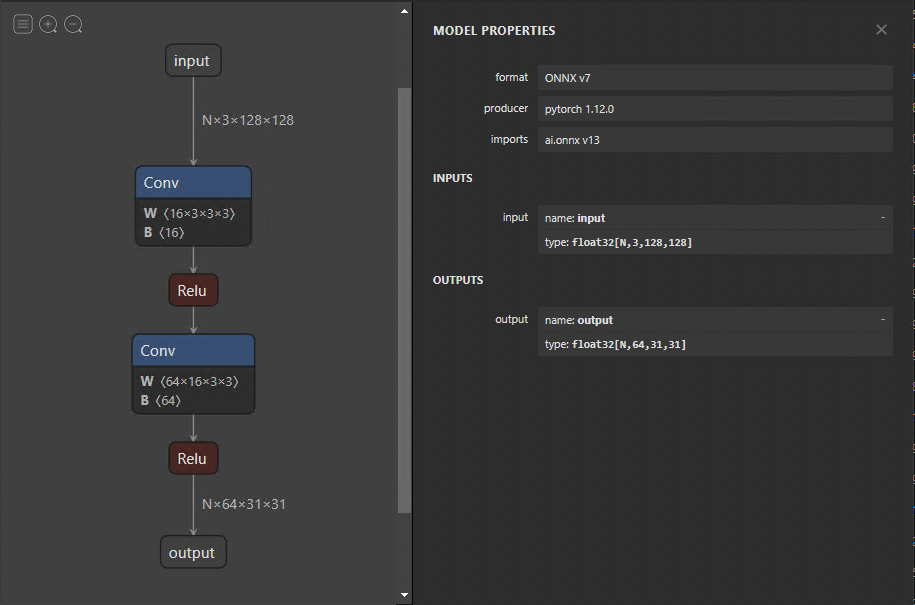
導出模型后,可以使用 Netron 將其可視化。默認視圖提供模型圖和屬性面板(圖 2 )。如果選擇輸入或輸出,屬性面板將顯示常規信息,例如名稱、OpSet和尺寸。
類似地,在圖中選擇節點會顯示節點的屬性。這是一種很好的方法,可以檢查模型是否正確導出,以及以后調試和分析問題。
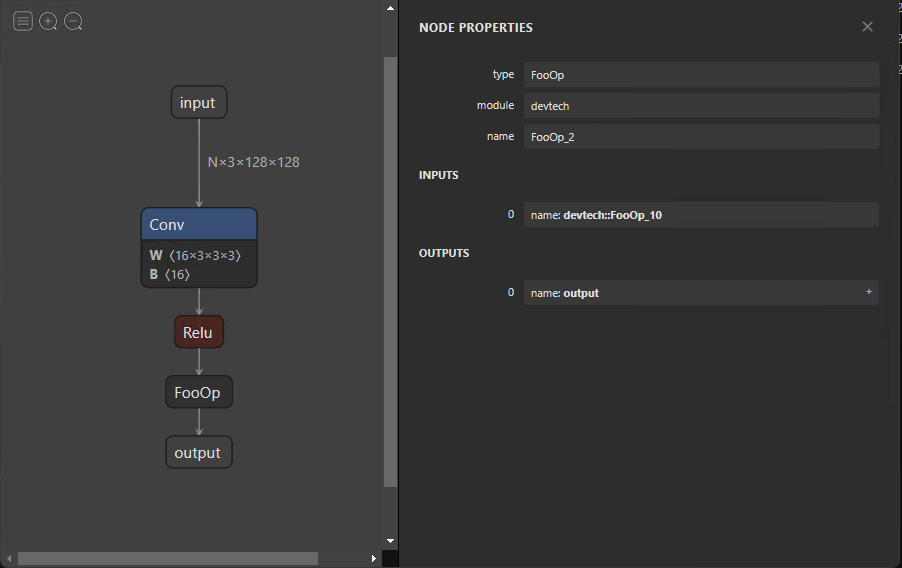
自定義運算符
目前, ONNX 定義了大約 150 個操作。它們的復雜性從算術加法到完整的長短期內存( LSTM )實現。盡管此列表隨著每個新版本的增加而增加,但您可能會遇到不包括研究模型中的操作員的情況。
在這種情況下,您可以定義torch.autograd.Function,其中包括forward函數中的自定義功能和symbolic中的符號定義。在這種情況下,forward函數通過返回其輸入來實現 no 操作。
class FooOp(torch.autograd.Function):
@staticmethod
def forward(ctx, input1: torch.Tensor) -> torch.Tensor:
return input1
@staticmethod
def symbolic(g, input1):
return g.op("devtech::FooOp", input1)
class FooModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = torch.nn.Sequential(
torch.nn.Conv2d(3, 16, 3, 2),
torch.nn.BatchNorm2d(16),
torch.nn.ReLU()
)
def forward(self, x):
x = self.model(x)
return FooOp.apply(x)
model = FooModel().eval().to(device="cpu")
dummy_input = torch.rand((1, 3, 128, 128), device="cpu")
torch.onnx.export(
model,
dummy_input,
"model_foo.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "N"}, "output": {0: "N"}},
opset_version=13,
)此示例演示如何定義用于將模型導出到 ONNX 的符號節點。盡管forward函數中提供了符號節點的功能,但必須將其實現并提供給用于推斷 ONNX 模型的運行時。這是特定于執行提供程序的,稍后將在本文中討論。
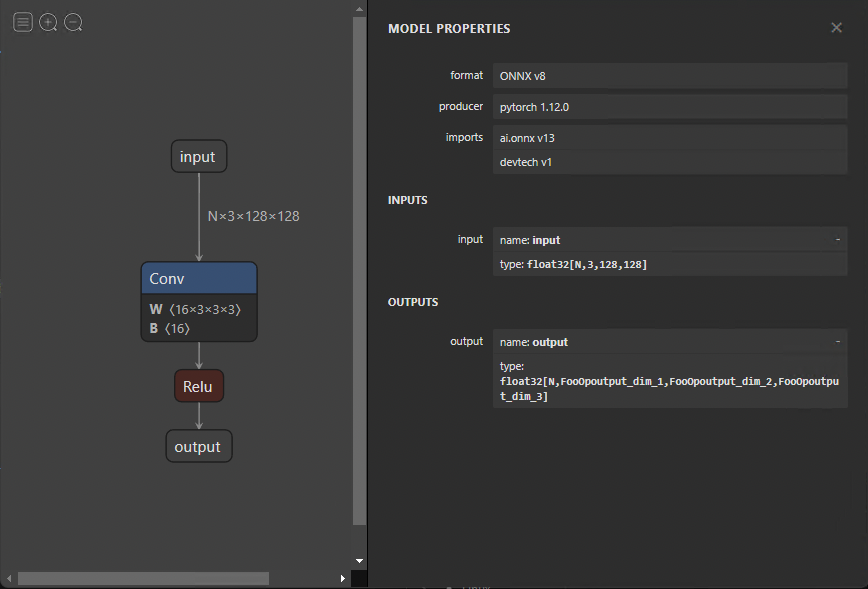
修改 ONNX 模型
您可能希望對 ONNX 模型進行更改,而無需再次導出。更改范圍從更改名稱到刪除整個節點。直接修改模型是困難的,因為所有信息都被編碼為協議緩沖區。幸運的是,您可以使用 GraphSurgeon 簡單地更改模型。
下面的代碼示例顯示了如何從導出的模型中刪除假FooOp節點。還有許多其他方法可以使用GraphSurgeon來修改和調試模型,我在這里無法介紹。有關詳細信息,請參閱 GitHub repo 。
import onnx_graphsurgeon as gs
import onnx
graph = gs.import_onnx(onnx.load("model_foo.onnx"))
fake_node = [node for node in graph.nodes if node.op == "FooOp"][0]
# Get the input node of the fake node
# For example, node.i() is equivalent to node.inputs[0].inputs[0]
inp_node = fake_node.i()
# Reconnect the input node to the output tensors of the fake node, so that the first identity
# node in the example graph now skips over the fake node.
inp_node.outputs = fake_node.outputs
fake_node.outputs.clear()
# Remove the fake node from the graph completely
graph.cleanup()
onnx.save(gs.export_onnx(graph), "removed.onnx")要刪除節點,必須首先使用GraphSurgeon API 加載模型。接下來,遍歷該圖,查找要替換的節點,并將其與FooOp節點類型匹配。將其輸入節點的輸出張量替換為其自身的輸出,然后移除其自身與輸出的連接,從而移除該節點。
圖 4 顯示了結果圖。
總結
本文介紹了使用 ONNX 運行時運行模型、模型優化和體系結構考慮。如果您對這些主題有任何進一步的問題,請聯系 開發者論壇?或加入 NVIDIA Developer Discord 。
要閱讀本系列的下一篇文章,請參閱 End-to-End AI for Workstation: ONNX Runtime and Optimization.
注冊 了解有關使用 NVIDIA 技術加速您的創意應用程序的更多信息?。
?





