
擴散模型正在各行各業中改變創意工作流程。這些模型通過采用降噪擴散技術,將隨機噪聲逐步塑造為 AI 生成的藝術,從而根據簡單的文本或圖像輸入生成令人驚嘆的圖像。這些模型可用于許多企業用例,例如為營銷創建個性化內容、為照片中的物體生成想象力的背景、為游戲設計動態高質量環境和角色等。
雖然擴散模型是增強工作流程的有用工具,但在大規模部署時,這些模型會非常計算密集。在非專用硬件 (如 CPU) 上生成一批四張圖像可能需要幾分鐘時間,這可能會阻礙創意流程,并且成為許多開發者滿足嚴格服務級別協議 (SLA) 的障礙。
在本文中,我們將向您展示 NVIDIA AI 推理平臺 可以專注于解決這些挑戰,穩定 Diffusion XL(SDXL)。我們首先探討企業在生產環境中部署 SDXL 時面臨的常見挑戰,然后深入探討如何 Google Cloud 的 G2 實例 由NVIDIA L4 Tensor Core GPU, NVIDIA TensorRT 和NVIDIA Triton 推理服務器 可以幫助緩解這些挑戰。我們介紹了 Let’s Enhance,一家領先的 AI 計算機視覺初創公司,正在 NVIDIA AI 推理平臺和 Google Cloud 上使用 SDXL,讓企業能夠一鍵創建引人注目的產品圖像。最后,我們提供了一個分步教程,介紹如何在 Google Cloud 上使用 SDXL 進行經濟高效的圖像生成。
克服 SDXL 生產部署挑戰
在任何 AI 生產環境中部署工作負載都帶來了一系列挑戰。這些挑戰包括在現有的模型服務基礎設施中部署模型,通過優化推理請求的批處理來提高吞吐量和延遲,并在預算限制的范圍內保持基礎設施成本。
然而,在生產環境中部署擴散模型所面臨的挑戰是顯而易見的,因為它們依賴于卷積神經網絡進行圖像預處理和后處理操作,并且需要滿足嚴格的企業服務級別協議(SLA)要求。
在本文中,我們將更深入地探討這些方面,并探索如何利用NVIDIA 全棧推理平臺來幫助緩解這些問題。
利用 GPU 專用的 Tensor Core
Stable Diffusion 的核心是 U-Net 模型,它始于一個噪聲圖像 (一組隨機數矩陣)。這些矩陣被切割成較小的子矩陣,然后應用一系列卷積 (數學運算),從而產生一個更加精細且噪音更少的輸出。每次卷積都包含一次乘法和累加運算。這種降噪過程需要多次迭代,直到獲得一個新的增強輸出圖像。

由于其計算復雜性,此過程可以顯著受益于特定類型的 GPU 核心,例如 NVIDIA Tensor 核心。這些專用核心從設計之初就旨在加速矩陣乘法累加運算,從而加快圖像生成速度。
NVIDIA 通用 L4 GPU 擁有超過 200 個 Tensor Core,是企業希望在生產環境中部署 SDXL 的理想經濟高效 AI 加速器。企業可以通過 Google Cloud 等云服務提供商訪問 L4 GPU,第一個 CSP 通過其 G2 實例在云端提供 L4 GPU。

圖像預處理和后處理自動化
在使用 SDXL 的實際企業應用程序中,該模型是包含其他計算機視覺模型和預處理和后處理圖像編輯步驟的更廣泛 AI 管線的一部分。
例如,如果使用 SDXL 為新產品發布活動創建背景場景,則可能需要在輸入產品圖像到 SDXL 模型以生成場景之前執行預備縮放預處理步驟。生成的 SDXL 圖像輸出也可能需要進一步的后期處理,例如使用圖像放大器將分辨率提升到更高的分辨率,以便在市場營銷活動中使用。
通過將這些預處理和后處理步驟整合到精簡的 AI 工作流程中,可以實現自動化,例如使用開源的 Triton 推理服務器。這樣一來,無需編寫手動代碼,也無需在計算環境中來回復制數據,從而消除了不必要的延遲,并節省了昂貴的計算和網絡資源。
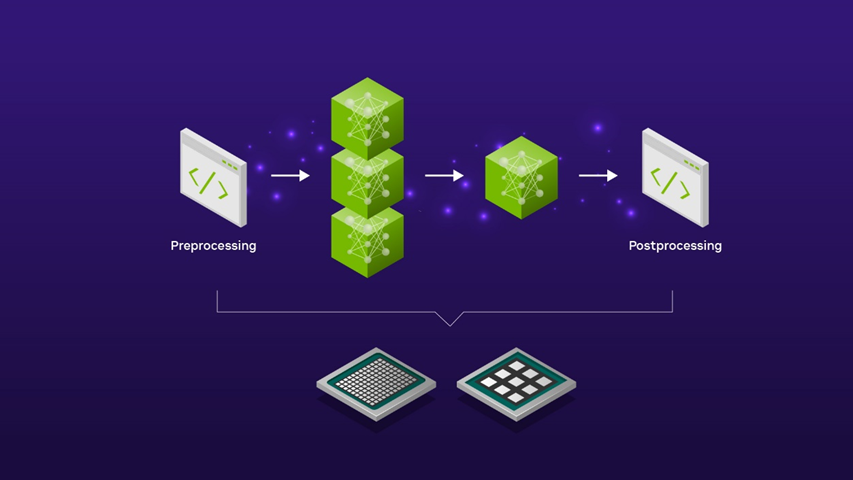
通過使用 Triton 推理服務器來服務 SDXL 模型,您可以利用模型集成功能,以低代碼方式定義如何將一個模型的輸出作為下一個模型的輸入。您可以選擇在 CPU 上運行預處理和后處理步驟,在 GPU 上運行 SDXL 模型,也可以選擇在 GPU 上運行整個管線,以實現超低延遲應用程序。無論您選擇哪種方式,您都可以完全控制 SDXL 管線的端到端延遲。
生產環境的高效擴展
隨著越來越多的企業致力于將 SDXL 整合到各個業務線中,處理用戶請求的高效批處理和提高 GPU 利用率的挑戰變得越來越復雜。這種復雜性來自于盡可能減少用戶體驗中的延遲,同時提高吞吐量以降低運營成本的需求。
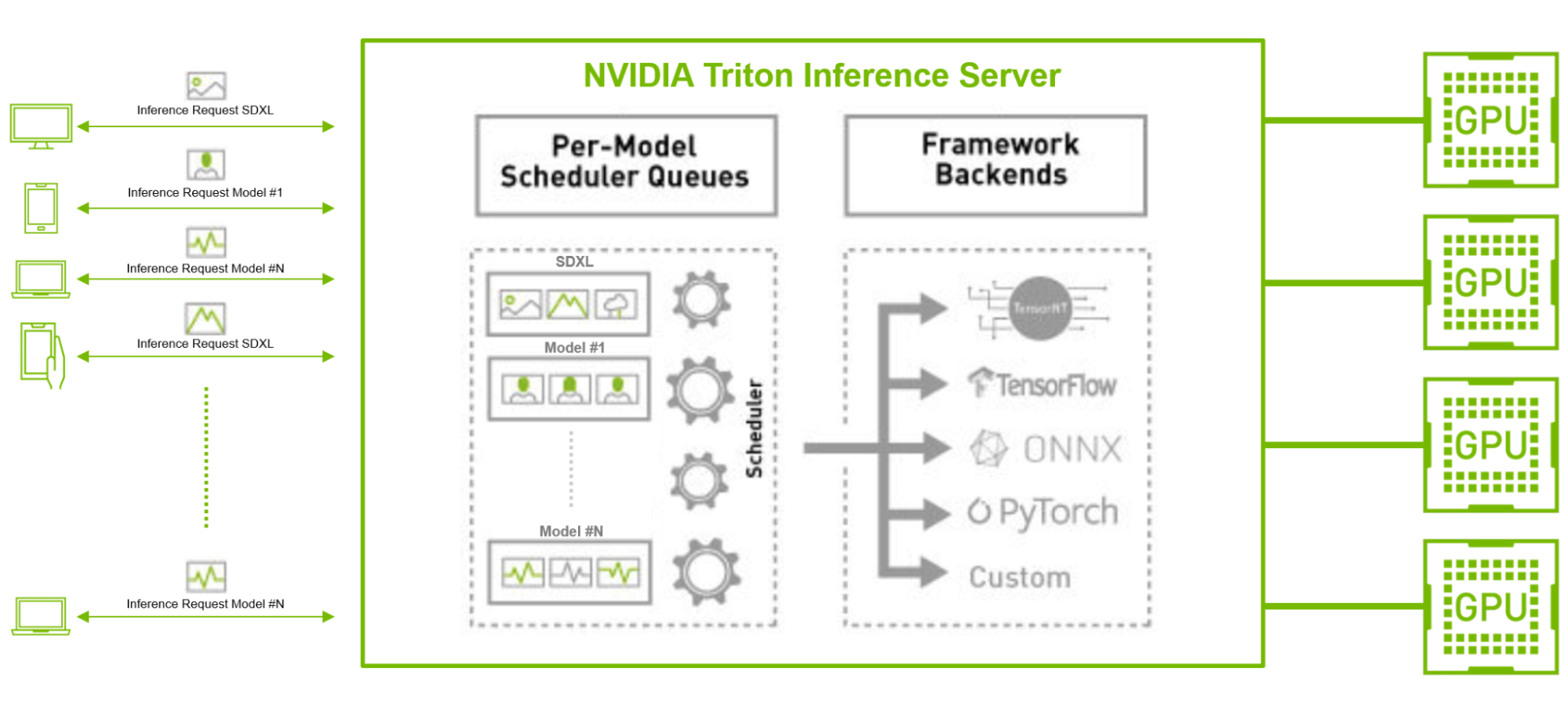
使用像 TensorRT 這樣的開源 GPU 模型優化器,并結合使用具有并發模型執行和動態批處理功能(如 Triton 推理服務器)的推理服務器,可以緩解這些挑戰。
例如,考慮一下在與其他 TensorFlow 和 PyTorch 圖像分類或特征提取 AI 模型并行運行 SDXL 模型的情況,尤其是在有大量客戶請求的生產環境中。在這種情況下,SDXL 模型可以使用 TensorRT 進行編譯,以優化模型以實現低延遲推理。
Triton 推理服務器還可以通過其動態批處理和并發推理功能,在各個模型中高效批量處理大量來自不同后端框架的請求,從而優化吞吐量,使企業能夠借助更少的資源和更低的總體擁有成本滿足用戶需求。
將普通產品照片轉化為精美的營銷素材
利用 NVIDIA AI 推理平臺的強大功能,在生產環境中為 SDXL 提供支持的優秀示例包括 Let’s Enhance.這家領先的 AI 初創公司已經在 NVIDIA Tensor Core GPU 上部署了超過 30 個 AI 模型,使用 Triton 推理服務器,并且已經運行了 3 年多。
最近,Let’s Enhance 宣布推出最新產品 AI Photoshoot,該產品使用 SDXL 模型將普通的產品照片轉換為電子商務網站和營銷活動的精美視覺素材。
借助 Triton 推理服務器對各種框架和后端的強大支持,以及其動態批處理特征集,Let’s Enhance 創始人兼首席技術官 Vlad Pranskevichus 能夠將 SDXL 模型無縫集成到現有的 AI 管線中,從而釋放 ML 工程團隊的時間,讓他們能夠專注于研發工作。
通過成功的概念驗證,AI 圖像增強初創公司發現,通過將其 SDXL 模型遷移到 Google Cloud G2 實例上的 NVIDIA L4 GPU 可以將成本降低 30%,并概述了在 2024 年中期完成多個管線遷移的路線圖。

使用 L4 GPU 和 TensorRT 開始使用 SDXL
在下一節中,我們將展示如何在 Google Cloud 的 G2 實例上快速部署經過 TensorRT 優化的 SDXL,以獲得出色的性價比。要在 Google Cloud 上使用 NVIDIA 驅動啟動 VM 實例,請按照以下步驟操作。
選擇以下機器配置選項:
- 機器類型:g2-standard-8
- CPU 平臺:英特爾 Cascade Lake
- 最低 CPU 平臺:無 Original:
- 顯示設備:禁用
- 顯示設備:關閉
- GPU: 1 NVIDIA L4
Original:
g2-standard-8 機型配備一個 NVIDIA L4 GPU 和四個 vCPU,而大型機型則配備 available 具體取決于所需的內存量。
g2-standard-8 機型配備一個 NVIDIA L4 GPU 和四個 vCPU,而大型機型則配備 available GPUs,具體取決于所需的內存量。
選擇以下啟動磁盤選項,確保選擇源鏡像:
- 類型:均衡的持久磁盤。
- 尺寸:500 GB
- 區域:美國中部第 1 區
- 標簽:無
- 用戶:實例 1
- 快照計劃:無
- 來源圖像:c0-deeplearning-common-gpu
- 加密類型:由 Google 管理。
- 一致性組:無
NVIDIA Omniverse 平臺通過 Google 深度學習 VM 提供了最新的 NVIDIA GPU 庫。
VM 實例啟動并運行后,在瀏覽器窗口中,選擇 連接, SSH, 打開, 然后進行身份驗證。此操作會在瀏覽器窗口中加載 SSH 終端。
使用以下步驟使用 TensorRT 優化的 Stable Diffusion XL 生成圖像。
克隆 TensorRT OSS 資源庫:
git clone https://github.com/NVIDIA/TensorRT.git -b release/9.2 --single-branchcd TensorRT |
安裝 NVIDIA-docker 并啟動 PyTorch 容器:
docker run --rm -it --gpus all -v $PWD:/workspace nvcr.io/nvidia/pytorch:24.01-py3 /bin/bash |
安裝最新的 TensorRT 版本:
python3 -m pip install --upgrade pippython3 -m pip install --pre --upgrade --extra-index-url https://pypi.nvidia.com tensorrt |
安裝所需軟件包:
export TRT_OSSPATH=/workspaceexport HF_TOKEN=cd $TRT_OSSPATH/demo/Diffusionpip3 install -r requirements.txt |
現在,運行經 TensorRT 優化的 Stable Diffusion XL 模型,輸入“art deco,realistic”(藝術裝飾,逼真) 提示:
python3 demo_txt2img_xl.py "art deco, realistic" --hf-token=$HF_TOKEN --version xl-1.0 --batch-size 1 --build-static-batch --num-warmup-runs 5 --seed 3 --verbose --use-cuda-graph |
這會生成一張令人驚嘆的圖像,可以在 notebook 中查看:
from IPython.display import displayfrom PIL import Imageimg = Image.open('output/xl_base-fp16-art_deco,_-1-xxxx.png')display(img) |

恭喜!您已使用經 TensorRT 優化的 Stable Diffusion XL 生成樣本圖像。
為了提高吞吐量,您可以使用更大的機器類型,利用多達 8 個 L4 GPU,并在每個 GPU 上加載模型以實現高效并行處理。為了進一步加快推理速度,您可以調整降噪步長、圖像分辨率或精度。例如,在前面的示例中,將降噪步長從 30 調整為 20,可將吞吐量提高 1.5 倍。
L4 GPU 在性價比方面表現出色,每美元可生成 1.4 倍的圖像。NVIDIA A100 Tensor Core GPU 使其非常適合成本敏感型應用程序和離線批量圖像生成。相比之下,A100 或 H100 更適合延遲敏感型應用程序,可以分別將圖像生成速度加快 3.8 倍和 7.9 倍。
推理期間的性能受到多種因素的影響,包括批量大小、分辨率、降噪步長和數據精度。要了解更多關于優化和配置選項的信息,請參閱 DemoDiffusion 或 NVIDIA /TensorRT GitHub 資料庫中的示例。
使用 Triton 推理服務器在生產環境中部署 SDXL
以下是如何在 g2-standard-32 機型上使用 Triton 推理服務器在生產環境中部署 SDXL 模型的方法。
克隆 Triton 推理服務器教程資源庫:
git clone https://github.com/triton-inference-server/tutorials.git -b r24.02 --single-branchcd tutorials/Popular_Models_Guide/StableDiffusion |
構建 Triton 推理服務器擴散容器鏡像:
./build.sh |
在容器鏡像中運行交互式 shell。以下命令啟動容器并將當前目錄作為工作空間掛載:
./run.sh |
構建穩定 Diffusion XL TensorRT 引擎。這需要幾分鐘時間。
./scripts/build_models.sh --model stable_diffusion_xl |
完成后,預期輸出將如下所示:
diffusion-models |-- stable_diffusion_xl |-- 1 | |-- xl-1.0-engine-batch-size-1 | |-- xl-1.0-onnx | `-- xl-1.0-pytorch_model `-- config.pbtxt |
啟動 Triton 推理服務器。在本演示中,我們使用 EXPLICIT 模型控制模式,以控制加載的 Stable Diffusion 版本。有關生產部署的更多信息,請參閱 安全部署注意事項。
tritonserver --model-repository diffusion-models --model-control-mode explicit --load-model stable_diffusion_xl |
完成后,預期輸出將如下所示:
I0229 20:22:22.912465 1440 server.cc:676]+---------------------+---------+--------+| Model | Version | Status |+---------------------+---------+--------+| stable_diffusion_xl | 1 | READY |+---------------------+---------+--------+/sy |
在單獨的交互式 shell 中,啟動新的容器以運行示例 Triton 推理服務器客戶端。以下命令啟動容器并將當前目錄作為工作空間掛載:
./run.sh |
將提示發送至 Stable Diffusion XL:
python3 client.py --model stable_diffusion_xl --prompt "butterfly in new york, 4k, realistic" --save-image |

恭喜!您已成功使用 Triton 部署 SDXL。
借助 Triton 推理服務器實現動態批處理
在基本 Triton 推理服務器啟動并運行后,您現在可以增加max_batch_size啟用動態批處理。
如果 Triton 推理服務器正在運行,請停止該服務器。可以在交互式 shell 中輸入 CTRL-C 來停止該服務器。
編輯模型配置文件,./diffusion-models/stable_diffusion_xl/config.pbtxt,將批量大小增加到 2:
- 之前:
max_batch_size: 1 - 最終效果:
max_batch_size: 2
為批量大小為 2 的 TRT 引擎重建引擎。此過程需要幾分鐘。
./scripts/build_models.sh --model stable_diffusion_xl |
完成后,預期輸出將如下所示:
diffusion-models|-- stable_diffusion_xl |-- 1 | |-- xl-1.0-engine-batch-size-2 | |-- xl-1.0-onnx | `-- xl-1.0-pytorch_model `-- config.pbtxt |
重啟 Triton 推理服務器:
tritonserver --model-repository diffusion-models --model-control-mode explicit --load-model stable_diffusion_xl |
完成后,預期輸出將如下所示:
I0229 20:22:22.912465 1440 server.cc:676]+---------------------+---------+--------+| Model | Version | Status |+---------------------+---------+--------+| stable_diffusion_xl | 1 | READY |+---------------------+---------+--------+ |
向服務器發送并發請求。為了讓服務器動態批量處理多個請求,必須有多個客戶端同時發送請求。使用示例客戶端,您可以增加客戶端數量,以查看動態批量處理的優勢。
python3 client.py --model stable_diffusion_xl --prompt "butterfly in new york, 4k, realistic" --clients 2 –requests 5 |
檢查服務器日志和指標。啟用動態批處理、并發請求和 info 級別記錄后,示例將打印有關每個請求中包含的提示數量的 TensorRT 引擎的額外信息。
57291 │ I0229 20:36:23.017339 2146 model.py:184] Client Requests in Batch:257292 │ I0229 20:36:23.017428 2146 model.py:185] Prompts in Batch:2 |


總結
在 NVIDIA AI 推理平臺上部署 SDXL 可為企業提供可擴展、可靠且經濟高效的解決方案。
TensorRT 和 Triton 推理服務器均能解鎖高性能并簡化生產就緒型部署,它們包含在 NVIDIA AI Enterprise 中,可以在 Omniverse 應用中通過 Google Cloud Marketplace 獲得。AI Enterprise 提供 NVIDIA 的 支持服務,并為支持 AI 推理的開源容器和框架提供企業級穩定性、安全性和可管理性。
企業開發者還可以選擇使用 NVIDIA Picasso,這是一個專為視覺內容定制生成式 AI 打造的平臺。
SDXL 可以通過 NVIDIA AI 基礎模型 在 NGC 目錄中獲得,提供一個易于使用的界面。您可以在 這里 快速試用 SDXL,直接從您的瀏覽器中運行。
如需詳細了解 NVIDIA 如何為擴散模型推理管線提供支持,請訪問 NVIDIA GTC 2024.
- 全球速度最快的穩定 Diffusion。
- Diffusion Models: The Big Bang of Generative AI
- 利用多模態生成式 AI 和 NVIDIA 技術創作藝術肖像
- AI 推理的實際應用:讓我們增強
- 利用 NVIDIA Picasso 構建視覺生成式 AI 應用
?







