
借助互聯網級數據,AI 生成內容的計算需求顯著增加,數據中心在數周或數月內全力運行單個模型,更不用說通常作為服務提供的高生成推理成本。在這種情況下,犧牲性能的次優算法設計是一個代價高昂的錯誤。
近期,AI 生成的圖像、視頻和音頻內容取得了很大進展,降噪擴散 —— 一種以迭代方式將隨機噪聲塑造成新數據樣本的技術。我們的團隊最近發表的一篇研究論文 《闡明基于擴散的生成模型的設計空間》 獲得了 NeurIPS 2022 杰出論文獎,該論文識別出了文檔中看似復雜的方法背后的簡單核心機制。從對基礎知識的清晰認識開始,我們能夠發現在質量和計算效率方面的先進實踐。
降噪擴散
降噪是指從圖像中消除傳感器噪聲或從錄音中消除聲等操作。本文將使用圖像作為運行示例,但該過程也適用于許多其他領域。此任務非常適合卷積神經網絡。
這與生成新圖像有什么關系?想象一下,圖像上有大量噪點。確實,原始圖像丟失了這么多。是否可以使用降噪器來揭示某些隨機可能隱藏在所有噪音下的圖像?令人驚訝的是,答案是肯定的。
這是降噪擴散的一個簡單本質:首先,隨機繪制一張純白色噪聲的圖像,然后通過反復將其輸入到神經降噪器,在噪聲級別(例如一次 2%)消除噪聲。逐漸地,從噪聲下方出現隨機干凈的圖像。生成內容(貓和狗的圖片?英語口語短語的音頻波形?駕駛視頻片段?)的分布由降噪器網絡訓練時使用的數據集確定。

以下代碼是對如何在假設神經網絡函數的情況下實現這一想法的初步猜測denoise可用。
# start with an image of pure large-magnitude noisesigma = 80????? # initial noise levelx = sigma * torch.randn(img_shape)?
for step in range(256):????# keep 98% of current noisy image, and mix in 2% of denoising????x = 0.98 * x + 0.02 * denoise(x, sigma)?????????# keep track of current noise level????sigma *= 0.98 |
如果您看過該領域的代碼庫或科學論文(充滿了方程頁),您可能會驚訝地發現,這個幾乎微不足道的代碼實際上是一個理論上有效的實現,稱為概率流普通微分方程求解器.盡管此代碼段并非最佳,但令人驚訝的是,它體現了論文中解釋的許多關鍵良好實踐。該團隊的頂級最終采樣器本質上只是幾行。
該函數如何denoise?其核心同樣非常簡單:降噪器必須輸出可能隱藏在噪聲下的所有可能的清晰圖像的模糊平均值。各種噪聲級別下的預期輸出可能如圖 2 所示。

使用基本損失(即輸出與清晰目標之間的均方誤差)訓練降噪器網絡(通常為 U-Net)可以精確地達到此結果。旨在提高輸出清晰度的更精細的損失實際上是有害的,并且違反了理論。請記住,即使任務在概念上很簡單,大多數現有的降噪器也不是專門針對它進行訓練的。
許多明顯的數學復雜性都源自于 該理論的原理。該理論可以從各種形式中構建,其中最流行的兩種是 Markov 鏈和隨機微分方程。雖然每種方法都可以歸結為使用經過訓練的降噪器的降噪循環,但它們為不同的實際實現開辟了廣闊且令人困惑的空間,并為做出錯誤選擇提供了機會的雷區。
該論文回顧了數學復雜性的各個層,直接揭示了標準化框架中易于分析的實際設計選擇。
本文通過可視化和代碼介紹了團隊的主要發現和直覺。我們將介紹三個主題:
- 直觀地概述了理論降噪擴散背后的原理
- 設計選擇采樣(在您已經擁有經過訓練的降噪器時用于生成圖像)
- 設計選擇訓練降噪器
是什么讓擴散發揮作用?
首先,本節將回顧基礎知識,并構建理論框架來證明這段簡單代碼的正確性。我們在微分方程的框架下找到了大部分見解,這一框架最初在通過隨機微分方程進行基于分數的生成建模中被提出。雖然方程和數學概念可能看起來復雜,但它們對于理解核心概念并不是必要的。偶爾提及這些概念是有益的,因為它們往往只是用另一種語言描述代碼中所完成的具體事務。
想象一張 RGB 圖像 x,其形狀為 [3, 64, 64]。首先,我們考慮一種簡單的破壞方向,即通過逐漸在圖像上添加噪點來調整圖像。(當然,這與最終目標相反。)
for step in range(1000):????x = x + 0.1 * torch.randn_like(x) |
這實際上是(適當地斜視)與簡單 SDE 對應的隨機微分方程 (SDE) 求解器 表示圖像的更改 x 在短時間步長內為隨機白噪點。在這里 解決 只是意味著模擬 SDE 描述的過程的特定隨機數值實現。
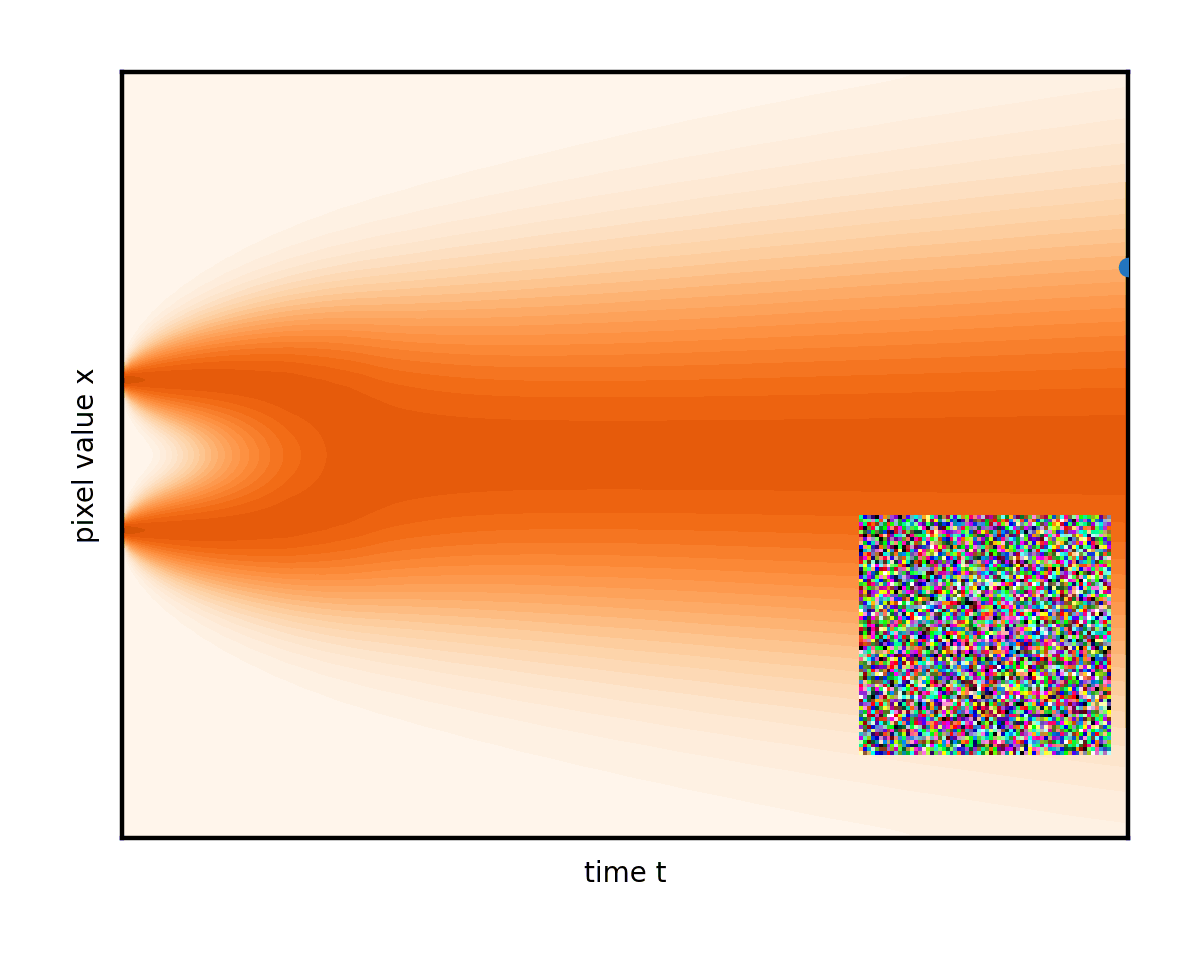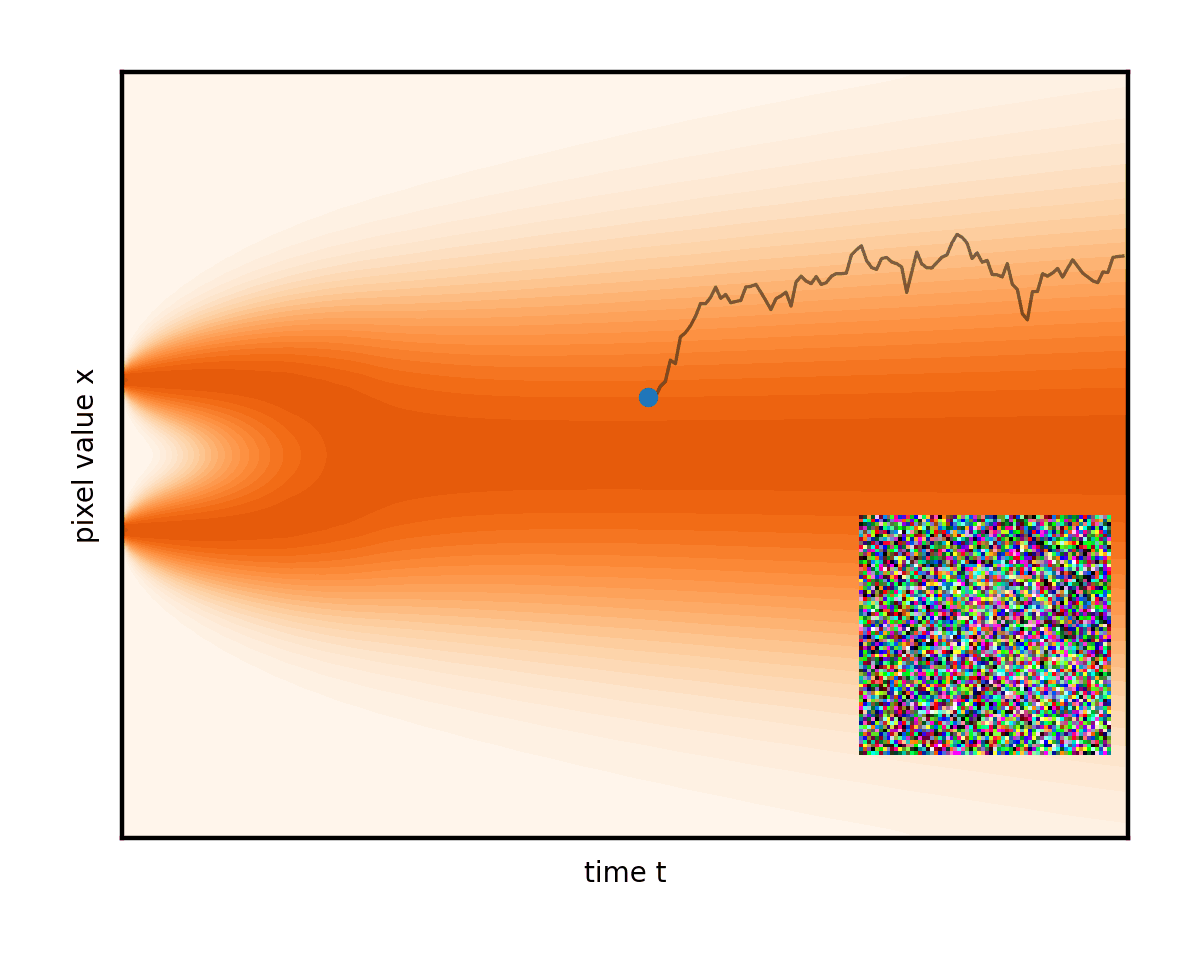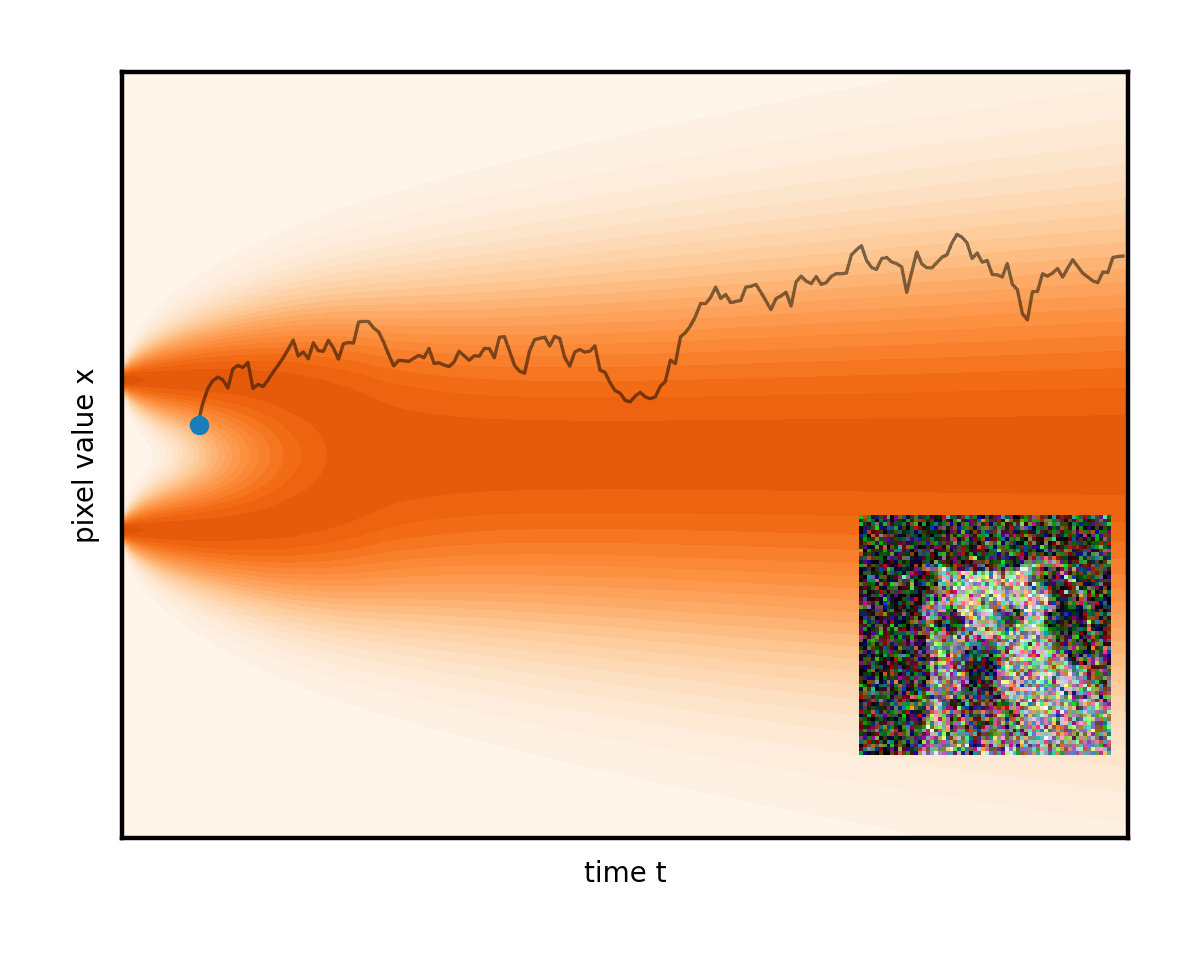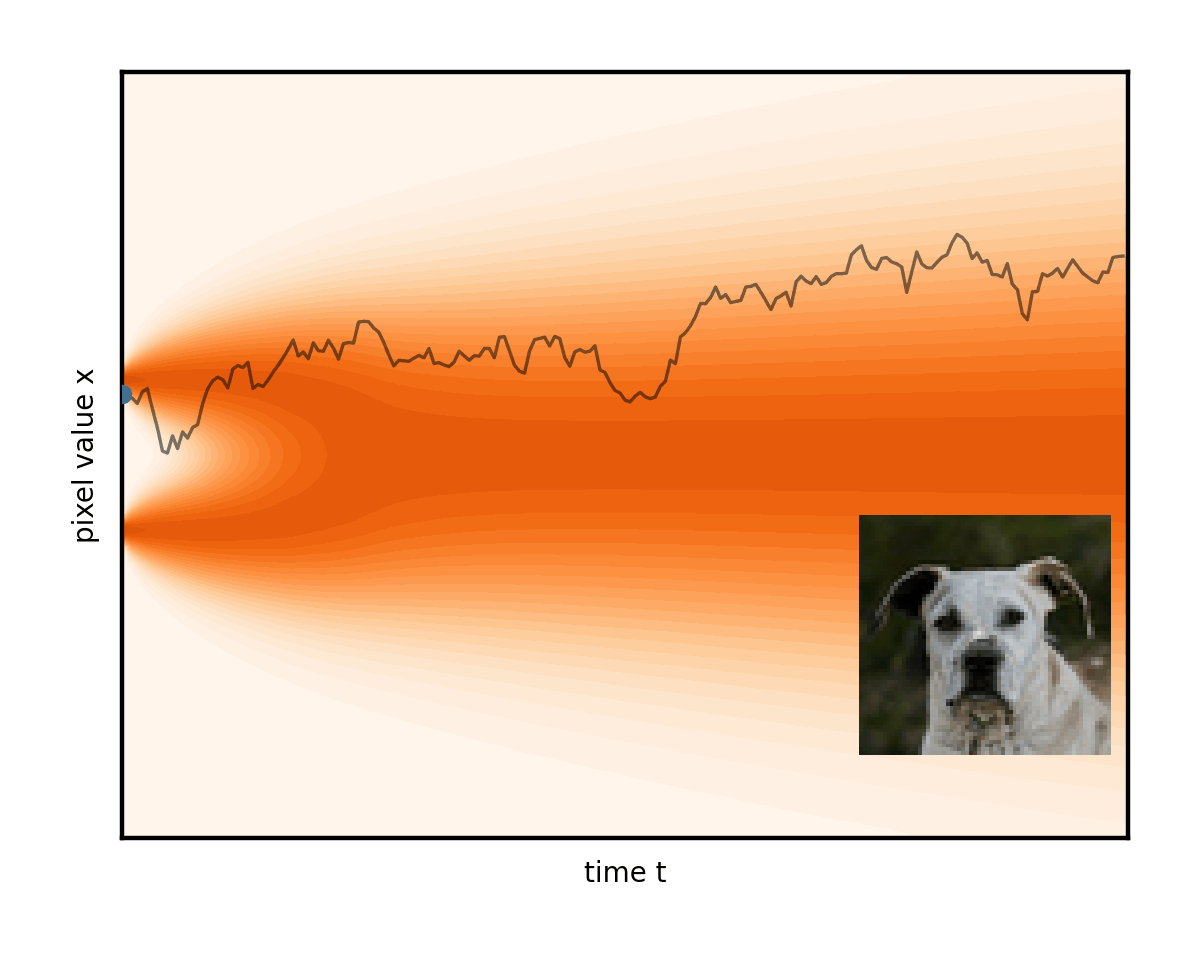
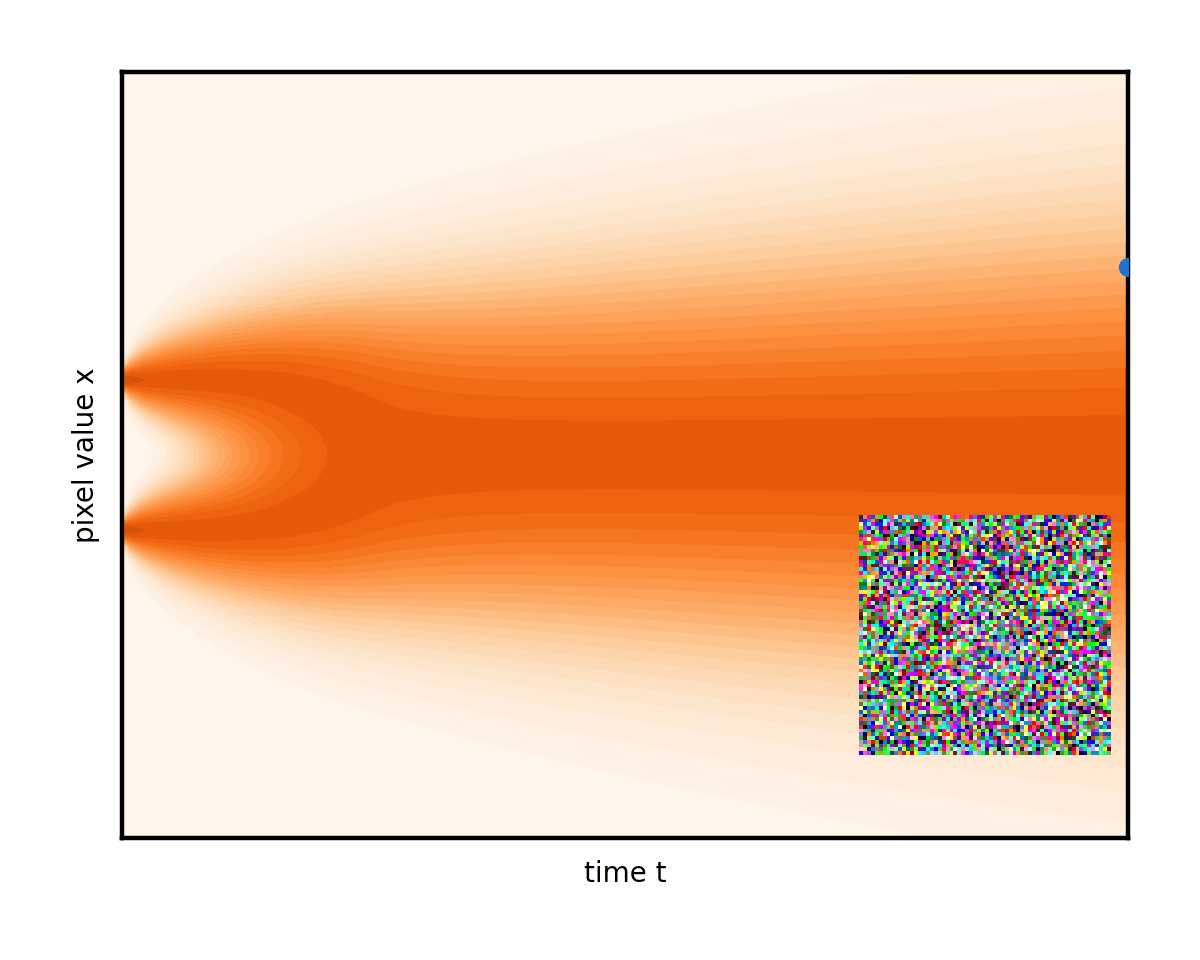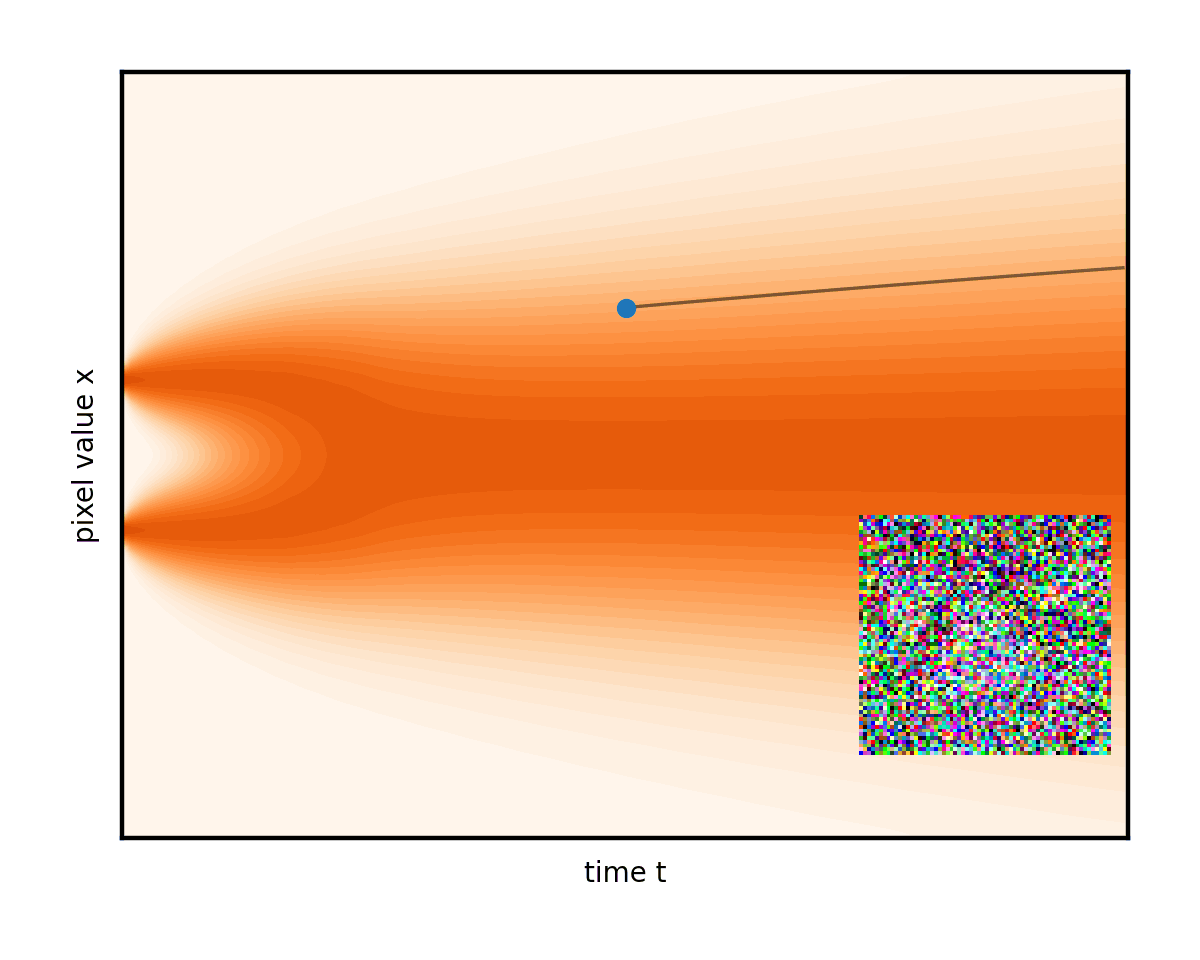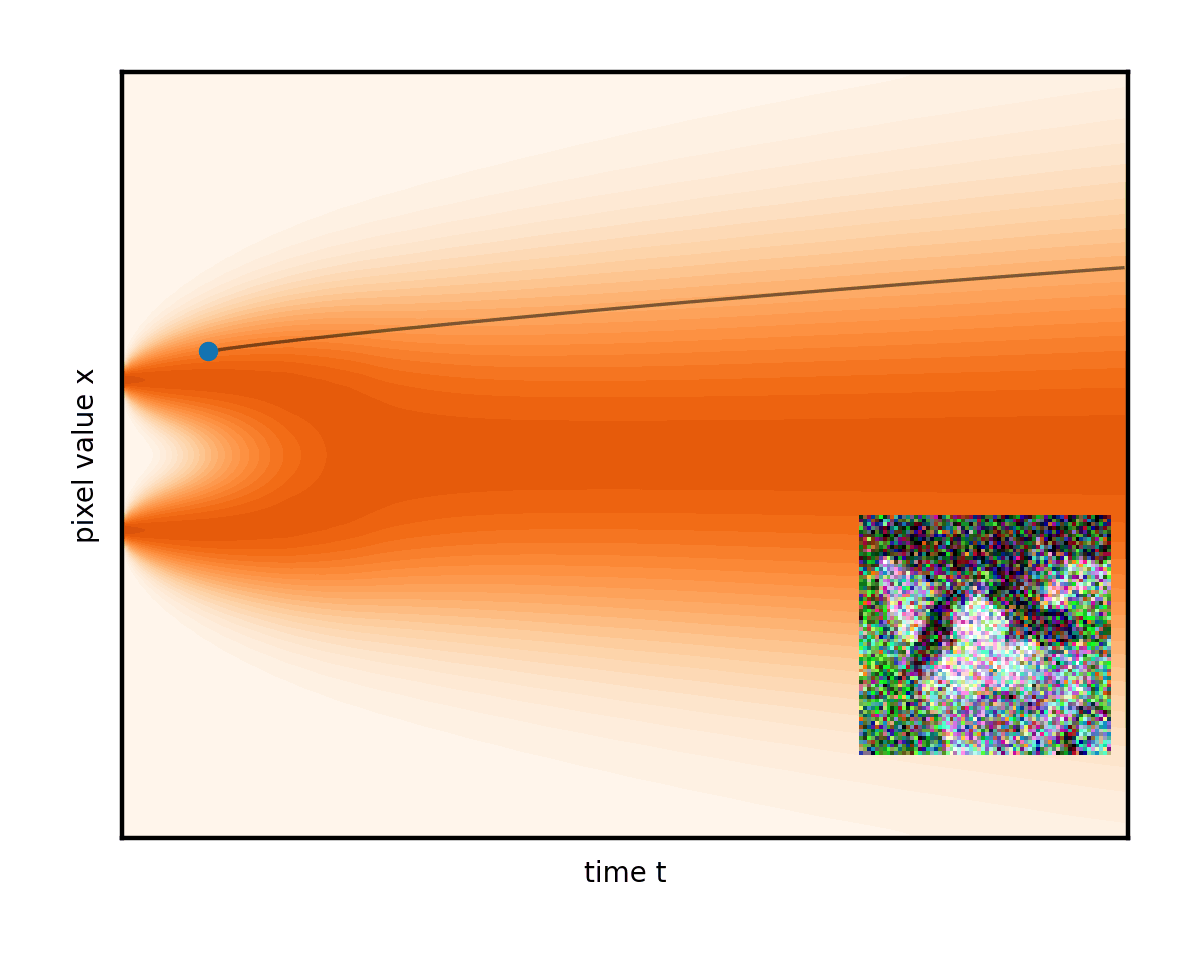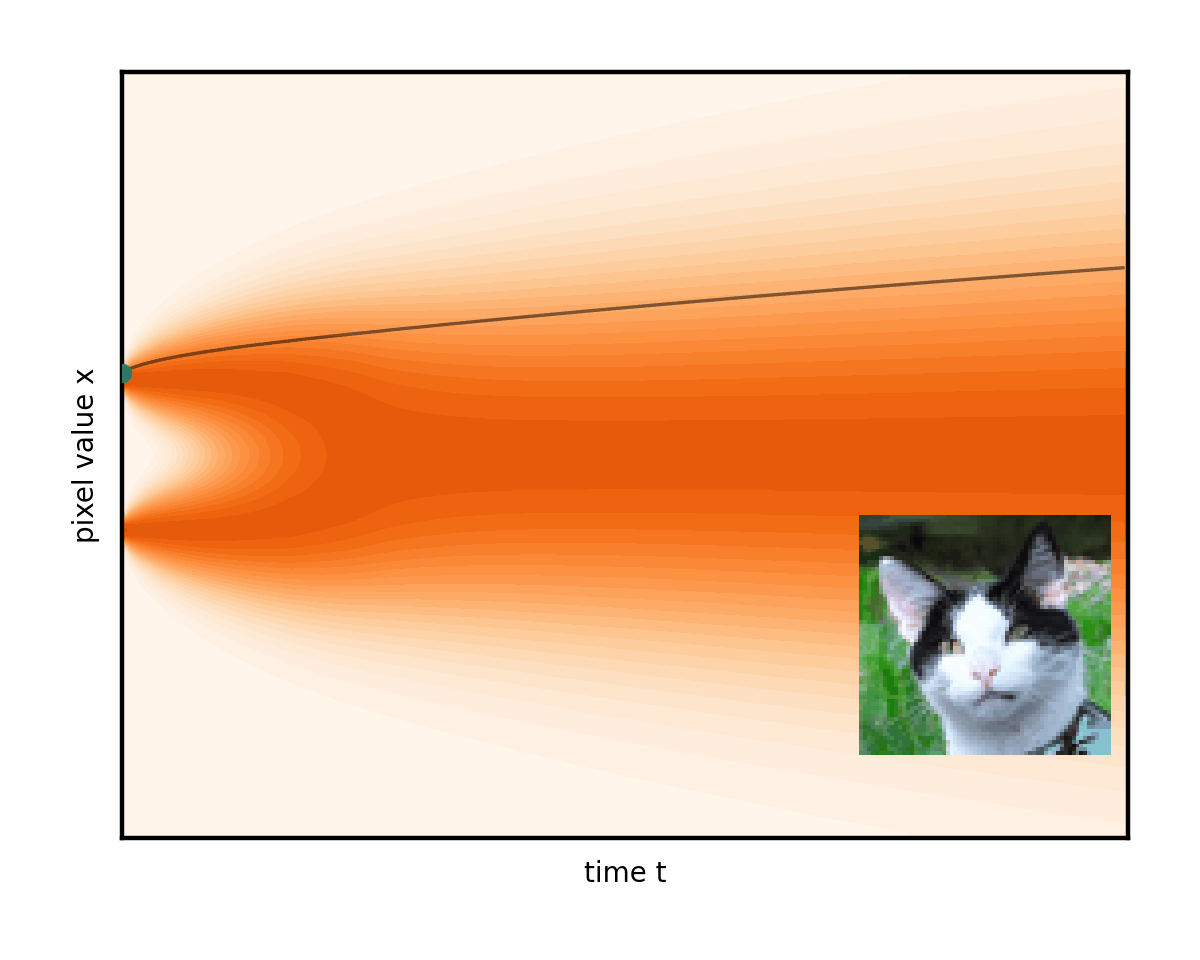
微分方程的一個優點是它們具有直觀的幾何解釋。您可以將這一過程視為圖像在像素值空間中進行類似布朗運動(著名的 Brownian 運動或 Wiener 過程)的隨機漫步。如果您將x視為僅僅是一個數字(“單像素圖像”),那么您可以根據下圖來描繪其變化過程。真實情況與此完全相同,只不過是在更高維度上進行,因此無法在二維顯示器上直觀顯示。
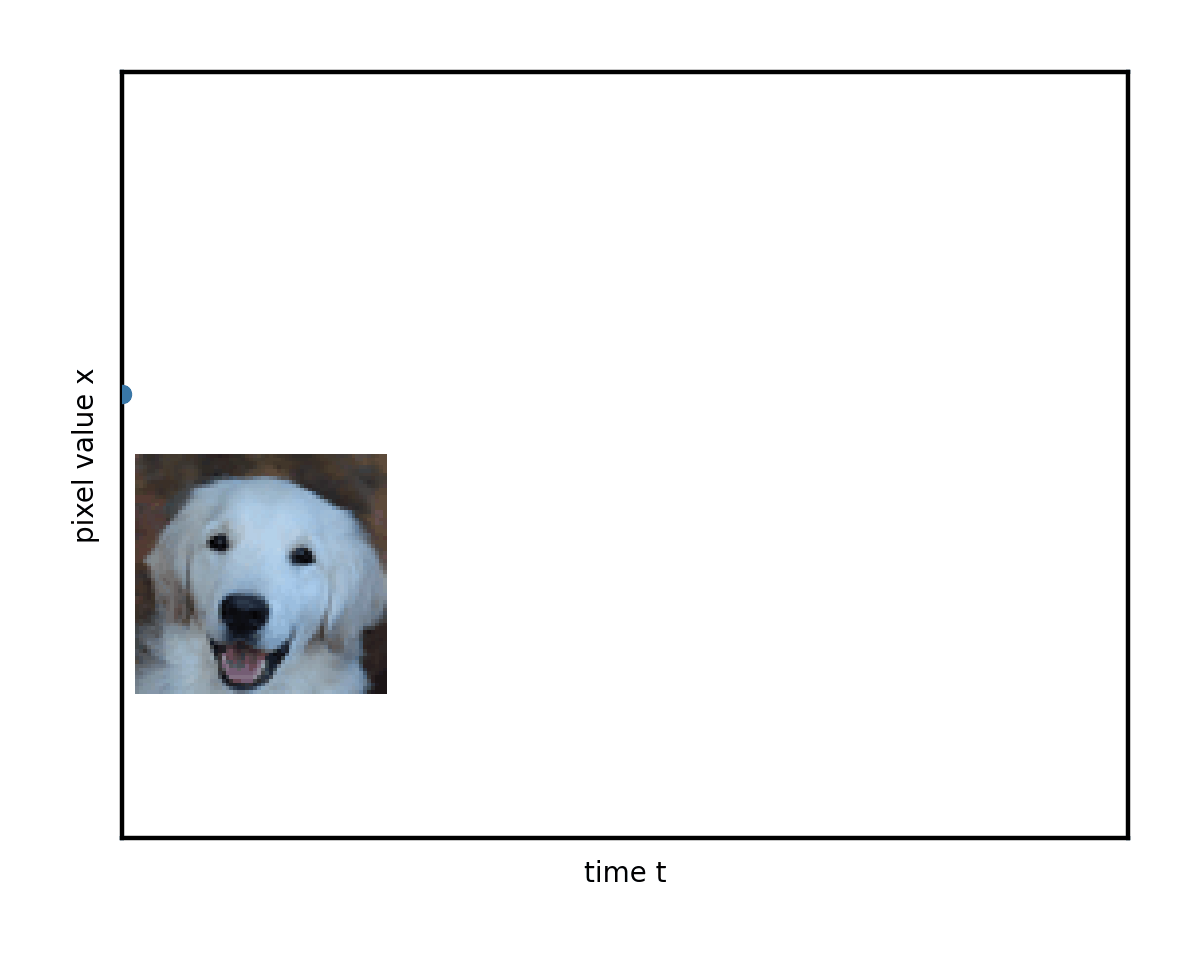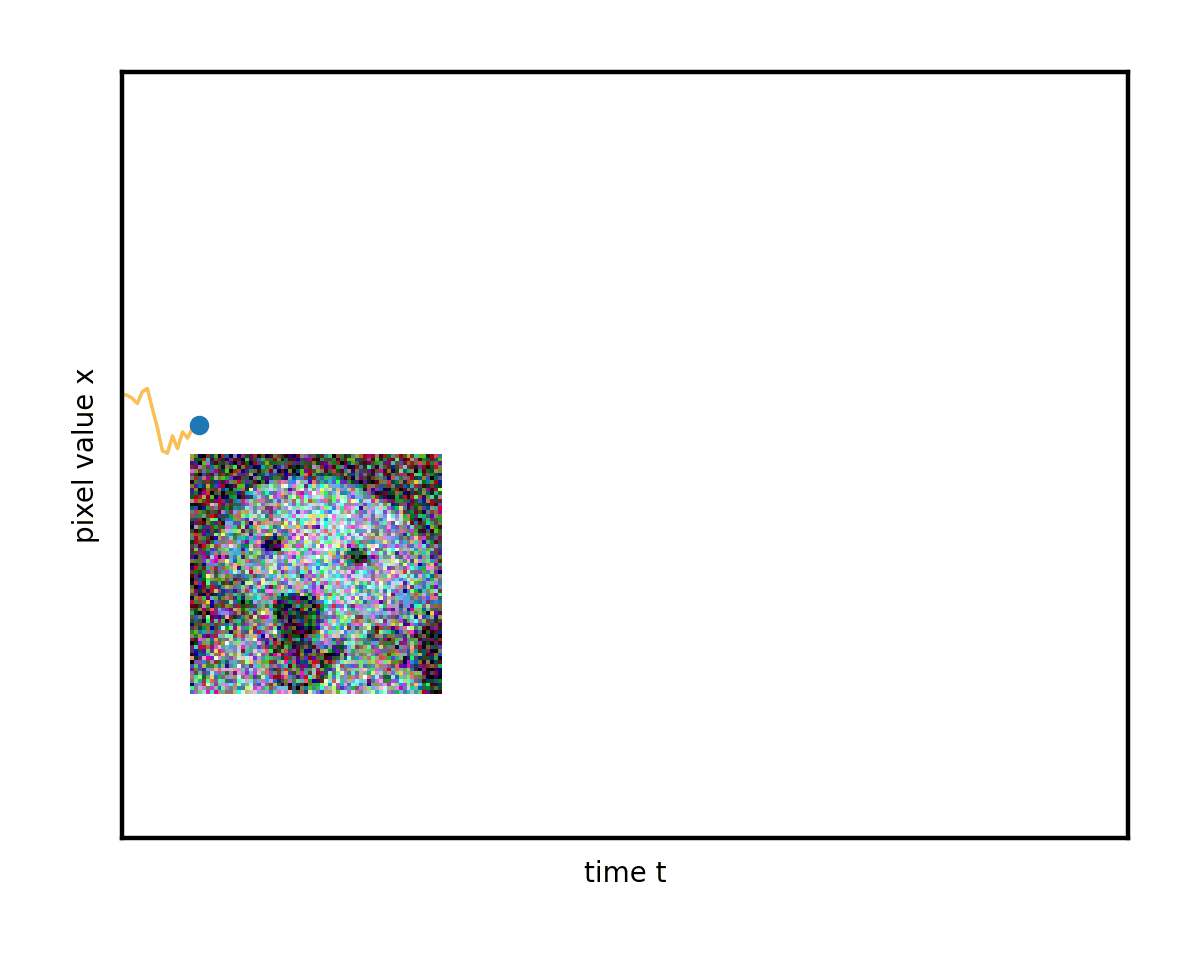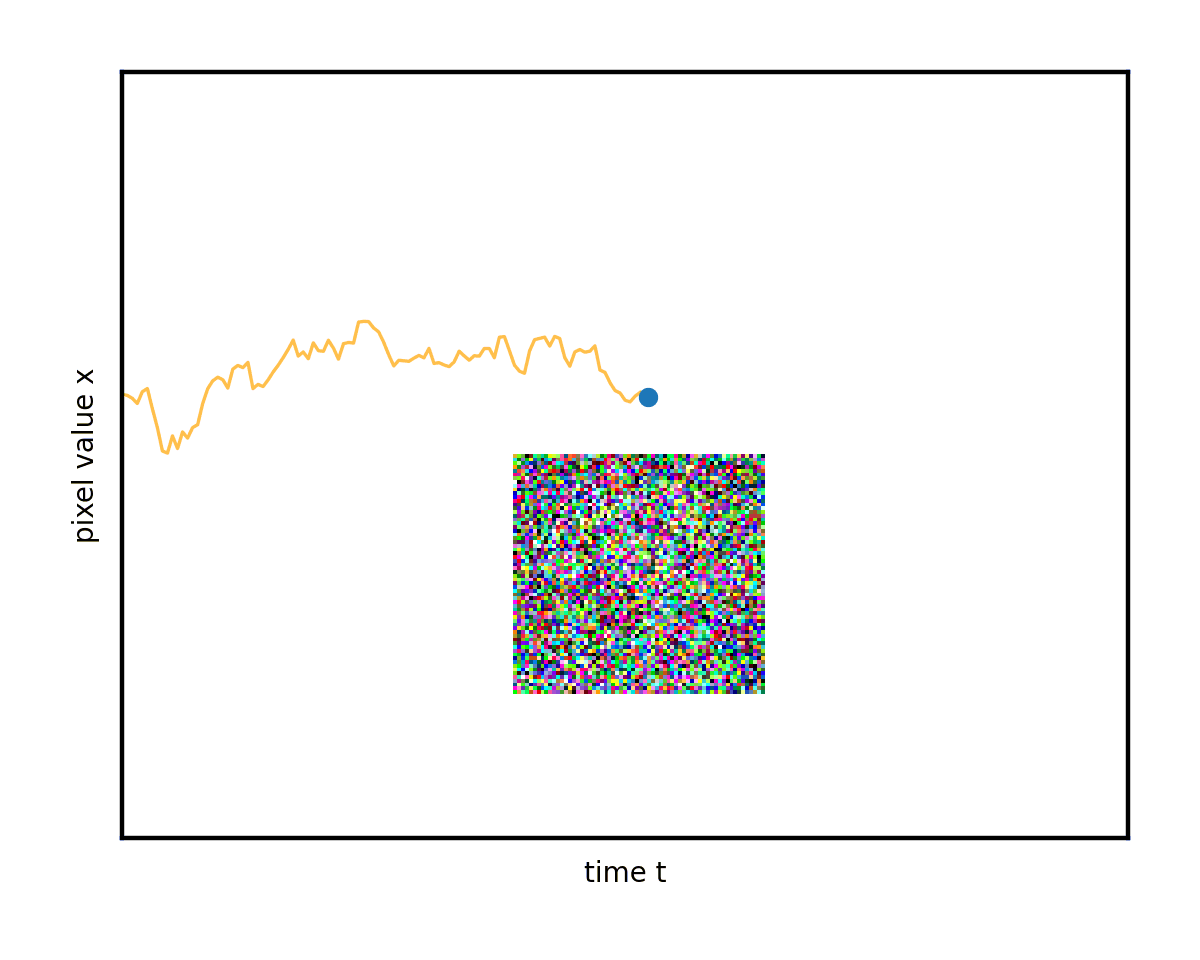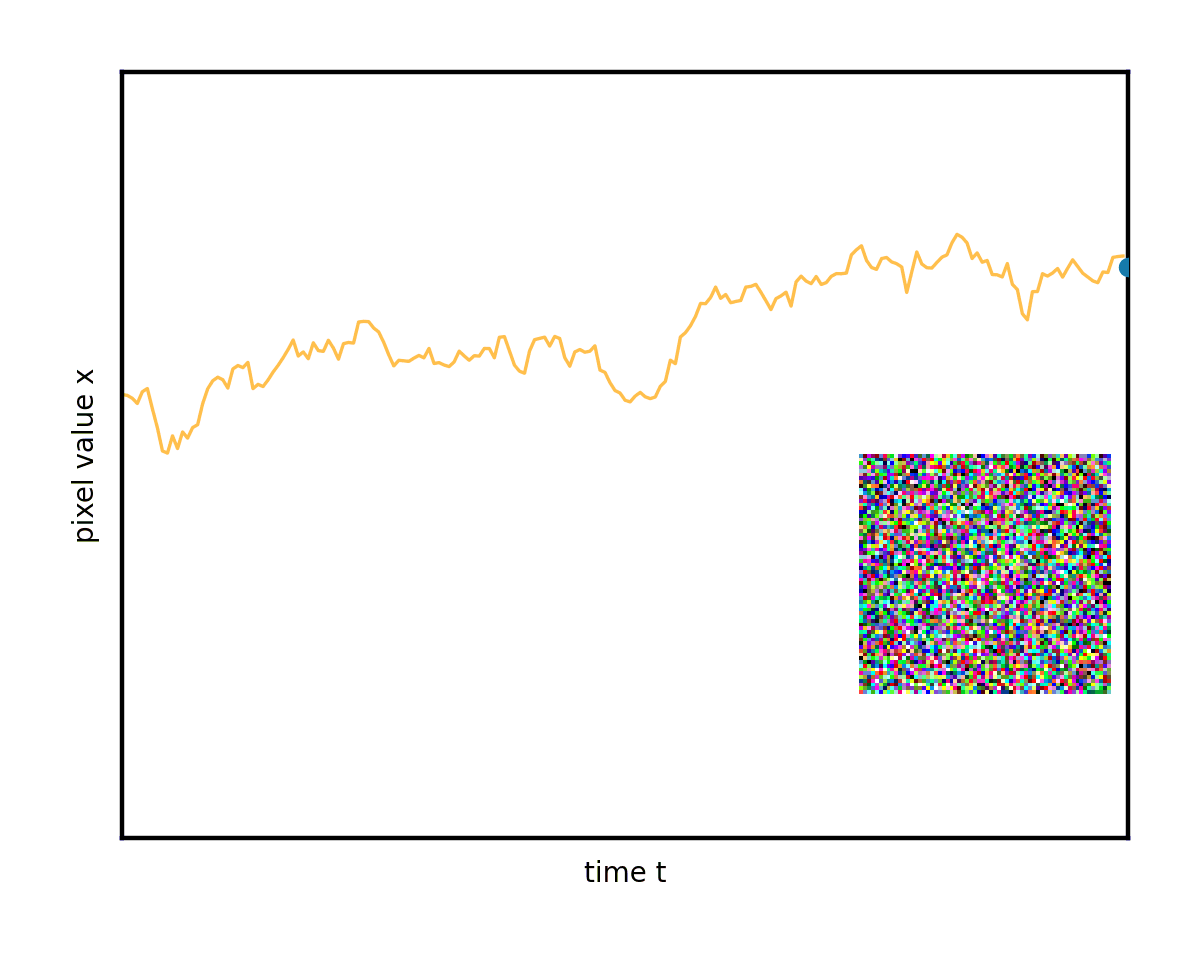
通過使用許多不同的起始圖像和隨機路徑研究這種演變,您開始看到混亂中的一些順序。想象一下,這些彎曲的路徑堆疊在一起。它們平均會隨著時間的推移而改變形狀。
左邊緣的復雜數據模式(您可以隱喻性地想象分別對應于貓和狗圖像的兩個峰值)逐漸混合并簡化為右邊緣的無特征 Blob.這是無處不在的正態分布或純白色噪聲。
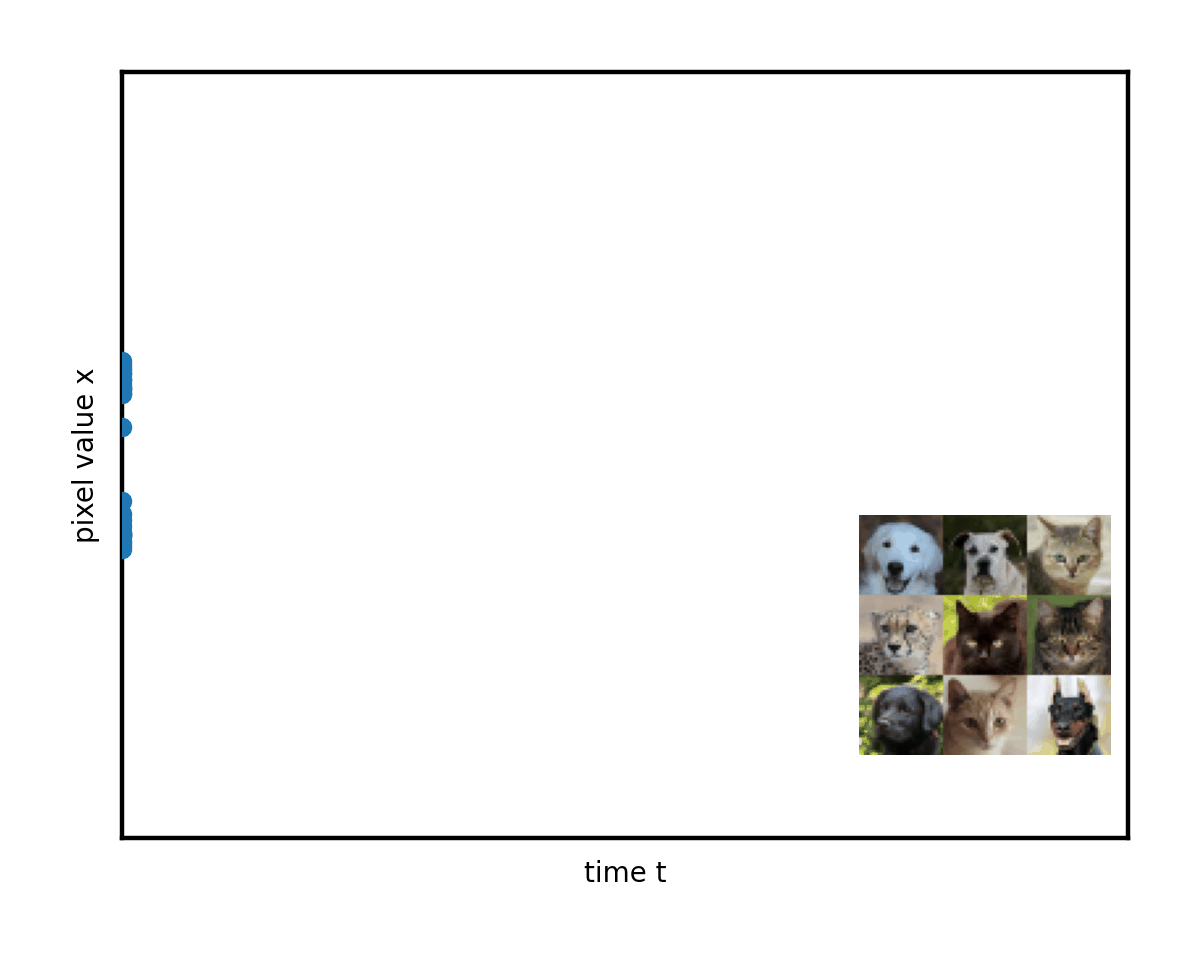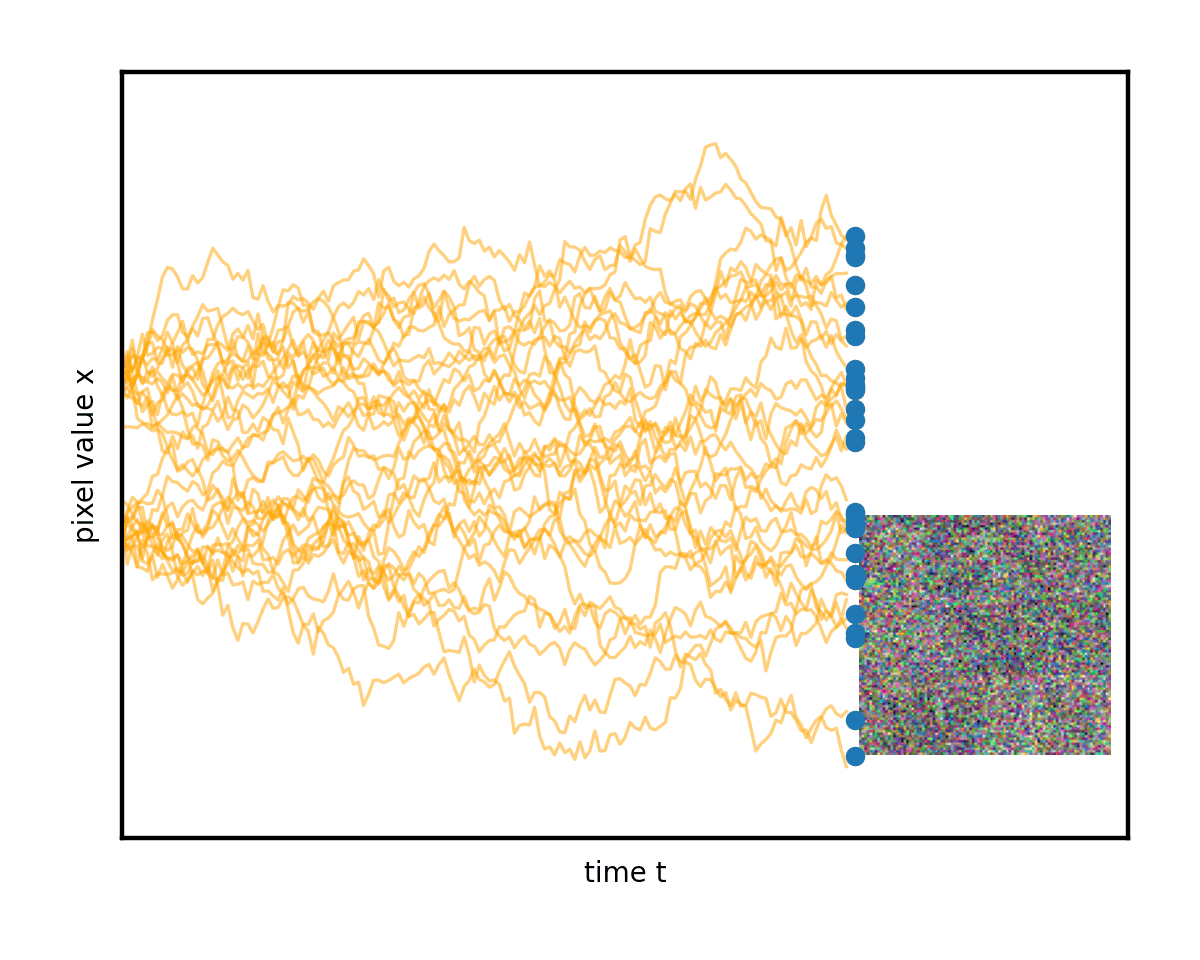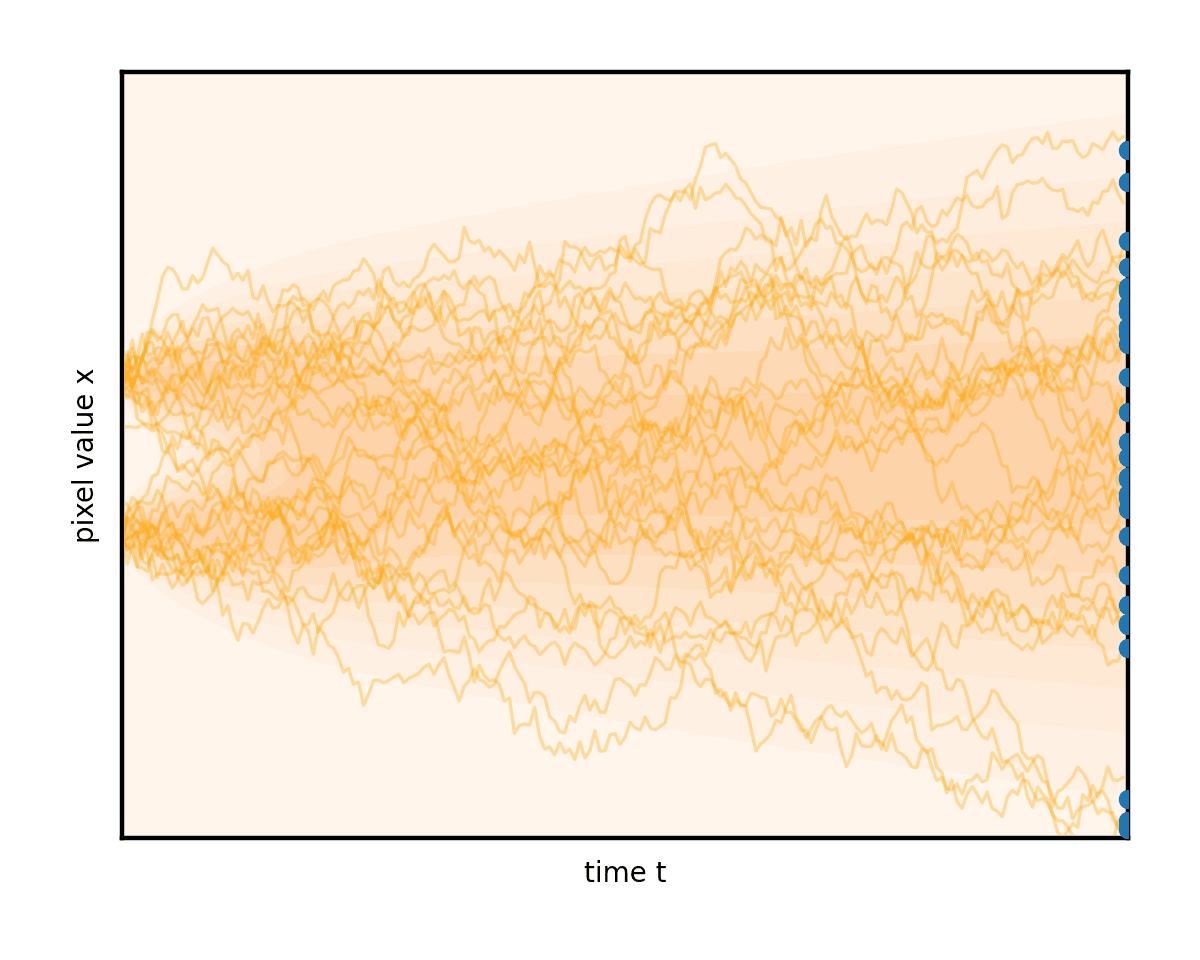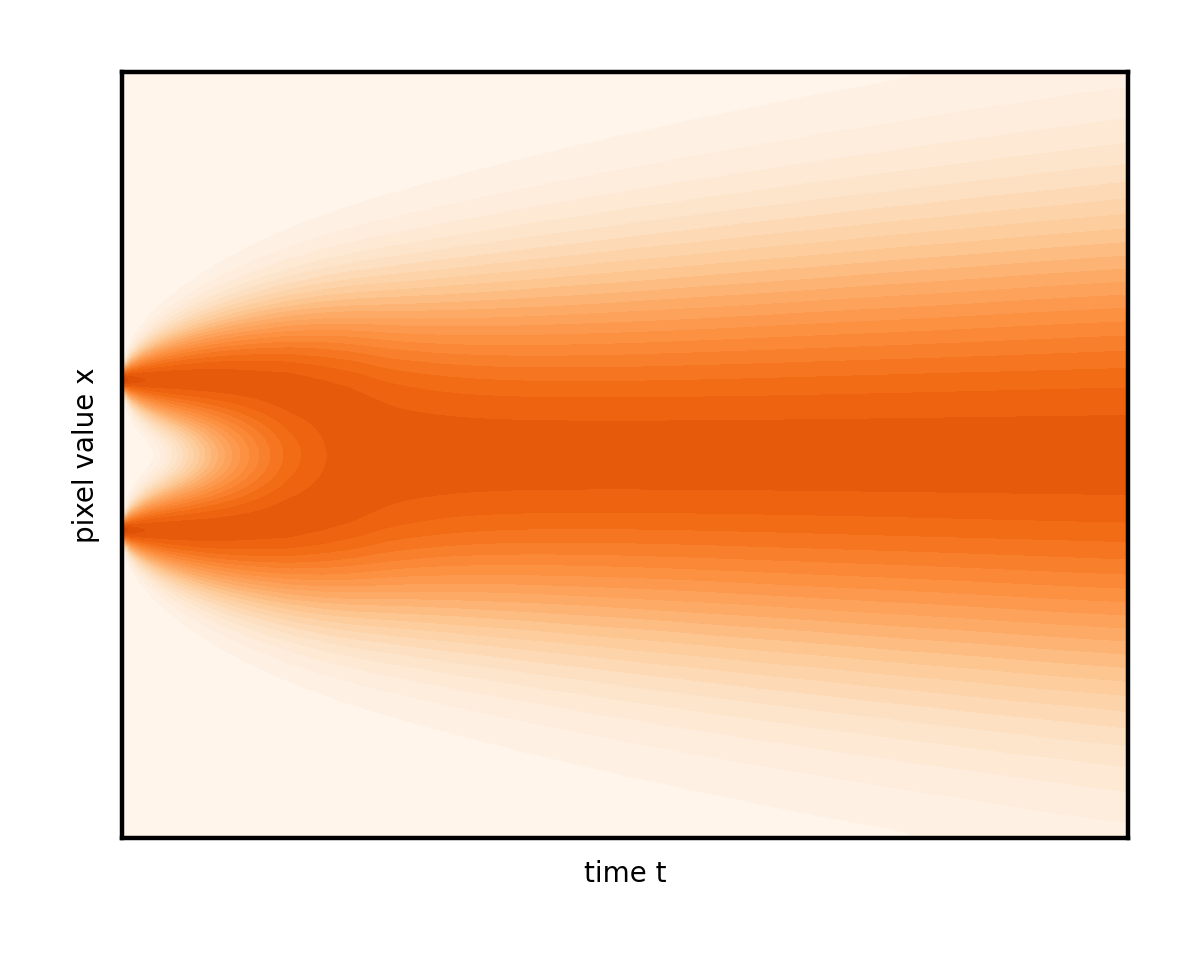
高級目標(生成建模)是以某種方式找到從圖 4 左側真實隱藏數據分布中對新圖像進行采樣的技巧,即實際的新圖像,可能位于數據集中,但.您可以輕松地從右側的純噪聲狀態中進行采樣,使用randn.是否可以反向運行上述降噪過程,以隨機采樣干凈的圖像結束(圖 5)?
遵循從右邊緣開始的隨機路徑后,有什么能保證左邊緣有正確的圖像,而不僅僅是更多的噪點?需要額外的力量來將圖像朝著每個步驟的數據輕輕拉取。
SDE 的理論提供了一個很好的解決方案。在不深入探討技術細節的情況下,它確實可以反轉時間方向,這樣做就會自動為受歡迎的數據吸引力引入一個額外的術語。該力將噪聲圖像拉向均方優化降噪。這可以通過經過訓練的神經網絡進行估計(此處,sigma 是當前的噪聲級別):
您甚至可以調整這兩個術語的權重,前提是您注意保持降噪總速率不變。將此想法帶到消除噪音的極限只會導致完全確定性的普通微分方程(ODE),完全沒有隨機分量。然后演變遵循平滑的軌跡,圖像只是從固定噪聲下方逐漸消失(圖 6)。
請注意圖 6 中的曲線軌跡如何將右邊緣的初始隨機噪聲連接到左邊緣唯一生成的圖像。事實上,ODE 為每個初始噪聲建立了不同的軌跡。將這些曲線想象成推動我們的圖像的流體的流線。在生成過程中,任務只是簡單地從一開始就盡可能準確地遵循流線。從右側的隨機點開始,在每個步驟中,公式(實際上是降噪器網絡)都會顯示流線指向當前圖像的位置。在其方向上英寸一點并重復。這就是生成過程。
圖 7 顯示求解器的每個步驟都會將時間向后推進選定的數量 (dt),并參考 ODE 公式(以及降噪器網絡),以確定如何在時間步長內更改圖像。
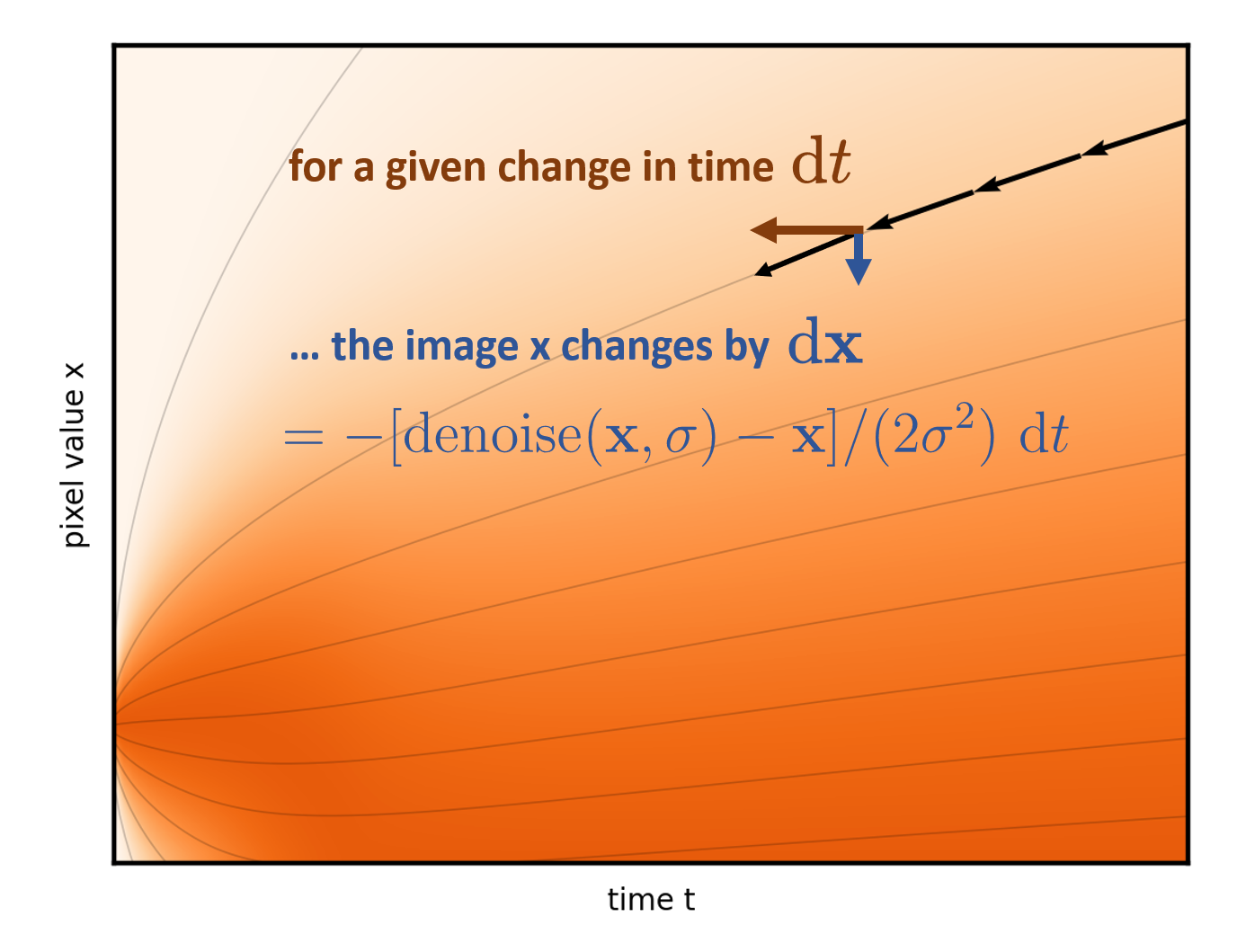
后續部分僅分析確定性版本,因為隨機性模糊了確定性圖片提供的幾何見解。盡管隨機性在適當調整后具有有益的糾錯特性,但其使用起來相對繁瑣,可以視為一種輔助手段。有關更多詳細信息,請參閱闡明基于擴散的生成模型的設計空間。
用于采樣以生成圖像的設計選擇
正如簡介中所述,是決定性能的細節。關鍵的困難在于網絡給出的步進方向是有效的僅在當前噪聲級別附近.嘗試在不停止重新評估的情況下立即減少過多的噪點會導致在圖像中添加不應該存在的內容。這表現為不同程度的圖像質量降低:難以形容的模糊和顆粒化、顏色和強度偽影、面部失真和缺乏一致性以及其他更高級別的細節等。
在 1D 可視化中,這對應于從起始流線開始的步長,如圖 8 所示。請注意箭頭(表示可能采取的步長)與曲線之間的空隙。
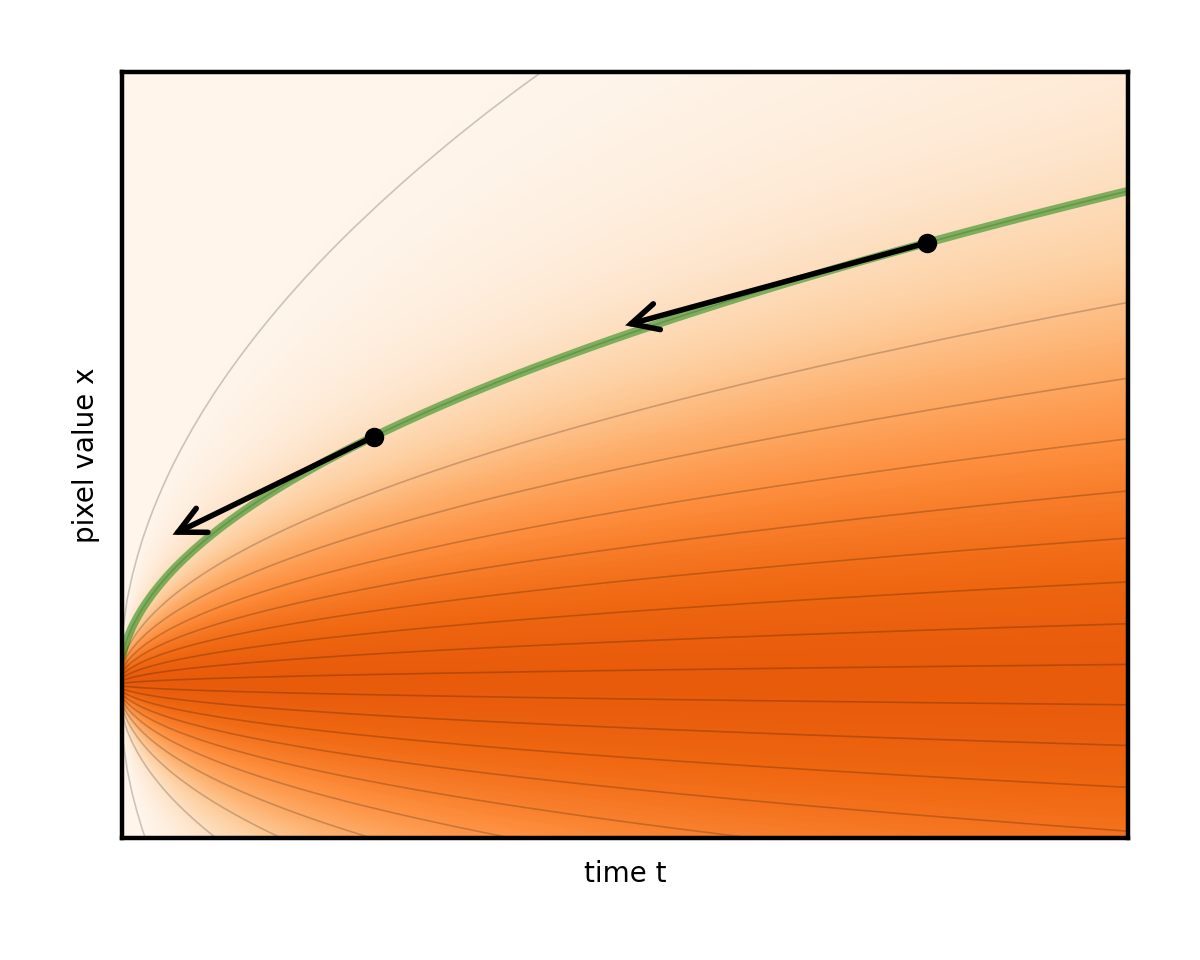
常見的強力解決方案是簡單地執行大量極短的步驟,以避免被丟棄。但是,這很昂貴,因為每個步驟都需要對降噪器網絡進行完整的評估。這就像爬行而不是運行:安全但緩慢。
我們的采樣器設計在不影響質量的情況下大幅減少了所需步驟的數量。策略有三個方面:
- 設計 ODE,使其流線盡可能筆直,因此易于遵循 (噪音調度)
- 確定哪些噪聲級別仍需額外小心步進 (時間步長離散)
- 采取更明智的步驟,充分利用每個(高階求解器)
理順流程以減少步驟
問題的關鍵在于流線的曲率。如果它們是直線,就很容易遵循。可以采取一個漫長的直線步驟,一直到噪聲級別 0,而不必擔心從曲線上掉下來。實際上,一些曲率是不可避免地內置在設置中的。能否減少?
事實證明,上一節中開發的理論在這方面做出了一些糟糕的選擇。例如,您可以通過指定不同的噪聲表來構建不同版本的 ODE.回想一下,1D 可視化是通過在每個步驟中添加相同數量的噪聲來構建的。如果以不同的時變速率添加,則會在不同的時間(不同的時間表)達到每個噪聲級別。這相當于延伸和壓縮時間軸。
圖 9 顯示了幾個不同的 ODE,這些 ODE 是由不同的噪聲表選項引起的。
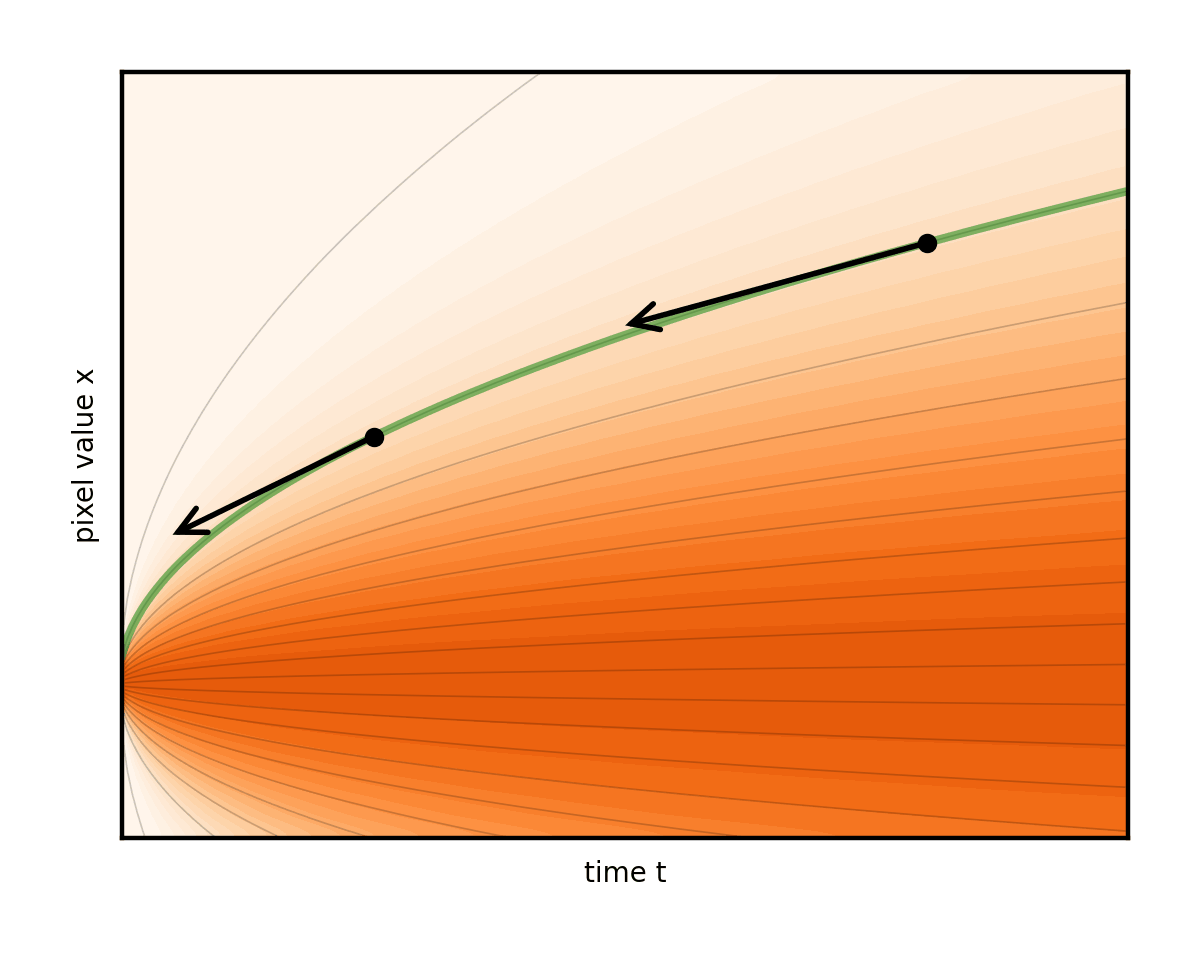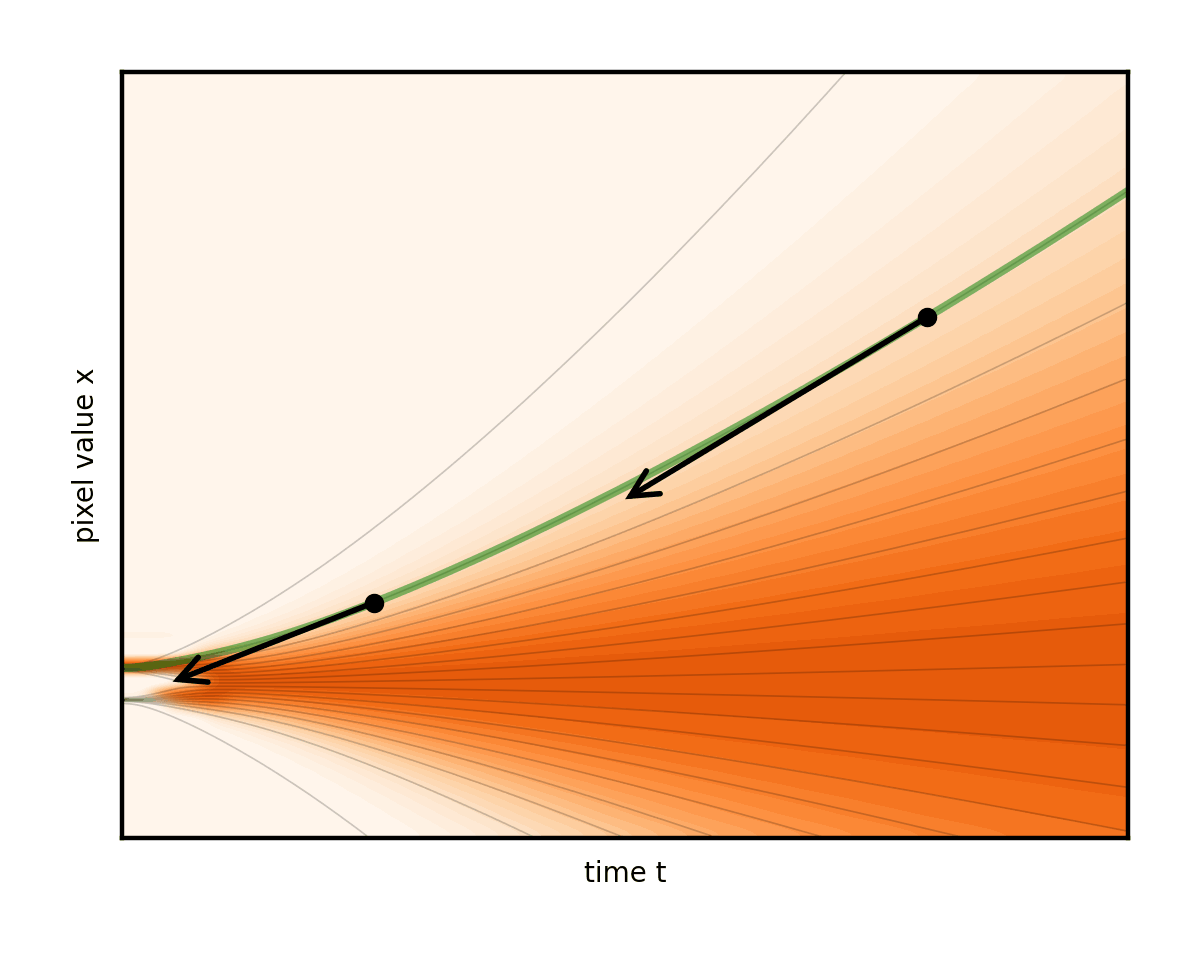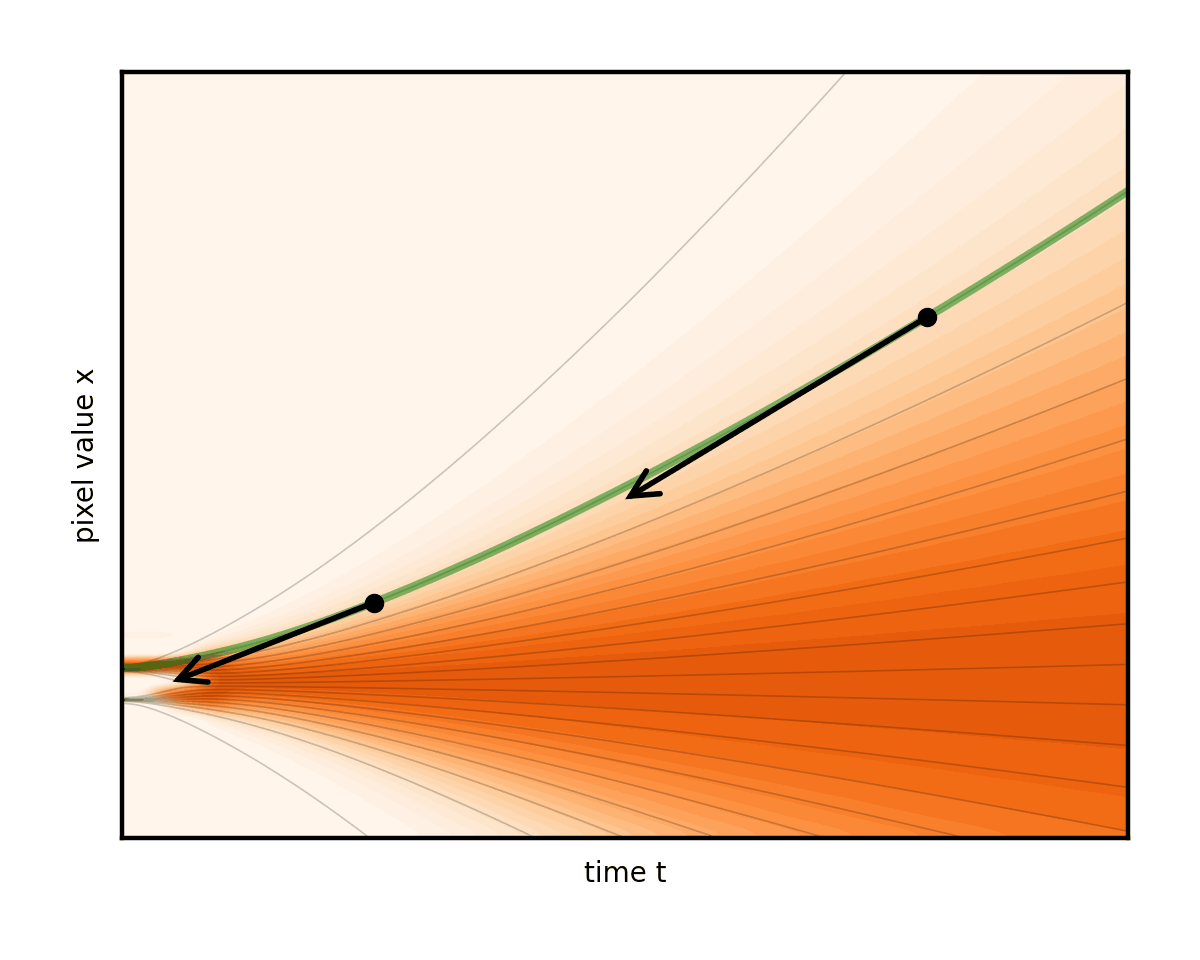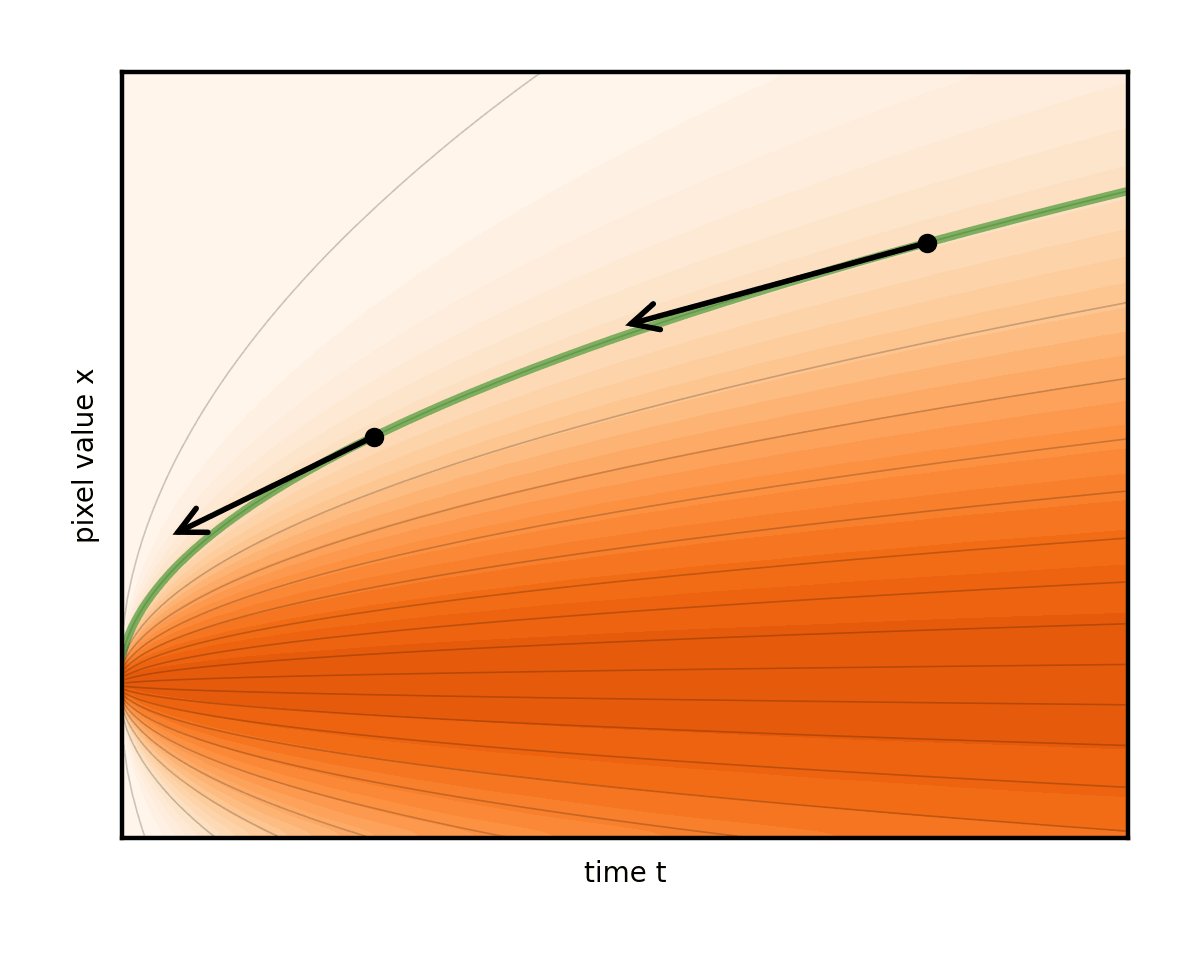
請注意,這會產生重構流線的副作用。事實上,這些線在其中一個調度表中幾乎是筆直的。這確實是團隊所主張的。表示步驟的箭頭現在幾乎與曲線完全對齊。因此,與其他選擇相比,可以減少很多步驟(圖 10)。
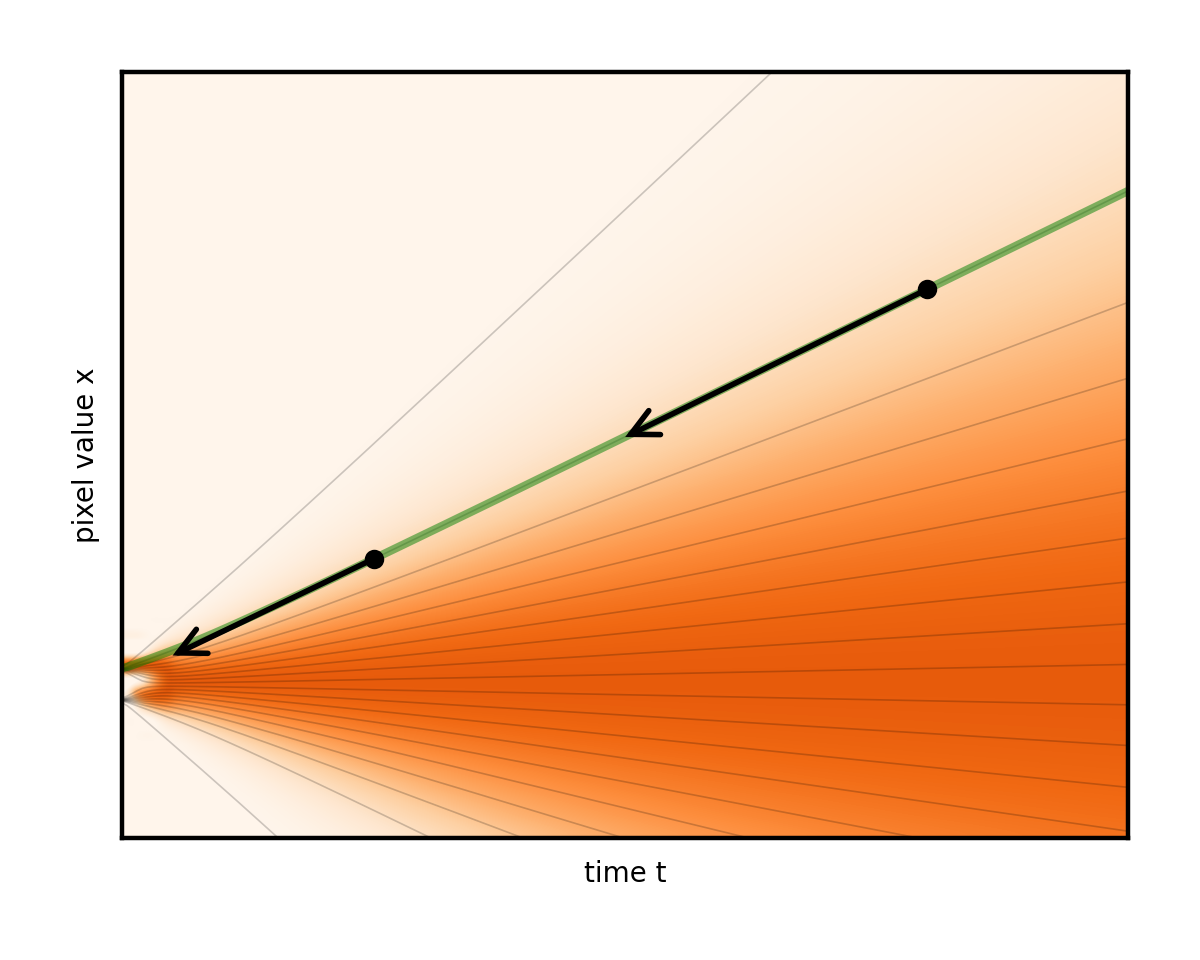
圖 10 顯示了隨著時間的推移,噪音水平呈線性增長的進度。與先前的固定速率加法示例相比,噪音水平最初快速增長,但隨后放慢。換言之,時間成為噪音水平的代名詞。在不深入討論此處的技術細節的情況下,這一特定選擇提供了非常直觀的求解器算法。這是我們論文中的算法 1,沒有可選的第 6 行到第 8 行,使用了建議的時間表,并在經過一些整理之后:
# a (poor) placeholder example time discretizationtimesteps = np.linspace(80, 0, num_steps)?
# sample an image of random noise at first noise levelx = torch.randn(img_shape) * timesteps[0]?
# iterate through pairs of adjacent noise levelsfor t_curr, t_next in zip(timesteps[:-1], timesteps[1:]):?
????# fraction of noise we keep in this iteration????blend = t_next / t_curr?????????# mix in the denoised image????x = blend * x + (1-blend) * denoise(x, t_curr) |
代碼僅對簡介中提到的內容進行了輕微的泛化處理,其實并沒有比這更簡單的了。這個算法如此簡單,以至于人們會好奇,為什么它沒有在 2015 年以啟發式算法的形式被提出 —— 也許當時這個想法看起來太過荒謬,不切實際。順便提一下,2015 年的論文討論了降噪擴散,使用無平衡熱力學的深度無監督學習,但是措辭包含了復雜的數學術語。多年來,其潛在價值一直未受到足夠的重視。
在低噪音水平下小心步進
這清楚地凸顯了另一種設計選擇,在大多數處理中,這種選擇是模糊的,并且與噪點安排糾結在一起:時間步長的選擇。先前代碼片段中使用的線性間距實際上是一個糟糕的選擇。從經驗(以及根據自然圖像統計推理)來看,很明顯,細節在低噪點附近顯示得更快。在 1D 可視化中,圖形右側的大部分幾乎沒有發生,但隨后流線突然轉向左側的兩個池中的一個。這意味著在高噪點級別下可以實現長步長,但在接近低噪點級別時必須放慢速度(圖 11)。
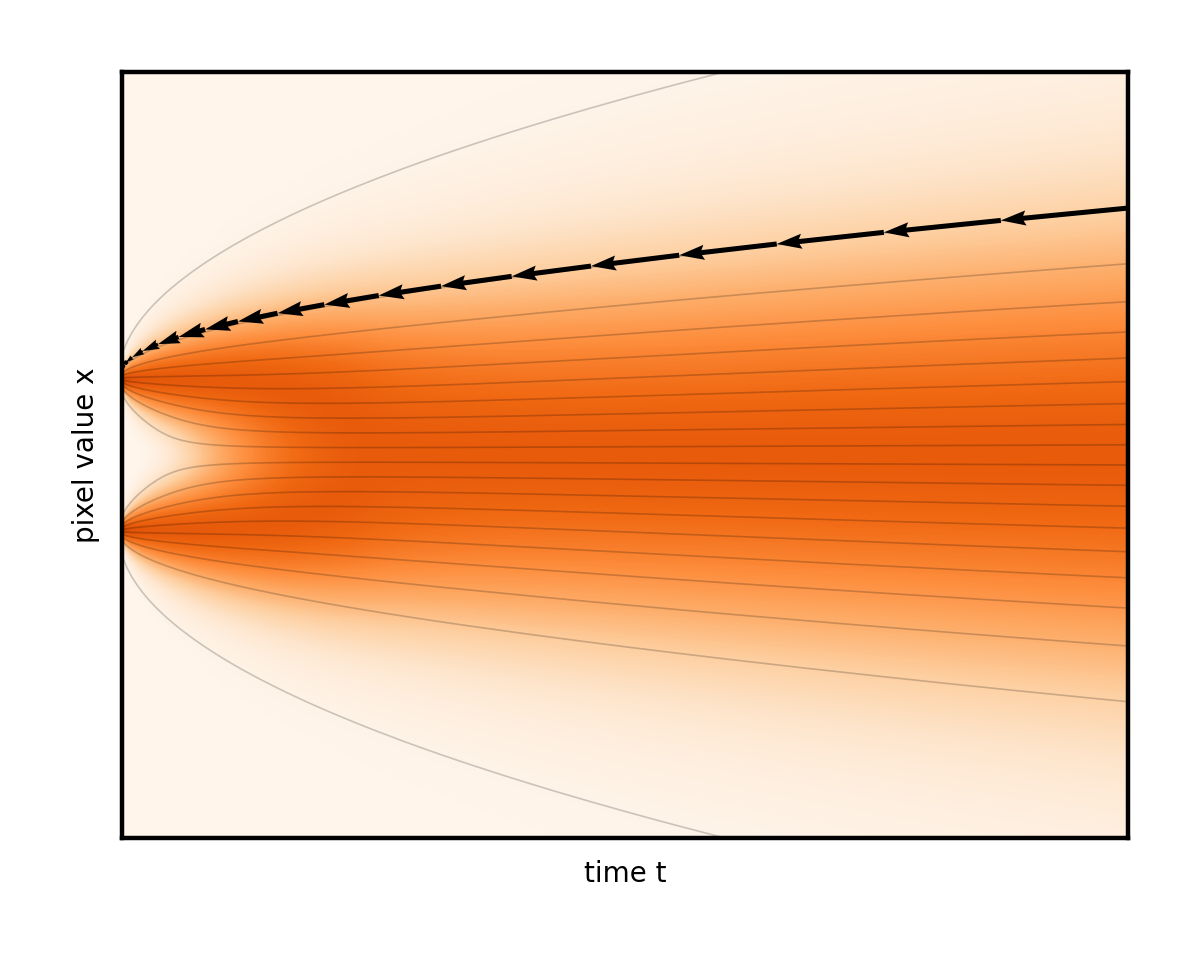
我們的論文以經驗為基礎,研究了在低噪聲級別與高噪聲級別下,步長的相對長度。以下代碼片段對時間步長作出了簡單而可靠的修改。大致上,將其中的數字提高到 7 的(注意將其擴展到 0 到 80 的原始范圍)。這嚴重偏移了低噪聲級別的步長:
sigma_max = 80sigma_min = 0.002?? # leave a microscopic bit of noise for stabilityrho = 7?
step_indices = torch.arange(num_steps)timesteps = (sigma_max ** (1 / rho) \??????????+ step_indices / (num_steps - 1) \????????????* (sigma_min ** (1 / rho) - sigma_max ** (1 / rho))) ** rho |
高階求解器,可實現更準確的步驟
ODE 視點支持使用更精致的高階求解器,該求解器本質上采用曲線而不是線性步驟。這在嘗試遵循曲線流線時顯得尤為有利。盡管如此,其優勢并不總是明顯,因為估計局部曲率需要額外的神經網絡評估。團隊測試了一系列方法,并一致認為所謂的二階 Heun 方案是最佳選擇(見圖 12)。這需要在代碼中添加幾行(詳見闡明基于擴散的生成模型設計空間的算法 1),雖然每次迭代的成本翻倍,但所需的迭代次數卻減少到了一小部分。
Heun 步驟具有很好的幾何解釋和代碼中的簡單實現。像以前一樣采取初步步驟,然后采取第二步,從著陸點返回一半。注意最終校正步驟如何比原始步驟更接近實際流線(圖 12)。
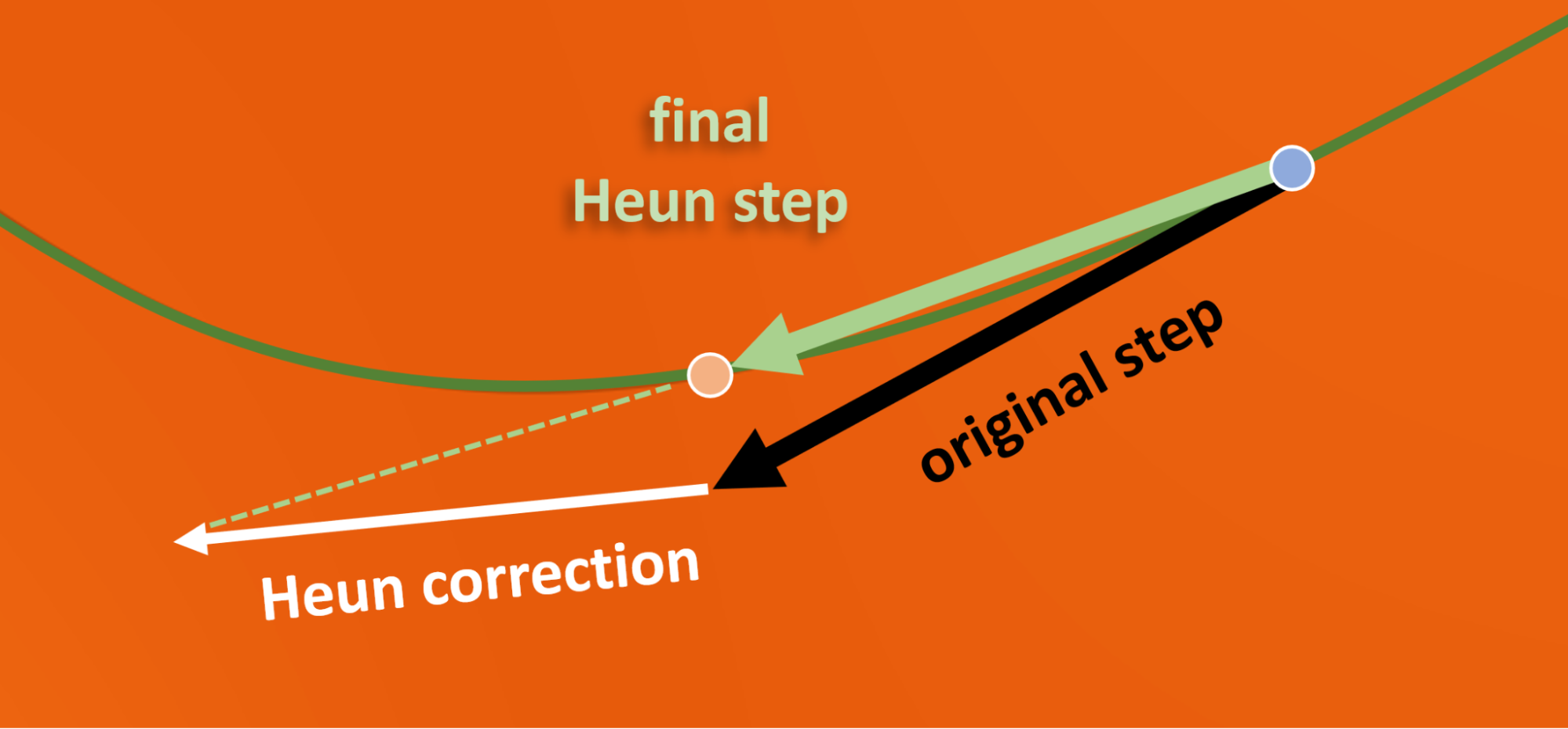
結合所有這些改進,現在只需對降噪器進行 30 到 80 次評估即可,而在之前的大多數工作中,評估降噪器的次數是 250 到 1000 次。
用于訓練降噪器的設計選擇
這是一個流暢高效的降噪步驟鏈。到目前為止,我們假設每個步驟都可以稱為易于訓練的降噪器denoise (x, sigma)輸入噪點圖像和指示其噪點級別的數字。但如何對其進行 參數化和訓練以獲得最佳結果?
理論上有效的此類網絡訓練的最基本形式(此處 PyTorch 模塊實例化為denoise)看起來類似于以下內容:
# WARNING: this code illustrates poor choices across the board!?
for clean_image in training_data:?? # we’ll ignore minibatching for brevity?
????# pick a random noise level to train at????sigma = np.random.uniform(0, 80)?
????# add noise with this level????noisy_image = clean_image + sigma * torch.randn_like(clean_image)?
????# feed to network under training????denoised_image = denoise(noisy_image, sigma)?
????# compute mean square loss????loss = (denoised_image - clean_image).square().sum()?
????# ... plus the usual backpropagation and parameter updates |
該理論要求使用白噪點和均方損失,并觸及打算用于采樣的所有噪聲級別。在這些限制范圍內,可以很大程度上重新排列計算。以下小節確定并解決了本代碼中的每個嚴重實際問題。
請注意,網絡架構本身將不會得到解決。本次討論在很大程度上是正交的,與層數量、形狀和大小、注意力或轉換器的使用等無關。對于論文中的所有結果,都采用了之前工作中的網絡架構。
網絡友好型數值大小
根據經驗,我們已將這些示例中的最大噪點級別選為足夠大的數字,以完全淹沒圖像。因此,有時會向降噪器饋入像素值大約在 -1 到 1 范圍內的圖像(當噪點級別非常低時),有時還會饋入超出 – 100 到 100 范圍的圖像。這會引發紅旗,因為眾所周知,如果神經網絡的輸入在不同示例之間的規模上存在巨大差異,則會受到不穩定訓練和最終性能不佳的影響。 來標準化規模。
有些人通過修改 ODE 本身來解決這一問題,例如,采樣過程使噪聲圖像保持在固定幅度范圍內,而不是允許其隨著時間的推移而擴展(即所謂的保持差異 擴展時間表)。遺憾的是,這再次扭曲了流線,破壞了上一節中介紹的拉直的好處。
下面是一個不存在此類數值缺點的簡單解決方案。噪聲級別是已知的,因此只需將噪聲圖像擴展到標準大小,然后再將其輸入到網絡中即可。它將通過訓練自動適應不同的比例約定,但會消除有問題的范圍變化。
要做到這一點,最好的方法是保持denoise從外部調用者(ODE 求解器和訓練循環)的角度來看沒有變化,但在內部改變其利用網絡的方式。將實際的原始網絡層隔離到自己的黑子模塊中net并使用大小管理代碼(“preconditioning”)將其包裝在denoise:
sigma_data = 0.5??? # approximate standard deviation of ImageNet pixelsdef denoise(noisy_image, sigma):????noisy_image_variance = sigma**2 + sigma_data**2????scaled_noisy_image = noisy_image / noisy_image_variance ** 0.5????return net(scaled_noisy_image, sigma) |
此處,噪聲圖像除以其預期標準差,使其大致達到單位方差。
作為次要細節(未在此處顯示),同樣也會將噪聲級別標簽輸入扭曲為net使用對數函數使其更均勻地分布在 -1 到 1 的范圍內。
預測圖像與噪聲
如果您熟悉現有的擴散方法,您可能已經注意到,大多數方法訓練網絡來預測噪聲(單位方差),而不是訓練清晰的圖像,而是將其明確擴展到已知的噪聲級別sigma然后通過從輸入中減去來恢復降噪圖像。
事實證明,特別是在低噪聲級別下,這是個好主意,但在高噪聲級別下,則是個壞主意。由于大多數圖像細節在相對較低的噪聲級別下會突然顯示出來,因此好處大于缺點。
為什么在低噪聲級別下這樣做是個好主意?這種方法從輸入中回收近乎清晰的圖像,并且僅使用網絡向其添加少量的噪聲校正。重要的是,網絡輸出顯式縮小(通過sigma)來匹配噪聲級別。因此,如果網絡發生了一些錯誤(就像往常一樣),該錯誤也會縮小,并且沒有機會搞亂圖像。這可以最大限度地減少不可靠的學習網絡的貢獻,并最大限度地重復使用輸入中已知的內容。
為什么在高噪聲級別下這是個壞主意?它最終會根據大噪聲大小提高網絡輸出。因此,網絡發生的任何小錯誤現在都會成為降噪器輸出中的大錯誤。
更好的選擇是持續過渡,其中網絡=預測(負)噪聲和清晰圖像的噪聲級別相關混合。然后將其與適當數量的噪聲輸入混合,以消除噪聲。
本文介紹了一種計算混合權重作為噪聲級別函數的原則性方法。確切的統計參數在某種程度上涉及,因此本文不會嘗試完整復制它。基本上,它詢問的是導致網絡輸出放大最小的混合系數。實現非常簡單。最后一個返回行替換為以下代碼,其中c_skip和c_out混合因子分別控制輸入的回收量和網絡的貢獻量。
return c_skip * noisy_image + c_out * net(scaled_noisy_image, sigma) |
均衡噪聲級別的梯度反饋大小
完成降噪器內部結構后,本節將解決 straw-man 訓練代碼片段中的噪聲級別問題。不對損失應用任何與噪聲級別相關的縮放是一種(較差)隱性選擇。就像編寫了以下內容:
weight = 1loss = weight * (denoised_image - clean_image).square().sum() |
問題在于,由于降噪器內部的各種縮放,此損失值對于某些噪聲級別來說很大,而對于其他噪聲級別來說則較小。因此,對網絡權重進行的更新(梯度反饋)的大小也將取決于噪聲級別。這就像對不同的噪聲級別使用不同的學習率,沒有充分的理由。
在另一種情況下,統一大小會導致訓練更加穩定和成功。幸運的是,一個簡單的獨立于數據的統計公式給出了每個噪聲級別的預期損失幅度。weight相應地將大小調整回 1.
分配 訓練工作量
一種很有吸引力的誤用weight還可以根據噪音的相對重要性來衡量噪音水平,以便在需要的地方引導更多的網絡容量。但是,通過在這些重要的噪音水平上更頻繁地進行訓練,可以在不影響強度的情況下實現相同的目標。圖 13 從概念上說明了團隊所主張的勞動分工。
在整個訓練過程中,每個噪聲級別都會為網絡權重提供梯度更新(箭頭)。另外,我們使用兩個各自的機制來控制這些更新的大小和數量。默認情況下,大小(箭頭的長度)和頻率(數量)都不加控制地取決于噪聲級別。該團隊主張進行勞動分工,其中損失擴展會標準化長度,而噪聲級別分布決定在每個級別的訓練頻率。
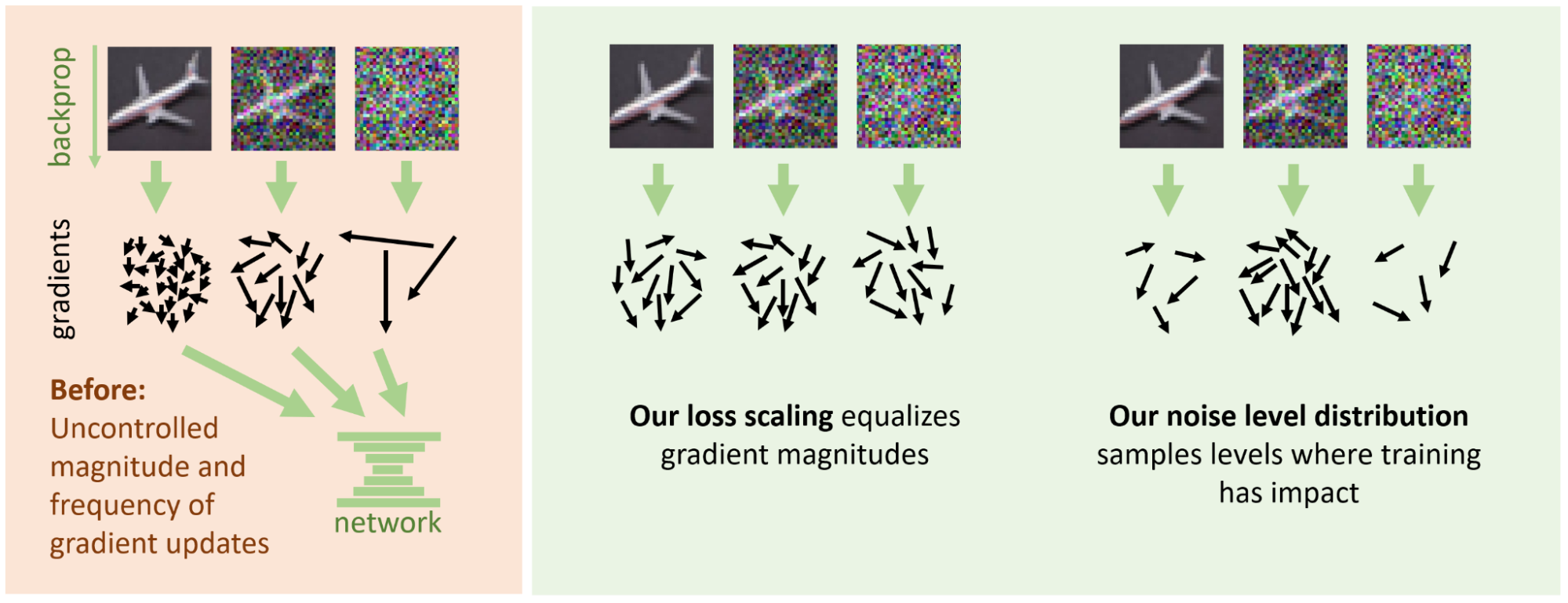
不出所料,從均勻分布中選擇訓練噪聲級別的代碼示例并非易事。該理論在此選擇中提供的指導很少,因為它取決于數據集的特征。在非常低的噪聲級別下,進展極小,因為預測無噪點圖像的噪聲實際上是不可能的(但也無關緊要)。相反,在非常高的噪聲級別下,優化降噪(數據集圖像的模糊平均值)相當容易預測。中間部分提供了可以取得進展的廣泛級別。
在實踐中,我們從公式中選擇了隨機訓練噪聲級別,sigma = torch.exp(P_mean + P_std * torch.randn([]))在哪里P_mean和P_std指定用于訓練的平均噪聲級別,以及該值周圍的隨機化寬度。選擇此特定公式的原因很簡單,因為它是繪制跨多個數量級的非負隨機值的直接啟發式方法。這些參數的值經過經驗調優,但在常規圖像數據集中證明相當可靠。
總結一下,以下是一個最小部分,其中匯集了原始訓練代碼中討論過的所有更改,包括任何省略的公式:
P_mean = -1.2?????? # average noise level (logarithmic)P_std = 1.2???? # spread of random noise levelssigma_data = 0.5??? # ImageNet standard deviation?
def denoise(noisy_image, sigma):????????# Input, output and skip scale????????c_in = 1 / torch.sqrt(sigma_data**2 + sigma**2)????????c_out = sigma * sigma_data / torch.sqrt(sigma**2 + sigma_data**2)????????c_skip = sigma_data**2 / (sigma**2 + sigma_data**2)????????c_noise = torch.log(sigma) / 4????? # noise label warp?
????????# mix the input and network output to extract the clean image????????return c_skip * noisy_image + \???????????????????c_out? * net(c_in * noisy_image, c_noise)?
for clean_image in training_data:?? # we’ll ignore minibatching for brevity???????# random noise level????????sigma = torch.exp(P_mean + P_std * torch.randn([]))?
???????noisy_image = clean_image \????????????????????????????+ sigma * torch.randn_like(clean_image)???????denoised_image = denoise(noisy_image, sigma)????????????# weighted least squares loss???????weight = (sigma**2 + sigma_data**2) / (sigma * sigma_data)**2???????loss = weight * (denoised_image - clean_image).square().sum()?
???????# ... plus backpropagation and optimizer update |
結果和結論
本博文中展示的所有結果都通過徹底的數值實驗證明是有益的,詳情請參閱《闡明基于擴散的生成模型的設計空間》。采用所有改進的最終效果是對先前工作的顯著進步。特別是,在競爭激烈的 ImageNet 64 × 64 類別中,我們保持了世界紀錄的 FID 指標一段時間。此外,我們在生成過程中大幅減少了降噪器評估的數量,從而實現了這一記錄。
我們相信,這些發現對于未來其他數據模式、改進的網絡架構或更高分辨率的圖像仍然具有相關性。當然,在不同的環境中應用模型時,我們仍應注意基本推理。例如,在采用潛在擴散或提高分辨率時,許多常量(例如最大噪聲級別為 80,或訓練噪聲級別分布的位置和寬度)肯定需要進行調整。
要查看我們的官方實現以及預訓練網絡,請訪問 NVlabs/edm GitHub 上的代碼。該代碼是一種簡潔且精簡的實現,遵循論文的符號和慣例,可以作為實驗和構建這些想法的絕佳起點。請注意,我們包含了多個函數和類,這些函數和類用于重現先前方法以便進行比較,但使用或學習我們的方法并不需要這些函數和類。有關特別相關的代碼,請參閱:
generate.pyedm_sampler實現了完整的采樣器,包括可選的隨機性
training/loss.EDMLoss損失函數和權重networks.EDMPrecond用于規模管理和混合預測networks.DhariwalUNet用于重新實現常用的 ADM 網絡架構
該團隊最近發布了一篇后續研究論文,分析和改進擴散模型的訓練動力學。在這項工作中,他們通過深入研究降噪器網絡的設計和訓練,實現了前所未有的生成質量。
?






