量化開發者需要運行回測模擬,以便從損益(P&L)的角度了解金融算法的表現。統計技術對于根據可能的損益路徑可視化算法的可能結果非常重要。GPU 可以大大減少執行此操作所需的時間。
從更廣泛的角度來看,金融市場的數學建模是一種實踐,可以追溯到榮獲諾貝爾獎的 Black-Scholes 模型 (1973 年)。它在當時是革命性的,從那時起就影響了資本市場。統計 Monte Carlo 模擬的方法是表示使用 Brownian motion 模型可實現的價格路徑,該方法涉及根據市場在檢查市場微觀結構時的行為方式定制的自定義模型。
本文介紹了適用于金融市場市場參與者的硬件加速研究。市場參與者可以是:
- 交易員,負責制定盈利策略
- 交易所,為公司提供購買和出售證券的能力
- 風險經理,確保公司的一系列頭寸不會使公司資本風險過高
這些市場參與者都在全球的交易所中開展協作,在這些交易所中,有一套關于價格、交易量和時間的非常具體的規則,稱為交易證券的動態訂單薄。
由于定價數據龐大且執行速度快,GPUs 可提供模擬這些動態訂單所需的加速計算。本文將介紹如何在此設置中應用 GPUs。
如今,市場參與者對帶有納秒時間戳的市場交易感興趣,尤其是希望通過準確預測獲得正利潤的高頻交易參與者。在這種情況下, alpha 是相對于市場指數的投資超額回報的衡量指標 ,考慮了無風險率并進行了風險調整。
遵循?《算法和高頻交易》(Algorithmic and High-Frequency Trading)?一書中的算法和高頻交易模擬方法,并使用來自?Market Making at the Touch with Short-Term Alpha?的代碼樣本,可以選擇一組隨機過程并為用戶提高及時性,如定時圖表中報告的那樣。?Buy Low, Sell High: A High Frequency Trading Perspective?是一個從量化角度來看,高頻交易視角對于這些高頻市場已解決的整體問題而言,是一個非常易于理解的替代方案。?
在研究期間,我們發現模擬時間范圍越長,提供的硬件加速就越多。市場從業者將決定在模擬中獲得信心所需的范圍,以便為在實時交易中部署這些模擬技術做好準備。無論使用何種 NVIDIA GPU 型號:H100 NVL、H100 SXM、H200 NVL、H200 SXM、GH200、B200 或 GB200, NVIDIA Hopper 和 NVIDIA Blackwell 架構均提供超過 14,000 個內部 CUDA 核心,以提供大規模并行程序執行。
訂單和要解決的問題
全球金融市場高頻捕獲的市場數據量驚人。實際訂單記錄以及訂單記錄的模擬均由復雜狀態組成,其中包括:
- 交易對手進行競價的價格水平
- 交易對手的 要價或要價(asks) 所在的價格水平
- 中間價,即最高買入價和最低賣出價的平均值
有 10 個投標級別和 10 個要價級別。限價訂單 (LO) 通常由特定價格點的交易對手發出。市價訂單 (MO) 由交易對手下達,他們在執行價格方面更加靈活,但需要立即執行交易。研究人員和從業者專注于模型,通過在選擇交換上按順序放置 LO 和 MO,在發生這些動態事件時獲取利潤。模擬這些策略很重要,因為企業分配給它們的資金量很大。
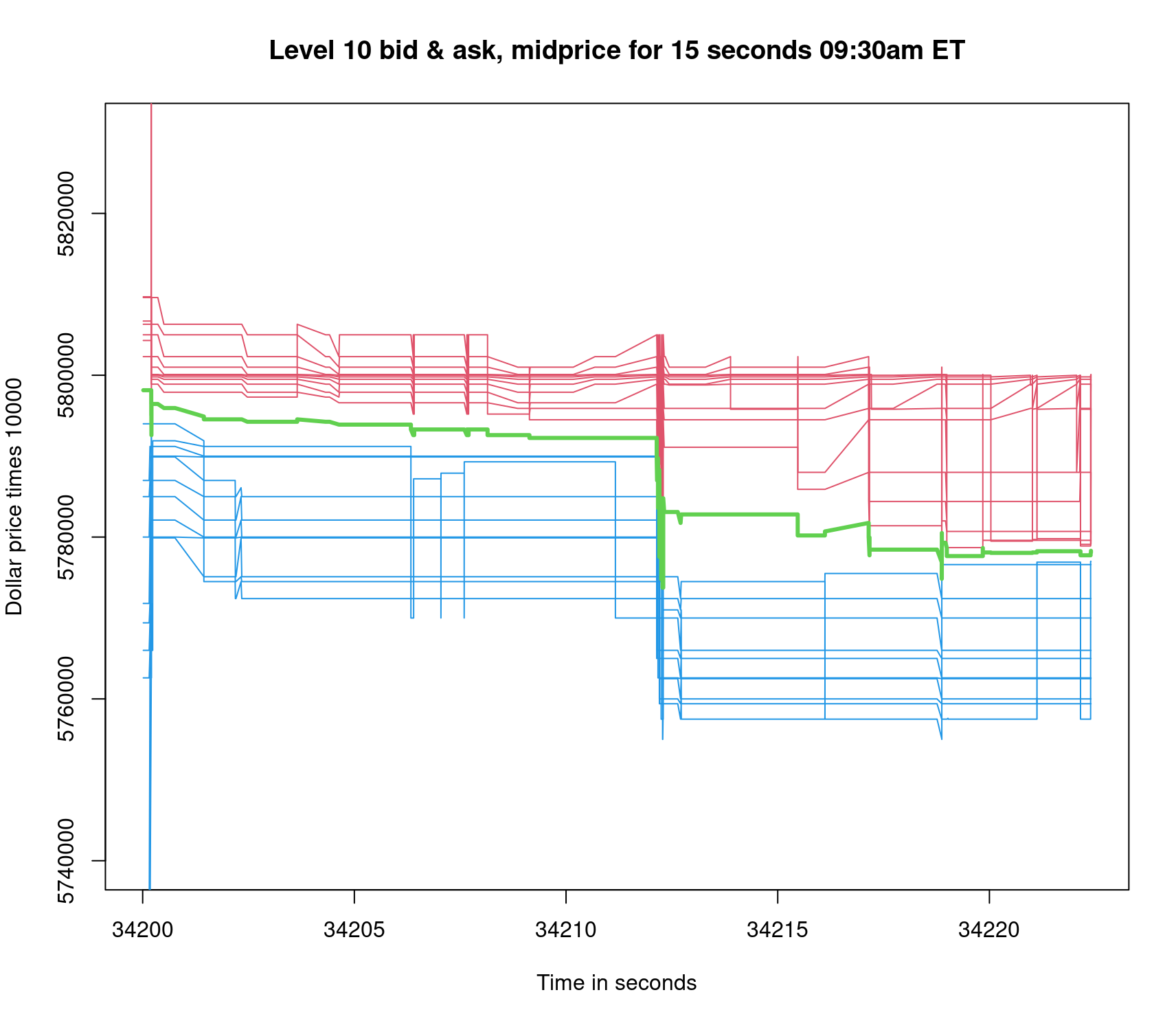
圖 1 和圖 2 分別提供了訂單記錄 15 秒和 23,400 秒 (或一個交易日) 的透視圖。在圖 1 中,給定股票的限價盤記錄在 15 秒視圖的中間跳下來。因此,中間價降低了約 1 美元,從每股約 579.00 美元降至每股約 578.00 美元。34,200 的初始時間表示上午 9:30 ET 市場開放。請注意,34,212 秒是開盤時價格的極端波動。
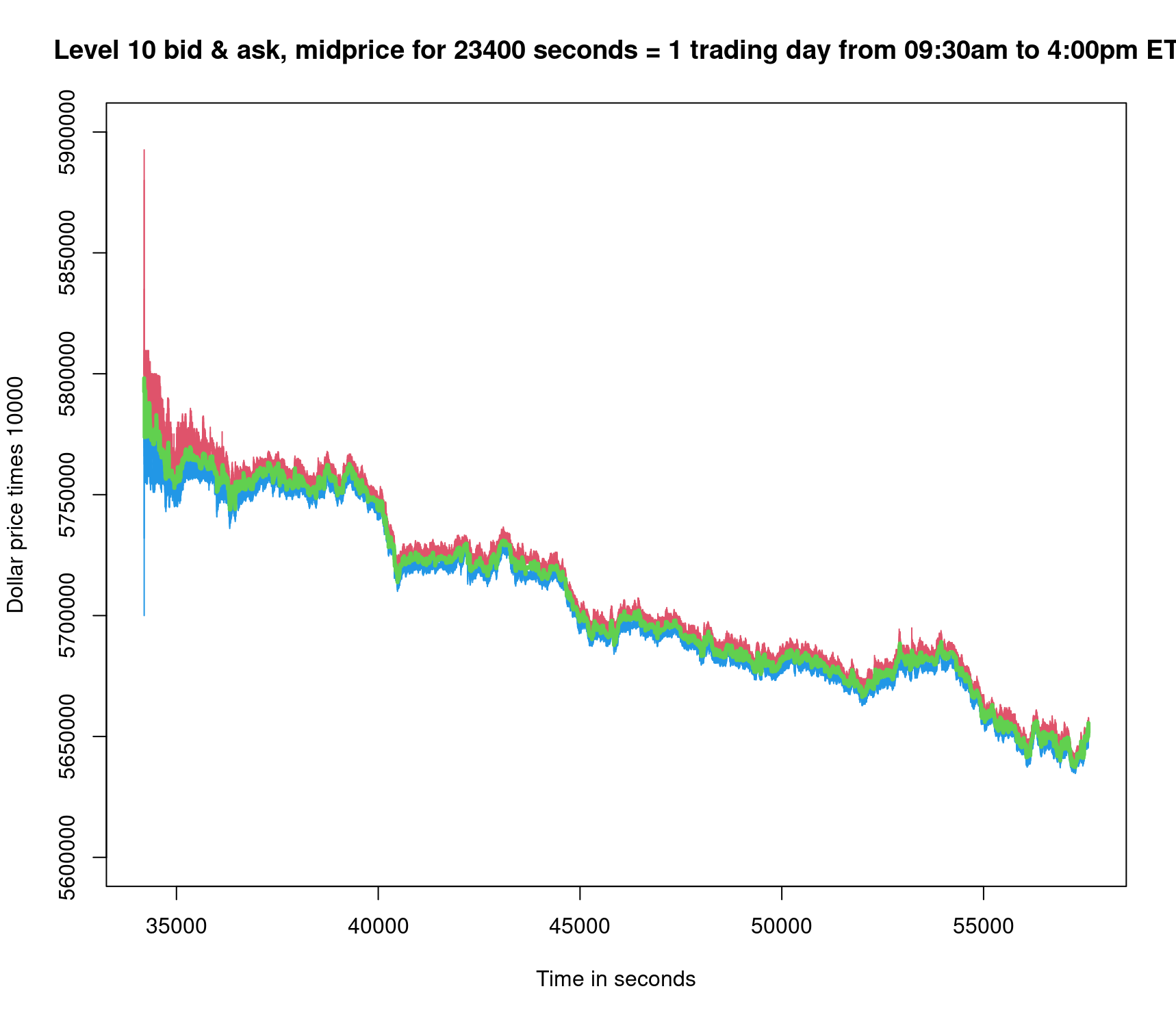
此示例為大型科技股。由于有更多的時間讓市場價格受到所有 LO 和 MO 活動的影響,因此全天的交易范圍更廣。在圖 2 中,中間價從每股 579.00 美元左右降至每股 565.00 美元左右。隨著時間遠離交易日的市場開放時間,限價單記錄的寬度從上到下逐漸縮小。
統計蒙特卡洛模擬需要使用 GPU 加速,因為它們非常適合解決該問題,并能讓研究人員更高效地利用時間。對所用方法的特定實現進行采樣,以用于其中一個主要的市場模擬模塊。
使用 CUDA Python 加速模擬:CuPy 與 Numba 的對比
Python 不要求語句包含在函數內,因此您可以將 Python 程序視為一系列函數內外交替的語句。一般來說,在函數外部編寫代碼時,CuPy 方法非常適合 GPU 執行。使用 CuPy 代替 NumPy 非常方便。下面是使用 CuPy 的示例。
import cupy as cpx = cp.array([1, 2, 3, 4, 5])y = cp.array([5, 4, 3, 2, 1])z = x * y # GPU-accelerated operation |
以下是使用 Numba 演示的等效代碼:
import numbafrom numba import cuda@cuda.jitdef mult_kernel(x, y, z): i = cuda.grid(1) if i < x.size: z[i] = x[i] * y[i]# Example usage of Python Numba kernel:import numpy as npx = np.array([1, 2, 3, 4, 5], dtype=np.float32)y = np.array([5, 4, 3, 2, 1], dtype=np.float32)z = np.zeros_like(x)mullt_kernel[1, x.size](x, y, z) # Launch kernel |
Numba 方法可以更好地控制并行性,因為它明確使用 i = cuda.grid(1) 通過 i 為 GPU 網格的線程建立索引。多年來,CUDA C++開發者習慣于顯式編寫核函數,以便能夠控制 GPU 上的計算。CuPy 矩陣不能直接在 Numba CUDA 核函數中使用,并且原始模擬以時間循環 Python 函數的形式出現,并注定會成為 Numba 核函數。出于這些原因,此處重點關注的是 Numba,而不是 CuPy,以便將模擬移植到 GPU 上運行。
普通和均勻變體
與大多數概率模擬一樣,正常變量和一致變量都需要隨機數生成器。NumPy 提供了這一點,因此有必要對這些數據進行批處理,并將其發送到 GPU,以避免在獲取變量時產生開銷。相同的 normal(0,1) 和 uniform(0,1) 變量使用 cuda.to_device 在“主機”(CPU) 中以“設備”(GPU) 為目標。
if isGPU: #duplicate norm and unif variates on host and device np.random.seed(20) norm_variates_d = cuda.to_device(np.random.randn(Nsims*Nt).reshape(Nsims,Nt)) unif_variates_d = cuda.to_device(np.random.rand(Nsims*Nt).reshape(Nsims,Nt))np.random.seed(20)norm_variates = np.random.randn(Nsims*Nt).reshape(Nsims,Nt)unif_variates = np.random.rand(Nsims*Nt).reshape(Nsims,Nt)if isGPU: assert(norm_variates_d.copy_to_host()[0,10]==norm_variates[0,10]) #check |
生成仿真內核
重新編碼用于生成隨機模擬的 Python 函數成為實現加速的主要工程任務。這是為了在模擬路徑之間實現并行化,并為模擬數千秒提供合理的運行時間。
對于每個結果數組,使用 copy_to_host 方法將其從設備復制到主機。Numba 核函數由裝飾器 @cuda.jit 標識。函數主體包含許多關鍵的 2D 隨機變量:stock price s_path、isMO、buySellMO、alpha_path、inventory q_path、wealth X_path。
@cuda.jit(debug=False)def generate_simulation_kernel(Nsims, t, dt, Delta, sigma,...): . . . j = cuda.grid(1) #cuda.blockDim.x * cuda.blockIdx.x + cuda.threadIdx.x if j < Nsims: for i in range(0, Nt - 1, 1): # Print Counter . . . s_path[j, i+1] = s_path[j, i] + alpha_path[j, i] * dt + sigma * norm_variates[j, i] . . . alpha_path[j, i+1] = math.exp(-zeta * dt) * alpha_path[j, i] + eta * math.sqrt(dt) * norm_variates[j, i] + \ epsilon * (isMO[j, i]) * (buySellMO[j, i]) . . . |
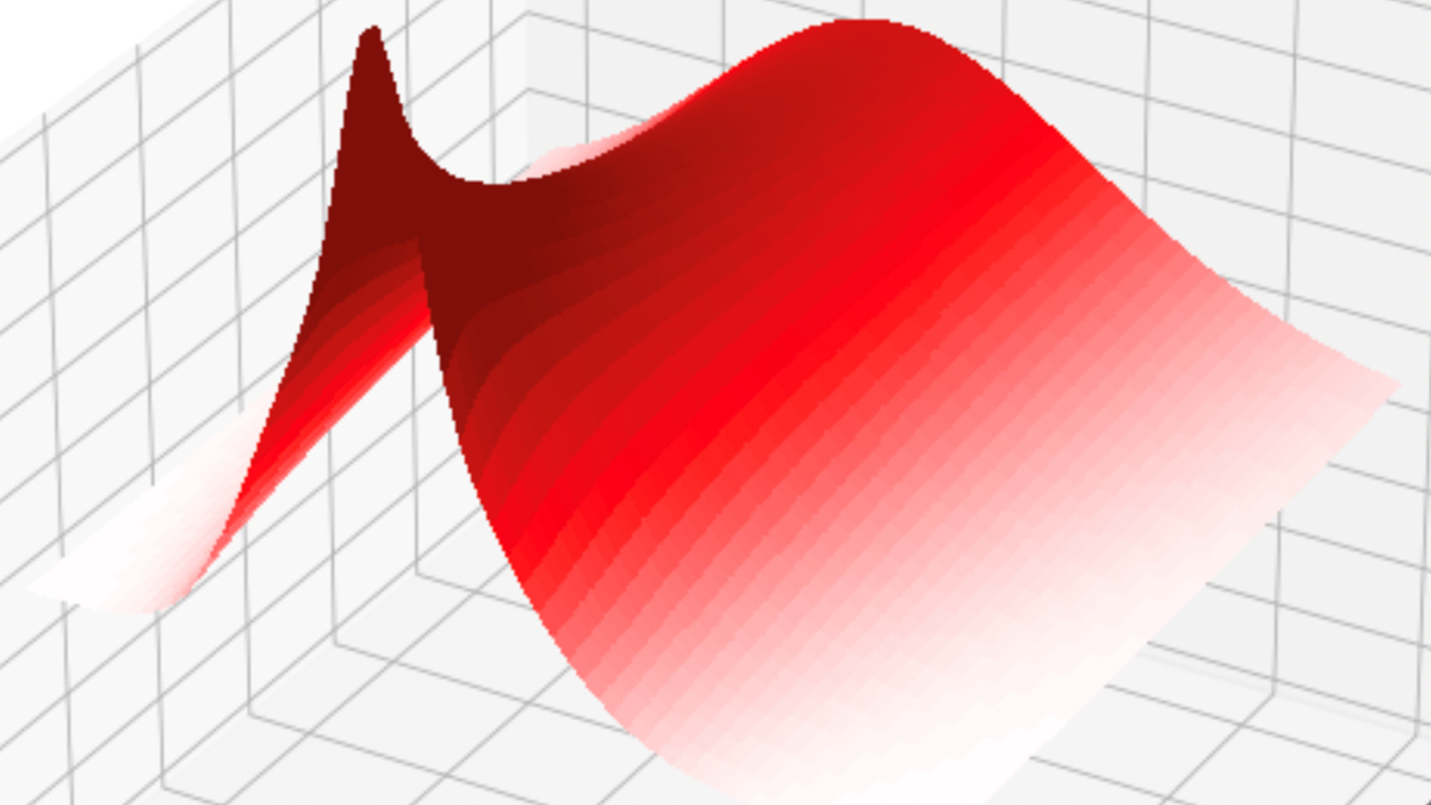
請查看圖 3 和圖 4 中關于 T = 30 秒 (dt = 0.2 秒) 的短時內 Alpha 過程和中價的模擬圖。
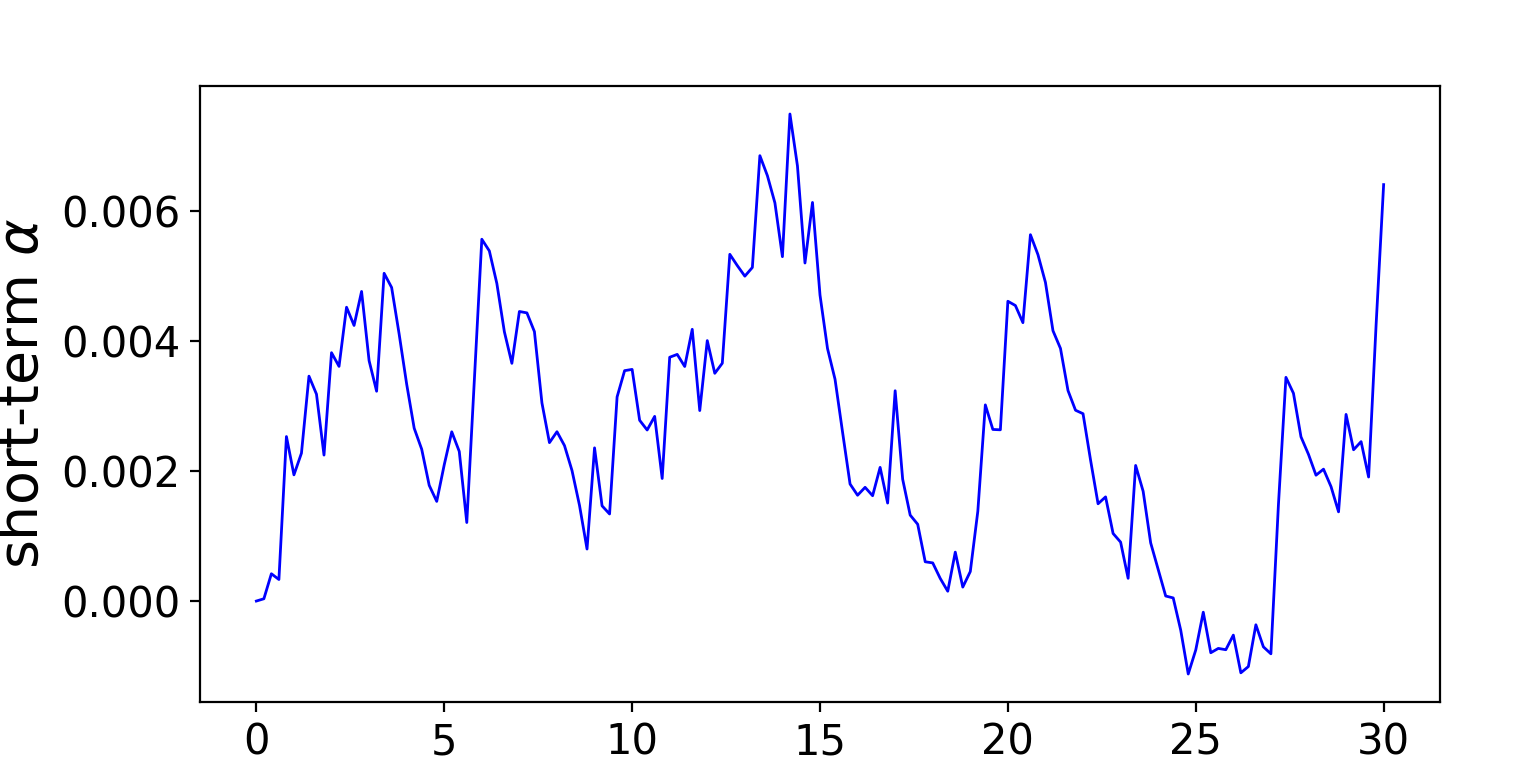
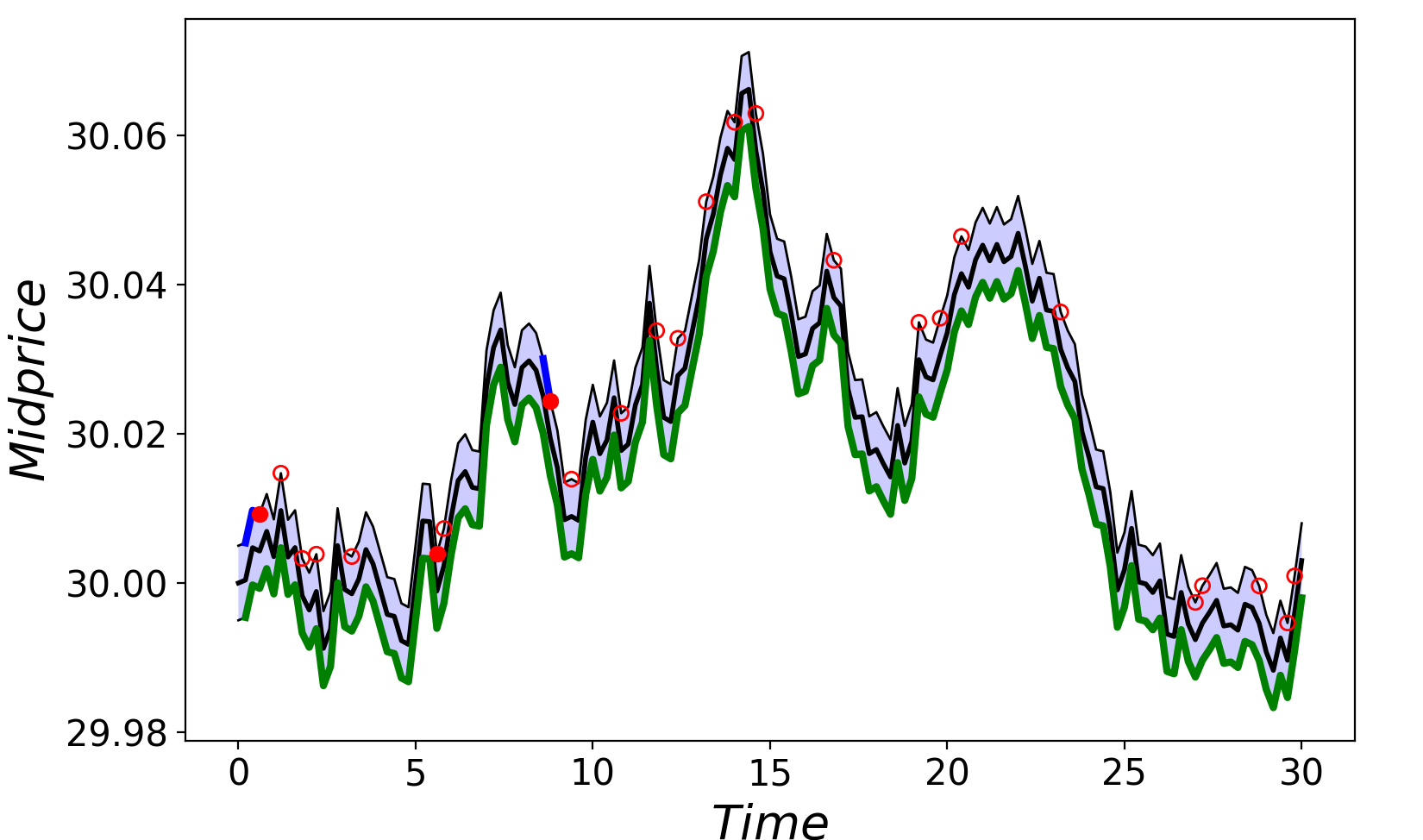
加速結果
CPU 和 NVIDIA H200 GPU 在三個模擬時間范圍內的性能結果如圖 5 所示。在一個月的較長時間范圍內,可利用 NVIDIA H200 Tensor Core GPU 的大量 CUDA 核心實現 114 倍的加速。使用可靠數量的模擬 (例如 1,000) 允許計算中間價、alpha 和 P&L 的平均值和標準差。
加速的來源
GPU 提供的加速來自于算法的 2D 幾何圖形。在第一個維度中,即從 0 到結束 T 的時間 (以秒為單位),由于隨機微分方程時間模擬的順序性質,GPU 不可能加速。剛剛超過時間點 (稱為 s_path(t+Δt)) 的時間的股價值取決于先驗值 s_path(t),這將沿著時間線繼續計算。
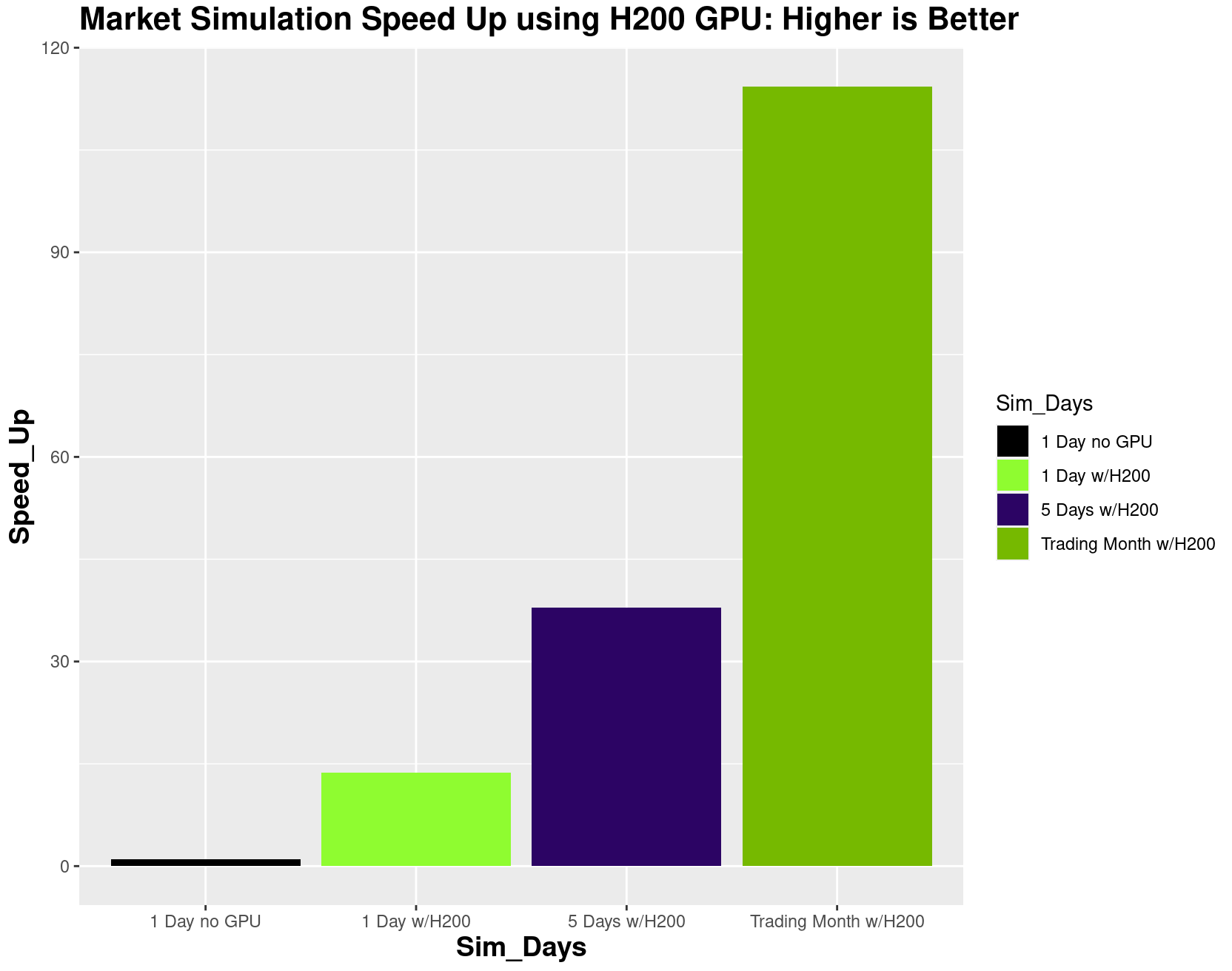
第二個維度是 Nsims = 1,000,即用于實現魯棒模擬的計算路徑數。一般來說,隨著模擬數量的增加,Monte Carlo 模擬可以更好地估計計算出的隨機變量的分布。因此,在 1,000 次或更多次的模擬中,以及在更長的時間內,可以依靠 GPU 以遠超其他方式的速度執行所需的大規模并行計算,從而提高運行效率。正如 2022 年 和 2023 年 研究基于 2018 年一項研究 的機器學習分類方法所展示的那樣,這將延續到極限順序手冊級別的機器學習。
結語
對于過去的中價流程,高頻限價訂單和市價訂單流程的新最佳實踐模擬遵循《金融隨機微積分 II》(Stochastic Calculus for Finance II) 一書中所述的方法。在檢查訂單記錄時,流程的數量要多得多,并且與高頻交易對手參與者的復雜程度有關。如需了解正態分布和對數收益對蒙特卡羅模擬市場實際價格行為的建模效果,請參閱《使用 R 進行金融分析》(Financial Analytics with R) 一書。
算法和高頻交易 提供的深入分析詳細說明了動態編程優化目標。將這種更復雜的模擬以亞秒級粒度擴展到交易日,即使在多核 CPU 上也難以計算,根據本文中提供的結果,最好使用 GPU 提供的加速來完成。
雖然這種模擬會生成自己的市場狀態,但使用大型訂單記錄數據集的經驗也需要 GPU 加速,GPU 在資本市場技術領域的成功證明了這一點。在回測模擬中,要處理全球許多交易所的許多交易證券,需要多個 GPU。
下載并安裝 RAPIDS,開始為您的數據科學工作負載啟用 GPU。請務必預先安裝 NVIDIA 驅動程序和 CUDA 工具包。
下載 Numba,開始使用此軟件包加速您的 Python 程序。CuPy 可以直接轉換為 GPU 數組,而 Numba 可以對矩陣并行的維度進行更多控制,因此非常適合本文介紹的解決方案。
加入我們的 NVIDIA GTC 2025,并查看 AI 在電子市場中的安全高效交易會議【S72692】。
?
?