AI是一種編寫軟件的新方法, AI 推理正在運行該軟件。 AI machine learning正在解鎖各種領域的突破性應用,如在線產品推薦、圖像分類、聊天機器人、預測、制造質量檢查等。構建一個用于產生式推理的平臺是非常困難的。原因如下。
應用
應用程序有不同的需求,需要根據用戶的需求進行不同的優化。
- 有些人希望連續處理來自攝像頭或麥克風等傳感器的流式數據。
- 有些人希望以最低的成本優化吞吐量,比如處理衛星圖像以創建高保真地圖。
- 有些需要實時響應,比如對話式 AI 聊天機器人。
模型類型
不同的用例利用不同的模型類型,這會生成非常不同的計算圖,為了獲得最佳性能,應該對這些圖進行編譯。一些流行的模型類型有卷積神經網絡( CNN )、遞歸神經網絡( RNN )、 transformers 、決策樹、隨機森林和圖形神經網絡。
框架
模型在不同的框架中進行訓練 并且有不同的格式–TensorFlow, PyTorch、 TensorRT 、 ONNX 、MXNet和XGBoost等等。
人工智能平臺
應用程序運行在許多應用程序之上 不同的人工智能平臺——國產平臺,如 Cloudera 或 Domino Data Labor ,或公共云 ML 平臺,如 Amazon SageMaker 、 Azure ML 或 Google Vertex 人工智能。
計算處理器
選擇計算處理器是漫長旅程的下一步。 GPU 和 CPU 有不同的版本。在裸機或虛擬機上運行模型是另一個考慮因素。
部署環境
推理部署環境可能因應用程序而異—公共云、內部部署核心(數據中心)、企業邊緣和嵌入式設備。
一個給定的推理平臺應該考慮所有前面的因素,這就是為什么構建一個高效的高性能平臺是困難的。
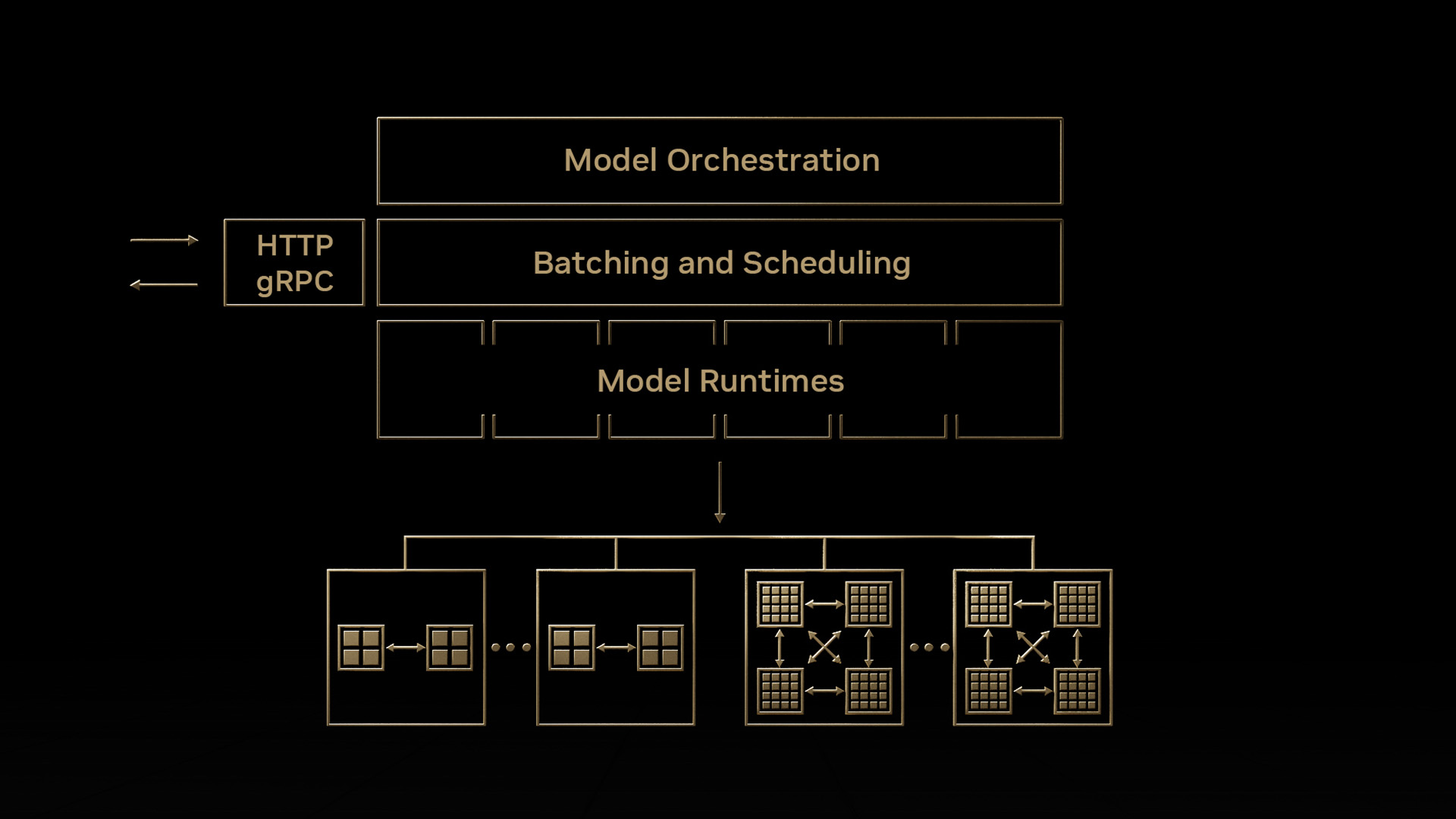
NVIDIA Triton 推理服務器
NVIDIA Triton Inference Server是一款開源推理服務軟件,用于應用程序中的快速可擴展 AI 。它可以幫助滿足推理平臺前面的許多考慮。下面是這些功能的摘要。有關更多信息,請參閱Triton Inference Server在 GitHub 上閱讀我的文章。
- NVIDIA Triton 可用于部署來自所有流行框架的模型。它支持 TensorFlow 1 和 x 、 PyTorch 、 ONNX 、 TensorRT 、 RAPIDS FIL (對于 XGBOOST 、Scikit-learn Random Forest、 LITGBM )、 OpenVIO 、 Python ,甚至自定義 C ++后端。
- NVIDIA Triton 優化了多種查詢類型的推理——實時、批處理、流式,還支持模型集成。
- 支持 NVIDIA GPU s 和 x86 & ARM CPU s 上的高性能推斷。
- 在云計算或數據中心、企業邊緣運行,甚至在嵌入式設備上運行,比如 NVIDIA Triton 。它支持 AI 推理的裸金屬和虛擬化環境(例如 VMware VSCOPE )。在 Windows 、 Jetson 和 Jetson SBSA 上運行專用的 NVIDIA Triton 版本。
- Kubernetes 和 AI 平臺支持:
- 它可以作為 Docker 容器提供,并且可以輕松地與Kubernetes平臺集成,如 AWS EKS 、谷歌 GKE 、 Azure AKS 、阿里巴巴 ACK 、騰訊 TKE 或紅帽 OpenShift 。
- NVIDIA Triton 在托管云 AI 工作流平臺中可用,如 Amazon SageMaker 、 Azure ML 、 Google Vertex AI 、阿里巴巴 AI 彈性算法服務平臺和騰訊 TI-EMS 。
并行執行
GPU 是能夠同時執行多個工作負載的計算引擎。 NVIDIA Triton 推理服務器通過在 GPU 上同時運行多個模型,最大限度地提高性能并減少端到端延遲。這些模型可以是相同的,也可以是來自不同框架的不同模型。 GPU 內存大小是對可同時運行的型號數量的唯一限制。這導致 GPU 利用率和吞吐量較高。
動態配料
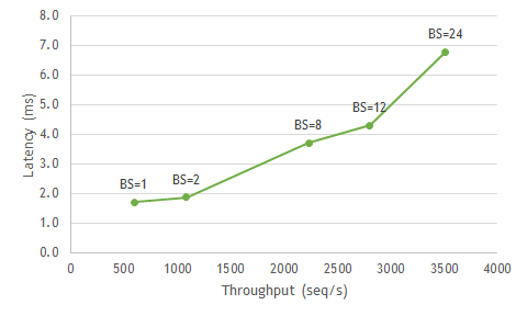
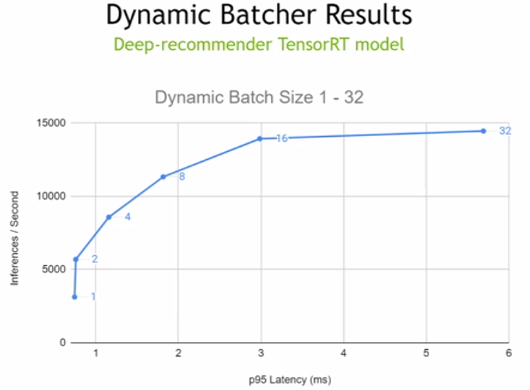
推理優化的一個因素是批量大小,即您一次處理的樣本數量。 GPU 以更大的批量提供高吞吐量。然而,對于實時應用程序,服務的真正限制不是批量大小,甚至不是吞吐量,而是為最終客戶提供卓越體驗所需的延遲。下面是一個簡單的例子。對于智能揚聲器網絡,管道 NLP 部分使用的 BERT 模型的最大延遲必須為 7 毫秒或更短,才能提供出色的體驗。現在,如果您查看圖 1 ,您可以看到,為了保持< 7ms 的延遲閾值,您可以運行到批大小 24 ,以滿足您的目標延遲并最大化吞吐量。
在生產環境中運行推理時,有兩種類型的批處理:客戶端(靜態)和服務器端(動態)。通常,當客戶機向服務器發送請求時,默認情況下服務器將按順序處理每個請求,這對于吞吐量來說不是最優的。
在大規模實現推理時,開發人員可能希望平衡延遲和吞吐量目標,以滿足其應用程序的要求。圖 4 顯示了如何通過使用 NVIDIA Triton 推理服務器的動態批處理來平衡這些優先級。隨著獨立推斷請求進入服務器, NVIDIA Triton 將在服務器端動態地將客戶端請求分組在一起,形成一個更大的批。 Triton 可以將此批處理管理到指定的延遲目標,從而在指定的延遲目標內實現吞吐量最大化的平衡。 NVIDIA Triton 自動管理此任務,因此您不必在客戶端對代碼進行任何更改。
例如,八個不同的設備可能同時有一個圖像搜索請求,但 NVIDIA Triton 能夠將它們全部批處理在一起,以便對 GPU 進行單個查詢,從而提高吞吐量,而不是對每個順序請求執行推斷,并且仍然以低延遲交付結果。
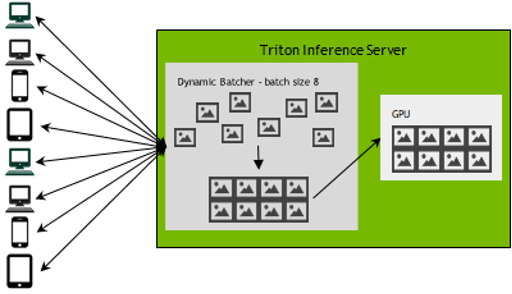
要了解這在實踐中是如何工作的,請查看下面圖 5 中的示例。該行顯示給定模型在不同批量大小下的延遲和吞吐量。如果向用戶提供良好體驗的延遲閾值為 3ms ,則可以將動態批處理設置為 16 ,并滿足延遲目標,同時獲得比以批處理大小 1 運行時 3 倍以上的性能。此示例顯示了 Triton 如何幫助管理批量大小和吞吐量以滿足需求,而不依賴批量大小來管理您的服務。
總之, NVIDIA Triton 的動態批處理功能可以在嚴格的延遲限制下大幅提高吞吐量,從而提供 GPU 的高性能和利用率。
現在讓我們看看 NVIDIA Triton 最近添加的一些功能。
模型分析器
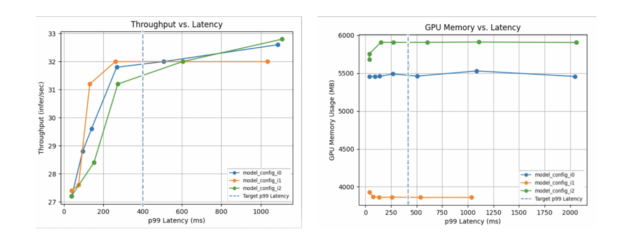
為了有效地提供推理服務,應該為給定的處理器確定最佳的模型配置,例如批量大小和并發模型實例的數量。如今,用戶手動嘗試不同的(有時是數百種)組合,以最終找到適合其吞吐量、延遲和內存利用率要求的最佳配置。 NVIDIA Triton Model Analyzer 是一種優化工具,通過自動找到模型的最佳配置,為用戶自動進行選擇,以獲得最高性能。用戶可以指定性能要求(例如延遲約束、吞吐量目標或內存占用),模型分析器將搜索不同的配置(批量大小、并發模型實例等),并找到在其約束下提供最佳性能的配置。然后,它將輸出一個摘要報告,其中包括如下所示的圖表,以幫助可視化頂級配置的性能。例如:可以在 GitHub repo :https://github.com/triton-inference-server/model_analyzer中找到文檔和示例。
多 – GPU 多節點推理
NLP 模型的規模呈指數增長(每 2 . 5 個月翻一番)。例如, 2020 年初推出的 NVIDIA Turing NLG ( 17B 參數)應至少具有 34G 的 GPU 內存, 2020 年中期推出的 GPT-3 ( 175B 參數)應至少具有 350G 的 GPU 內存,最新的 Megatron NVIDIA Turing NLG ( 530B 參數)模型應具有> 1TB 的 GPU 內存。這些大型 transformer 型號無法裝入單個 GPU 中。
對于這些非常大的 transformer 模型, NVIDIA Triton 引入了多 GPU 多節點推理。它使用以下模型并行技術在多個 GPU 和節點上拆分大型模型:
- 管道(層間)并行,將連續的層集分割到多個 GPU 上。這將最大限度地提高單節點中的 GPU 利用率。
- 張量(層內)平行性,將各個層分割到多個 GPU s 。這可以最大限度地減少單個節點中的延遲。
它在 Magnum IO 中使用 NCCL 進行拓撲感知通信,以實現高吞吐量。
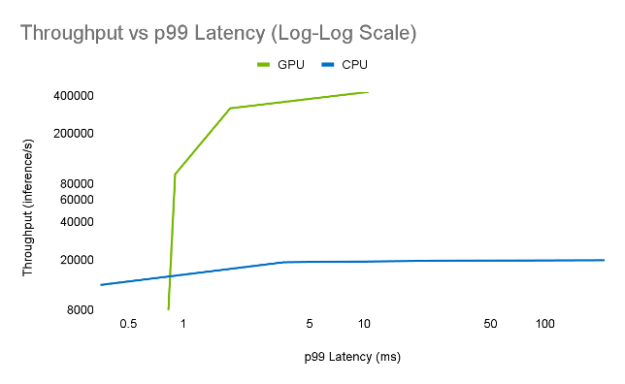
實時推理性能需要多 CPU 推理。以下是在 GPU 和 CPU 純服務器上運行 Megatron 圖靈 NLG ( 530B )模型的比較。配置為–第 1 批查詢,輸入序列長度= 128 個令牌(平均 102 個字),輸出序列長度= 8 個令牌(平均 6 個字)
- GPU :約半秒使用張量和管道并行性– 2 DGX-A100-80GB ,批量大小= 1 , FP16 ,速度更快 transformer 4 . 0 , Triton 2 . 15 。
- CPU :> 1 分鐘–至強鉑金 8280 2S ,最多 1TB /插槽系統內存,批量大小= 1 , FP32 , TensorFlow 。
在兩臺 DGX 上, Megatron NVIDIA Turing NLG 模型可以每半秒傳輸八個輸出令牌(六個字),以減少實時對話的顯示或講話延遲。正如我們所看到的,如此大的模型應該具備 GPU 系統的強大功能,才具有實用性。許多 GPU 系統,如 DGX ,使用 NVLink 進行高性能節點內通信,使用 Infiniband / Ethernet 進行節點間通信。
新的 RAPIDS 林推理庫后端
NVIDIA Triton 包括 RAPIDS ( FIL )作為 XGBoost 、 LightGBM 和 ScikitLearn 隨機林模型 GPU 或 CPU 推斷的后端。? 通過 FIL 集成, NVIDIA Triton 現在是深度學習和傳統機器學習工作負載的統一部署引擎。?
樹模型( XGBoost 、 Random Forest 、 LightGBM )無處不在——特別是在金融和推薦系統中——但支持deep -learning模型的軟件包很少支持樹模型推理。在實踐中,許多應用程序(尤其是推薦系統)使用樹模型和 DL 模型的集合,并且需要工具來支持大規模對這些集合的推理。對于盡可能頻繁地針對所有可用產品對所有客戶重新評分或針對多個欺詐模型對每個全球信用卡交易評分等用例, FIL 后端提供了高度優化的解決方案。
雖然其他樹模型部署解決方案通常需要將模型轉換為 ONNX 等專用格式,但 FIL 后端允許用戶根據培訓部署 XGBoost 和 LightGBM 模型。此外, FIL 的 GPU – 加速推理意味著用戶不再需要在小型模型上妥協以滿足緊迫的延遲目標。相反,他們可以利用巨大的集成,在不影響延遲預算的情況下,提供更高的靈敏度,例如欺詐檢測。
具有 FIL 后端的 NVIDIA Triton 支持 GPU 加速推理,即使是最大的樹模型也可用于低延遲應用程序,從而提高欺詐檢測、推薦系統等的準確性。在 GPU 和 CPU 上都可以對 XGBoost 、 LightGBM 的非分類特征、 cuML / Scikit 學習隨機森林的單輸出回歸和二元分類進行推理。 LightGBM 機型的分類功能支持即將推出。
新的 Amazon SageMaker 集成
NVIDIA Triton 推理服務器現已在 Amazon SageMaker 中進行本機集成和提供。 AWS 和 NVIDIA 密切合作,提供這一功能,為客戶提供 NVIDIA Triton 在 SageMaker 方面的優勢。Amazon SageMaker是一項針對數據科學和機器學習( ML )工作流的全面管理服務。現在, NVIDIA Triton 推理服務器可用于為 Amazon SageMaker 中的推理模型提供服務,并受益于 NVIDIA Triton 提供的性能優化、動態批處理和多框架支持。它采取兩個步驟:
- 在 Amazon S3 中創建 Triton 模型 repo 和配置。
- 創建 SageMaker NVIDIA Triton 端點并部署。
欲了解更多信息,請閱讀本帖。 NVIDIA Triton 推理服務器容器可在 Amazon SageMaker 可用的所有地區使用,且無需額外費用。
NVIDIA Triton 可用于所有主要云服務提供商, AWS 、谷歌云、 Microsoft Azure 、阿里云和騰訊云,以及托管 Kubernetes 和 AI 平臺服務。
客戶成功案例
讓我們來看看英偉達 Triton 的一些新客戶成功案例:
- 微軟團隊
- Microsoft Azure 認知服務將 GPU 上的 Triton 用于 Microsoft 團隊中的 ASR ,用于實時字幕和轉錄。有關詳細信息,請閱讀post。
- 西門子能源公司
- 西門子能源公司使用 NVIDIA Triton 實現發電廠的自主運行。 NVIDIA Triton 推理服務器提供的計算機視覺模型可檢測泄漏和其他異常情況。有關更多詳細信息,請閱讀post。
結論
NVIDIA Triton 在每個數據中心、云和嵌入式設備中提供標準化的可擴展生產AI。它支持多個框架,在 CPU 和 GPU 上運行模型,處理不同類型的推理查詢,并與Kubernetes和MLOPs平臺集成。今天從NGC下載NVIDIA Triton 作為Docker容器,并在open source github上查找文檔。此外,訪問 NVIDIA Triton了解更多信息。