Machine learning ( ML )越來越多地用于各個行業。欺詐檢測、需求感知和信貸承銷是特定用例的幾個示例。
這些機器學習模型做出影響日常生活的決策。因此,模型預測必須公平、無偏見、無歧視。在透明度和信任至關重要的高風險應用程序中,準確的預測至關重要。
確保 AI 公平性的一種方法是分析從機器學習模型獲得的預測。這暴露了差異,并提供了采取糾正措施診斷和糾正根本原因的機會。
Explainable AI (XAI) 是一個負責任的人工智能領域,致力于研究解釋機器學習模型如何進行預測的技術。這些解釋是人類可以理解的,使所有利益相關者能夠理解模型的輸出并做出必要的決策。 SHAP 是一種在工業中廣泛使用的評估和解釋模型預測的技術。
這篇文章解釋了如何訓練 XGBoost 模型,如何使用 CPU 和 GPU 在 Python 中實現 SHAP 技術,最后比較兩者的結果。在文章結束時,您應該能夠回答以下問題:
- 為什么解釋機器學習模型至關重要,特別是在高風險決策中?
- 我們如何區分可解釋技術和可解釋技術?
- 什么是 SHAP 技術,它是如何用來解釋模型的預測的?
- GPU 加速 SHAP 的優勢是什么?
可解釋性與可譯性
在人工智能和機器學習的背景下,區分可解釋性和可譯性很有幫助。這些術語具有不同的含義,但經常互換使用。
在開創性的論文 Psychological Foundations of Explainability and Interpretability in Artificial Intelligence 中,美國國家標準與技術研究院( NIST )的研究人員提出了以下解釋性和可解釋性的定義:
可解釋性
可解釋性是一種低級、詳細的心理表征,旨在描述一些復雜的過程。解釋描述了一些模型機制或輸出是如何產生的。
可譯性
可解釋性是一種高層次、有意義的心理表征,它將刺激情境化,并利用人類背景知識。可解釋的模型應該為用戶提供數據點或模型輸出在上下文中的含義的描述。
此外,根據 Explanation in Artificial Intelligence: Insights from the Social Sciences, ,可解釋性是指人類能夠理解和信任 ML 模型預測的程度。
解釋方法概述
解釋模型預測的方法可大致分為 model-specific 和 post-hoc 技術 .
特定于型號
廣義線性模型、決策樹和廣義可加模型等算法都是可解釋的。這些模型被稱為“玻璃盒模型”,因為可以跟蹤和推斷預測是如何做出的。用于解釋此類模型的技術是 model-specific ,因為每種方法都基于特定模型的內部結構。例如,對線性模型中權重的解釋會影響 model-specific explanations 。
后 hoc
顧名思義,事后解釋技術是在模型經過訓練后應用的。一些著名的事后技術包括 SHAP 、 LIME 和[VZX 42]。這些是不確定模型的。他們將模型視為 BlackBox ,并假設他們只能訪問模型的輸入和輸出。這使得它們有利于復雜算法,如增強樹和深度神經網絡,這些算法無法通過特定于模型的技術進行解釋。
這篇文章主要關注 SHAP ,一種解釋模型預測的事后技術。
使用 SHAP 技術解釋模型
SHAP 是 SHapley Additive Explanations 的縮寫。它是最常用的事后解釋技術之一。 SHAP 利用合作博弈理論 的概念分解預測,以衡量每個特征對預測的影響。
Shapley 值定義為特征值在所有可能的特征聯盟中的平均邊際貢獻。沙普利價值觀是一種起源于經濟學和博弈論的技術,它根據參與者對總收益的貢獻,為聯盟中的參與者分配公平的報酬。將其轉化為機器學習場景意味著根據特征對模型預測的貢獻來為模型中的特征分配重要性。
SHAP unifies 使用 Shapley 值生成準確的局部特征重要性值的幾種方法,然后可以對這些值進行聚合以獲得全局解釋。 SHAP 值解釋了具有特定值的給定特征對模型預測的影響,與我們在該特征采用某個基線值時所做的預測相比。基線值是模型在沒有任何特征值信息的情況下預測的值。
SHAP 是用于計算特征屬性的最廣泛的事后解釋技術之一。它不依賴于模型,可以作為一種局部和全局特征屬性技術使用,并有可靠的經濟學理論支持。此外,基于樹的模型的 SHAP 變體大大減少了計算時間,從而幫助用戶快速從模型中獲得見解。
以下部分提供了如何使用 SHAP 技術的示例。
步驟 1 :訓練 XGBoost 模型并計算 SHAP 值
使用眾所周知的 Adult Income Dataset 執行以下操作:
- 根據給定的數據集訓練 XGBoost 模型,預測一個人的年收入是否超過 5 萬美元。此類數據在目標營銷等各種用例中都很有用。
- 計算 SHAP 值以解釋各個特征的貢獻。
- 可視化并解釋 SHAP 值。
安裝
可以使用 GitHub 上提供的名為 shap 的獨立 Python 軟件包安裝 SHAP :
pip install shap
or
conda install -c conda-forge shapSHAP 本身也受到流行算法(如 LightGBM 和 XGBoost )以及幾個 R 包的支持。
設置環境
首先設置環境并導入必要的庫:
import numpy as np
import pandas as pd
# Visualization Libraries
import matplotlib.pyplot as plt
%matplotlib inline
## Machine learning packages
from sklearn.model_selection import train_test_split
import xgboost as xgb
## Model Interpretation package
import shap
shap.initjs()
# Ensuring Reproducibility
SEED = 12345
# Ignoring the warnings
import warnings
warnings.filterwarnings(action = "ignore")數據集
此數據集來自 UCI Machine Learning Repository Irvine ,可在 Kaggle 上使用。它包含基于人口普查數據的 人口統計信息。數據集具有諸如教育程度、每周工作時間、年齡等屬性。
shap 庫附帶了一些常用的數據集,包括下面使用的成人收入數據集的預處理版本。
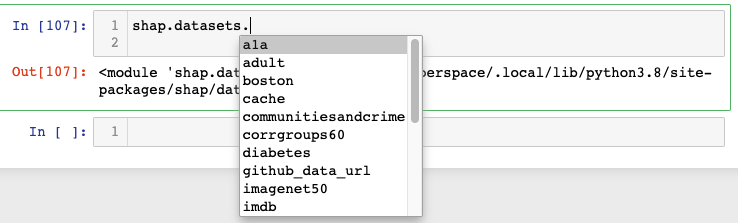
X,y = shap.datasets.adult()
X_view,y_view = shap.datasets.adult(display=True)
X_view.head()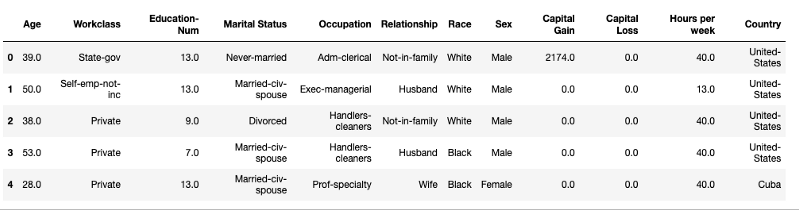
如上所示,數據集由各種預測變量(如年齡、工作級別和教育程度)以及一個目標變量組成。如果一個人年收入> 5 萬美元,目標變量為True;如果年收入為≤$ 50 公里。在確保數據集經過預處理和清理后,繼續進行模型訓練。
訓練 XGBoost 模型
XGBoost 在表格數據集方面表現出色,在機器學習社區中非常流行。首先,將數據集拆分為訓練集和驗證集。
# create a train/test split
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=7)接下來,根據 5K 助推回合的訓練數據訓練 XGBoost 模型。
# read in the split dataset into an optimized data structure called Dmatrix required by XGBoost
dtrain = xgb.DMatrix(X_train, label=y_train)
dvalid = xgb.DMatrix(X_valid, label=y_valid)
%%time
# Feed the model the global bias
base_score = np.mean(y_train)
#Set hyperparameters for model training
params = {
'objective': 'binary:logistic',
'eval_metric': 'logloss',
'eta': 0.01,
'subsample': 0.5,
'colsample_bytree': 0.8,
'max_depth': 5,
'base_score': base_score,
'seed': SEED
}
# Train using early stopping on the validation dataset.
watchlist = [(dtrain, 'X_train'), (dvalid, 'X_test')]
model = xgb.train(params,
dtrain,
num_boost_round=5000,
evals=watchlist,
early_stopping_rounds=20,
verbose_eval=100)
===============================================================
Wall time: 14.3 s在 Apple M1 8 核 CPU 上執行訓練需要 14.3 秒,并啟用了提前停止功能。
有關 XGBoost 模塊內可配置參數的更多信息,請參閱 XGBoost Parameters 。
計算 SHAP 值
根據算法的性質, SHAP 有許多不同的風格。最流行的似乎是 KernelSHAP 、 DeepSHAP 和 TreeSHAP 。雖然 KernelSHAP 與模型無關,但 TreeSHAP 僅適用于基于樹的模型(包括我們剛剛培訓的 XGBoost 模型)。使用 shap 庫中的 TreeExplainer 類解釋包含超過 30K 個樣本和超過 1000 棵樹的整個數據集。
%%time
explainer = shap.TreeExplainer(model=model)
shap_values = explainer.shap_values(X)
================================================================
CPU times: user 4min 12s, sys: 116 ms, total: 4min 12s
Wall time: 1min 4s
使用上述相同的硬件,在 1.4 分鐘內計算出 SHAP 值。請注意將它們與下一秒獲得的值進行比較的時間。既然已經確定了 SHAP 值,下一步就是解釋。為了理解這些值, shap 提供了幾種不同類型的可視化,如力圖、匯總圖、決策圖等,每種圖都突出了模型的特定方面。下面包括兩個圖。
SHAP 力圖
力圖用于解釋數據集中的單個實例。為訓練集中的第一行生成力圖,并查看不同特征如何影響預測。首先打印此數據實例的地面真相標簽和模型預測。
classes = {0 : 'False', 1: 'True'}
# ground truth label
y[0]
=========================
False
# Model Prediction
y_pred = [round(value) for value in model.predict(dvalid)]
classes[y_pred[0]]
==========================================================
False
此人的基本真相標簽為 False ;也就是說,這個人賺了≤$每年 5 萬。該模型也預測了同樣的情況。圖 2 顯示了同一個人的力量圖,深入了解了各種特征是如何對模型的預測做出貢獻的。
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[0,:],X.iloc[0,:])
此處的 base _ value 為– 1.143 ,而所選樣本的目標值為– 3.89 。所有大于基本值的值都有收益≥$ 50K ,反之亦然。對于所選的樣本,圖 2 中顯示為紅色的特征將預測推到基礎值,而藍色的特征則將預測推離基礎值。因此,可以推斷,擁有 2174 的資本收益和 0 的關系狀態會對該模型對該特定個人收入> 5 萬美元的預測產生負面影響。
SHAP 匯總圖
上一節討論了 SHAP 如何提供局部解釋,或針對單個預測的解釋。可以聚合這些值,以了解全局視圖。一種方法是使用 SHAP summary plots .
SHAP 匯總圖概述了哪些功能對模型更重要。這可以通過為數據集中的每個樣本繪制每個特征的 SHAP 值來實現。圖 3 描述了一個匯總圖,其中圖中的每個點對應于數據集中的一行。
shap.summary_plot(shap_values_gpu, X_test)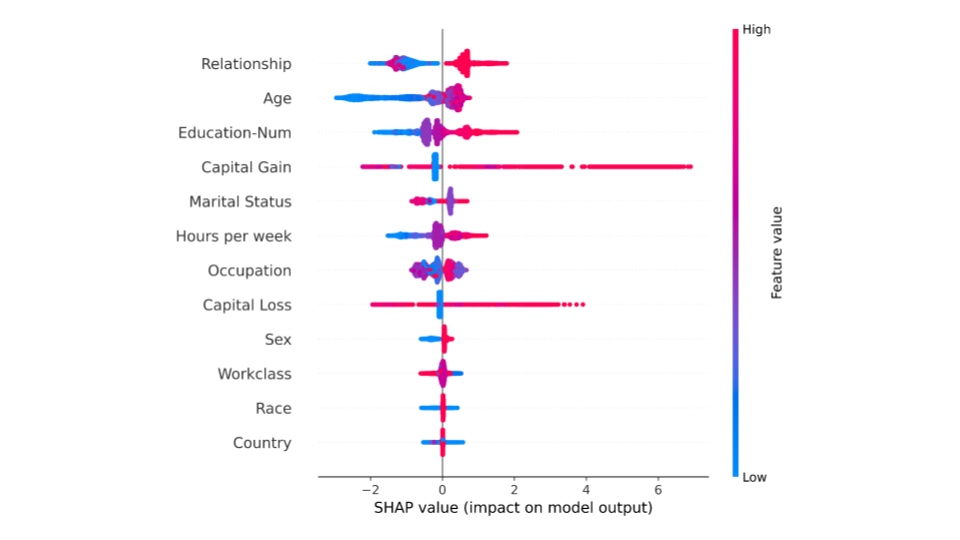
圖 3 中的每個點表示原始數據集中的一行。對于每個點:
- y 軸按重要性從上到下的順序指示特征。 x 軸指的是實際的 SHAP 值。
- 點的水平位置表示特征對該特定樣本的模型預測的影響。
- 顏色顯示數據集任何行的特征值是高(紅色)還是低(藍色)。
從總結圖可以推斷,與其他特征相比,“關系狀態”和“年齡”對預測一個人是否會獲得更高收入具有更高的總模型影響。
步驟 2 : GPU 加速 SHAP
如前一節所述, TreeSHAP 是專門為樹集成模型定制的 SHAP 版本。雖然 TreeSHAP 相對較快,但當集合大小變得太大時,它也可能面臨典型的計算問題。在這種情況下,建議利用 GPU 加速來加快過程。
然而, TreeSHAP 算法的復雜性導致難以映射到硬件加速器。這導致了 GPUTreeShap 的開發,這是適合與 GPU 一起使用的 TreeSHAP 算法的變體。現在可以在計算 SHAP 值時利用 GPU 硬件,從而加快整個模型解釋過程。
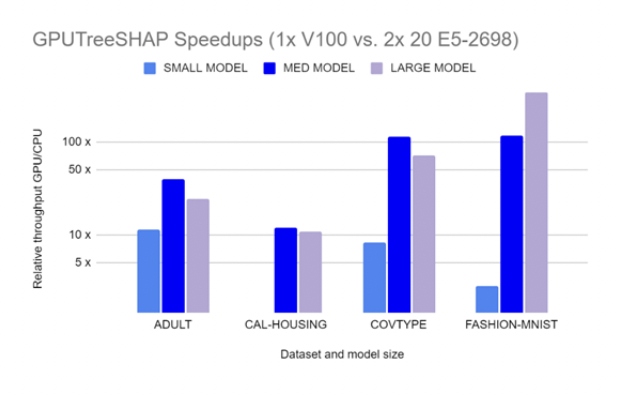
GPUTreeShap enables massively exact calculation of the shape values for tree-based algorithms. 圖 4 顯示了 GPUTreeSHAP 如何提供在 CPU 上使用帶有 GPU 的 SHAP 時獲得的增益估計。根據 GPUTreeShap: Massively Parallel Exact Calculation of SHAP Scores for Tree Ensembles ,“通過單個 NVIDIA Tesla V100-32 GPU ,在兩個 20 核 Xeon E5-2698 v4 2.2 GHz CPU 上執行的最先進的多核 CPU 實現上,我們實現了 SHAP 值最高 19 倍的加速, SHAP 交互值最高 340 倍的加速。我們還使用八個 V100 GPU 進行了多 GPU 計算實驗,顯示每秒 1.2M 行的吞吐量–基于 CPU 的等效性能估計需要 6850 CPU 個內核。”
安裝
GPUTreeShap 已與 Python shap package 集成。訪問 GPUTreeShap 的另一種方法是安裝 RAPIDS 數據科學框架。這確保了可以訪問 GPUTreeShap 和許多不同的庫,以便完全在 GPU 中執行端到端的數據科學管道。
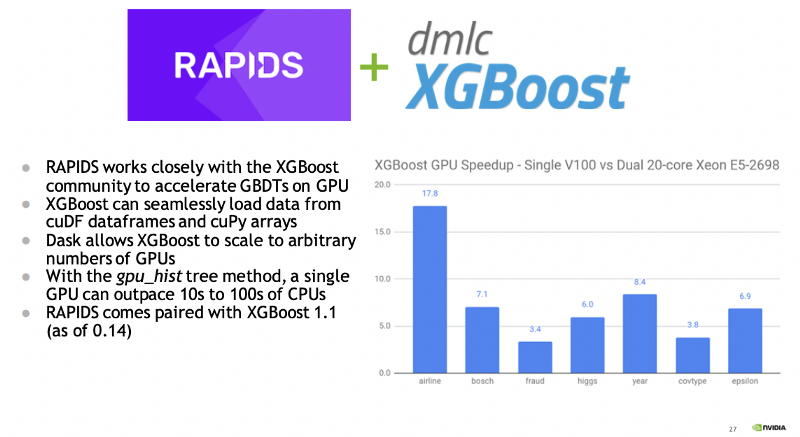
RAPIDS 也有 integrated with XGBoost (從 0.14 開始)。事實上, XGBoost 是在最終成為 RAPIDS 生態系統的情況下加速的第一個流行的 ML 工具包。圖 5 突出顯示了 GPU 上的 XGBoost 加速,將單個 V100 GPU 與雙 20 核 CPU 進行了比較。
開發人員可以利用 RAPIDS 對 XGBoost 和 SHAP 值的 GPU 加速。默認的開源 XGBoost 包已經包含支持 GPU CUDA 的 GPU 支持。
使用 GPU 加速訓練 XGBoost 車型
上一節演示了誰在成人收入數據集上訓練 XGBoost 模型。本節重復使用 GPU 加速啟用的相同過程。這需要更改名為tree_method的單個參數的值,并大幅減少計算時間。
將tree_method參數指定為gpu_hist,保持所有其他參數不變。
%%time
# Feed the model the global bias
base_score = np.mean(y_train)
#Set hyperparameters for model training
params = {
'objective': 'binary:logistic',
'eval_metric': 'logloss',
'eta': 0.01,
'subsample': 0.5,
'colsample_bytree': 0.8,
'max_depth': 5,
'base_score': base_score,
'tree_method': "gpu_hist", # GPU accelerated training
'seed': SEED
}
# Train using early stopping on the validation dataset.
watchlist = [(dtrain, 'X_train'), (dvalid, 'X_test')]
model_gpu = xgb.train(params,
dtrain,
num_boost_round=5000,
evals=watchlist,
early_stopping_rounds=10,
verbose_eval=100)
=============================================================
CPU times: user 2.43 s, sys: 484 ms, total: 2.91 s
Wall time: 3.27 s使用單個 Tesla T4 GPU (通過 Google Colab 提供)訓練 XGBoost 車型有助于將訓練時間從 14.3 秒減少到 3.27 秒。減少計算時間是有益的,因為訓練機器學習模型,特別是在大型數據集上,既有挑戰性,又很昂貴。
使用 GPU 計算 SHAP 值
當選擇 GPU 預測器時, XGBoost 將 GPUTreeShap 用作計算形狀值的后端。
%%time
model_gpu.set_param({"predictor": "gpu_predictor"})
explainer_gpu = shap.TreeExplainer(model=model_gpu)
shap_values_gpu = explainer_gpu.shap_values(X)
==========================================================
CPU times: user 1.34 s, sys: 252 ms, total: 1.59 s
Wall time: 1.56 s
使用 GPU ,計算 Shapley 值的計算時間從 1.4 分鐘減少到 1.56 秒,大大減少了計算時間。當數據集涉及數百萬個數據點時,這種收益將更加顯著,這在許多行業都很常見。
總結
SHAP 等技術可以使機器學習系統更加可靠。如果一個模型可以被忠實地解釋,那么可以對其進行分析,以確定它是否適合部署。這是向灌輸對任何技術的信任邁出的重要一步。使用 GPU 加速,可以更快地計算 SHAP 值,從而更快地了解預測模型。
然而, SHAP 并不是萬能的,它有自己的局限性。對 SHAP 的主要批評是它可能被誤解。 SHAP 基本上有助于回答為什么特定觀測值接收到預測而不是基線值的問題。該基線值由背景數據集的選擇決定,如果參考數據集發生變化,則可以提供對比結果。
因此,根據背景數據集的選擇,相同的觀察可能會導致不同的 SHAP 值。因此,重要的是要仔細、適當地 選擇背景數據集?記住它們的使用背景。理解機器學習中與可解釋性技術相關的假設和權衡非常重要。
要查看本文中使用的代碼,請訪問 GitHub 上的 parulnith/Data-Science-Articles 。
?