使用 GPU 進行提取、轉換和加載(ETL)操作的 NVIDIA RAPIDS Accelerator for Apache Spark 可以在大規模數據上運行,從而節省成本并提高性能。我們在上一篇文章 “GPUs for ETL? Run Faster, Less Costly Workloads with NVIDIA RAPIDS Accelerator for Apache Spark and Databricks” 中展示了這一點。在這篇文章中,我們深入了解了哪一個 Apache Spark SQL 操作對于給定的處理體系結構是加速的。
這篇文章是關于 GPU 和提取轉換加載(ETL)操作的系列文章的一部分.
將 ETL 遷移到 GPU
是否應將所有 ETL 遷移到 GPU ?或者,評估哪種處理體系結構最適合特定的 Spark SQL 操作有好處嗎?
CPU 針對順序處理進行了優化,單個內核明顯更少但速度更快。在內存管理、處理 I/O 操作、運行操作系統等方面都有明顯的計算優勢。
GPU 優化用于并行處理,它具有更多但速度較慢的核心。GPU 擅長繪制圖形、訓練、機器學習 和 深度學習模型、執行矩陣計算以及其他受益于并行化的操作。
實驗設計
我們使用計算成本高昂的 ETL 操作,根據真實客戶零售銷售數據創建了三個大型、復雜的數據集:
- 聚合(SUM+GROUP BY)
- 交叉連接
- 活接頭
每個數據集都經過專門策劃,以測試特定 Spark SQL 操作的極限和值。所有三個數據集都是基于一家全球零售商的交易銷售數據集建模的。選擇行大小、列數和類型是為了平衡實驗處理成本,同時進行測試,以證明和評估 CPU 和 GPU 架構在特定操作條件下的優勢。數據概況見表 1。
| 活動 | 行 | #COLUMNS:結構化數據 | #COLUMNS:非結構化數據 | 大小(MB) |
| 聚合(SUM+GROUP BY) | 9440 萬 | 2 | 0 | 3200 |
| 交叉連接 | 630 億 | 6 | 1 | 983 |
| 活接頭 | 4 億 4700 萬 | 10 | 2 | 721 |
本實驗評估了以下計算配置:
- 工作線程和驅動類型
- 工作線程最低和最高
- RAPIDS 或光子部署
- Databricks 單元(DBU)的最大小時限制——Databrickss 計算成本的專有衡量標準
| 工作線程和驅動類型 | 工作線程最小值/最大值 | RAPIDS 加速器/PHOTON | 最大 DBU/小時 |
| 標準_NC4 as_T4_v3 | 1/1 | RAPIDS 加速器 | 2 |
| 標準_NC4 as_T4_v3 | 2/8 | RAPIDS 加速器 | 9 |
| 標準_NC8as_T4_v3 | 2/2 | RAPIDS 加速器 | 4.5 |
| 標準_NC8as_T4_v3 | 2/8 | RAPIDS 加速器 | 14 |
| 標準_NC16as_T4_v3 | 2/2 | RAPIDS 加速器 | 7.5 |
| 標準_NC16as_T4_v3 | 2/8 | RAPIDS 加速器 | 23 |
| 標準_E16_v3 | 2/2 | Photon | 24 |
| 標準_E16_v3 | 2/8 | Photon | 72 |
其他實驗注意事項
除了構建具有行業代表性的測試數據集外,以下還列出了其他實驗因素。
- 數據集是在現收現付實例上使用幾種不同的工作線程和驅動程序配置運行的,而不是現場實例,因為它們固有的可用性建立了整個實驗的定價一致性。
- 對于 GPU 測試,我們在 T4 GPU’上使用了 RAPIDS 加速器,該加速器針對分析重負載進行了優化,并且每個 DBU 的成本顯著降低。
- CPU 工作程序類型是一種內存優化架構,使用 Intel Xeon Platinum 8370C(Ice Lake) CPU 。
- 我們還利用了 Databricks Photon,一個原生的 CPU 加速器解決方案,以及用 C++重寫的傳統 Java 運行時的加速版本。
選擇這些參數是為了確保實驗的可重復性和對常見用例的適用性。
后果
為了以一致的方式評估實驗結果,我們開發了一個名為每分鐘調整 DBU(ADBU)的復合指標。ADBU 以 DBU 為基礎,計算如下:

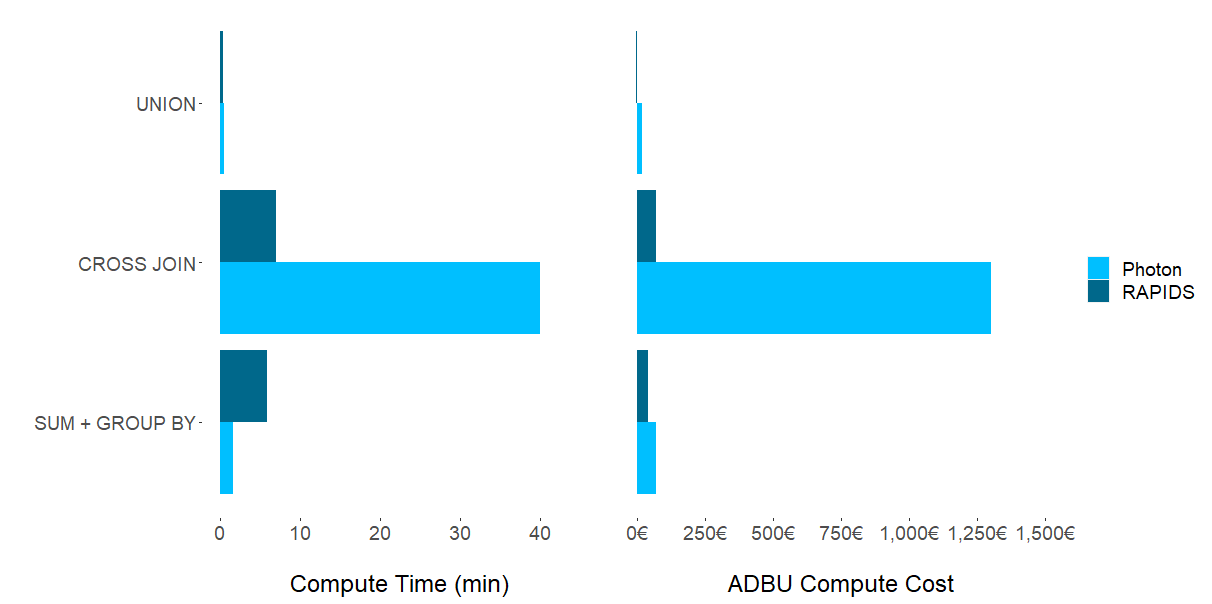
實驗結果表明,不存在一個芯片組( CPU 或 CPU )占主導地位的計算 Spark SQL 任務。如圖 1 所示,數據集特征和集群配置的適用性對為特定任務選擇哪個框架的影響最大。盡管不足為奇,但問題仍然存在:哪些 ETL 過程應該遷移到 GPU ?
UNION 操作
盡管 T4 上的 RAPIDS 加速器 Spark 使用 UNION 運算生成的結果具有較低的成本和執行時間,但與 CPU 相比,差異可以忽略不計。對于數據集和 CPU SQL 操作的這種組合,將現有的 ETL 管道從 CPU 移動到 GPU 似乎是沒有必要的。盡管這項研究未經測試,但更大的數據集可能會產生值得轉移到 GPU 的結果。
CROSS JOIN 操作
對于計算量大的 CROSS JOIN 操作,我們觀察到通過在光子( GPU )上使用 RAPIDS 加速器( GPU )可以節省一個數量級的時間和成本。
對這些性能提高的一種可能解釋是,CROSS JOIN 是一個笛卡爾乘積,它涉及非結構化數據列與自身的乘積。這導致復雜性呈指數級增長。 GPU 的性能增益非常適合這種類型的大規模并行操作。
成本差異的主要驅動因素是,我們實驗的 CPU 集群的 DBU 評級遠高于所選的 GPU 集群。
SUM+GROUP BY 運算
對于聚合操作(SUM+GROUP BY),我們觀察到混合結果。光子( CPU )提供了顯著更快的計算時間,而 RAPIDS 加速器( GPU )提供更低的總體成本。觀察單個實驗運行,我們觀察到光子成本越高,DBU 就越高,而與 T4 相關的成本則明顯更低。
這就解釋了在這部分實驗中使用 RAPIDS 加速器的總體成本較低的原因。總之,如果速度是目標,光子顯然是贏家。更注重價格的用戶可能更喜歡 RAPIDS 加速器更長的計算時間,以顯著節省成本。
決定使用哪個體系結構
在常用的聚合(SUM+GROUP BY)實驗中, CPU 集群在執行時間方面獲得了性能。然而,這是以更高的相關集群成本為代價的。對于 CROSS JOIN,一種不太常見的高計算和高度并行化操作, GPU 在更高的速度和更低的成本方面占據主導地位。UNION 在計算時間和成本方面的比較差異可以忽略不計。
GPU (以及關聯的 RAPIDS 加速器)在很大程度上取決于數據結構、數據規模、執行的 ETL 操作和用戶的技術深度。
GPU 用于 ETL
通常, GPU 非常適合大型復雜數據集和 Spark SQL 操作,這些操作具有高度并行性。實驗結果表明,在 CROSS JOIN 情況下使用 GPU ,因為它們易于并行化,并且可以隨著數據大小和復雜性的增長而輕松擴展。
需要注意的是,數據的規模并不如數據的復雜性和所選操作重要,如 SUM+GROUP BY 實驗所示。(與 CROSS JOIN 相比,這個實驗涉及更多的數據,但計算復雜度更低。)NVIDIA 免費提供預計的 GPU 加速收益估計,基于對 Spark 日志文件的分析。
CPU 用于 ETL
根據實驗,某些 Spark SQL 操作(如 UNIONs)在成本和計算時間方面的差異可以忽略不計。在這種情況下,可能不需要轉換到 GPU 。此外,對于聚合(SUM+GROUP BY),可以根據情景需求有意識地選擇速度而非成本,其中 CPU 執行速度更快,但成本更高。
在內存中的計算很簡單的情況下,使用已建立的 CPU ETL 架構可能是理想的。
討論和未來考慮
本實驗探索了一步 GPU SQL 操作。例如,單個 CROSS JOIN 或單個 UNION,省略了涉及多個步驟的更復雜的 ETL 作業。未來一個有趣的實驗可能包括在細粒度級別優化 ETL 處理,在單個作業或腳本中向 Spark 或 GPU 發送單獨的 Spark SQL 操作,并針對時間和計算成本進行優化。
精明的 Spark 用戶可能會嘗試專注于實現腳本策略,以充分利用默認運行時,而不是實現更高效的范例。示例包括:
- Spark SQL 聯接策略(廣播聯接、混洗合并、散列聯接等)
- 高性能數據結構(例如,將數據存儲在拼花文件中,與文本文件相比,拼花文件在云架構中具有高性能)
- 可重復使用的戰略性數據緩存
我們的實驗結果表明,利用 GPU 進行 ETL 可以提供足夠的額外性能,以保證實現 GPU architecture。
盡管在 Azure Databricks 上默認情況下不支持 RAPIDS 加速器Apache Spark。這需要安裝 .jar 文件,可能需要進行一些調試。這筆技術債務在很大程度上得到了償還,因為 RAPIDS 加速器的后續使用是無縫和直接的。 NVIDIA 支持隨時可在必要時提供幫助。
最后,我們選擇將所有創建的集群保持在每小時 100 個 DBU 以下,以管理實驗成本。我們只嘗試了一種大小的光子簇。實驗結果可能會隨著集群大小、工人數量和其他實驗參數的變化而變化。我們認為這些結果對于運行 ETL 作業的組織中的許多典型用例來說是足夠穩健和相關的。
結論
NVIDIA T4 GPU 是專門為分析工作負載設計的,它實現了與利用 GPU – 基于計算相關的性價比的飛躍。在 NVIDIA RAPIDS Accelerator for Apache Spark 上,尤其是在 NVIDIA T4 GPU 上運行時,有可能顯著降低某些常見 ETL SparkSQL 操作的成本和執行時間,尤其是那些高度并行的操作。
如果您想在自己的 Apache Spark 工作負載上實現此解決方案而不更改代碼,請訪問 NVIDIA/spark-rapids-examples GitHub 或 Apache Spark 工具 頁面。示例代碼和應用程序展示了在數據處理或機器學習管道中使用 RAPIDS 加速器的性能和好處。
?