在處理表格數據時,特征工程仍然是提高模型準確性的最有效方法之一。與 NLP 和計算機視覺等神經網絡可以從原始輸入中提取豐富模式的領域不同,性能最佳的表格模型 (尤其是梯度提升決策樹) 仍然從精心打造的特征中獲得顯著優勢。然而,潛在的有用特征數量意味著,深入研究這些特征通常需要大量的計算。在 CPU 上使用標準 pandas 生成和驗證數百或數千個功能理念的速度太慢,無法實現。
這就是 GPU 加速改變游戲規則的地方。借助 NVIDIA cuDF-pandas,我可以在 GPU 上加速 pandas 操作,無需更改代碼,從而為 Kaggle 2 月的 Playground 比賽快速生成和測試 10000 多個設計功能。這種加速的發現過程是關鍵的差異化因素。在大幅縮短的時間內 (幾天而不是潛在的幾個月) ,發現的最佳 500 個特征顯著提高了我的 XGBoost 模型的準確性,在預測背包價格的競賽中獲得第一名。下面,我將分享由 cuDF-pandas 加速的核心特征工程技術,這些技術促成了這一結果。
Groupby(COL1)[COL2].agg(STAT)
最強大的特征工程技術是逐組聚合。即,我們執行代碼 groupby(COL1)[COL2].agg(STAT)。這就是我們按 COL1 列和聚合 (即。計算) 另一列 COL2 上的統計 STAT。我們使用 NVIDIA cuDF-Pandas 的速度來探索數千個 COL1、COL2、STAT 組合。我們會嘗試統計 (STAT) ,例如“mean”、“std”、“count”、“min”、“max”、“nunique”、“skew”等。我們從表格數據的現有列中選擇 COL1 和 COL2。當 COL2 是目標列時,我們會使用嵌套交叉驗證來避免驗證計算中的泄漏。當 COL2 是目標時,此操作稱為 Target Encoding。
Groupby(COL1)[‘Price’].agg(HISTOGRAM BINS)
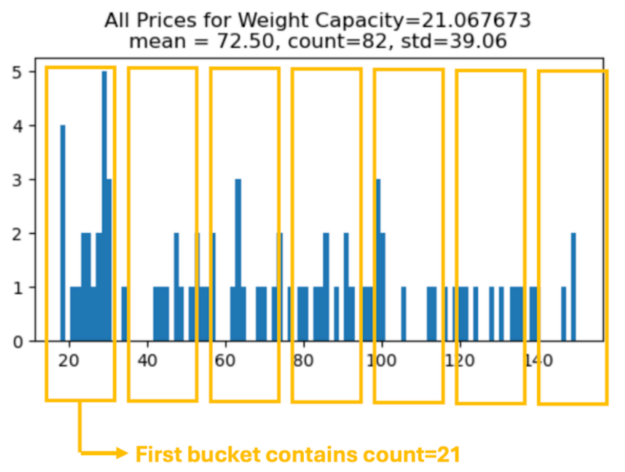
當我們使用 groupby(COL1)[COL2] 時,每個組都有一個數字分布 (集) 。我們無需計算單個統計數據 (并新建一列) ,而是可以計算描述此數字分布的任何數字集合,并共同創建許多新列。
下方顯示了 Weight Capacity = 21.067673 組的直方圖。我們可以統計每個 (等距) bucket 中的元素數量,并為每個 bucket 數量創建新的 engineered feature,以便按組返回!下方顯示 7 個 bucket,但我們可以將 bucket 數量視為 hyperparameter。
result = X_train2.groupby("WC")["Price"].apply(make_histogram)X_valid2 = X_valid2.merge(result, on="WC", how="left") |
Groupby(COL1)[‘Price’].agg(QUANTILES)
我們可以 groupby 并計算 QUANTILES = [5,10,40,45,55,60,90,95] 的 quantiles,然后返回八個值以創建八個新列。
for k in QUANTILES: result = X_train2.groupby('Weight Capacity (kg)').\ agg({'Price': lambda x: x.quantile(k/100)}) |
將所有 NAN 作為單個 Base-2 列
我們可以在多個列上從所有 NAN 創建新列。這是一個功能強大的列,我們隨后可以將其用于 groupby 聚合或與其他列的組合。
train["NaNs"] = np.float32(0)for i,c in enumerate(CATS): train["NaNs"] += train.isna()*2**i |
將數值列放入 Bins 中
本次比賽中最有力的 (預測性) 欄目是“Weight Capacity” 欄目。我們可以通過對該列進行四舍五入來創建更強大的列。
for k in range(7,10): n = f"round{k}" train[n] = train["Weight Capacity (kg)"].round(k) |
將 Float32 提取為數字
本次比賽中最有力的 (預測性) 欄目是“Weight Capacity” 欄目。我們可以通過提取數字來基于此列創建更強大的列。這種技術看起來很奇怪,但通常用于從產品 ID 中提取信息,其中產品 ID 中的單個數字表示產品的相關信息,例如品牌、顏色等。
for k in range(1,10): train[f'digit{k}'] = ((train['Weight Capacity (kg)'] * 10**k) % 10).fillna(-1).astype("int8") |
分類列的組合
此數據集中有 8 個分類列 (不包括數值列 Weight Capacity) 。通過組合所有分類列的組合,我們可以再創建 28 個分類列。首先,我們將原始分類列標記為整數,其中 -1 表示 NAN。然后,我們將整數組合起來:
for i,c1 in enumerate(CATS[:-1]): for j,c2 in enumerate(CATS[i+1:]): n = f"{c1}_{c2}" m1 = train[c1].max()+1 m2 = train[c2].max()+1 train[n] = ((train[c1]+1 + (train[c2]+1)\ /(m2+1))*(m2+1)).astype("int8") |
使用原始 Dataset 創建合成數據
我們可以按照制造商建議的零售方式處理創建本次競賽合成數據的原始數據集。并將本次競賽的數據視為各個商店的價格。因此,我們可以通過為每一行提供 MSRP 的相關信息來幫助預測:
tmp = orig.groupby("Weight Capacity (kg)").Price.mean()tmp.name = "orig_price"train = train.merge(tmp, on="Weight Capacity (kg)", how="left") |
分區功能
使用 groupby(COL1)[COL2].agg(STAT) 創建新列后,我們可以將這些新列組合成更多新列。例如:
# COUNT PER NUNIQUEX_train['TE1_wc_count_per_nunique'] =\ X_train['TE1_wc_count']/X_train['TE1_wc_nunique']# STD PER COUNTX_train['TE1_wc_std_per_count'] =\ X_train['TE1_wc_std']/X_train['TE1_wc_count'] |
總結
本次 Kaggle 比賽的第一名結果不僅在于找到合適的功能,還在于快速找到這些功能。特征工程對于更大限度地提高表格模型的性能仍然至關重要,但使用 CPU 的傳統方法通常會出現問題,導致大量特征發現 速度 緩慢,令人望而卻步。
NVIDIA cuDF-pandas 正在改變一切可能。通過加速 GPU 上的 pandas 操作,它能夠在大幅縮短的時間內大規模探索和生成新功能。這使我們能夠找到最佳功能并構建比以前更準確的模型。查看解決方案 源代碼 以及相關的 Kaggle 討論帖子 此處 以及 此處 。
如果您想了解更多信息,請查看我們關于 特征工程 的 GTC 2025 研討會或在 Python 中 將加速計算引入數據科學 ,或注冊我們的 DLI 學習路徑 課程,了解數據科學。
?