
文本到圖像的 Diffusion 模型已經被建立為基于給定文本的高保真圖像生成的強大方法。然而, Diffusion 模型并不總是在給定的輸入文本和生成的圖像之間實現所需的對齊,尤其是對于現實生活中沒有遇到的復雜的特殊提示。因此,人們對有效地微調 Diffusion 文本到圖像模型以實現即時對齊并最大化文本到圖像評分模型越來越感興趣。
直接獎勵微調(DRaFT)是一種簡單而有效的方法,旨在微調 Diffusion 模型,以最大化可微分的獎勵函數,如可微分報酬的直接微調 Diffusion 模型所示。
這篇文章解釋了 Diffusion 模型的 DRaFT 方法,以更好地與不同和復雜的提示保持一致。我們還介紹了 DRaFT+,它增強了 DRaFT 方法的能力,并解決了它們的主要缺點。
現在,您可以通過訪問 DRaFT+ 算法和示例代碼 NeMo Aligner 庫 在 GitHub 上。NVIDIA NeMo 是一個端到端的平臺,用于在任何地方開發自定義生成人工智能。它包括用于訓練、微調、檢索增強生成、防護、數據管理工具和預訓練模型的工具,為企業提供了一種簡單、經濟高效、快速的方式來采用生成人工智能。未來,我們計劃將 DRaFT+ 算法集成到 NeMo 框架容器 中。
直接獎勵微調(DRaFT)
以下部分詳細探討了 DraFT 算法及其局限性,并深入探討了我們如何增強和開發 DraFT+算法。
鑒于人類反饋強化學習(RLHF)方法在大語言模型(LLM)微調中取得了顯著成功,生成文本到圖像社區已經測試了類似的想法,以提高圖像生成的保真度。這些方法將 Diffusion 過程視為完整的 RL 軌跡,并使用文本到圖像的評分模型進行引導。有關更多信息,請參閱 DPOK:用于微調文本到圖像 Diffusion 模型的強化學習 和用強化學習訓練 Diffusion 模型。
然而,這些方法有兩個缺點。首先,強化學習(RL)樣本是低效且計算昂貴的訓練過程。其次,它們只在狹窄的提示領域取得了成功,并且在不同的提示中缺乏可推廣性。
為了解決這些問題,作為 RL 的替代方案,DRaFT 方法建議通過 Diffusion 過程直接反向傳播可微分獎勵。盡管該方法比 RL 過程更簡單,但它在更大的范圍內(數十萬個提示)實現了文本和輸入提示之間明顯更好的對齊,計算時間快了幾個數量級。
然而,對于相同的提示,原始的 DRaFT 方法容易出現獎勵過度優化、模式崩潰和缺乏多樣性的問題。為了解決這些缺點,我們引入了 DRaFT+,它添加了一個正則化項來增強生成多樣性,控制優化的回報,并防止模式崩潰。
DRaFT 方法微調了 Stable Diffusion v1.5 模型(來自 具有潛在 Diffusion 模型的高分辨率圖像合成),參數化方式為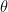

![{maximize}\;\mathbb{E}_{c\sim p_{c}, x_{T}\sim\mathcal{N}(\textbf{0},\textbf{1})}\big[R(x_{0}(\theta, x_{T}, c), c)\big]](https://s0.wp.com/latex.php?latex=%7Bmaximize%7D%5C%3B%5Cmathbb%7BE%7D_%7Bc%5Csim+p_%7Bc%7D%2C+x_%7BT%7D%5Csim%5Cmathcal%7BN%7D%28%5Ctextbf%7B0%7D%2C%5Ctextbf%7B1%7D%29%7D%5Cbig%5BR%28x_%7B0%7D%28%5Ctheta%2C+x_%7BT%7D%2C+c%29%2C+c%29%5Cbig%5D&bg=transparent&fg=000&s=0&c=20201002)
在這里 
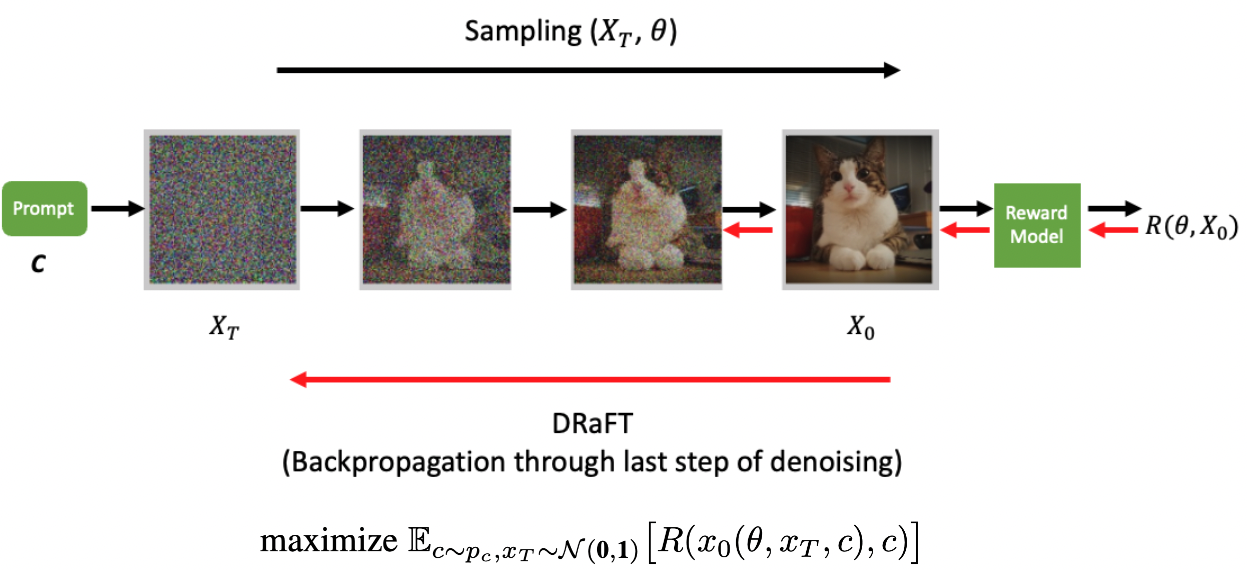
在反向過程中,我們計算生成的獎勵相對于 Diffusion 模型權重的梯度。然而,僅通過獎勵模型進行反向傳播,并且僅通過 Diffusion 模型的最后一個去噪步驟。令人驚訝的是,如可微分報酬的直接微調 Diffusion 模型所示,在 Diffusion 過程中反向傳播一個以上的步驟會導致算法的獎勵降低。
圖 1 展示了使用 vanilla DRaFT 的前后傳球。從正態分布采樣的初始噪聲通過 Diffusion 模型以獲得以輸入文本(c)為條件的去噪圖像。去噪后的圖像被傳遞到(凍結的)可微分獎勵模型。
草稿?
普通 DRaFT 算法的主要缺點是模式崩潰、獎勵黑客攻擊和缺乏多樣性。換言之,隨著 Diffusion 模型相對于獎勵模型進行訓練,它逐漸學會增加獎勵,同時對于輸入到 Diffusion 模型中的不同初始純噪聲,它會塌陷到相同的圖像 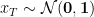
DRaFT 的作者提到了兩種解決此類問題的嘗試:在獎勵函數中添加輟學者,并在獎勵中添加一個術語,以促進微批量中圖像對之間的差異。然而,他們也提到,這些方法并不能完全緩解這一問題。
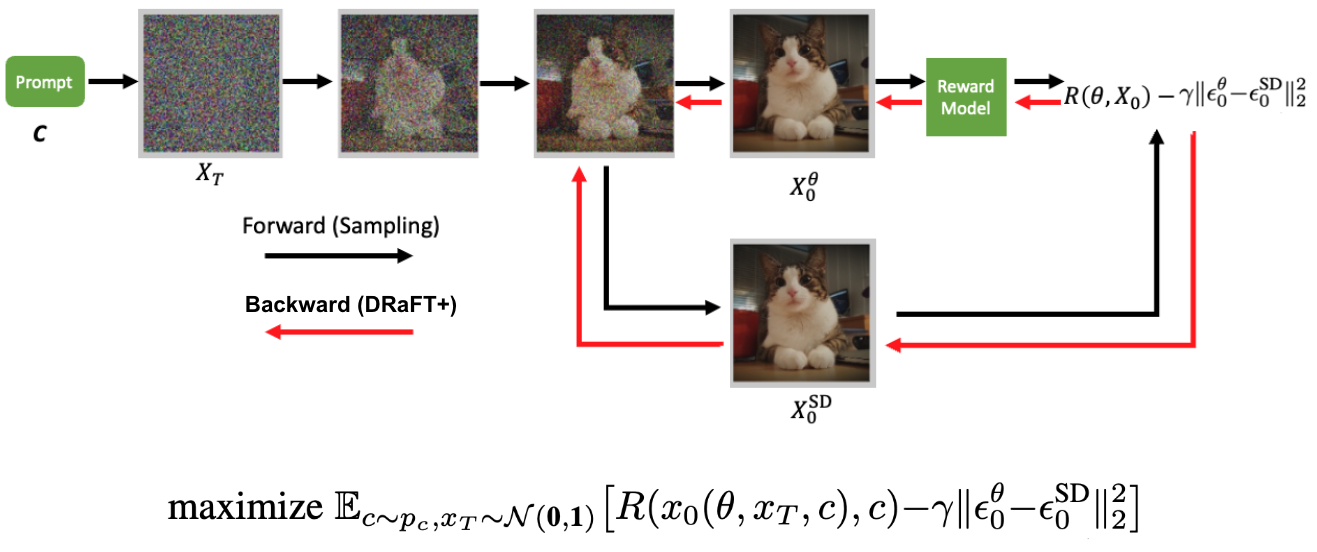
相反,我們的方法使用了兩個版本的穩定 Diffusion 模型,一個是針對獎勵模型進行訓練,另一個是使用凍結權重進行訓練。根據 RLHF 實踐,我們建議在訓練目標中添加一個正則化項,以懲罰凍結模型和正在訓練的模型之間的差異。
我們通過添加兩個模型預測的噪聲高斯之間的 Kullback-Leibler(KL)散度(此處等效于 L2 距離),將這樣的術語納入以下訓練目標中引入的目標中。
在這種情況下,

圖 2 展示了 DRaFT+算法的前向-后向傳遞。從正態分布采樣的初始噪聲通過可訓練 Diffusion 模型,但去噪的最后一步也通過凍結 Diffusion 模型來完成。這導致以輸入文本(c)為條件的兩個去噪圖像。將來自可訓練模型的去噪圖像傳遞到可微分獎勵模型。獎勵減去由可訓練和凍結模型生成的去噪圖像之間的距離,通過 Diffusion 模型進行反向傳播以更新其參數。
使用訓練 DRaFT+NeMo Aligner 庫 非常簡單,只需指定數據集和檢查點,然后運行以下腳本。
GPFS="/path/to/nemo-aligner-repo"TRAIN_DATA_PATH="/path/to/train_dataset.tar"UNET_CKPT="/path/to/unet_weights.ckpt"VAE_CKPT="/path/to/vae_weights.bin"RM_CKPT="/path/to/reward_model.nemo"NUM_DEVICES=#number of gpustorchrun --nproc_per_node=${NUM_DEVICES} ${GPFS}/examples/mm/stable_diffusion/train_sd_draftp.py \ trainer.num_nodes=1 \ trainer.devices=${NUM_DEVICES} \ model.micro_batch_size= \ model.global_batch_size= \ model.kl_coeff= \ model.optim.lr= \ model.unet_config.from_pretrained=${UNET_CKPT} \ model.first_stage_config.from_pretrained=${VAE_CKPT} \ rm.model.restore_from_path=${RM_CKPT} \ model.data.train.webdataset.local_root_path=${TRAIN_DATA_PATH} \ exp_manager.explicit_log_dir=/results |
欲了解更多關于運行腳本和設置的信息,請參閱 DRaFT+ 用戶指南。
DRaFT+訓練的結果?
本節介紹了使用 DRaFT+目標函數訓練穩定 Diffusion 模型的結果。正則化提高了生成的微調圖像的多樣性。對于這個問題,我們改變目標函數中正則化項的系數,并繪制多樣性度量與獎勵的關系圖。
在這里,我們使用的多樣性度量來自 深層特征作為感知度量的不合理有效性,該方法基本上基于來自預定義網絡(Alexnet)的兩個圖像補丁的激活來計算兩個給定圖像的感知相似性。更高的 LPIPS 分數轉化為更多樣的圖像。
我們比較了穩定 Diffusion v1.5、香草 DRaFT、具有不同正則化系數的 DRaFT+和 DDPO 的 LPIPS 得分測量。對于獎勵模型,我們使用中介紹的 PickScore 獎勵模型Pick-a-Pic:一個開放的文本到圖像生成用戶偏好數據集,請注意,對于相同的獎勵,我們的模型獲得了更好的多樣性得分。
圖 3 顯示了多樣性和回報之間的權衡。左邊的圖表顯示,較低的 KL 導致較低的 LPIPS 分數(較少的多樣性和更容易發生模式崩潰)。中間的圖表顯示 KL 越低,獎勵越高。右圖顯示,對于相同的獎勵,與香草 DRaFT 相比,DRaFT+獲得了更好的多樣性得分(相當于 KL 為 0 的 DRaFT+)。換言之,在獎勵閾值的情況下,引入正則化項將導致模型在實現該獎勵的同時具有更好的多樣性得分。
所有模型都在動物數據集上訓練了 200 個時期。多樣性得分是在來自相同提示的 100 個生成圖像的固定數據集上訓練期間測量的,并且總得分是 100 個圖像之間的平均成對 LPIPS 得分。
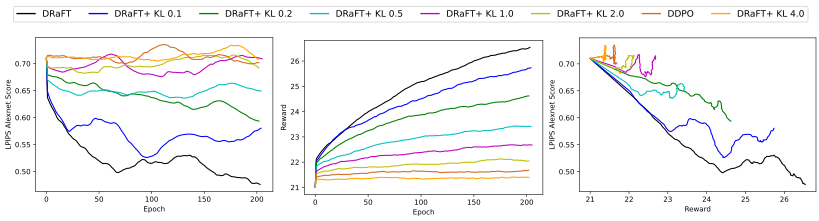
圖 4 顯示了在動物數據集上訓練 200 個時期后,針對不同模型的相同提示生成的圖像。圖中的每一行都包含來自模型不同變體的具有相同初始隨機種子的生成圖像。該圖顯示,對于較低的 KL,模式坍塌更嚴重,而具有較高 KL 的模型更接近穩定 Diffusion 模型。請注意,正則化項的添加對于防止發生在最右側列中的模式崩潰至關重要。

最后,圖 5 顯示了與基本穩定 Diffusion 模型相比,使用我們的 DRaFT+算法微調穩定 Diffusion 模型的幾個例子。兩個模型都使用相同的提示和初始種子來生成圖像。使用 PickScore 獎勵對 Pic-a-Pic 數據集提示進行微調。

總結?
本文介紹了用于微調生成文本到圖像 Diffusion 模型的 DRaFT+算法。該算法通過最大化從給定的可微分獎勵模型產生的獎勵來微調 Diffusion 過程。通過正則化項,我們的算法通過防止模式崩潰和增強圖像生成的多樣性來改進以前的方法。
要嘗試 DRaFT+ 算法,請訪問 NeMo Aligner 庫,位于 GitHub 上的開源倉庫。
?
?






