視覺效果生成式 AI是一個根據文本提示創建圖像的過程。該技術基于在互聯網規模的數據上預訓練的視覺語言基礎模型。通過提供多模態表示,這些基礎模型可以應用于許多領域。例如,包括圖像字幕和視頻檢索、創意3D和2D圖像合成以及機器人操作。所有這些任務都得益于視覺語言基礎模型的“開放世界”能力,從而能夠使用豐富、自由形式的文本和視覺類別的“長尾”。
借助這些強大的表征,我們將面臨新的挑戰。也就是說,如何將這些模型與用戶特定的或個性化的視覺概念結合使用。如何教會這些模型將此類用戶特定的概念與他們之前從海量數據集中學到的知識相結合?
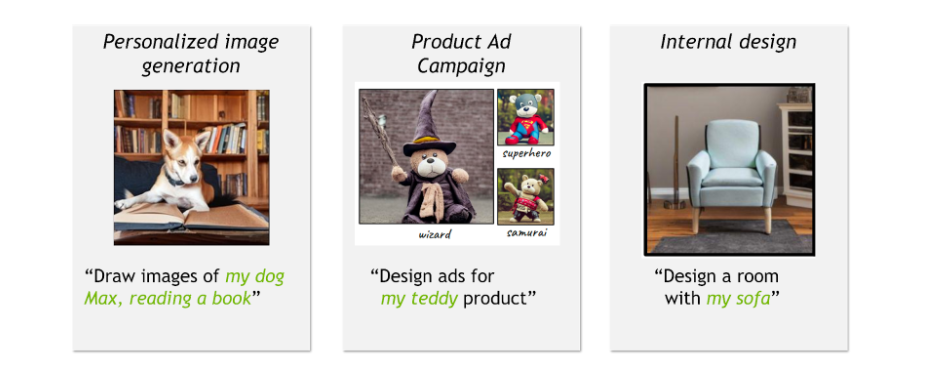
例如,玩具品牌的創意總監正在計劃圍繞新的玩具熊產品開展廣告活動,并希望在不同的場景中展示玩具,這些場景包括扮演超級英雄或巫師的角色。或者,孩子希望創作家庭狗的搞笑動畫片。或者,室內設計師希望在使用傳家寶家庭沙發設計房間。所有這些個性化用例都需要合成新場景,并將特定物品與通用組件相結合。
為應對這一挑戰,我們設計了多種算法。此類個性化算法應滿足以下質量、易用性和效率目標:
- 捕捉所學概念的視覺特征,同時根據文本提示進行更改。
- 支持在一張圖像中結合使用多個已學習的概念。
- 快速運行,每個概念只需占用少量內存。
什么是文本反演?
本節通過 文本反演 介紹了個性化生成式 AI 的基本技術。
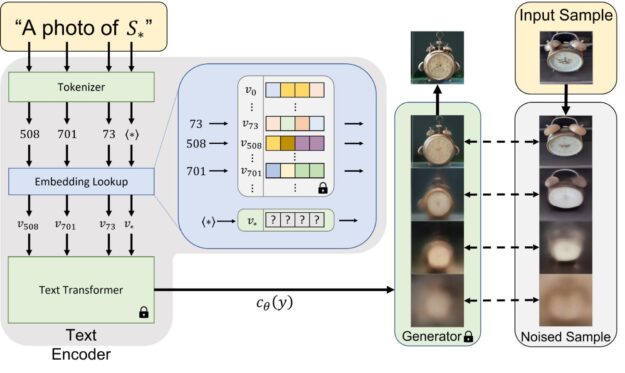
給定一些概念的訓練圖像,我們的目標是學習新概念,使基礎模型能夠以合成方式使用豐富的語言生成圖像。概念可以與訓練期間未與新概念一起看到的名詞、關系和形容詞相結合。同時,即使在修改和與其他概念結合時,概念也應保持其“基本”視覺屬性。
名為文本反演的方法通過在凍結的視覺語言基礎模型的詞嵌入空間中查找新詞來克服這些挑戰(圖 2)。這包括學習將新的嵌入向量與用占位符標記的新“偽詞”進行匹配 ?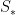
為了找到?
實驗性見解
文本轉圖像個性化支持一系列應用。圖 3 通過將學習到的偽詞整合到新的文本提示中,顯示了新場景的構成。每個概念都從四個示例圖像中學習,然后用于新的復雜文本提示。凍結的文本轉圖像模型可以將大量先前知識與新概念相結合,將它們整合到新的創作中。
令人驚訝的是,雖然學習概念時的訓練目標本質上是直觀的,但學習的偽詞封裝了語義知識。例如,碗(下行)可以包含其他對象。

個性化還可以通過使用精心策劃的小型數據集,為有偏見的概念學習不太帶偏見的新詞。然后,可以用這個新詞代替原始詞,以推動更具包容性的生成(圖 4)。

在輕量級模型中進行更好的編輯
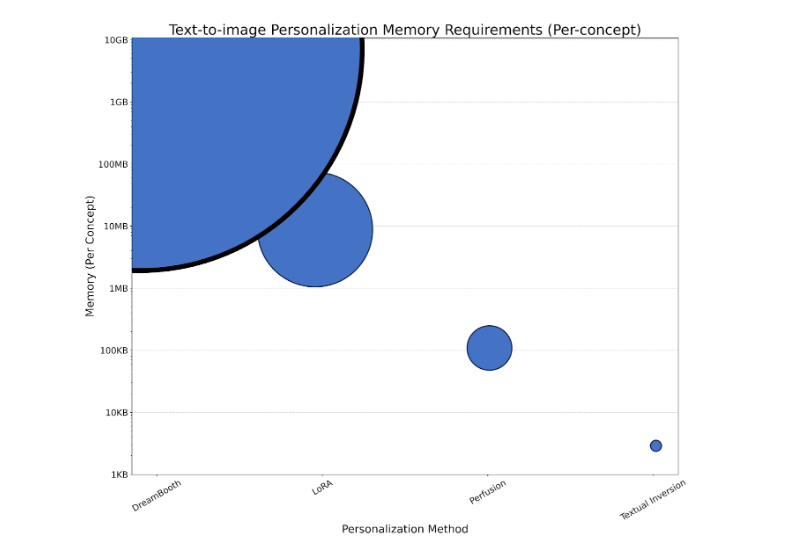
前面介紹的文本反演方法是一種輕量級模型,僅使用 1K 參數對概念進行編碼。由于規模很小,需要組合多個概念或嚴格控制概念與文本時,其質量可能會下降。
另一種模型DreamBooth:針對主題驅動生成微調文本轉圖像漫射模型調優一個GB大小的U-Net架構會生成一個資源密集型模型,每個概念都需要GB的存儲空間,訓練速度很慢。LoRA(低階自適應)可以與DreamBooth結合使用,通過凍結U-Net權重并將較小的可訓練矩陣注入特定層來減少其存儲占用空間。
我們開始設計一種網絡架構和算法,該架構和算法可生成更符合文本提示和視覺特征的圖像,同時保持較小的模型尺寸,并支持將多個學習概念組合到單個圖像中。
我們提出了一種方法,通過對 1 級模型進行輕量級編輯來應對所有這些挑戰,如在 用于文本轉圖像個性化的 Key-Locked Rank One Editing。這可以實現更好的泛化,同時在 4 – 7 分鐘內使用低至 100KB 的存儲空間對模型進行個性化處理。
這個想法非常直觀。使用 Teddy Bear 的示例,預訓練模型可能已經知道生成了扮演超級英雄的普通玩具熊的圖像。在這種情況下,首先為普通玩具熊生成圖像,“鎖定”一些模型組件的激活,然后使用特定的個性化玩具熊重新生成圖像。當然,關鍵是應該鎖定哪些組件。
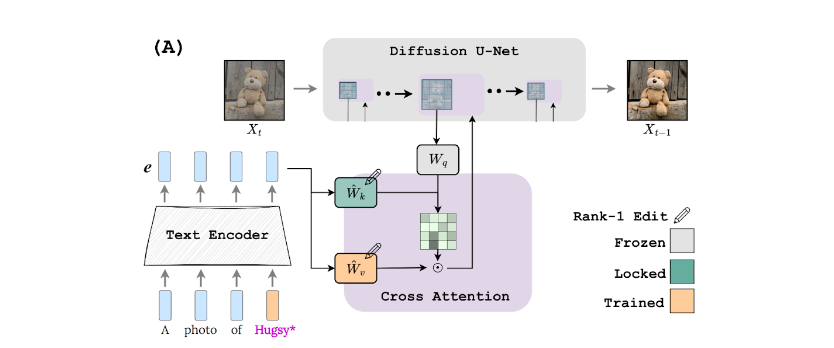
我們的主要見解是,擴散模型(K 矩陣)中交叉注意力模塊的關鍵路徑控制著注意力圖的布局。事實上,我們觀察到現有技術往往過適合該組件,導致對 新詞的注意力超出概念本身的視覺范圍。
基于這一觀察結果,我們提出了一種密鑰鎖定機制(圖 5),在該機制中,個性化概念(玩具熊)的密鑰固定在超級類別(填充動物甚至普通玩具)的密鑰上。為了保持模型的輕量級和快速訓練,我們將這些組件直接整合到文本到圖像的擴散模型中。我們還添加了門控機制,以調節對所學概念的重視程度,并在推理時結合多個概念。我們稱之為方法注入 (執行時間聲音化差異融合)。
實驗性見解
本節提供了一系列探索 Perfusion 屬性的示例。
圖 7 展示了生成的高質量個性化圖像,這些圖像將兩個新概念組合到一張圖像中。左側的圖像用于向模型教授新的個性化概念,即 Teddy? 和 Teapot?.在實踐中,我們不需要特定的描述,我們可以使用更廣泛的概念,例如 toy?。在右側的圖像中,這些概念被組合在一起,并且以令人驚訝的方式進行了組合,例如“a teddy*sailing in a Teapot?”。
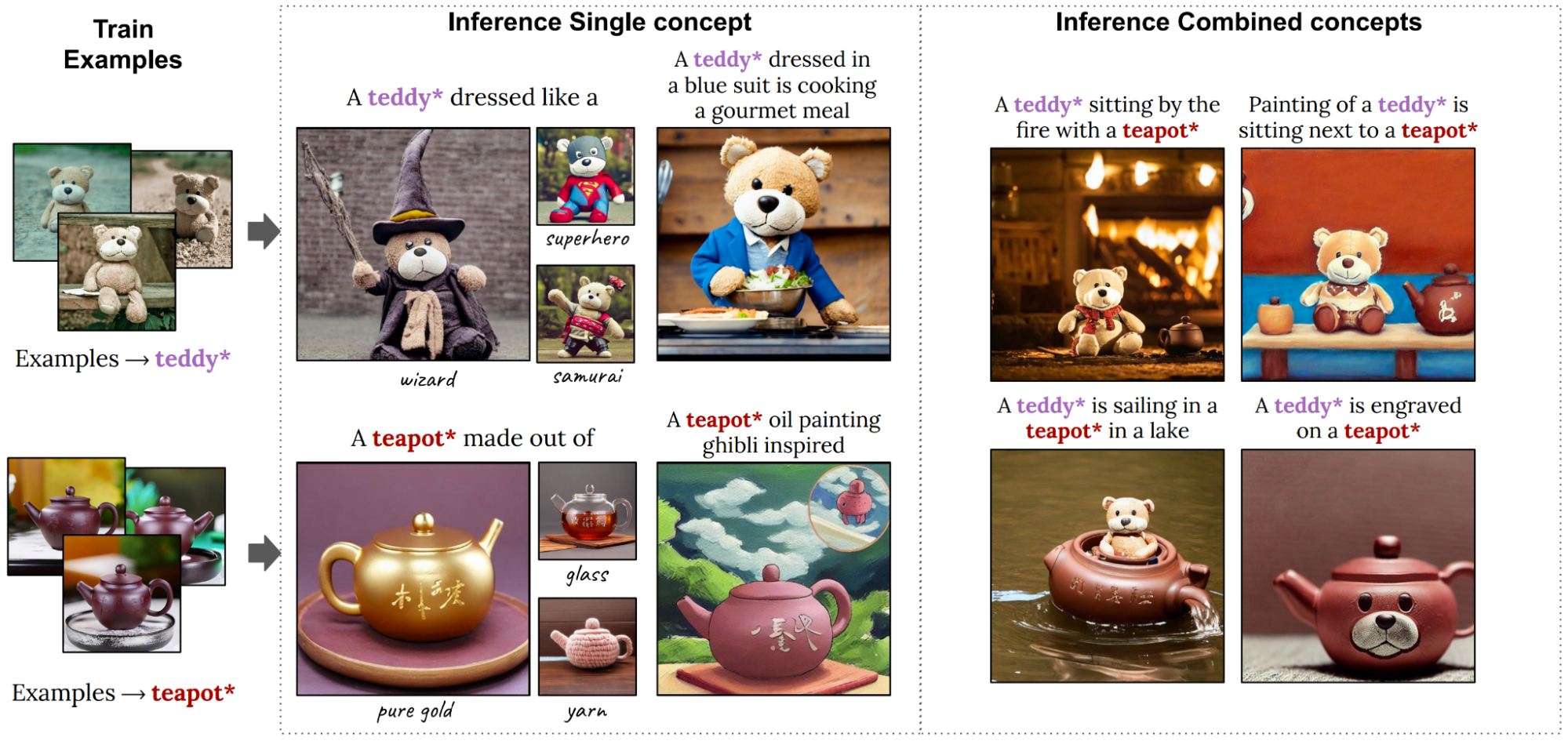
圖 8 探討了在 Perfusion 中使用密鑰鎖定對生成的圖像與文本提示的相似性產生的影響。使用密鑰鎖定生成的圖像(第一行)與未使用密鑰鎖定的圖像(最后一行)相比,與提示的匹配效果要好得多,但與訓練圖像的姿勢和外觀的相似性較低。訓練密鑰類似于 DreamBooth 或 LoRA,但所需的存儲空間更少。

圖 9 說明了 Perfusion 如何使創作者能夠在生成過程中使用單個運行時參數控制視覺保真度和文本相似度之間的平衡。左側是單個訓練模型的量化結果,其中調整了單個運行時參數。Perfusion 可以通過在生成時調整該參數而跨度廣泛的結果范圍(由藍色線表示),而無需重新訓練。右側的圖像說明了此參數對生成圖像的影響。
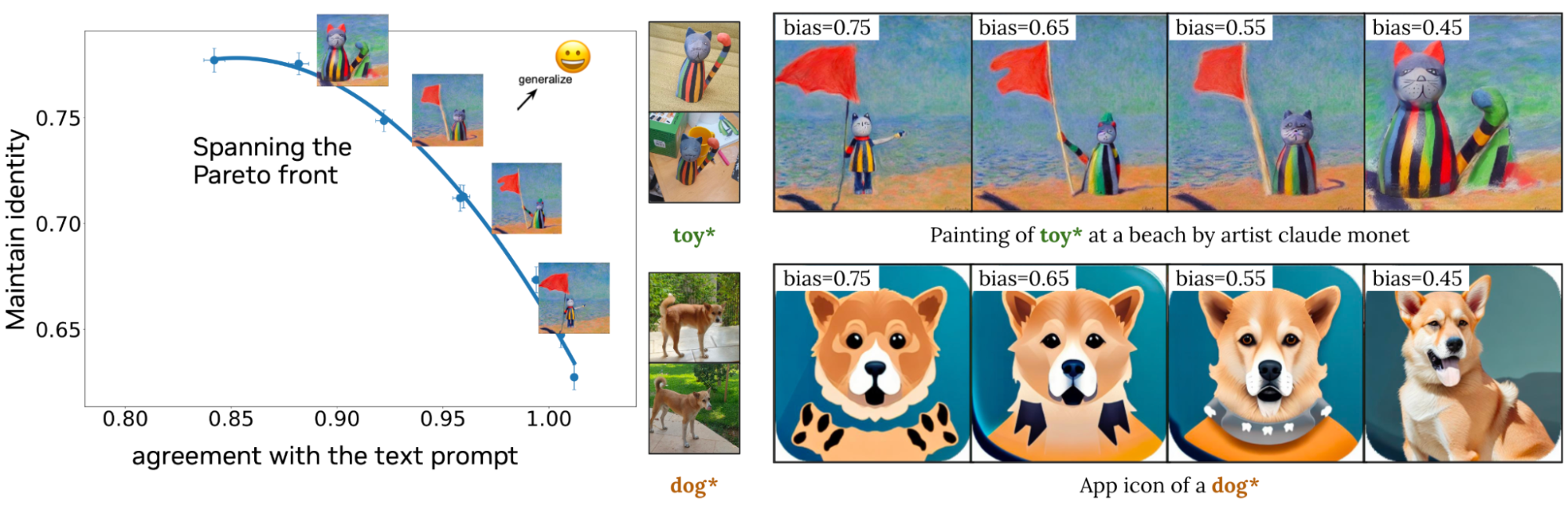
圖 10 將 Perfusion 與基準方法進行了比較。Perfusion 可在不受訓練圖像特征影響的情況下實現出色的提示一致性。

加速個性化
大多數個性化方法(如文本反演和 Perfusion)可能需要幾分鐘時間來教授模型一個新概念。對于業余愛好者來說,這通常足夠快,但有一種更快、更高效的方法可以大規模或動態地實現個性化。
加速新概念訓練過程的一種方法是預訓練編碼器。 編碼器是一種經過訓練的神經網絡,用于預測漫長的個性化訓練過程的大致結果。例如,如果您想為模型教授一個表示您的貓的新詞,您可以訓練一個新模型,該模型將貓的一張(或多張)圖像作為輸入,并輸出一個新詞的數字表示。然后,您可以將該表示輸入到文本轉圖像模型中,以生成新的貓照片。
我們提出了一種用于調整的編碼器 (E4T) 方法,該方法采用兩步式方法。第一步是學習預測描述概念的新詞,以及該概念類別的一組權重偏移量。這些偏移量有助于您更輕松地學習個性化該類別中的新對象,例如狗、貓或面孔。這些偏移量保持較小(正則化),以避免過擬合。
在第二步中,我們對完整的模型權重(包括權重偏移)進行了微調,以更好地重建概念的單個圖像。雖然這仍然需要一些調整,但我們的第一步是確保我們從非常接近概念的角度開始。因此,訓練新概念只需五個訓練步驟,只需幾秒鐘而不是幾分鐘。
結束語
個性化生成方面的最新進展現在能夠在令人驚喜的新環境中創建特定個性化商品的高質量圖像。本文解釋了個性化背后的基本思路以及兩種改進個性化文本轉圖像模型的方法。
第一種方法使用密鑰鎖定來提高與訓練圖像的視覺外觀和文本提示含義的相似性。第二種方法使用編碼器以更少的圖像將個性化速度提高 100 倍。這兩種技術可以結合使用,從而生成快速訓練的高質量、輕量級模型。
這些技術仍然存在局限性。學習模型并不總是完全保留概念的特征,使用文本提示而非通用概念可能更難以編輯。未來的工作將繼續改進這些局限性。
想要在商業應用程序中使用這些方法?請填寫 研究許可申請表。
?






