
一旦您有了自動語音識別( ASR )模型預測,您可能還想知道這些預測正確的可能性。這種正確率或置信度通常作為原始預測概率(快速、簡單且可能無用)來衡量。您還可以訓練單獨的模型來估計預測置信度(準確,但復雜且緩慢)。這篇文章解釋了如何使用基于熵的方法實現快速、簡單的單詞級 ASR 置信度估計。
置信度估計概述
你有沒有見過機器學習模型預測,并想知道這種預測有多準確?您可以根據在類似測試用例中測量的準確度進行猜測。例如,假設您知道 ASR 模型以 10% 的單詞錯誤率( WER )預測錄制語音中的單詞。在這種情況下,您可以預期該模型識別的每個單詞都有 90% 的準確率。
對于某些應用程序來說,這樣的粗略估計可能就足夠了,但如果您想確切地知道哪個單詞更可能正確,哪個單詞不正確呢?這將需要使用超出實際單詞的預測信息,例如從模型接收的準確預測概率。
使用原始預測概率作為置信度的度量是判斷哪個預測更可能正確、哪個預測不太可能正確以及哪個預測最簡單的最快方法。
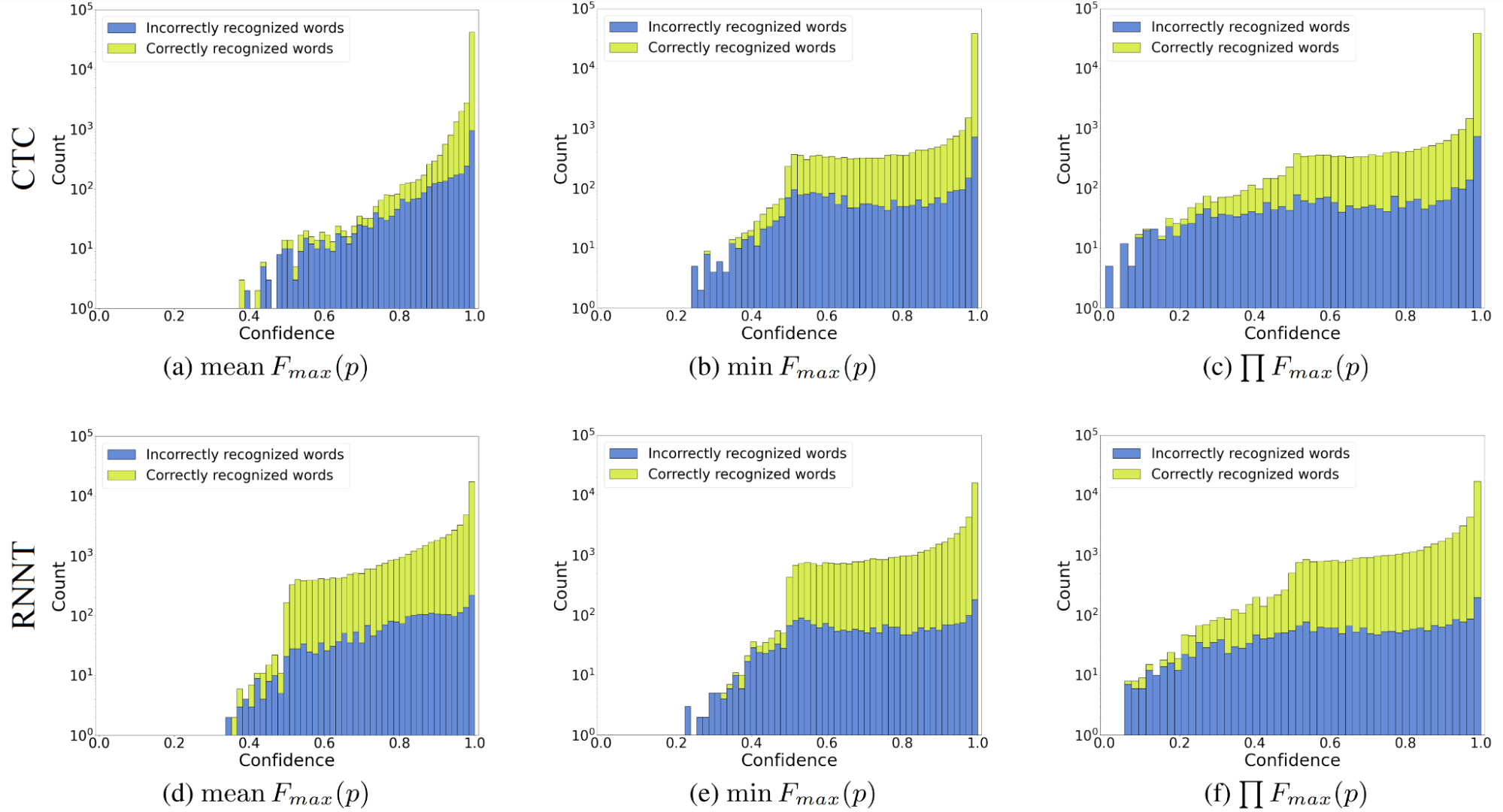
但原始概率作為置信度估計有用嗎?不是真的。例如,圖 1 是貪婪搜索識別結果的置信度計算:一幀一幀地計算概率最高的語言單元(“最大概率”或
換言之,該模型幾乎總是給出一個接近于一個可能預測的概率,而其他任何預測的概率都為零。因此,即使預測不正確,其概率也通常大于 0.9 。過度自信與模型的架構或組件無關:簡單的卷積或遞歸神經網絡可以具有與 transformer 或類似 transformer 的模型相同的過度自信程度。
過度自信來自用于訓練端到端 ASR 模型的損失函數。當目標預測概率最大化時,簡單損失達到最小值,而任何其他預測概率為零。這些損失包括交叉熵、普遍的連接主義時間分類( CTC )或遞歸神經網絡傳感器( RNN-T ),或任何其他最大似然族損失函數。
過度自信使預測概率變得不自然。很難設置正確的閾值來區分正確和錯誤的預測,這使得使用原始概率作為置信度幾乎是無用的。
 )獲得。
)獲得。使用原始概率作為置信度的另一種選擇是創建單獨的可訓練置信度模型,以基于概率和(可選) ASR 模型嵌入來估計置信度。這種方法可以提供相當準確的置信度,代價是訓練每個模型的估計器,將其與主模型一起納入推理(并不可避免地減慢推理速度),并且缺乏可解釋性。
然而,如果你想要最佳的正確性度量,并且對神經網絡估計另一個神經網絡的系統感到滿意,那么試試神經置信度估計器。
基于熵的置信度估計
本節介紹了一種不可訓練但有效的置信度估計方法。您將學習如何在貪婪搜索識別模式下為 CTC 和 RNN-T ASR 模型建立快速、簡單、魯棒和可調整的置信度估計方法。
一種簡單的基于熵的置信測度
如上所述,將置信度簡單地視為原始預測概率是不可行的。最好將此定義擴展到區間[0 , 1]上所有可用知識的函數。將預測概率“按原樣”歸為這個定義。這種方法使您能夠嘗試在評估中添加外部知識或以新的方式使用現有信息(概率)。
信心必須忠于其主要目的,即衡量正確性。至少,它必須這樣做:為更可能正確的預測分配更高的值。
作為一種置信度度量,熵在理論上是合理的,并且運行良好。在信息論中,熵是不確定性的度量,它基于所有可能結果的概率來計算不確定性值。
這正是具有貪婪解碼模式的 ASR 所需要的,其中每個概率向量只有一個預測。只需將熵值分配給預測。然后反轉熵值(使其“確定”)并將其歸一化(將其映射到[0 , 1]),如下所示。
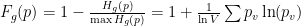
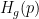
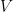
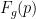
這種規范化很方便,因為它不依賴于可能的函數的數量,并且給你一個簡單的經驗法則:接受接近于 1 的函數,放棄接近于 0 的函數。
基于熵的高級置信測度
上述基于熵的置信度估計在這種形式下非常適用,但仍有改進的空間。雖然理論上正確,但它永遠不會顯示值??由于模型的過度自信,在實踐中接近于零(當所有概率相等時)。
此外,它不能以這種形式解決不同程度的過度自信。第二個問題很棘手,但第一個問題可以通過不同的標準化來解決。指數運算在這里會有所幫助。當負數被提升為冪時,結果將位于區間[0 , 1]內,并且對于大多數參數接近于零。
使用此屬性,可以使用以下公式規范化熵:

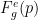
要使基于熵的信心對過度自信具有真正的魯棒性,需要一種稱為 temperature scaling 的方法。此方法將 log softmax 乘以一個 0 <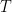

不等式的右側對于
幸運的是,你不必自己將溫度代入熵。二十世紀引入了一些參數熵。其中包括統計熱力學中的 Tsallis entropy 和信息論中的 Rényi entropy ,這將在下文中討論。兩者都有一個特殊的參數
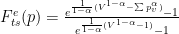
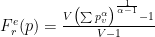
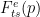
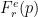
置信預測聚合
到目前為止,本文已經考慮了單個概率向量或單個幀的置信度估計。本節介紹了單詞級預測的完整置信度估計方法,引入了預測聚合。
基于熵的置信度可以以與最大概率相同的方式聚合:平均值、最小值和屬于同一單詞的幀預測的乘積。無論采取何種措施,在聚合 ASR 置信度預測時必須回答兩個問題: 1 )如何將預測聚合到語言單元,而不是將語言單元聚合到單詞,以及 2 )如何處理所謂的 幀(預測 令牌的幀)。和以前一樣,第一個問題很簡單,第二個問題很棘手。
RNN-T 模型每次發生時只發出一個非 令牌,因此您可以簡單地將此預測作為單位級別的置信度,并將其放入單詞置信度聚合。 CTC 模型可以在相應單元發音時重復發出相同的非 令牌。我發現對單位和單詞使用相同的聚合函數已經足夠好了,但總的來說還有實驗的空間。
有兩種方法可以處理 幀進行置信度聚合:使用它們或丟棄它們。雖然第一個選項看起來很自然,但它迫使您精確地找出如何將它們分配給最近的非 單元。
你可以把它們放在最左邊的單位,只放在最靠近的單位,或者其他什么地方,但最好把它們放下。為什么?除了更容易之外,這為基于熵的高級度量提供了(令人驚訝的)更好的結果。這在理論上也更為合理: 預測包含有關在說話時未被識別的單元和單詞的信息(所謂的刪除)。如果您試圖將 置信度分數合并到聚合管道中,您可能會用有關刪除單元的信息污染您的置信度。
評估結果和使用提示
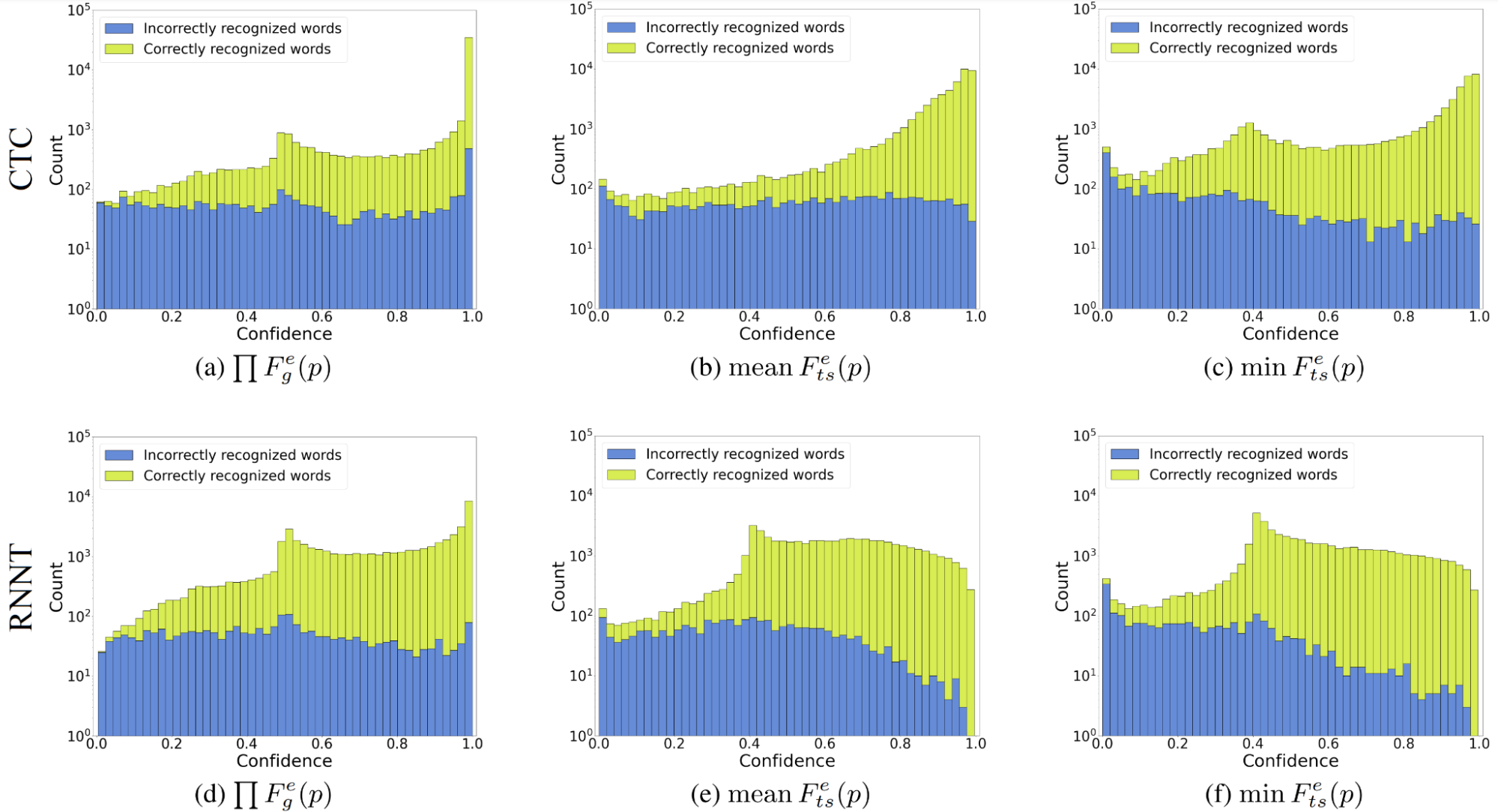
現在,看看所提出的基于熵的置信度估計方法是否優于最大概率置信度。圖 2 可能與圖 1 相似,具有最大概率置信分布,但您可以看到基于熵的方法轉換正確和錯誤的單詞分布,以便更好地分離。(不同的分布形狀表示更好的可分離性。)
所有三種方法都涵蓋了整個置信譜。盡管產品聚合對于指數歸一化吉布斯熵置信度表現最好,但該熵本身并不能很好地處理過度自信。基于 Tsallis 熵的置信度
?
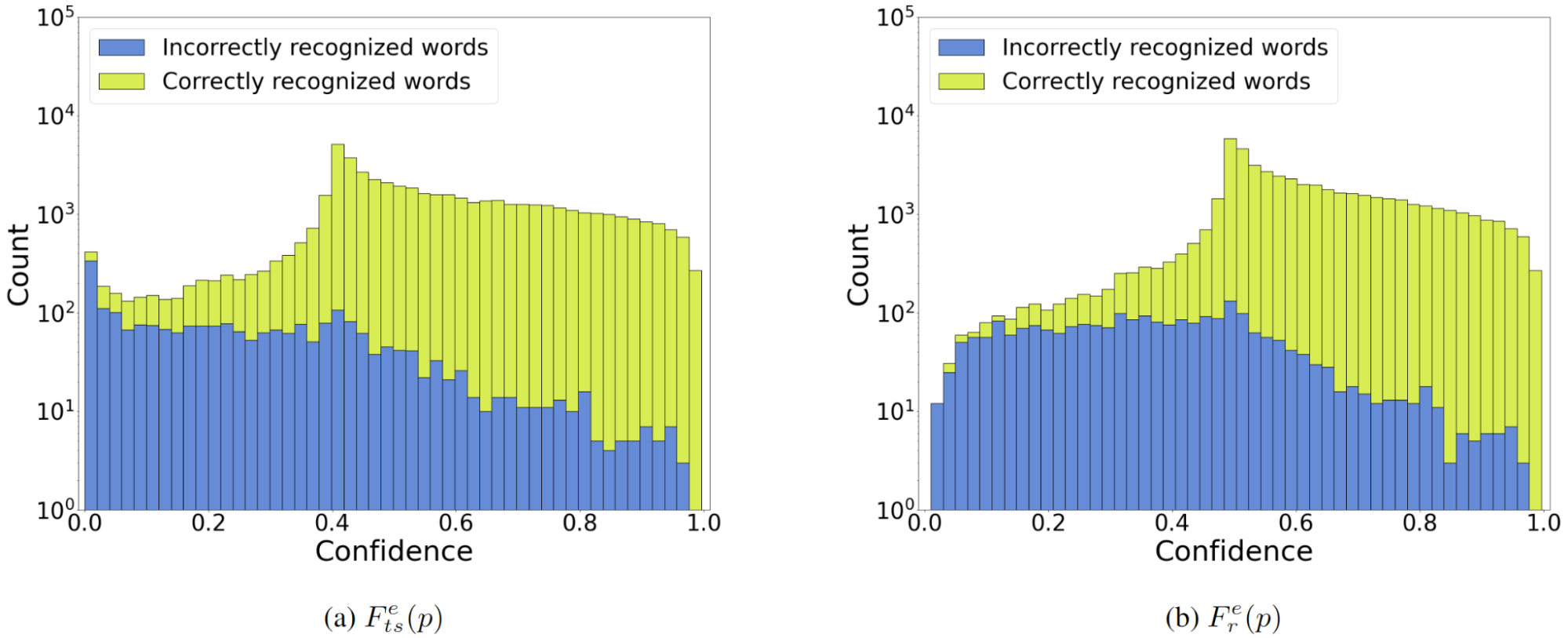
比較中的 R é nyi 熵在哪里?基于 Tsallis 和 R é nyi 的方法的性能幾乎相同,盡管它們的公式存在明顯差異(圖 3 )。對于相同的
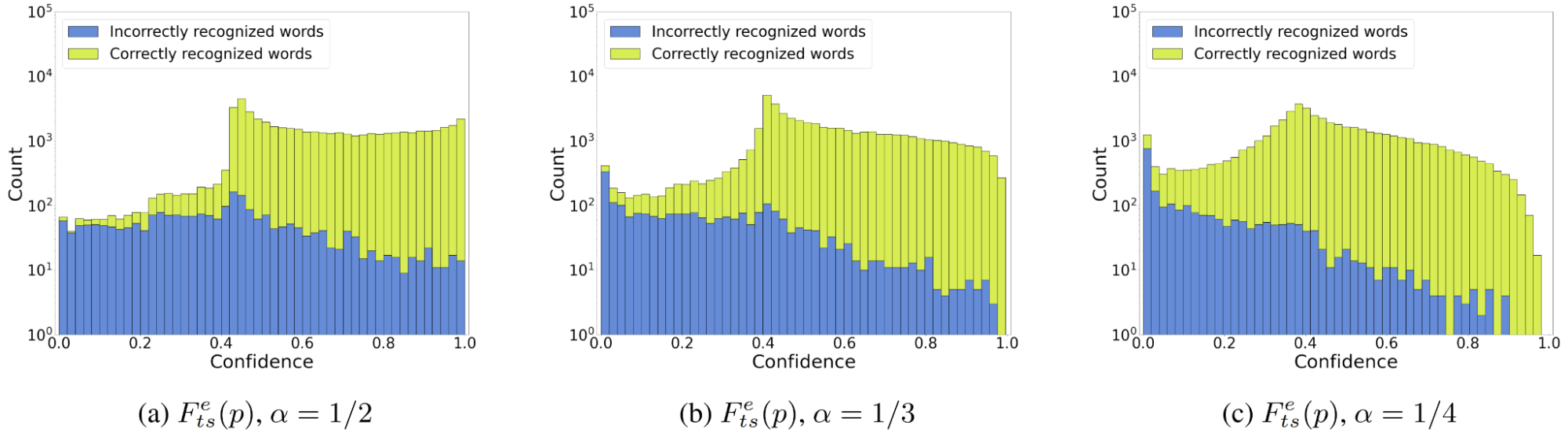
最后一個問題是如何選擇
如果您愿意犧牲分數的自然性(獲得正確預測的合理高置信分數)以獲得更好的分類能力,則應選擇較小的
 之間的比較 具有 RNN-T 模型的基于 Tsallis 熵的方法的值
之間的比較 具有 RNN-T 模型的基于 Tsallis 熵的方法的值剩下的是對提出的基于熵的方法的正式評估。首先,基于熵的置信度估計方法在檢測錯誤單詞方面比最大概率方法好四倍。第二,所提出的估計器具有噪聲魯棒性,允許您以在常規聲學條件下丟失 5% 正確單詞的代價過濾掉多達 40% 的模型幻覺(基于純噪聲數據測量)。最后,基于熵的方法給出了 CTC 和 RNN-T 模型的相似度量分數。這意味著您可以使用 RNN-T 模型預測的置信度分數,這在以前是不實際的。
結論
這篇文章提供了三個主要要點:
- 使用 Tsallis 和 Rényi 基于熵的置信度代替原始概率作為 ASR 貪婪搜索識別模式的正確性度量。它們速度一樣快,而且更好。
- 調整測試集上的熵指數
- 嘗試你自己的想法,找到比熵更好的信心度量。
有關擬議方法評估的詳細信息,請參見 Aleksandr Laptev 和 Boris Ginsburg 的 Fast Entropy-Based Methods of Word-Level Confidence Estimation for End-To-End Automatic Speech Recognition 。
NVIDIA NeMo 中提供了所有方法以及評估指標。訪問 GitHub 上的 NVIDIA/NeMo 開始。
?






