
機器人智能體要與環境中的物體進行交互,必須了解周圍物體的位置和方向。此信息描述了 3D 空間中剛體的六自由度 (DOF) 姿態,詳細說明了平移和旋轉狀態。
準確的姿態估計對于確定如何定位機械臂以特定方式抓取或放置物體至關重要。用例包括用于拾放操作的機器人操作,尤其適用于包裝箱、部件裝載和食品包裝等任務的倉庫場景。了解物體的姿態對于機器人對人類的切換也至關重要,在醫療健康、零售和家庭場景中也很有用。
NVIDIA 開發了深度物體姿態估計 (DOPE),用于查找物體的六個 DOF 姿態。在本文中,我們將展示如何生成合成數據來訓練物體的 DOPE 模型。
深度物體姿態估計
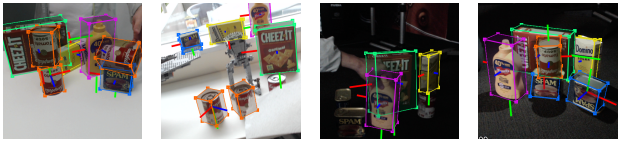
DOPE 是由 NVIDIA 開發的一次性 DNN,可通過 RGB 圖像估算六個感興趣物體的自由度姿態,以實現機器人操作環境中的物體。它僅根據合成數據進行訓練,并且需要一個紋理 3D 模型。它為真實的抓取和抓取操作提供足夠的準確性,公差為 2 厘米。
DOPE 是一個實例級模型,這意味著 DOPE 模型必須針對類中的每種對象類型進行專門訓練。例如,我們無法訓練單個 DOPE 模型來檢測所有類型的椅子,而是必須為每個椅子類型訓練一個模型。
再舉一個例子,如果一個應用檢測四個不同顏色的幾何相似框,則需要四個 DOPE 模型實例進行推理,即在每個彩色框上專門訓練一個 DOPE 模型實例。
DOPE 的優勢
- 它可以完全基于合成數據進行訓練,從而降低數據收集和標注成本。
- 處理物體遮擋。
- 通過結合用于訓練的域隨機化和逼真合成數據,減少現實差距挑戰。
- 它使用 Perspective-n -point (PnP) 算法處理不同的攝像頭內部結構,無需重新訓練。
- NVIDIA Isaac ROS 支持 DOPE,可提供 GPU 加速的物體姿態估計。
現實差距挑戰
僅在合成數據上訓練的網絡在處理真實數據時通常表現不佳。微調或域隨機化等技術有助于提高性能。
域隨機化是在模擬環境中更改場景照明、比例、姿態、顏色和物體紋理等參數的方法。這樣做的目的是為神經網絡提供足夠的各種域參數,以改進對真實環境的泛化。這樣,真實數據就會顯示為網絡的另一個變體。
DOPE 通過結合用于訓練的域隨機化和逼真的合成數據來彌合現實差距,并很好地推廣到真實的用例。
架構
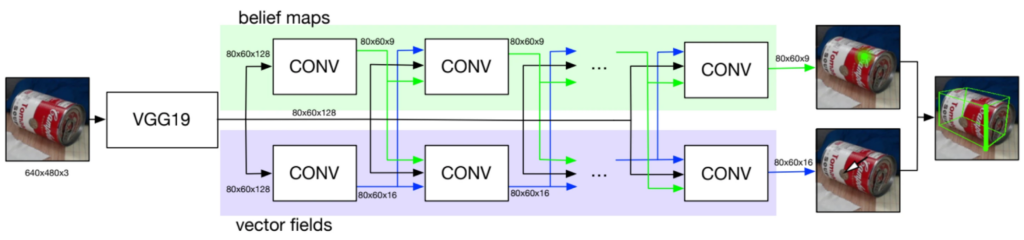
DOPE 是一種單次全卷積神經網絡,其設計靈感源自卷積式姿態機(CPM)和多人姿態估計器。該架構由標準 CNN(如 VGG19 或帶有額外卷積層的 ResNet)組成。
想要全面了解 DOPE 架構和數據生成管道,請參閱 深度物體姿態估計:用于語義機器人抓取家居物體的方法。
數據集
NVIDIA 提供了基于預訓練 DOPE 模型訓練的 NVIDIA 家居用品 (HOPE) 數據集,該數據集包含 28 個不同環境中的玩具雜貨店對象。它是 6D 物體姿態估計基準測試的一部分,可以在 這里 和 這里 訪問。
在實例級別,DOPE 必須使用針對與應用程序相關的感興趣對象的數據集進行訓練。要生成用于訓練 DOPE 的數據集,需要對象的 3D 模型。可以使用 BundleSDF 方法,該方法由 NVIDIA 開發,使用單目 RGBD 攝像頭,無需使用昂貴的 3D 傳感器。
數據生成
可以使用 NVIDIA Isaac Sim 為 DOPE 生成用于域隨機化的合成數據。我們專注于兩個數據集(MESH 和 Dome),并實施隨機化技術,類似于在NViSII 論文中所述。
這些數據集可為目標物體周圍的場景添加飛行干擾素,并對光照條件、干擾素的顏色和材質進行隨機化處理。Dome 使用的干擾素比 MESH 少,可提供更逼真的背景。

關于如何使用 Isaac Sim 為 DOPE 創建訓練數據的信息,請訪問 NVIDIA 文檔。
您可以指定要針對每種類型(MESH 和 Dome)生成的圖像數量。良好的 MESH/Dome 分割取決于用例。嘗試找到適合您的模型的啟發式算法(例如,MESH/Dome 之間的啟發式算法為 25/75)。如果在單個對象上生成數據和訓練 DOPE,包含大約 2 萬張圖像的訓練數據集通常就足夠了。
生成的數據集包括圖像和帶注釋的 JSON 文件。每個 JSON 文件都包含有關對象的信息,包括相應圖像中的對象類、位置、方向和可見性。可見性表示對象的可見程度(在遮擋情況下),并可用于過濾圖像以進行訓練。
這種使用 Isaac Sim 生成數據的方法,可以類似地創建數據集,例如YCB 視頻數據集,這些數據集可以用于訓練其他 6D 姿態估計模型。
物體對稱
DOPE 在與目標對象綁定的長方體邊角上進行訓練。此對象中的旋轉對稱性可能會產生多個幀,這些幀在像素上相同,但有不同的長方體邊角標記。
請在 GitHub 上觀看視頻 Deep Object Pose 視頻了解詳情。
目前,Isaac Sim 的數據生成方法沒有特別處理旋轉對稱性。然而,NVIDIA 提供了使用 NViSII 合成數據生成腳本來處理對稱性的方法。這些腳本可以在 GitHub 上找到。
訓練 DOPE
在生成訓練數據集后,NVIDIA 將提供用于訓練 DOPE 的腳本。您可以將腳本指向訓練數據,并指定要訓練模型的批量大小和訓練次數。
該腳本會保存有用的訓練信息(包括損失圖和信念圖),您可以使用 TensorBoard 查看這些信息。
推理和評估
訓練 DOPE 模型后,您可以對測試數據集運行推理。根據測試數據中的圖像,您可以在提供的配置文件中指定配置參數,也可以編寫自己的參數。
我將感興趣對象的物理尺寸包含在對象配置文件中。我使用 3D 查看器 加載 3D 模型并查找維度。推理工作流程使用這些維度生成檢測到的物體周圍的邊界框的結果。

運行推理后,我們會提供評估工作流程,以量化方式評估模型的性能。評估時需要真實數據、推理步驟的預測結果以及目標對象的 3D 模型(.obj 格式)。我們會渲染對象的 3D 模型,以計算真實數據和預測結果之間的 3D 誤差。
使用 ADD 指標,我們提供兩個計算誤差的選項:
- 平均距離 (ADD) 是使用預測姿態和真實姿態之間的最近點距離計算得出的平均距離。
- 長方體距離計算使用3D模型的8個立方體點(真值)和預測的立方體點計算平均距離。這種方法比計算ADD的速度更快,但準確度較低。
僅針對任意物體的域隨機化數據,在 30 萬張圖像中,觀察到的曲線下最大區域 (AUC) 為 66.64.僅使用包含 60 萬張照片級逼真圖像的數據集時,觀察到的 AUC 為 62.94.結合使用域隨機化和照片級逼真的合成圖像時,準確度最高 (77.00 AUC)。
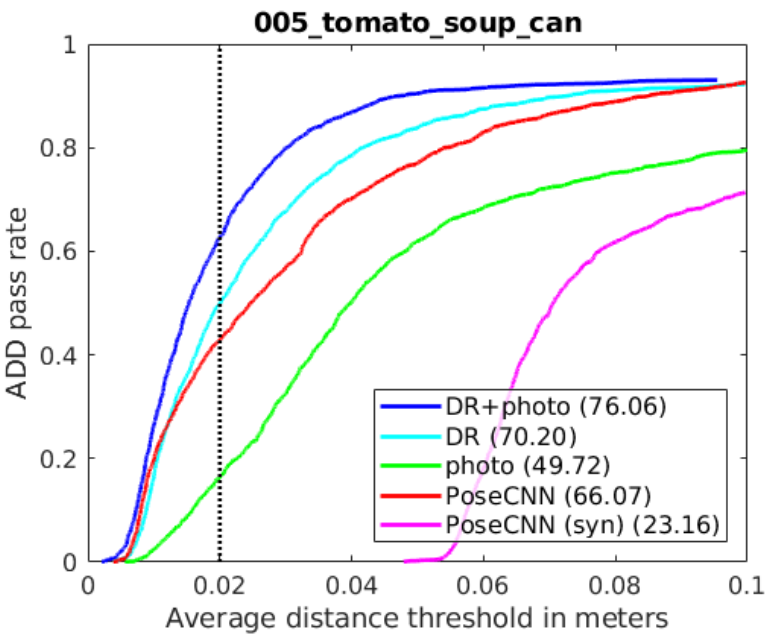
DOPE 僅使用合成圖像進行訓練。然而,即使在出現遮擋和極端光照變化的情況下,它在使用其他攝像頭拍攝的場景中仍然表現出色。其性能優于 PoseCNN 和 BB8,后者使用真實數據或合成數據與真實數據的組合進行訓練。
為進行直接比較,從 YCB 數據集中選擇了 5 個物體,而 DOPE 在 5 個物體中的 4 個中實現了高于 PoseCNN 的 AUC.
如需了解更多詳情,請參閱DOPE 論文。請訪問我們的 GitHub,了解更多信息關于推理和評估。
使用 Isaac ROS 姿態估計
Isaac ROS 提供了一個 ROS 2 包,用于使用 DOPE 進行姿態估計。它使用 NVIDIA Triton 或 NVIDIA TensorRT 與 Isaac ROS DNN 推理。
在訓練 DOPE 模型后,您可以在 Omniverse 上使用此軟件包運行推理,適用于NVIDIA Jetson或配備 NVIDIA GPU 的系統。
您還可以對來自攝像頭流的實時圖像執行推理,但這是一個計算密集型任務。姿態估計的幀率低于攝像頭輸入率。我們的 DOPE 圖形在 NVIDIA Jetson AGX Orin 上以 39.8 FPS 運行,在 NVIDIA RTX 4060 Ti 上以 89.2 FPS 運行,基于 Isaac ROS 基準測試 工作流程。
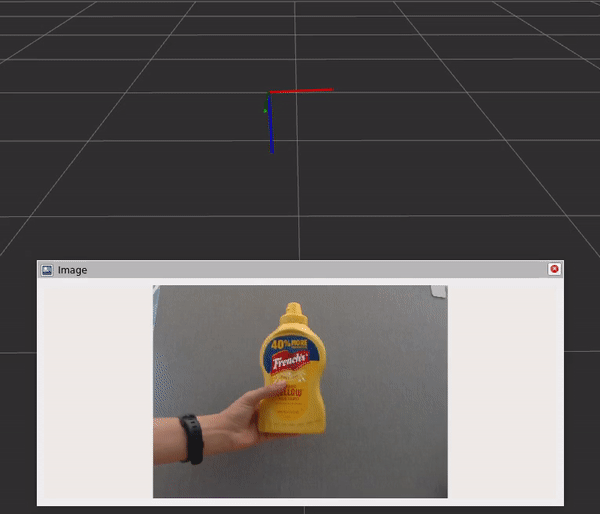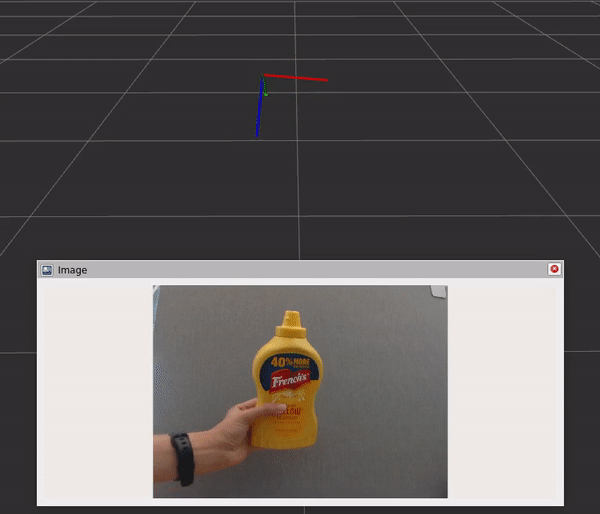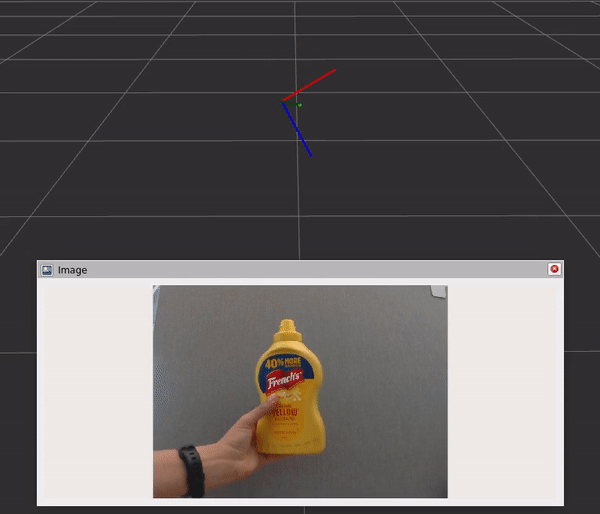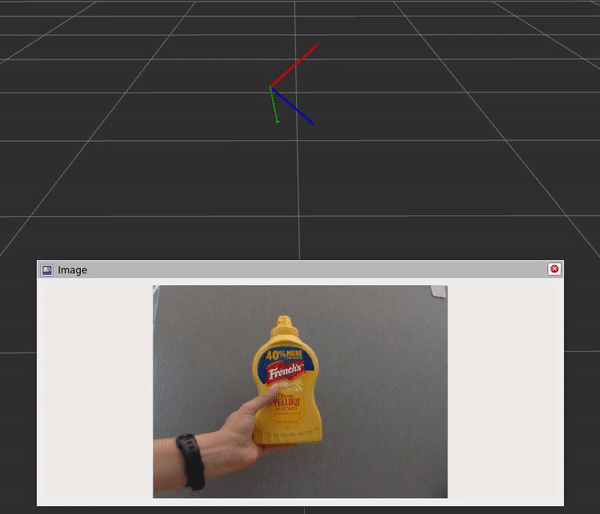
該圖包含三個組件和步驟:
- DNN 圖像編碼器節點將原始圖像轉換為標準化張量。
- TensorRT 節點將輸入張量轉換為信念圖張量。
- DOPE 解碼器節點將信念貼圖轉換為一系列姿勢。
要深入了解不同 Isaac ROS 軟件包的性能和基準測試方法,請查閱性能概要。此外,您還可以在 GitHub 上查看 Isaac ROS 姿態估計的發布信息:https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_pose_estimation。
?





