
我們被卡住了。真的卡住了。隨著艱難的交付截止日期的臨近,我們的團隊需要弄清楚如何在幾個小時內處理數萬億銷售點交易記錄的復雜提取轉換負載( ETL )工作。這項工作的結果將為一系列下游機器學習( ML )模型提供信息,這些模型將為全球零售商做出關鍵的零售分類分配決策。這些模型需要在真實的事務數據上進行測試和驗證。
然而,到目前為止,還沒有一個 ETL 作業完成。每次測試運行都需要幾天的處理時間,所有測試都必須在完成前終止。
使用 NVIDIA RAPIDS Accelerator for Apache CPU ,與在 Spark 上使用 Spark 的傳統方法相比,我們觀察到運行時間顯著加快,并節省了額外的成本。讓我們后退一點。
擺脫困境:全球零售商的 ETL
凱捷的人工智能與分析實踐是一個數據科學團隊,提供定制的、平臺無關的和語言無關的解決方案,這些解決方案涵蓋了數據科學的全部范疇,從數據工程到數據科學,再到機器學習工程和 MLOps 。我們擁有一支擁有豐富技術經驗和知識的團隊,其中包括 100 多名北美數據科學顧問,以及 1600 多名全球數據科學家。
對于該項目,我們的任務是為一家國際零售商提供端到端的解決方案,包括以下可交付成果:
- 創建基礎 ETL
- 構建一系列 ML 模
- 創建優化引擎
- 設計基于網絡的用戶界面,以可視化和解釋所有數據科學和數據工程工作
這項工作最終為每個零售店提供了一個最佳的零售分類分配解決方案。使該項目更加復雜的是,在我們開始引入光環效應(例如跨部門的交互效應)后,狀態空間爆炸。例如,如果我們將貨架空間分配給水果,這對與將貨架空間進一步分配給蔬菜相關的 KPI 有什么影響,我們如何共同優化這些交互效應?
但是,如果沒有基本的 ETL , ML 、優化或前端都無關緊要。所以我們被卡住了。我們在 Azure 云環境中使用 Databricks 和 Spark SQL 進行操作,即使在那時,我們也沒有在下游模型要求的時間內觀察到我們需要的結果。
在緊迫感的刺激下,我們探索了可能使我們能夠顯著加快 ETL 過程的潛在變化。
加速 ETL
代碼的編寫效率低嗎?它是否最大限度地提高了計算速度?它必須被重構嗎?
我們重寫了幾次代碼,并測試了各種集群配置,結果只是觀察到了邊際收益。然而,由于成本限制,我們擴大規模的選擇有限,沒有一個能提供我們取得重大收益所需的馬力。還記得為期末考試臨時抱佛腳的時候嗎?當時時間有點緊,你肚子里的坑一分鐘比一分鐘深?我們很快就沒有選擇和時間了。我們需要幫助。現在
在 Databricks Runtime 9 . 1 LTS 中, Databrickss 發布了一個名為 Photon 的原生矢量化查詢引擎。 Photon 是一個 C ++運行時環境,與傳統的 Java 運行時環境相比,它可以運行得更快,并且更可配置。數周來, Databricks 支持幫助我們為 ETL 應用程序配置 Photon 運行時。
我們還聯系了 NVIDIA 的合作伙伴,他們最近更新了 RAPIDS 加速軟件庫套件。基于 CUDA -X AI , RAPIDS 完全在 GPU 上執行數據科學和分析管道,其 API 看起來和感覺都像最流行的開源庫。它們包括一個與 Spark 的查詢計劃器集成的插件,以加快 Spark jobs 的速度。
在接下來的一個月里,在 Databricks 和 NVIDIA 的支持下,我們并行開發了這兩種解決方案,將之前無法維持的運行時間降至兩小時以下,速度驚人!
這是我們需要達到的下游 ML 和優化模型的目標速度。壓力消除了,僅僅是因為比我們使用 RAPIDS 提前幾天解決了 Photon 的 ETL 問題, Databricks Photon 解決方案就投入了生產。
從圍繞 ETL 過程的緊迫截止日期的焦慮中走出來后,我們收集了我們的想法和結果,并進行了事后分析。哪種解決方案實施得最快?哪種解決方案提供了最快的 ETL ?最便宜的 ETL ?我們將為類似的未來項目實施哪種解決方案?
實驗結果
為了評估我們的假設,我們創建了一組實驗。我們使用兩種方法在 Azure 上進行了這些實驗:
- Databricks Photon 將在第三代 Intel Xeon Platinum 8370C (冰湖) CPU 上以超線程配置運行。這就是最終為客戶投入生產的產品。
- RAPIDS Apache 加速器 Spark 將在 NVIDIA GPU 上運行。
我們將使用兩個不同的數據集在兩者上運行相同的 ETL 作業。數據集是 5 列和 10 列混合的數字和非結構化(文本)數據,每列有 2000 萬行,分別為 156 和 565 TB 。在基礎設施支出限制允許的情況下,最大限度地增加了工人人數。每個單獨的實驗進行三次。
實驗參數匯總在表 1 中。
| 工人類 | 驅動程序類 | 工人人數 | 站臺 | 列數 | 數據大小 |
| 標準_ NC6s _ v3 | 標準_ NC6s _ v3 | 12 | RAPIDS | 10 | 565 |
| 標準_ E20s _ v5 | 標準_ E16s _ v5 | 6 | PHOTON | 10 | 565 |
| 標準_ NC6s _ v3 | 標準_ NC6s _ v3 | 16 | RAPIDS | 10 | 565 |
| 標準_ NC6s _ v3 | 標準_ NC6s _ v3 | 14 | RAPIDS | 10 | 565 |
| 標準_ NC6s _ v3 | 標準_ NC6s _ v3 | 14 | RAPIDS | 5 | 157 |
| 標準_ E20s _ v5 | 標準_ E16s _ v5 | 6 | PHOTON | 5 | 148 |
我們研究了運行時的純速度。實驗結果表明,工人類型、駕駛員類型、工人、數據集大小、平臺、數據列和數據集大小的所有不同組合的運行時間都非常一致,平均每次運行 4 分 37 秒,最小和最大運行時間分別為 4 分 28 秒和 4 分 54 秒。
我們有一個 DBU /小時的基礎設施支出限制,因此,每個測試集群的不同工人也有限制。作為回應,我們開發了一種復合指標,能夠對結果進行最平衡的評估,我們將其命名為每分鐘調整 DBU ( ADBU )。 DBU 是 Databricks 單元,是計算成本的專有 Databrickss 單元。 ADBU 計算如下:
?
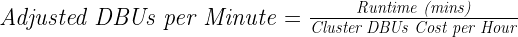
總的來說,考慮到云平臺成本,與在 Photon 運行時運行 Spark 相比,我們觀察到使用 RAPIDS Accelerator for Apache Spark ADBU 減少了 6% 。這意味著我們可以使用 RAPIDS 以更低的成本實現類似的運行時間。
注意事項
其他考慮因素包括實現的容易性和重寫代碼的必要性,這兩者對于 RAPIDS 和 Photon 來說都是相似的。第一次實施這兩種方法都不適合膽小的人。
完成一次后,我們非常確信,我們可以在幾個小時內為每個任務復制所需的集群配置任務。此外, RAPIDS 和 Photon 都不需要我們重構 Spark SQL 代碼,這節省了大量時間。
該實驗的局限性是復制次數少,工人和驅動程序類型的數量有限,以及工人組合的數量,所有這些都是由于基礎設施成本的限制。
接下來是什么?
最后,將 Databricks 與 RAPIDS AcceleratorforApache Spark 相結合,有助于擴展我們的數據工程工具包的廣度,并展示了 GPU 上 ETL 處理的新的可行范例。
想要了解更多信息,請訪問 RAPIDS 加速器 for Apache Spark。






