AI 生成化學有可能徹底改變科學家在藥物研發、健康以及材料科學和工程領域的工作方式。研究人員無需借助“化學直覺”手動設計分子或篩選數百萬種現有化學物質,而是可以訓練神經網絡來提出適合所需特性的新型分子結構。這種能力開辟了廣闊的化學空間,這是以前無法系統探索的。
雖然一些早期成功表明,生成式 AI 有望通過提出化學家可能沒有考慮過的創造性解決方案來加速創新,但這些成功只是一個開始。生成式 AI 還不是分子設計的靈丹妙藥,將 AI 建議的分子轉化為現實世界通常比 一些標題所顯示的困難得多 。
虛擬設計與現實世界影響之間的差距是當今 AI 驅動的分子設計面臨的核心挑戰。計算生成式化學模型需要實驗反饋和分子模擬來確認其設計的分子是否穩定、可合成且具有功能性。與自駕駛汽車一樣,AI 必須經過真實駕駛數據或高保真模擬的訓練和驗證,才能在不可預測的道路上行駛。正如用于生成式虛擬篩選的 NVIDIA BioNeMo Blueprint 的最新更新所示,如果沒有這種基礎,理論上兩個 AI 系統都有可能生成有前景的解決方案,但在現實世界中進行測試時卻失敗了。
Oracles:來自實驗和高保真模擬的反饋
將 AI 設計與現實聯系起來的一種強大方法是通過 oracle (也稱為 scoring function) 。在生成式分子設計中,oracle 是一種反饋機制,即一種測試或評估機制,用于告知我們所提議的分子在預期結果方面的表現,通常是分子或實驗屬性 (例如 potency、safety 和 feasibility) 。
此預言機可以是:
基于實驗:用于測量 AI 設計的藥物分子與目標蛋白質結合的程度 。
| 實驗性 Oracle 類型 | 優勢 | 限制 | 實際應用 |
| 體外分析 (例如生化、細胞測試、高通量篩選)? | 生物相關性高,小批量快速,可通過自動化實現擴展。 | 成本高昂,吞吐量低于模擬,可能無法捕獲 體內效果 。 | 用于在臨床試驗前識別和優化候選藥物的標準。 |
| In vivo 模型 (動物測試) | 提供有關安全性配置文件、劑量等的見解,這些信息通常用于藥物審批。 | 成本高昂、速度緩慢、倫理道德方面的問題以及物種差異可能會限制與人類的相關性。 | 用于臨床前藥物開發,同時越來越多地通過模擬進行補充。 |
這種預言機基于計算,使用高質量計算 (例如分子動力學模擬) 準確預測屬性,例如用于計算結合能 (藥物放入酶口袋的強度) 的自由能方法,或對材料穩定性的量子化學計算 。當實驗室測試速度緩慢、成本高昂或需要進行大規模評估時,這些都是計算機模擬的備用模型。
| 計算 Oracle 類型 | 優勢 | 限制 | 實際應用 |
| 基于規則的過濾器 (Lipinski 的 Rule of 5、PAINS 警報等) | 快速標記較差的候選藥物,這是廣泛接受的啟發式算法(heuristics)。 | 過于簡單化,可能會拒絕可行的藥物 | 用于在藥物設計初期快速過濾掉不合適的化合物。 |
| QSAR (從結構中預測活動的統計模型) | 快速、經濟高效,適用于 ADMET 屬性篩選。 | 需要實驗數據,難以處理新的化學物質(novel chemistries)。 | 用于 lead 優化和篩選出較差的候選項。 |
| 分子對接 (基于結構的虛擬篩選) | 快速篩選大型庫,說明分子如何與目標結合。 | 與實驗結果相比,通常不準確的假設是剛性結構。 | 在早期藥物發現中很常見,用于入圍前景良好的化合物。 |
| 分子動力學和自由能模擬 (模擬分子隨時間變化的行為) | 與對接相比,對靈活性和交互進行建模更真實。 | 計算密集、速度緩慢,需要專業知識。 | 用于候選藥物的后期細化。 |
| 基于量子化學的方法 (?第一原理電子結構模擬 ) | 提供對分子相互作用、電子屬性和反應機制的高度準確預測。 | 計算成本極高,無法隨系統大小進行擴展,并且需要大量專業知識。 | 用于預測相互作用能、優化領先化合物以及了解原子層面的反應機制。 |
在實踐中,研究人員通常使用分層策略,即廉價的高吞吐量預言機 (如快速計算屏幕) 過濾大量 AI 生成的分子。然后,使用更高準確性的預言機 (詳細的模擬或實際實驗) 評估最有前景的候選項。這可以將昂貴的實驗室工作集中在最重要的 AI 建議上,從而節省時間和資源。
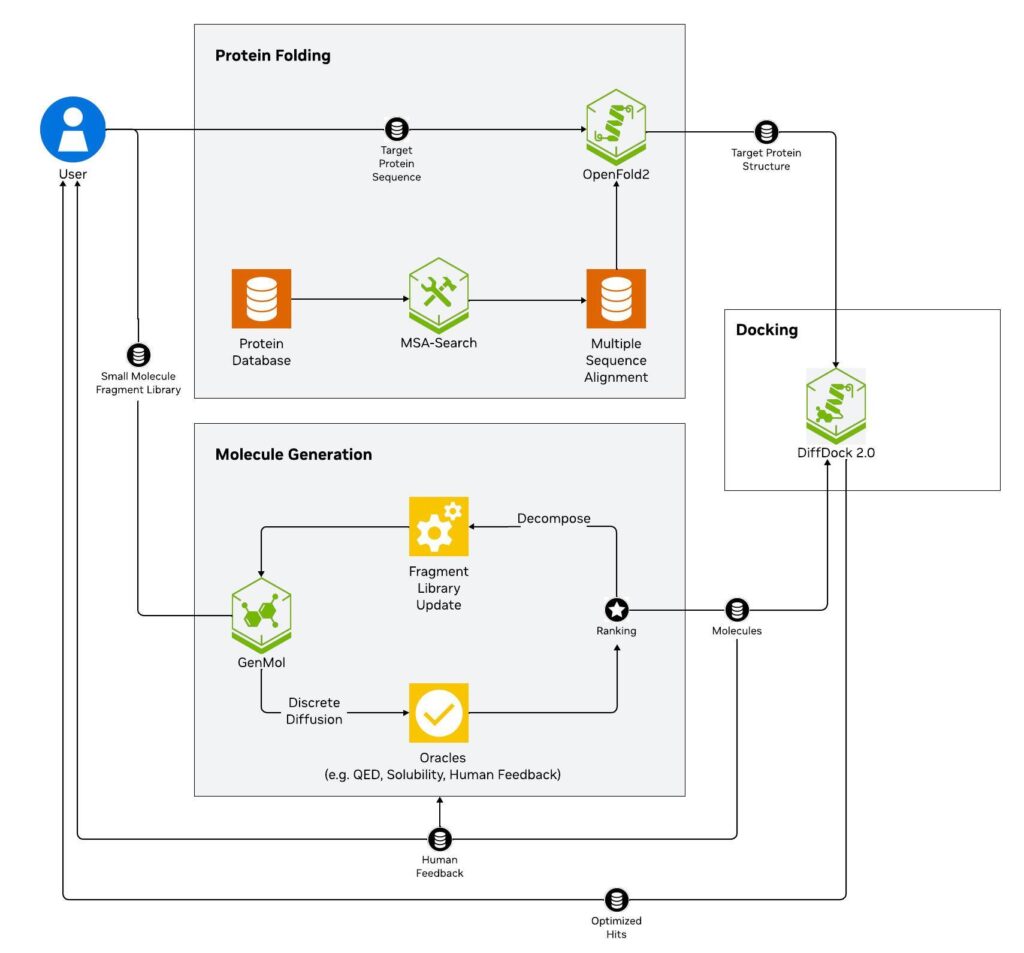
用于生成式虛擬篩選的 NVIDIA BioNeMo Blueprint (圖 1) 就是一個示例:
- 目標蛋白質序列傳遞給 OpenFold2 NIM,后者使用 MSA-Search NIM 的多序列對齊準確確定蛋白質的 3D 結構。
- 將初始化化學庫分解為碎片,并傳遞給 GenMol NIM,從而生成各種小分子。
- 對初始結構進行計算評分,并針對藥物的多個特征 (例如預測溶解度和 Quantitative Estimate of Drug-likeness (QED)) 進行排名。
- 這些分數用于在迭代生成周期中對生成的分子進行排序和篩選,直到它們達到進一步測試所需的閾值。使用 DiffDock NIM 預測這些生成的小分子與目標蛋白的結合姿勢。
- 最后,優化后的分子返回給用戶進行合成和進一步的實驗室驗證。
基于片段的分子設計中的 Oracles
按照以下偽代碼,使用 NVIDIA GenMol NIM 實現迭代分子生成和優化流程。 此過程包括從片段庫生成分子、使用 oracle 對其進行評估、選擇 top 候選分子、將其分解為新的片段,以及重復該循環。
# Import necessary modulesfrom genmol import GenMolModel, SAFEConverter # Hypothetical GenMol APIfrom oracle import evaluate_molecule # Hypothetical oracle functionfrom rdkit import Chemfrom rdkit.Chem import AllChem, BRICSimport random# Define hyperparametersNUM_ITERATIONS = 10 # Number of iterative cyclesNUM_GENERATED = 1000 # Number of molecules generated per iterationTOP_K_SELECTION = 100 # Number of top-ranked molecules to retainSCORE_CUTOFF = -0.8 # Example binding affinity cutoff for filtering# Initialize GenMol modelgenmol_model = GenMolModel()# Load initial fragment library (list of SMILES strings)with open('initial_fragments.smi', 'r') as file: fragment_library = [line.strip() for line in file]# Iterative molecule design loopfor iteration in range(NUM_ITERATIONS): print(f"Iteration {iteration + 1} / {NUM_ITERATIONS}") # Step 1: Generate molecules using GenMol generated_molecules = [] for _ in range(NUM_GENERATED): # Randomly select fragments to form a SAFE sequence selected_fragments = random.sample(fragment_library, k=random.randint(2, 5)) safe_sequence = SAFEConverter.fragments_to_safe(selected_fragments) # Generate a molecule from the SAFE sequence generated_mol = genmol_model.generate_from_safe(safe_sequence) generated_molecules.append(generated_mol) # Step 2: Evaluate molecules using the oracle scored_molecules = [] for mol in generated_molecules: score = evaluate_molecule(mol) # Example: docking score, ML predicted affinity scored_molecules.append((mol, score)) # Step 3: Rank and filter molecules based on oracle scores scored_molecules.sort(key=lambda x: x[1], reverse=True) # Sort by score (higher is better) top_molecules = [mol for mol, score in scored_molecules[:TOP_K_SELECTION] if score >= SCORE_CUTOFF] print(f"Selected {len(top_molecules)} high-scoring molecules for next round.") # Step 4: Decompose top molecules into new fragment library new_fragment_library = set() for mol in top_molecules: # Decompose molecule into BRICS fragments fragments = BRICS.BRICSDecompose(mol) new_fragment_library.update(fragments) # Step 5: Update fragment library for next iteration fragment_library = list(new_fragment_library)print("Iterative molecule design process complete.") |
受控分子生成中的 Oracles
按照以下偽代碼,使用 MolMIM NIM 實現由 Oracle 驅動的迭代分子生成過程。 此方法包括生成分子、使用 Oracle 評估分子、選擇出色的候選分子,以及根據 Oracle 反饋完善生成過程 (請參閱此處的示例代碼 Notebook)。
# Import necessary modulesfrom molmim import MolMIMModel, OracleEvaluator # Hypothetical MolMIM and Oracle APIimport random# Define hyperparametersNUM_ITERATIONS = 10 # Number of iterative cyclesNUM_GENERATED = 1000 # Number of molecules generated per iterationTOP_K_SELECTION = 100 # Number of top-ranked molecules to retainSCORE_CUTOFF = 0.8 # Example oracle score cutoff for filtering# Initialize MolMIM model and Oracle evaluatormolmim_model = MolMIMModel()oracle_evaluator = OracleEvaluator()# Iterative molecular design loopfor iteration in range(NUM_ITERATIONS): print(f"Iteration {iteration + 1} / {NUM_ITERATIONS}") # Step 1: Generate molecules using MolMIM generated_molecules = molmim_model.generate_molecules(num_samples=NUM_GENERATED) # Step 2: Evaluate molecules using the oracle scored_molecules = [] for mol in generated_molecules: score = oracle_evaluator.evaluate(mol) # Returns a score between 0 and 1 scored_molecules.append((mol, score)) # Step 3: Rank and filter molecules based on oracle scores scored_molecules.sort(key=lambda x: x[1], reverse=True) # Sort by score (higher is better) top_molecules = [mol for mol, score in scored_molecules[:TOP_K_SELECTION] if score >= SCORE_CUTOFF] print(f"Selected {len(top_molecules)} high-scoring molecules for next round.") # Step 4: Update MolMIM model with top molecules molmim_model.update_model(top_molecules)print("Iterative molecular design process complete.") |
將 Oracle(基于實驗和計算的反饋機制)集成到 AI 驅動的分子設計中,從根本上改變了藥物設計。通過在生成模型和現實世界的驗證之間建立連續循環,研究人員可以超越理論分子生成,轉而使用實用、可合成且具有功能性的候選藥物。
這種實驗室在環方法能夠:
- 使用 GenMol NIM 和 MolMIM NIM 等 AI 模型加快迭代周期,根據實驗或高精度計算反饋生成和完善分子。
- 高效的資源分配,在這種情況下,計算預言機可以快速篩選數千種分子,然后再將成本高昂的實驗室實驗重點放在具有廣闊前景的候選分子上。
- 通過將真實的實驗結果整合到 AI 模型中,幫助他們更好地預測藥物相似性,從而提高準確性和泛化程度。
隨著 AI 模型和 Oracle 系統變得更加先進,我們即將進入 AI 和實驗科學共同發展的時代,推動藥物設計取得突破性進展。通過集成高質量的 Oracle,虛擬分子設計與現實世界成功之間的差距將繼續縮小,為精準醫療等領域帶來新的可能性。
試用用于藥物設計的預言機
- 在用于生成式虛擬篩選的 NVIDIA BioNeMo Blueprint 中測試您自己的預言機,以生成基于片段的分子。
- 或者,使用 MolMIM NIM 進行 Oracle 引導的分子生成。
?