
NVIDIA Arm HPC 開發者套件?是一個集成的硬件和軟件平臺,用于在異構 GPU 和 CPU 加速計算系統上創建、評估和基準測試 HPC 、 AI 和科學計算應用程序。 NVIDIA 于 2021 3 月宣布上市。
該套件被設計為 HPC 和 AI 應用的下一代 NVIDIA Grace Hopper 超級芯片?的墊腳石。它可用于識別不明顯的 x86 依賴關系,并確保 1H23 中 NVIDIA Grace Hopper 系統?之前的軟件準備就緒。有關詳細信息,請參閱 NVIDIA Grace Hopper 超級芯片白皮書?。
Oak Ridge National Laboratory Leadership Computing Facility ( OLCF )將 NVIDIA Arm HPC 開發套件集成到其現有的 Wombat Arm cluster 中。應用程序團隊致力于構建、驗證和基準測試幾個 HPC 應用程序,以評估下一代基于 Arm 和 GPU 的 HPC 系統的應用程序準備情況。這些團隊已共同提交了《 IEEE 并行和分布式系統學報》,以供發表,證明 GPU 加速 Arm 系統可用的軟件和工具套件已準備好用于生產環境。要了解更多信息,請參見 Early Application Experiences on a Modern GPU-Accelerated Arm-based HPC Platform 。
OLCF 袋熊集群
Wombat 是一個實驗集群,配備了來自不同供應商的基于 Arm 的處理器。它從 2018 年開始運行。該集群由 OLCF 管理,用戶和研究人員可以自由訪問。
在研究時,集群由三種類型的計算節點組成:
- 4 個 HPE Apollo 70 節點,每個節點配備雙 Cavium (現為 Marvell ) ThunderX2 CN9980 處理器和兩個 NVIDIA V100 Tensor Core GPUs
- 16 個 HPE Apollo 80 節點,每個節點配備一個 Fujitsu A64FX 處理器
- 8 個 NVIDIA Arm HPC 開發套件節點,每個節點配備一個 Ampere Computing Altra Q80 – 30 CPU 和 2 個 NVIDA A100 GPU
這三種類型的節點共享一個基于 TX2 的通用登錄節點,基于 Arm ,所有節點都通過 InfiniBand EDR 和 HDR. 連接
HPC 應用評估
11 個不同的小組開展了評估工作。團隊包括橡樹嶺國家實驗室、桑迪亞國家實驗室、伊利諾伊大學厄巴納 – 香檳分校、佐治亞理工學院、巴塞爾大學、瑞士國家超級計算中心( SNSC )、赫爾姆霍茲 – 澤特姆 – 德累斯頓 – 羅森多夫分校、特拉華大學和 NVIDIA 的研究人員。
表 1 總結了應用程序的最終列表及其各種特性。這些應用程序涵蓋八個不同的科學領域,包括用 Fortran 、 C 和 C ++編寫的代碼。使用的并行編程模型有 MPI 、 OpenMP / OpenACC 、 Kokkos 、 Alpaka 和 CUDA 。在移植活動期間,沒有對應用程序代碼進行任何更改。評估過程主要集中于應用程序移植和測試,考慮到測試臺的實驗性質,較少強調絕對性能。
| App Name | Science Domain | Language | Parallel Programming Model |
| ExaStar | Stellar Astrophysics | Fortran | OpenACC, OpenMP offload |
| GPU-I-TASSER | Bioinformatics | C | OpenACC |
| LAMMPS | Molecular Dynamics | C++ | OpenMP, KOKKOS |
| MFC | Fluid Dynamics | Fortran | OpenACC |
| MILC | QCD | C/C++ | CUDA |
| MiniSweep | Sn Transport | C | OpenMP, CUDA |
| NAMD/VMD | Molecular Dynamics | C++ | CUDA |
| PIConGPU | Plasma Physics | C++ | Alpaka, CUDA |
| QMCPACK | Chemistry | C++ | OpenMP offload, CUDA |
| SPECHPC 2021 | Variety of Apps | C/C++/Fortran | OpenMP offload, OpenMP |
| SPH-EXA2 | Hydrodynamics | C++ | OpenMP, CUDA |
本文介紹了其中四個應用程序的結果。要了解有關其他應用程序的更多信息,請參閱 Early Application Experiences on a Modern GPU-Accelerated Arm-based HPC Platform 。
蛋白質結構和功能預測的生物信息學
GPU-I-TASSER 是用于蛋白質結構和功能預測的具有 GPU 能力的生物信息學方法。 I-TASSER 套件通過四個主要步驟預測蛋白質結構。其中包括螺紋模板識別、迭代結構裝配模擬、模型選擇和優化。最后一步是基于結構的函數注釋。結構折疊和重組階段通過復制品交換蒙特卡羅模擬進行。
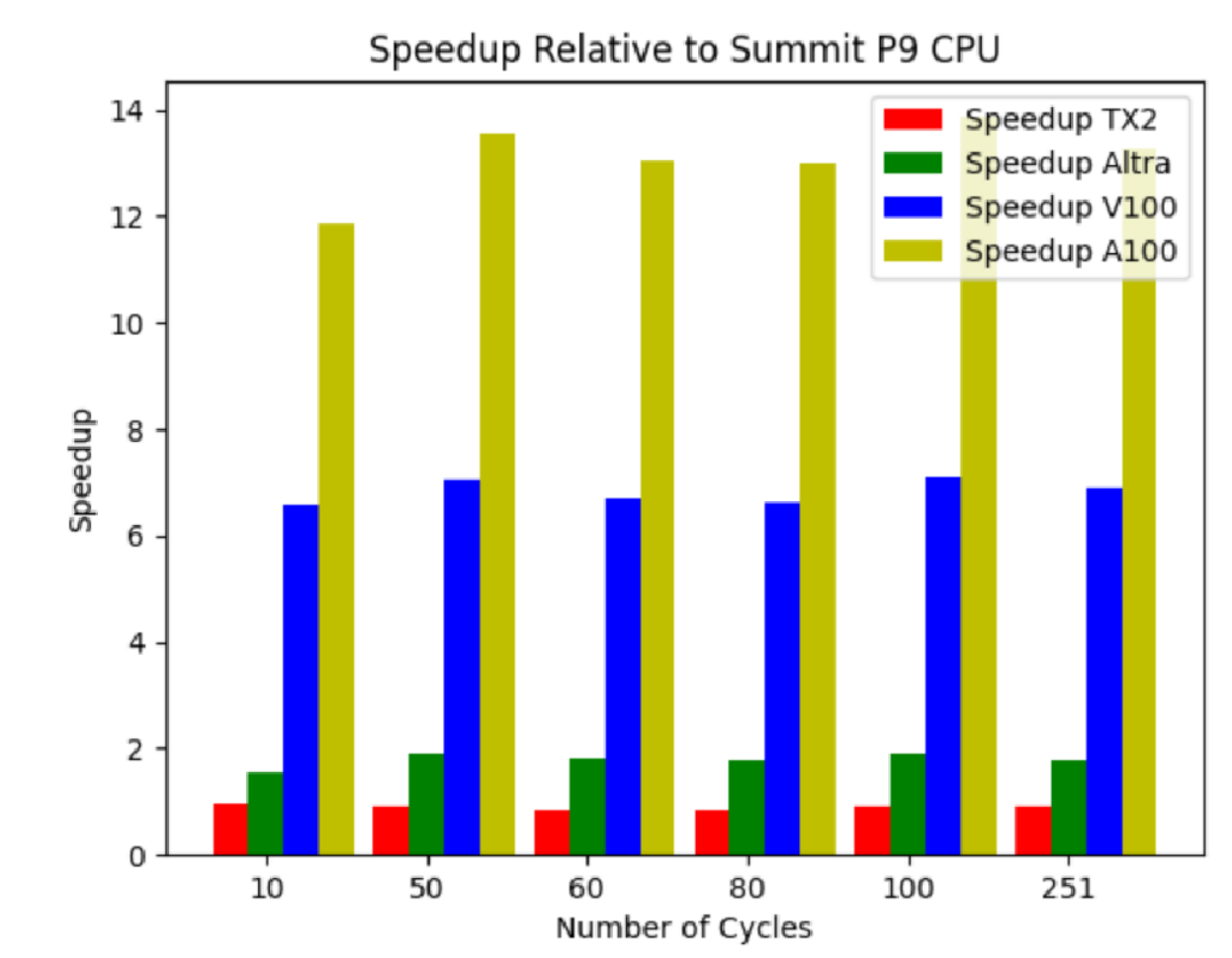
圖 1 顯示了 Wombat 的 ThunderX2 和 AmpereAltra 處理器以及 NVIDIA A100 和 V100 GPU 相對于 Summit 上的 POWER9 處理器的性能。對于 Ampere Ultra 、 NVIDIA V100 和 A100 ,分別觀察到 1.8 倍、 6.9 倍和 13.3 倍的加速。
物理問題的流體流求解器
Multi-component Flow Code ( MFC )是一個開源的流體流求解器,它為各種物理問題提供高階精確的解決方案,包括多相可壓縮流和子網格分散。
表 2 顯示了不同硬件的平均時鐘時間和相對性能指標。時間列幾乎沒有絕對意義,相對性能是最有意義的(也顯示在最后一列)。所有比較都使用 NVHPC v22.1 或 GCC v11.1 編譯器,如圖所示。 CPU 壁時鐘時間通過每個芯片的 CPU Core 的數量進行歸一化。結果表明,在 Summit 上, A100 GPU 比 V100 快 1.72 倍。
| ? | Compiler | Time (sec) | Speedup |
| NVIDIA A100 | NVHPC | 0.28 | 15.71 |
| NVIDIA V100 | NVHPC | 0.5 | 8.80 |
| 2xXeon 6248 | NVHPC | 2.7 | 1.63 |
| 2xXeon 6248 | GCC | 2.1 | 2.10 |
| Ampera Altra | NVHPC | 3.9 | 1.13 |
| Ampera Altra | GCC | 2.7 | 1.63 |
| 2xPOWER9 | NVHPC | 4.4 | 1.00 |
| 2xPOWER9 | GCC | 3.5 | 1.26 |
| 2xThunderX2 | NVHPC | 21 | 0.21 |
| 2xThunderX2 | GCC | 5.4 | 0.81 |
| A64FX | NVHPC | 4.3 | 1.02 |
| A64FX | GCC | 13 | 0.34 |
NAMD 和 VMD 用于生物分子動力學模擬和可視化
NAMD 和 VMD 是用于分子動力學模擬( NAMD )和制備、分析和可視化( VMD )的生物分子建模應用。研究人員使用 NAMD 和 VMD 研究生物分子系統,包括單個蛋白質、大型多蛋白復合物、光合細胞器和整個病毒。
表 3 顯示, NAMD 在 A100 上的模擬速度比 V100 快 50% 。 Cavium ThunderX2 和 IBM POWER9 之間的性能相似,后者得益于 CPU 和 GPU 之間的低延遲 NVIDIA NVLink 連接。
| CPU | GPU | Compiler | Perf (ns/day) |
| 2x EPYC 7742 | A100-SXM4 | GCC | 187.5 |
| 1x Ampera Altra | A100-PCIe | GCC | 182.2 |
| 2x Xeon 6134 | A100-PCIe | ICC | 181.4 |
| 2x POWER9 | V100-NVLINK | XLC | 125.7 |
| 2x ThunderX2 | V100-PCIe | GCC | 124.9 |
對于 VMD ,表 4 中的 GPU 加速結果顯示了與現有 CPU 平臺相比, GPU 提供的更高峰值算術吞吐量和內存帶寬帶來的性能增益。 GPU 分子軌道結果突出了 GPU 的性能和宿主 – GPU 互連帶寬。
| CPU | Compiler | SIMD | Time (sec) |
| AMD TR 3975WX | ICC | AVX2 | 1.32 |
| AMD TR 3975WX | ICC | SSE2 | 2.89 |
| 1x Ampere Alta | ArmClang | NEON | 1.35 |
| 2x ThunderX2 | ArmClang | NEON | 3.02 |
| A64FX | ArmClang | SVE | 4.15 |
| A64FX | ArmClang | NEON | 13.89 |
| 2x POWER9 | ArmClang | VSX | 6.43 |
qmcp 包
QMCPACK 是一個開源、高性能的量子蒙特卡羅( QMC )軟件包,使用多種統計方法解決多體薛定諤方程。可以系統地測試和減少 QMC 中所做的幾個近似值,與密度泛函理論等更廣泛使用的方法相比,這可能會使預測中的不確定性得到量化,但會犧牲大量的計算費用。
應用包括弱結合分子、二維納米材料和固態材料,如金屬、半導體和絕緣體。
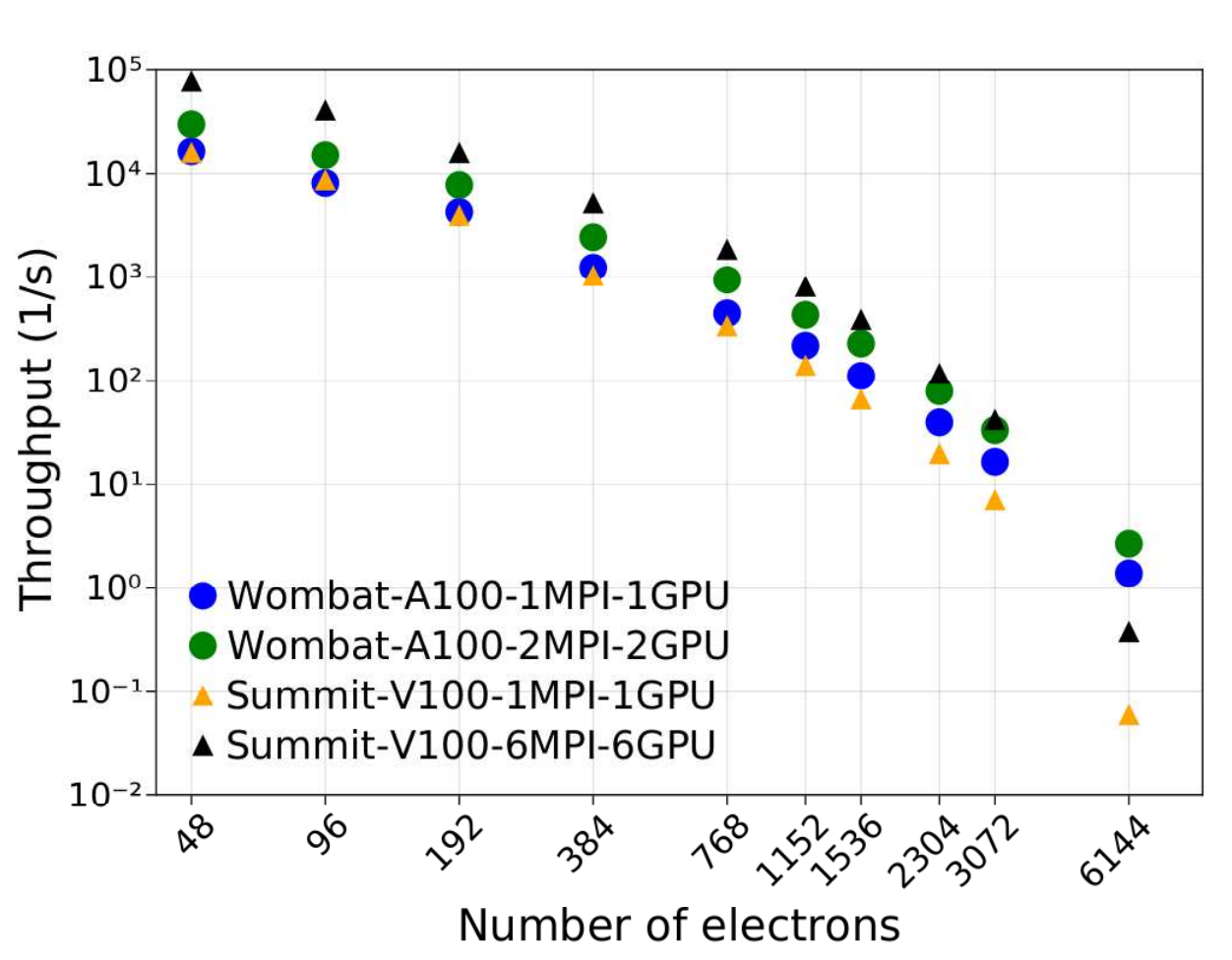
如圖 2 所示,在 Wombat 上運行的單個 A100 GPU 的性能優于 V100 ,幾乎所有問題大小的吞吐量都顯著提高。 Wombat 的 A100 2 GPU 在最大和最具計算挑戰性的情況下性能顯著提高。對于這些系統大小,更大的 GPU 內存是提高性能的最重要因素。
NVIDIA Arm HPC 開發套件評估結果
作為 Wombat 集群的一部分,與 NVIDIA Arm HPC Developer Kit 合作的研究團隊表示,“在我們部署包含 NVIDIA V GPU 的 Wombat 測試臺節點時,我們發現通過 Arm Server Ready 固件操作系統、軟件、庫和最終用戶包的跨堆棧貢獻,通用集群設置變得更容易。”
他們補充道:“本研究中測試的許多 GPU 加速應用程序的大部分性能來自為 GPU 架構優化的應用程序內核。”。“這并不能否定測試新 Arm 和 GPU 平臺的重要性。我們注意到,最大的限制似乎與有限的 GPU 內存大小以及用于遷移和保存 GPU 加速器附近數據的機制有關。”
NVIDIA Grace Hopper 系統之路
NVIDIA Arm HPC Developer Kit 旨在為客戶提供一個穩定的硬件和軟件平臺,用于 Arm 生態系統中加速 HPC 、 AI 和科學計算應用程序的開發和性能分析。 NVIDIA Grace Hopper Superchip 將 72 臂 Neoverse V2 CPU 內核的極高單線程性能與下一代 NVIDIA Hopper H100 GPU 相結合,為 HPC 和 AI 應用提供無與倫比的性能。 NVIDIA Grace Hopper Superchip 創新之處在于通過 NVLink-C2C 將 CPU 連接到 GPU ,這比 PCIe Gen5 快 7 倍,并通過 LPDDR5X 和 HBM3 內存支持 3.5 TB / s 的內存帶寬。
NVIDIA Grace Hopper Superchip 已經被領先的 HPC 客戶采用,包括瑞士國家超級計算中心( CSCS )、洛斯阿拉莫斯國家實驗室( LANL )和阿卜杜拉國王科技大學( KAUST )。
基于 NVIDIA Grace Hopper Superchip 的系統將于 2023 年上半年從領先的原始設備制造商處獲得。有興趣率先將應用程序遷移到 Arm 生態系統的客戶仍可從 Gigabyte Systems 購買 NVIDIA Arm HPC Developer Kit 。
要了解更多有關 NVIDIA Grace Hopper 架構如何提供下一代性能和易于編程的信息,請參閱 NVIDIA Grace Hopper Superchip Architecture whitepaper 。
?





