
基于 AI 的計算機視覺 (CV) 應用程序不斷增加,對于從視頻源中提取實時見解尤為重要。這項革命性的技術使您能夠解鎖在沒有重大操作人員干預的情況下無法獲得的寶貴信息,并為創新和解決問題提供新的機會。
NVIDIA DeepStream SDK 旨在為智能視頻分析 (IVA) 用例提供從視頻流中提取見解的能力,利用機器學習 (ML) 技術。在 NVIDIA 硬件上運行時,DeepStream 利用 GPU 加速和專為 ML 優化的加速硬件,以最大化提升預處理性能。
本文將探討如何結合使用 NVIDIA Omniverse 和 Edge Impulse,利用 NVIDIA DeepStream SDK 進行模型開發和部署,以便您可以快速創建端到端應用。Edge Impulse 是 NVIDIA 初創加速計劃的一部分。
計算機視覺應用
在當今環境中,快速構建復雜、可擴展的 CV 應用程序的能力至關重要。典型的 CV 應用程序包括各種用例,例如車輛識別、交通測量、檢查系統、生產線質量控制、通過監控增強安全和安保、智能結賬系統實施和流程測量。
集成機器智能以分析業務流程中的多媒體流可以增加巨大的價值。得益于無與倫比的準確性和可靠性,機器智能可以幫助簡化操作,從而提高效率。
預構建的 AI 模型并不總是合適的解決方案,通常需要針對預構建模型無法解釋的特定問題進行微調。
構建基于 AI 的 CV 應用程序通常需要具備以下三種技能組合的專業知識:MLOps、CV 應用程序開發和部署 (DevOps).如果沒有這些專業技能,項目投資回報率和交付時間表可能會面臨風險。
過去,復雜的 CV 應用程序需要高度專業的開發者。這轉化為漫長的學習曲線和昂貴的資源。
Edge Impulse 與 NVIDIA DeepStream SDK 的結合可提供用戶友好型互補解決方案堆棧,幫助開發者快速創建 IVA 解決方案。您可以針對特定用例輕松自定義應用程序,將 NVIDIA 硬件直接集成到您的解決方案中。
DeepStream 可免費使用,而 Edge Impulse 則提供適合許多 ML 模型構建用例的免費級別。
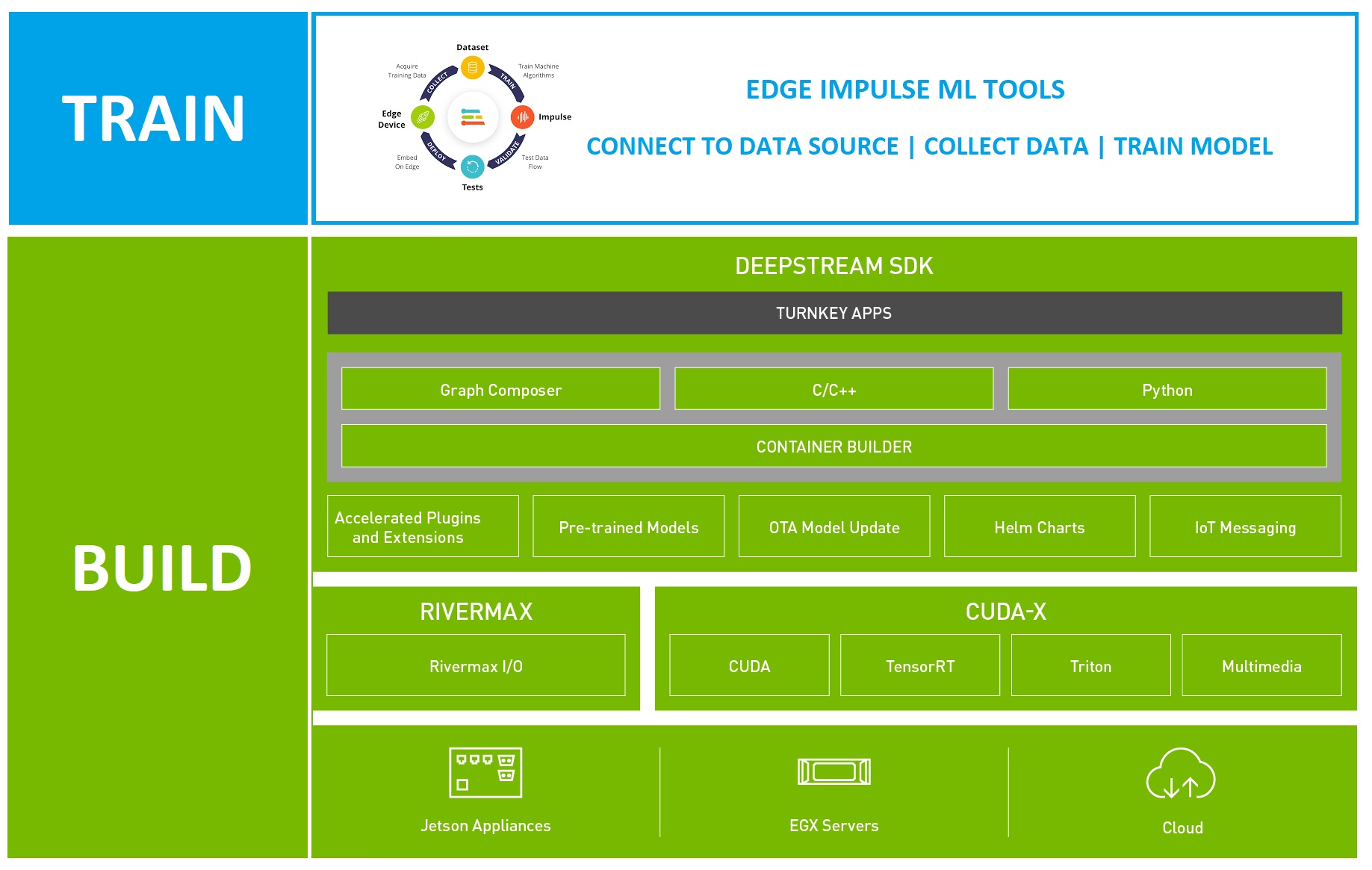
使用 NVIDIA DeepStream 構建 CV 應用
DeepStream SDK 是 NVIDIA Metropolis 項目的一部分,旨在支持大規模視頻分析。您可以快速且輕松地創建可直接部署在 NVIDIA 硬件設備上的生產就緒型計算機視覺 (CV) 流程。
DeepStream 應用使用以下方法構建:
- 在命令行中
- 以視覺方式使用 Graph Composer
- 如果沒有代碼,則使用 DeepStream 參考應用和配置文件
- 借助 C++或 Python 代碼實現更多自定義
如果您不是開發者,您可以在不到一小時的時間內使用前三個選項之一以及經過訓練的 ML 模型創建和運行工作流。如果您需要更多自定義,可以從現有模板構建自定義編碼解決方案作為起點。
部署 CV 應用
創建工作流后,您可以直接將其部署在 NVIDIA 硬件設備上,包括邊緣設備如 NVIDIA Jetson Nano,以及用于高性能計算 (HPC) 和云部署的設備,還有一種混合部署方法。
您可以部署應用程序,以便在 NVIDIA 邊緣硬件上本地運行,并直接連接視頻源,以盡可能降低延遲。如果您需要處理復雜的工作流或容納超過 NVIDIA 邊緣設備能力的多個視頻源,則可以將同一工作流部署到首選 IaaS 提供商上基于 NVIDIA 的云實例。
混合方法也是可行的,在這種方法中,管道可以部署到 NVIDIA 邊緣設備,并且可以使用 NVIDIA Triton 推理服務器。
Triton 支持遠程執行模型,從客戶端接收輸入幀并返回結果。Triton 在存在時利用 NVIDIA GPU,還可以在 x86 上執行推理,并支持并發和動態批處理。Triton 還原生支持大多數熱門框架,包括 TensorFlow 和 PyTorch.
DeepStream 通過名為 Gst-nvinfer 推理插件的替代方案 Gst – nvinferServer 來支持 Triton.此插件使您能夠在 DeepStream 應用程序中使用 Triton 實例。
IVA 應用的性能取決于其構建的 ML 模型。雖然有許多預構建模型可用,但用例通常需要自定義模型和 MLOps 工作流程。在這種情況下,易于使用的 MLOps 平臺可以實現快速部署,尤其是在與 DeepStream 快速應用開發相結合時。
適用于機器學習的 Edge Impulse
Edge Impulse 提供了一套強大的工具來構建 ML 模型,這些模型可以直接部署到 NVIDIA 目標上,然后放入 DeepStream 應用中。Edge Impulse 與 NVIDIA 硬件加速和 DeepStream SDK 無縫集成,可幫助您快速擴展項目。
在整個過程中,Edge Impulse 可為各個級別的開發者提供指導。經驗豐富的 ML 專業人員將欣賞從不同來源導入數據的簡便性和便利性,以及端到端模型構建過程。您還可以將自定義模型與自定義學習塊功能集成,從而擺脫 MLOps 的繁重任務。
對于機器學習新手,Edge Impulse 流程會指導您在使用環境時構建基本模型。您可以與 DeepStream 一起使用的基本模型類型是 YOLO 物體檢測和分類。
您還可以改變為 tinyML 目標構建的模型的用途,以便它們與邊緣用例和更強大的 NVIDIA 硬件配合使用。許多邊緣 AI 用例都涉及需要更強大計算資源的復雜應用程序。 NVIDIA 硬件可以幫助解決與受限設備的限制相關的挑戰。
雖然您可以使用 Edge Impulse 從頭開始創建自己的模型,但它還集成了 NVIDIA TAO 工具套件。您可以在 Omniverse 中利用 100 多個預訓練模型,通過 計算機視覺 Model Zoo 進行訪問。Edge Impulse 是對 TAO 的補充,可用于根據自定義應用調整這些模型。這是企業用戶的絕佳起點。
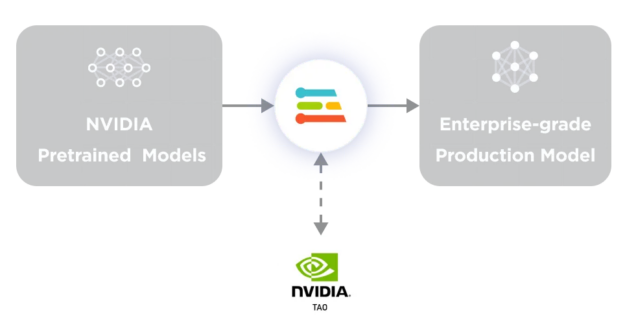
使用 Edge Impulse 構建 DeepStream 模型
完成模型構建后,將其部署到 DeepStream 中。從 Edge Impulse 導出模型文件并將其放入 DeepStream 項目中。然后按照配置步驟確保您的 Edge Impulse 模型與 DeepStream 配合使用。此過程通常包括四個步驟(圖 3)。

第 1 步:在 Edge Impulse 中構建模型
首先,在 Edge Impulse Studio 中構建 YOLO 或圖像分類模型。DeepStream 推理的 Gst-nvinfer 插件 要求輸入層的張量采用 NCHW 格式。請確保選擇 Jetson Nano 作為目標設備,并使用 FP32 權重。
第 2 步:從 Edge Impulse 導出模型
Edge Impulse 可以從 Edge Impulse Studio 的控制面板頁面導出模型。YOLOv5 可以導出為 ONNX,并且 NCHW 輸入層可隨時用于 DeepStream.

DeepStream 中的 IVA 工作流通常由主要推理 (PGIE) 步驟組成,該步驟使用邊界框坐標執行物體檢測。關聯的對象類被傳遞到對每個對象進行分類的次要推理步驟 (SGIE).每個類別都作為 Gst-nvinfer 插件的實例實現。
第 3 步:將模型轉換為兼容 DeepStream 的 ONNX
在將 YOLO 與 DeepStream 結合使用時,需要自定義輸出層解析器以從輸出層中提取邊界框和對象類別,并將它們傳遞給下一個插件。有關自定義 YOLO 輸出解析器的更多詳細信息,請參閱 如何使用自定義 YOLO 模型。
Edge Impulse 使用 YOLOv5,這是一個更新、性能更高的模型,其輸出張量格式與 YOLOv3 略有不同。YOLOv3 有三個輸出層,每個輸出層負責檢測不同比例的物體,而 YOLOv5 有一個輸出層,使用錨框處理各種大小的物體。
DeepStream 基于專為多媒體用例設計的 GStreamer. NVIDIA 已添加支持 GStreamer 流程中深度學習的功能,包括其他與 ML 相關的元數據,這些元數據通過 Gst-Buffer 傳遞到流程中,并通過 Gst – Buffer 封裝在 NvDsBatchMeta 結構中。
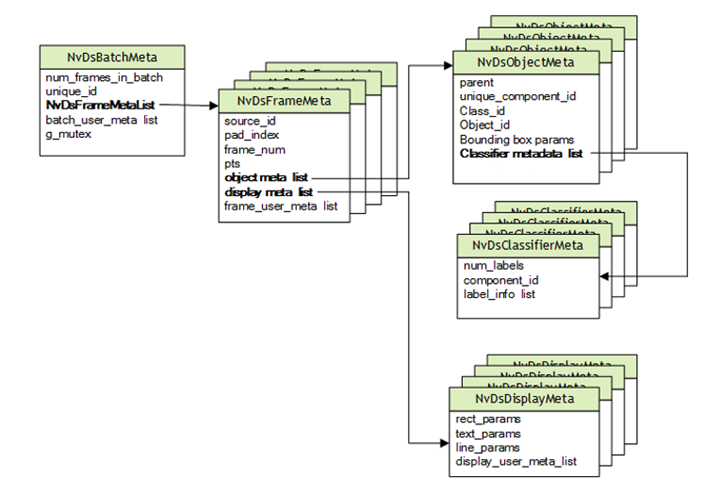
YOLO 輸出的張量格式與 DeepStream 需要的 NvDsObjectMeta 中保存的邊界框數據不同。要想將 YOLO 與 DeepStream 結合使用,需要開發自定義的輸出解析器,以便將 YOLO 的輸出轉換成符合 NvDsObjectMeta 要求的格式。 NVIDIA 提供了一個示例插件,該插件已適配 YOLOv3,可供參考。
Edge Impulse 使用 YOLOv5.YOLOv3 和 YOLOv5 的輸出層之間的差異使 YOLOv3 插件不適合與 YOLOv5 一起使用(圖 6)。
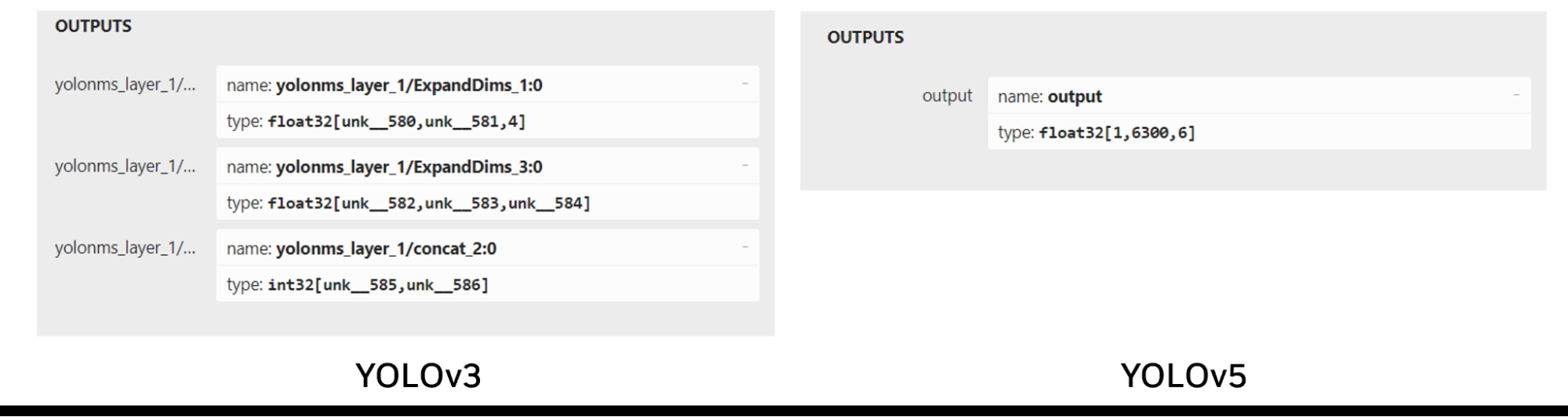
要在 Edge Impulse 中使用訓練好的 YOLOv5 模型,必須創建一個自定義的 YOLOv5 輸出解析器來處理單個輸出張量。一種可行的實現方式是使用第三方輸出解析器,它可以與 Edge Impulse 導出的 ONNX 模型配合使用。
對于圖像分類模型,Edge Impulse 以 NHWC 格式提供的默認 TFLite Float32 及其輸入層需要轉換為 NCHW.
這可以通過以下方式輕松實現:tf2onnx命令:
python -m tf2onnx.convert --inputs-as-nchw serving_default_x:0 --opset 13 --tflite MODELFILE --output OUTPUT.ONNX |
MODELFILE是輸入文件,OUTPUT.ONNX是輸出文件,用于指定 Edge Impulse 生成的輸入層名稱,serving_default_x:0.因此,輸入層進行了轉換,以滿足 DeepStream 要求。

第 4 步:創建推理插件配置文件
DeepStream 要求為 Gst-nvinfer 插件的每個實例創建純文本配置文件,以指定運行時要求。這包括 ONNX 模型文件或生成的 TRT 引擎文件以及包含標簽名稱的文本文件。圖 9 顯示了使用 Edge Impulse YOLOv5 和分類模型所需的最小參數集。

請注意,盡管出于說明目的,注釋與參數內聯顯示,但所有配置參數均應分開成新行。
我們的process-mode參數可用于指定插件是在主要階段還是次要階段執行。請注意,一旦指定了 ONNX 文件,DeepStream 就會使用trtexec來生成 TensorRT 引擎,而NVIDIA TensorRT則在 NVIDIA GPU 上執行。
創建引擎后,使用model-engine-file參數。model-file可將參數注釋掉,以防止在每次運行時重新創建引擎,從而節省啟動時間。
具體取決于model-color-mode(無論模型是 RGB 還是灰度),必須分別將參數設置為 0 或 2.這將對應于 Edge Impulse Studio 中設置的顏色深度。
前面的示例展示了模型如何用作主要推理插件。通過將模型設置為process-mode屬性如下所示:
process-mode=2 #SGIE |
圖 9 中的示例還顯示了兩階段工作流所需的最小配置文件,其中 YOLO 模型首先檢測對象,然后在第二階段分類器中單獨對其進行分類。對于 YOLO 模型,可以編輯默認的 YOLO 標簽文件,并且可以根據 YOLO 標準格式將標簽替換為自定義模型中的標簽,并在新行中添加每個標簽。
在分類模型的情況下,標簽用分號分開。在運行期間,模型將相應地根據這些文件進行索引,并顯示您指定的文本。
可以通過引用工作流中嵌入這些設置的配置文件來使用 DeepStream.
結束語
本文介紹了如何利用 Edge Impulse 和 NVIDIA DeepStream SDK 快速創建 HPC 視覺應用。這些應用包括車輛識別、交通測量、檢查系統、生產線質量控制、通過監控增強安全和安保、智能結賬系統實現和流程測量。AI 和 IVA 的新用例不斷涌現。
如需詳細了解 DeepStream,請參閱開始使用 NVIDIA DeepStream SDK。要開始結合使用 Edge Impulse 和 DeepStream,請參閱將 Edge Impulse 與 NVIDIA DeepStream 結合使用。本指南包含一個帶有預配置 DeepStream 工作流的資源庫鏈接,您可以使用該資源庫來驗證性能或開發自己的工作流。還包含適用于 Jetson Nano 架構的預編譯自定義解析器,可幫助您快速入門。
?





