大語言模型(LLMs)的出現使 AI 行業受益匪淺,它提供了能夠生成類似人類的文本和處理各種任務的通用工具。然而,雖然 LLMs 展示了令人印象深刻的一般知識,但開箱即用時,它們在專業領域(例如動物科學)中的性能有限。為了提高其在特定領域的效用,該行業通常采用兩種主要策略:微調和檢索增強生成(RAG)。
微調需要在精心策劃和結構化的數據集上訓練模型,這需要大量的硬件資源以及領域專家的參與,而這一過程通常既耗時又昂貴。遺憾的是,在許多領域,以兼容業務限制的方式聯系領域專家極具挑戰性。
相反,RAG 涉及構建全面的知識文獻語料庫,以及一個有效的檢索系統,該系統可以提取相關文本塊以解決用戶查詢。通過將這些檢索到的信息添加到用戶查詢中,LLMs 可以生成更好的答案。雖然這種方法仍然需要主題專家為數據集精心策劃最佳來源,但它比微調更易于處理和業務兼容。此外,由于無需對模型進行大量訓練,因此這種方法的計算密集程度較低,且成本效益更高。
在創建 RAG 系統時,開發者投入了大量精力來設計一種有效的機制,以從知識數據集中檢索最佳信息片段。因此,通常會通過文本嵌入使用語義相似度測量來檢索最相關的文本。
NVIDIA NIM 和 NLP 流程
NVIDIA NIM 使用 LLM 簡化了 NLP 流程的設計,這些微服務簡化了跨平臺生成式 AI 模型的部署,使團隊能夠在提供標準 API 來構建應用的同時自行托管 LLM。
NIM 抽象化執行引擎和運行時操作等模型推理內部,確保 TensorRT-LLM、vLLM 等實現出色性能。主要功能包括:
- 可擴展部署
- 支持各種具有優化引擎的LLM架構
- 靈活集成到現有工作流程中
- 具有安全張量和持續 CVE 監控的企業級安全
您可以使用 Docker 運行 NIM 微服務,并使用 API 執行推理。經過專門訓練的模型權重還可通過修改容器命令用于特定任務,例如文檔解析。
在本文中,我將介紹 NIM 微服務如何幫助 AITEM 團隊開發 LAIKA(面向獸醫學從業者的 AI Co-pilot)。具體來說,我將探討 NIM 如何支持 RAG 流程,以最大限度地提高檢索效率,并展示模型如何簡化和加速分析和開發流程。
借助 AI 重塑動物護理

AITEM 是 NVIDIA Inception 計劃面向初創公司的成員,我們與 NVIDIA 密切合作,專注于在工業和生命科學等多個領域開發基于 AI 的解決方案。
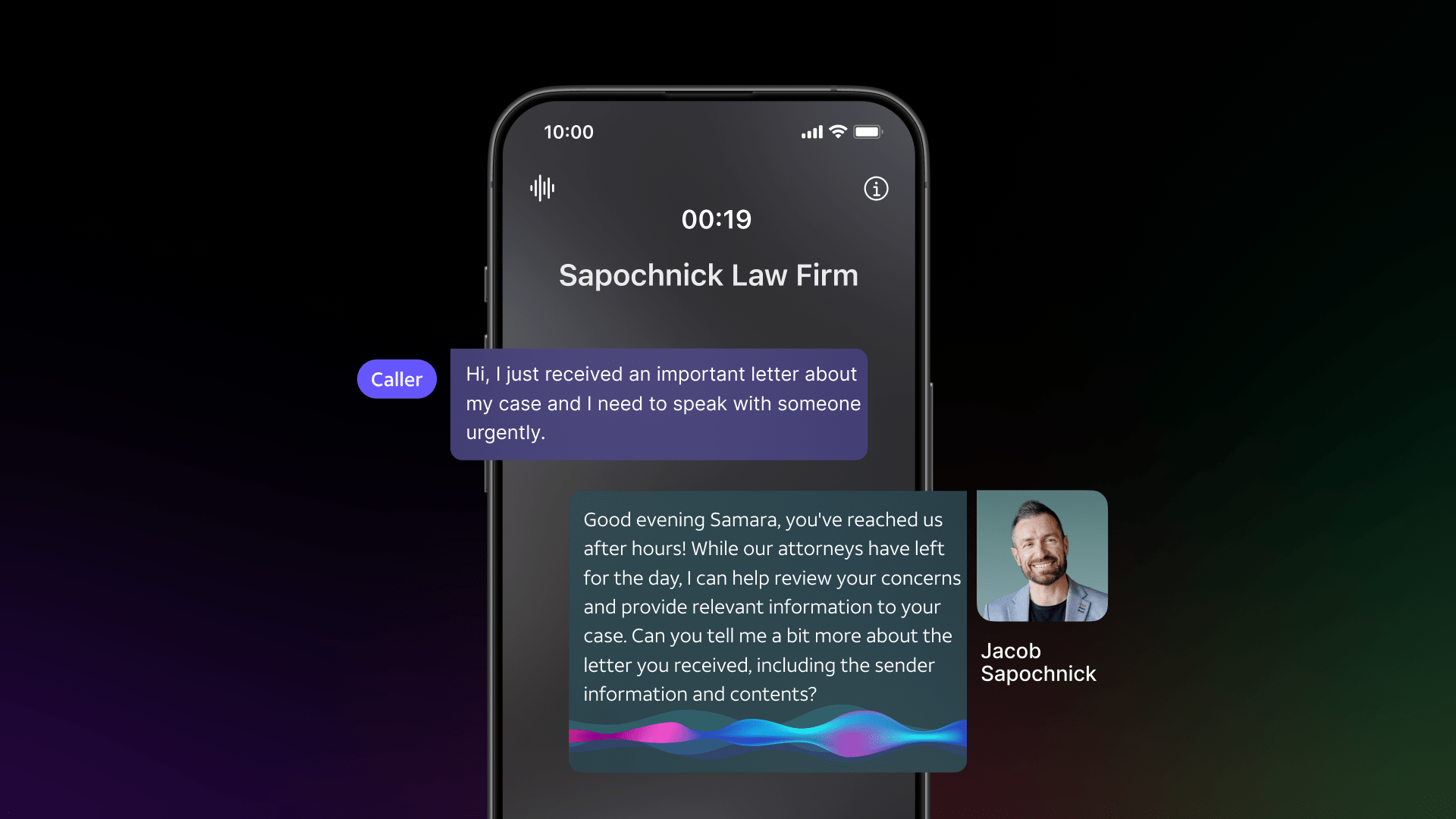
在動物醫學領域,我們正在開發?LAIKA,這是一種創新的 AI Copilot,旨在通過處理患者數據以及提供診斷建議、指導和澄清來協助動物醫生。LAIKA 充當對話代理,能夠處理文本查詢和實驗室分析文檔。LAIKA 最近在意大利和法國推出,不久后將擴展到其他國家。
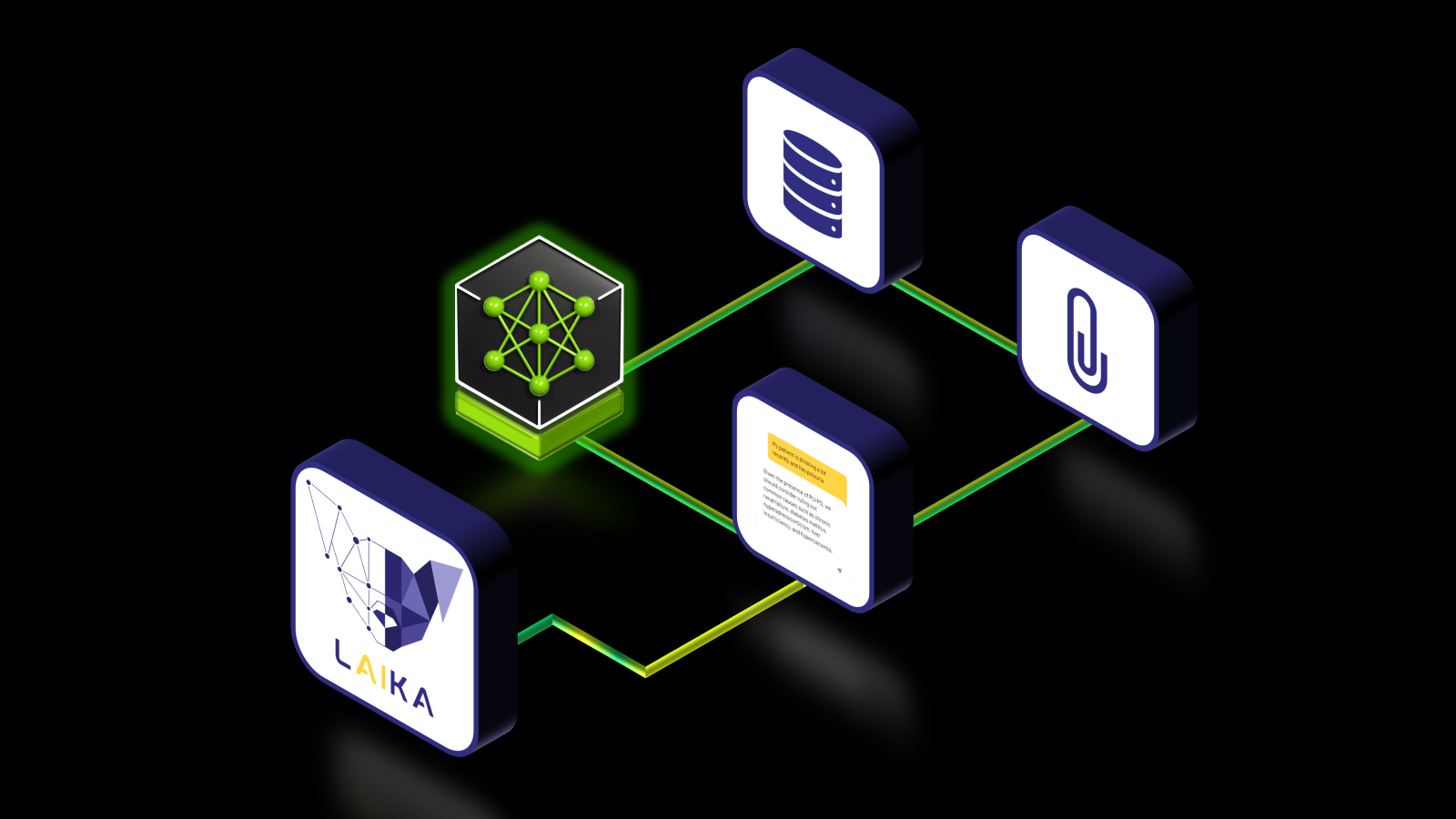
LAIKA 集成了多個 LLM 和 RAG 流程。RAG 組件從精心策劃的獸醫資源數據集中檢索相關信息(圖 2)。在準備過程中,每個資源被劃分為多個塊,并計算嵌入內容并存儲在 RAG 數據庫中。在推理過程中,會對查詢進行預處理,并計算其嵌入內容,并使用幾何距離指標將其與 RAG 數據庫中的嵌入內容進行比較。選擇最接近的匹配項作為最相關的匹配項,用于生成響應。

由于 RAG 數據庫中可能存在冗余,多個檢索到的數據塊可能包含相同的信息,從而限制了提供給應答系統的概念的多樣性。為了解決這一問題,LAIKA 采用了最大邊緣相關性(Maximal Marginal Relevance,MMR)算法,以最大限度地減少數據塊冗余,并確保更廣泛的相關信息。
由于從資源中提取數據塊是自動化的,且資源量過大,無法進行手動驗證,因此可能會包含格式錯誤的數據塊,例如腳注、錯誤的字符集或 OCR 錯誤。雖然由于分布外的嵌入,檢索此類無關數據塊的概率較低,但不是零,這仍然可能影響響應質量。
雖然基于距離指標的相似度檢索是一種廣泛使用的方法,但并非完美無缺。它可以檢索格式良好但無用甚至具有誤導性的信息。最大限度地減少錯誤檢索的影響對于保持高答案質量至關重要。
NVIDIA NeMo Retriever 重構 NIM 微服務
NVIDIA API 目錄包含一系列 NeMo Retriever NIM 微服務,使組織能夠將自定義模型無縫連接到各種業務數據,并提供高度準確的響應。
該集合包括 NVIDIA Retrieval QA Mistral 4B 重新排名 NIM 微服務,該模型旨在評估給定文本段落包含回答用戶查詢的相關信息的概率。將此模型集成到 RAG 流程中,使我們能夠過濾掉不通過重新排名模型評估的檢索內容,確保僅使用最相關和準確的信息。或者,可以使用重新排名模型的輸出對檢索的數據塊進行排序,僅保留排名在頂部的數據塊。
為了評估此步驟對 RAG 管道的影響,我們設計了一個實驗:
- 從 LAIKA 用戶中提取包含約 100 個匿名問題的數據集。
- 運行當前的 RAG 工作流以檢索每個問題的 chunks。
- 根據重新排序模型提供的概率,對檢索到的數據塊進行排序。
- 評估每個數據塊與查詢的相關性。
- 分析重新排序模型的概率分布與步驟4所確定的相關性的關系。
- 比較 Step 3 中數據塊的排名與 Step 4 中數據塊的相關性。
- ?
LAIKA 中的用戶問題在形式上可能會有很大差異(圖 3)。一些查詢包含對情況的詳細解釋,但缺少特定問題。其他查詢包含有關研究的精確查詢,而有些則尋求基于臨床案例或分析文檔的指導或區別診斷。

由于每個問題的數據塊數量眾多,我們使用了 Llama 3.1 70B Instruct NIM 微服務進行評估,該服務也可在 NVIDIA API 目錄中獲取。
為了更好地了解重新排序模型在數據集上的表現,我們詳細檢查了具體的查詢和模型響應。表 1 突出顯示了該查詢的頂部和底部重新排名塊,“這只貓已經瘦了兩個月,保持了食欲,沒有出現嘔吐或腹瀉。潛在的差分診斷是什么?”
帶有正 logits(相關性概率 > 50%)的前三個數據塊都提供了與問題直接相關的有用信息。相比之下,具有較大負 logits 的后三個數據塊的相關性較小,涵蓋了有限的案例研究和藥物投訴,但這些都于事無補。
| 文本 | 重新排名邏輯 |
| 尤其難以診斷的減重原因包括:未引起嘔吐的胃病、未引起嘔吐或腹瀉的腸病、肝臟疾病… | 3.3125 |
| 診斷非特異性體征(如厭食癥、體重減輕、嘔吐和腹瀉等)的差異……在貓中,急性胰腺炎很少見,……癥狀非特異性且定義不清(例如:厭食癥、嗜睡、體重減輕)。 | 2.3222 |
| 如果出現癌癥惡衰、消化不良/吸收不良……在某些情況下,食欲可能會增加……但是,正常的食欲并不排除存在嚴重的疾病。 | 2.2265 |
| Overall, weight loss was the most common presenting sign … with little difference between the groups … | -5.0078 |
| 其他客戶投訴包括嗜睡、厭食癥、體重減輕、嘔吐…… | -7.3672 |
| There were 6 British Shorthair, 4 European Shorthair, and 1 Bengal cat … Reported clinical signs by owners included: reduced appetite or anorexia… | -10.3281 |
圖 4 比較了相關 (良好) 和無關 (壞) 數據塊之間重新排序的模型概率輸出分布 (在對數中)。良好數據塊的概率高于壞數據塊,并且 t 檢驗確認此差異在統計上具有顯著性,p 值低于 3e-72。

圖 5 顯示了重新排名誘導的排序位置的分布差異:好數據塊主要位于頂部位置,而壞數據塊較低。Mann-Whitney 測試確認這些差異在統計上具有顯著性,導致 p 值低于 9e-31。

圖 6 顯示了排名分布,并有助于定義有效的截止點。在前五個位置中,大多數數據塊是好的,而位置 11-15 中的大多數數據塊是壞的。因此,僅保留前五個檢索項或其他選定的數字可以作為有效排除大多數壞數據塊的一種方法。

為了優化檢索流程并在更大限度提高準確性的同時盡可能降低提取成本,輕量級嵌入模型可以與 NVIDIA 重新排名 NIM 微服務搭配使用,以提高檢索準確性。執行時間可以縮短 1.75 倍(圖 7)。

借助 NVIDIA 重新排名的 NIM 微服務獲得更好的答案。
結果表明,將 NVIDIA 重新排名的 NIM 微服務添加到 LAIKA RAG 流程會對檢索數據塊的相關性產生積極影響。通過將更精確的專業信息轉發到下游應答 LLM,它為模型提供了在獸醫科學等高度專業領域所需的知識。
NVIDIA API 目錄中提供的 NVIDIA 重新排名 NIM 微服務可簡化采用流程,因為您可以輕松拉取和運行模型,并通過 API 推理其評估。這消除了與環境設置和手動優化相關的壓力,因為它幾乎適用于任何平臺,并通過 NVIDIA TensorRT 進行了預量化和優化。
關于 LAIKA 和其他 AITEM 項目的更多信息和最新更新,請參閱 AITEM 解決方案,并在 LinkedIn 上關注 LAIKA 和 AITEM。
?