InstaDeep 、慕尼黑工業大學( TUM )和 NVIDIA 之間的合作導致了基因組學多個超級計算規模基礎模型的開發。這些模型展示了許多預測任務的最先進性能,如啟動子和增強子位點預測。
聯合研究團隊表明,在基因組學上訓練的大型語言模型( LLM )可以在過多的基因組任務中推廣。以前的方法需要專門的模型。在 NVIDIA Healthcare VP Kimberly Powell’s invited talk on January 12 期間即將舉行的摩根大通醫療保健會議上,將對結果進行初步了解。
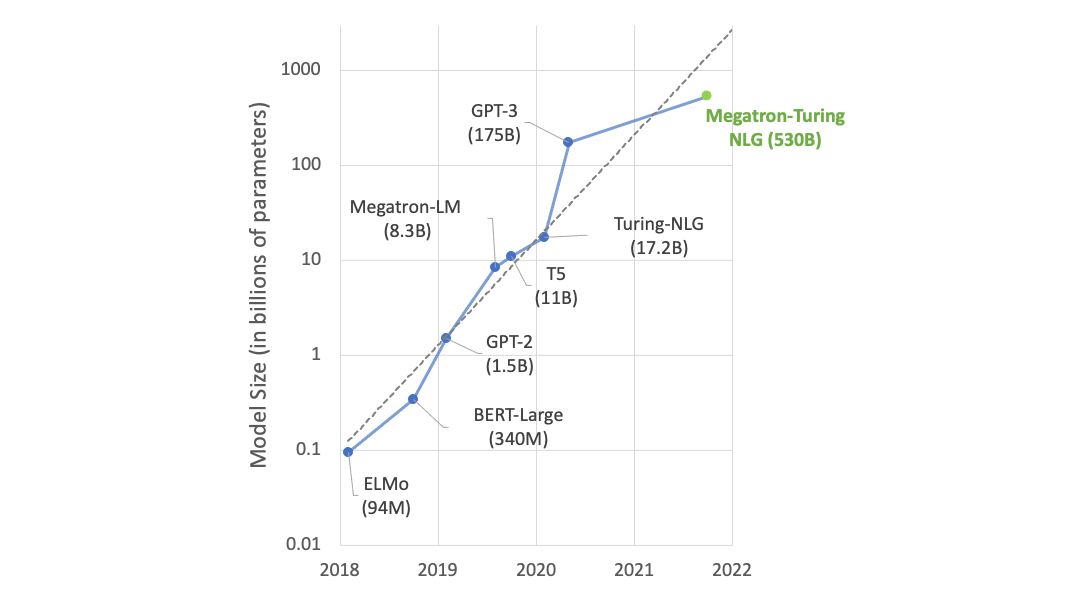
該團隊使用 NVIDIA 推出的超級計算機 Cambridge-1 來訓練各種大型語言模型( LLM ),從 500M 到 2.5B 參數。在不同的基因組數據集集合上訓練模型,以探索模型規模和數據多樣性對下游任務績效的作用。
分類任務包括預測增強子和啟動子序列以及轉錄因子結合位點。這些任務有助于理解 DNA 如何轉化為 RNA 和蛋白質的動力學,從而開啟新的臨床應用。
對于研究中確定的每一項任務,性能都隨著模型規模和數據集多樣性單調增加。與專業的最先進模型基線相比,在多物種數據集上訓練的最大 2.5B 參數 LLM 在 18 個任務中的 15 個任務中實現了同等或優異的性能。
這些結果是通過參數有效微調實現的。依賴于從 transformer 模型的各個層提取的預訓練嵌入,加上簡單的淺層感知( MLP )或邏輯回歸,足以在 11 項任務中實現同等或優異的性能。
在每個模型檢查點和每個任務的所有層上應用這種探測策略,得到了訓練的 120 萬 MLP 模型。該研究詳細分析了訓練和使用 LLM 的各個方面,例如不同層對下游任務績效的作用。
在固定的模型尺度上對序列多樣性進行直接比較顯示出了重要的收益,增加模型尺度也是如此。例如,僅在人類參考基因組上訓練的 500M 參數模型表現不如在 1000 Genomes 數據集上訓練的相同模型。
類似地,在 1000 個 Genomes 數據集上訓練的 2.5B 參數模型比任何 500M 參數模型表現更好。它的表現不如在自定義多物種數據集上訓練的相同模型,即使在僅涉及人類基因組的任務上測量下游表現時也是如此。
研究人員觀察到,并非所有嵌入都是平等創建的。雖然常識建議使用 LLM 的最后一層進行下游預測,但令人驚訝的是,中間層在下游任務上產生的表示具有明顯更高的性能。
InstaDeep 首席執行官 Karim Beguir 表示:“我們認為,這是第一個明確證明在基因組學中開發基礎模型的可行性的結果,這些模型可以真正在各個任務中推廣。”。他補充道,“在許多方面,這些結果反映了我們在過去幾年中在自然語言處理中開發適應性基礎模型所看到的情況,看到這一點現在應用于藥物發現和人類健康中的挑戰性問題,令人難以置信地興奮。”
劍橋 -1 號對該項目的成功至關重要,該項目需要高性能的計算基礎設施來訓練這樣的大型模型,使其具有捕捉基因組中長距離相互作用所需的感受野。
研究人員嘗試了多種方法,包括多種注意力機制、模型尺度和標記器方案。他們使用在 16 個 NVIDIA DGX A100 節點( 128 A100 80GB GPU )上訓練的 2.5B 參數稀疏注意力模型,最終在任務中獲得了最佳發布性能。
在未來的工作中,團隊計劃通過直接微調模型來探索進一步的下游任務性能改進,并將繼續在應用于基因組學的大型語言模型的架構創新方面進行合作。 InstaDeep 是首批進入劍橋 -1 的 NVIDIA Inception 成員之一。
?