數據科學家經常把金融界當作測試新技術的游樂場。金融數據已經被記錄了幾十年,而且都是數字形式的,因此很容易處理。另外,你總是有機會創造一個賺錢的模型!
在金融領域,投資的總體目標是最大限度地提高回報(投資的收益或損失),同時最小化風險(實際結果與預測結果不同的可能性)。簡而言之,投資就是數學。
這篇文章介紹了一種投資組合優化策略,可以幫助最小化風險敞口。有了 GPU ,算法的速度可以提高 66 倍。
對于散戶投資者來說,這種加速對于頻繁的再平衡尤其有用。同時,機構投資者可以通過機器人顧問使用這種算法來管理資金。為每個獨特客戶的投資組合重新計算算法的計算成本可能會很高,通過引入 GPU 可以大大降低計算成本。
在這篇文章中,我將一步一步地介紹使用分層風險平價( HRP )進行有效投資組合分配的 ML 技術。本例將 Python 用于 RAPIDS 。
選擇有效財務預測的算法
1952 年,哈里·馬科維茨( Harry Markowitz )引入了一種被稱為現代投資組合理論的投資組合優化模型。該模型可以生成一個投資組合,在給定的風險水平下實現收益最大化。
不幸的是,故事并沒有就此結束。馬科維茨的現代投資組合理論只有在你知道每種股票的風險和回報的情況下才能產生最有效的投資組合。然而,這種情況并不總是發生,因為過去的表現并不代表未來的結果。
什么是分層風險平價?
2016 年,馬科斯·洛佩斯·德普拉多在他的論文 建立多樣化的投資組合,在樣本之外表現良好 中介紹了 HRP 。該算法背后的想法是使用 machine learning 技術,這樣股票只需與類似股票競爭投資組合中的現貨。
例如, Verizon 股票與 AT & T 高度相關。因此, Verizon 只與 AT & T 等股票競爭代表權,而不是與每個行業的所有股票競爭。
HRP 投資組合分配分步指南
在本文的其余部分中,我重點介紹了在 RAPIDS 上實現 HRP ,然后將其性能與其他常用技術進行比較。
獲取數據
在這篇文章中,我使用了從 2018 年 11 月到 2021 年 11 月的納斯達克和紐約證券交易所的每一個證券的每日調整后的收盤數據。該數據集是通過 NVIDIA/fsi-samples GitHub repo 的腳本獲得的
在硬件方面,我使用了帶有 NVIDIA Quadro 8000 GPU 的 i7 CPU 。對于軟件,我使用了 Python 3.9 和 RAPIDS 22.02 。
爭論數據
首先讀取數據集,并將其聚合到名為 m 的數據幀中。拋售任何空值股票。
import cudf
m1 = cudf.read_csv("MVO3.2021.11/NASDAQ/prices.csv")
m2 = cudf.read_csv("MVO3.2021.11/NYSE/prices.csv")
m = cudf.concat([m1, m2], axis = 1)
m = m.dropna(axis = 1)
一些證券表現不佳:一些證券多年保持不變,另一些證券包含非正值。移除這些不良證券。
data = m.values # data.shape = (days, nAssets) days = data.shape[0] logRetAll = cp.log(data[1:, :]/data[:-1, :]) moveMask = cp.count_nonzero(logRetAll, axis = 0) > (days * 0.9) # Require that each security moves day to day at least 90% of the time positiveMask = data.min(axis = 0) > 0 # Require that all the data is positive mask = moveMask & positiveMask data = data[:, mask] logRetAll = logRetAll[:, mask]
接下來,將 m 分為兩部分:培訓和測試階段。培訓期為 2018 年 11 月至 2020 年 11 月,測試時間為 2020 年 11 月至 2021 年 11 月。
split = int(days*2/3) train = data[:split, :] test = data[split:, :]
因此,在為訓練數據(而不是時間序列數據)創建日志返回矩陣后,可以使用內置的cuDF方法獲得相關和協方差矩陣。
# Obtain training cov/corr logRetTrain = logRetAll[:split - 1, :] corrTrain = cp.corrcoef(logRetTrain, rowvar = False) covTrain = cp.cov(logRetTrain, rowvar = False) * 252 # Annualized covariance
執行群集
要將股票聚集在一起,請定義一個度量,給出兩個股票之間的距離:
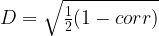
由于相關性的范圍是[-1 , 1],你可以看到
[0, 1],其中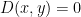



有關
D = cp.sqrt(0.5 * (1 - corr))
現在,您可以計算兩個股票之間的距離,對它們進行聚類,以便將相似的股票聚集在一起。
每個項目都放置在自己的簇中,最近的兩個簇連接在一起。然后,重新計算這個新簇和所有其他簇之間的距離。同樣,將兩個最近的簇組合在一起。重復這個過程,直到只有一個集群。可視化這種聚類的一種方法是使用樹狀圖。
from scipy.cluster.hierarchy import linkage, dendrogram dendrogram(linkage(D[:10, :10].get()));
cuML有一個內置的方法來執行此功能,在下面的代碼示例中使用。這比 scipy 的鏈接功能快得多,后者執行類似的功能。
from cuml import AgglomerativeClustering as AC # Create single linkage cluster using the Euclidean metric def cluster(D): model=AC(affinity='l2', connectivity='pairwise', linkage='single') model.fit(D); return model.children_
cluster()輸出一個 2 x N 矩陣,其中 N 是[0, i]和[1, i]表示為 i-th 迭代而加入的集群的索引。
使用矩陣序列化
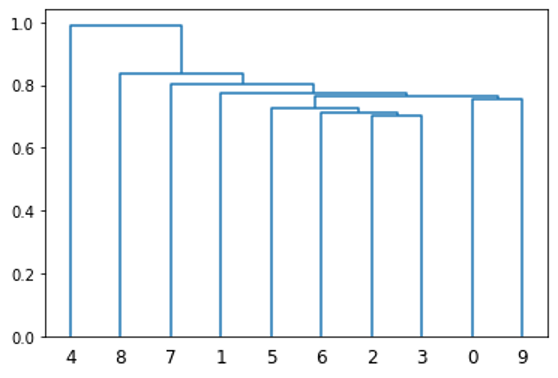
接下來,從這個集群中生成一個排序,像證券這樣的地方彼此靠近。例如,圖 2 的 x 軸根據前 10 只股票的聚類情況提供了它們的排序。這是通過矩陣序列化的迭代實現實現的,這是考古學中常用的一種技術。
def seriation(Z): N = Z.shape[1] stack = [2*N-2] res_order = [] while(len(stack) != 0): cur_idx = stack.pop() if cur_idx < N: res_order.append(cur_idx) else: stack.append(int(Z[1, cur_idx-N])) stack.append(int(Z[0, cur_idx-N])) return res_order
圖 3 顯示了得到的相關矩陣。
在圖 3 中,當您將排序應用于相關矩陣時,可以觀察到矩陣中出現的模式。這表明類似的股票彼此接近。
分配權重
最后,給股票分配權重。這是通過遞歸算法實現的。
將排序后的協方差矩陣一分為二,計算每一半的風險調整量,然后根據逆方差組合( IVP )方法為每一半分配權重。然后每一半重復這些步驟。
IVP 產生的權重與股票的風險量或方差成反比。也就是說,高風險股票的代表性較低,而低風險股票的代表性較高。
HRP 和 IVP 都是風險平價算法:它們只考慮基于過去表現的風險。
def recursiveBisection(V, l, r, W): #Performs recursive bisection weighting for a new portfolio #V is the sorted correlation matrix #l is the left index of the recursion #r is the right index of the recursion #W is the list of weights if r-l == 1: #One item return W else: #Split up V matrix mid = l+(r-l)//2 V1 = V[l:mid, l:mid] V2 = V[mid:r, mid:r] #Find new adjusted V V1_diag_inv = 1/cp.diag(V1) V2_diag_inv = 1/cp.diag(V2) w1 = V1_diag_inv/V1_diag_inv.sum() w2 = V2_diag_inv/V2_diag_inv.sum() V1_adj = w1.T@V1@w1 V2_adj = w2.T@V2@w2 #Adjust weights a2 = V1_adj/(V1_adj+V2_adj) a1 = 1-a2 W[l:mid] = W[l:mid]*a1 W[mid:r] = W[mid:r]*a2 W = recursiveBisection(V, l, mid, W) W = recursiveBisection(V, mid, r, W) return W
分析權重
您現在擁有執行 HRP 所需的所有工具。看看它的表現吧!
#Obtain the final weights and plot them
N = len(res_order)
V = covTrain[res_order, :][:, res_order]
W_tmp = recursiveBisection(V, 0, N, cp.ones(N))
W = cp.empty(len(W_tmp))
W[res_order] = W_tmp
plt.plot(W.get())
plt.xlabel("Security Index")
plt.ylabel("% allocation")
plt.title("HRP Allocation")
plt.plot();
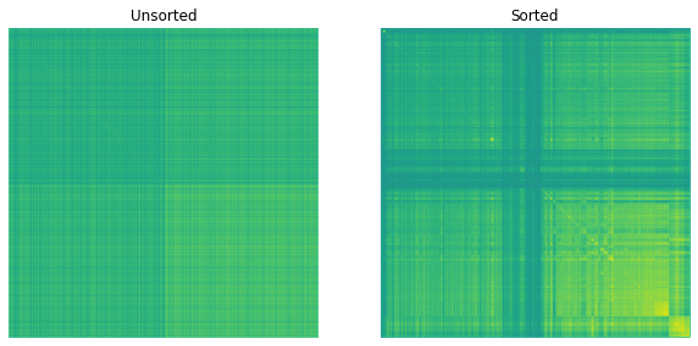
應用列出的方法后,您將得到一個變量 W ,該變量表示每個安全性的權重。
圖 4 顯示了結果。
這張圖表很難讀懂。您可以截斷它,以便只顯示權重大于 1% 的證券(圖 5 )。
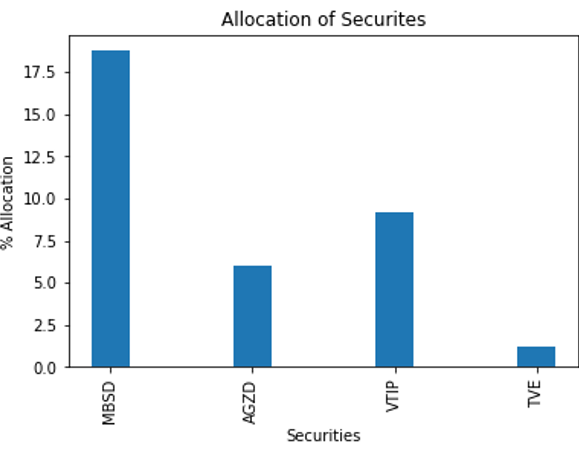
作為一個健全性檢查,圖 6 顯示了在培訓期間排名靠前的選手的表現。您希望確保證券的波動性相對較低。
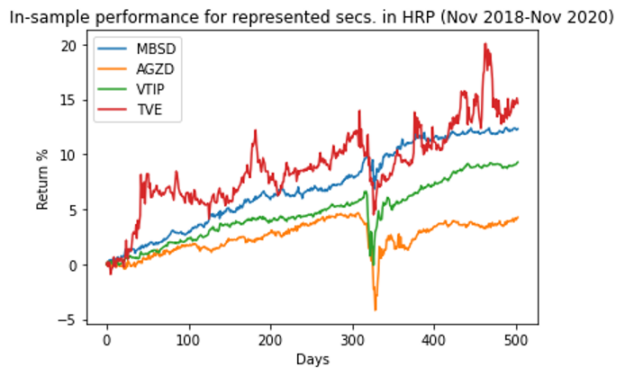
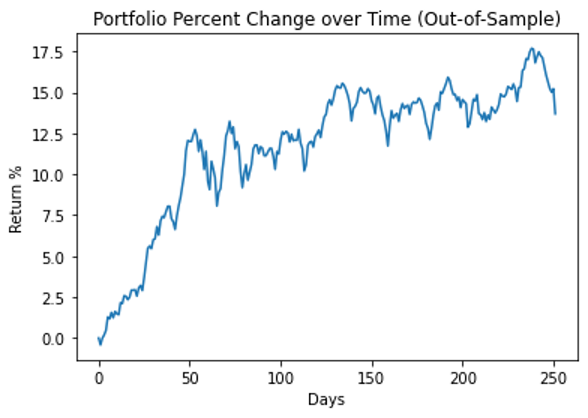
圖 7 顯示了整個投資組合在測試期間的性能。
與其他投資組合相比
你可以將這種表現與現代投資組合理論進行比較。在這個迭代中,我選擇了最大化夏普比率:一個跟蹤投資組合績效的指標。
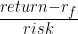
在這個公式中,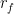
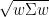

使用 scipy 執行數值優化。
from scipy.optimize import *
from scipy.optimize import *
def MPT(cov, R): cons = [{'type': 'eq', 'fun': lambda x: sum(x) - 1}, #sum(w)==1", {'type': 'ineq', 'fun': lambda x: x}] #each weight >=0 (no short selling)" res = minimize(lambda x: -(x@R-1.025)/sqrt(x.T@cov@x), x0=np.ones(len(R))/len(R), constraints=cons) #Minimize risk" return res.x
這是一個復雜的數值優化問題,尤其是考慮到你有 4000 多個資產。通過要求每種證券的夏普比率必須大于 1 ,將其縮減為 278 種證券。這種切斷是任意的,但建議屏蔽以減少運行時間。
W_MPT = cp.zeros(nAssets) sharpeTrain = (trainRetAll - 1.025) / (cp.std(logRetTrain, axis = 0) * math.sqrt(252)) # Annualized sharpe covnp = covTrain[sharpeTrain > 1, :][:, sharpeTrain > 1].get() # Numpy version of covariance matrix over training period, masked Rnp = trainRetAll[sharpeTrain > 1].get() # Return of all stocks over the training period, masked, in numpy W_MPT[sharpeTrain > 1] = MPT(covnp, Rnp, 1+i/100)
您還可以為反向方差投資組合生成權重。
invVarTrain = 1 / cp.var(logRetTrain, axis = 0) W_IVP = invVarTrain / invVarTrain.sum()
最后,生成一些隨機投資組合,選擇 15 種不同的證券,并隨機分配給每種證券。這模擬了不知情的散戶投資者可能選擇的投資組合。
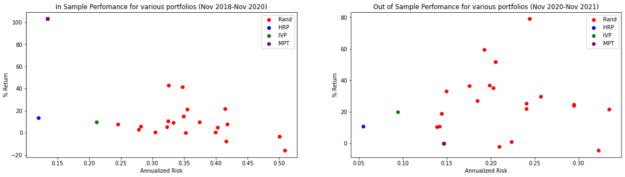
圖 8 顯示了所有投資組合的結果。
對于前面的投資組合,您可以在下表中生成夏普比率。
| Train (Nov 2018 – Nov 2020) | Test (Nov 2020 – Nov 2021) | |
| Median of Random Portfolios | 0.01 | 0.97 |
| HRP | 0.91 | 1.51 |
| IVP | 0.35 | 1.83 |
| MPT | 7.51 | -0.18 |
雖然 MPT 在培訓樣本期間的夏普比率較高,但在培訓期間,它會變為負值,這意味著投資組合的表現低于 2.5% 的無風險利率。這就證明了所謂的馬科維茨詛咒:雖然它在樣本中表現最佳,但它往往與樣本完全不同。
此外,雖然 IVP 在測試期間的夏普比率高于 MPT ,但請記住,這兩種方法都是 risk-parity 組合。他們的目標是將風險降至最低,不考慮回報。值得注意的是,在測試期間, HRP 的風險為 5.5% ,而 IVP 的風險為 9.4% 。
分析速度
另一個需要分析的是運行時與 CPU 的比較。您可以使用 SciPy 、 pandas 或 NumPy 等庫而不是 RAPIDS 來重新創建算法。
隨著分析的證券數量的增加,所需的計算能力也會增加。這也增加了并行化的能力, GPU 可以捕獲并行化。
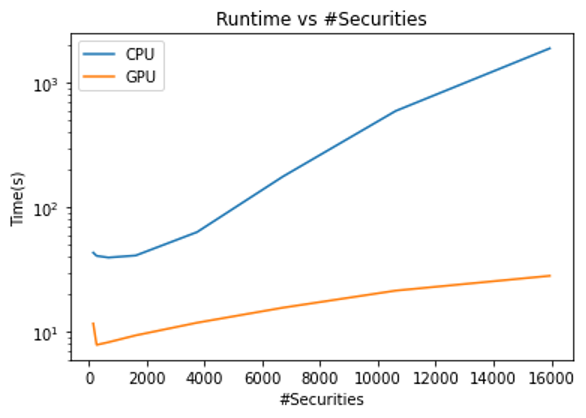
對于最大數量的證券,通過在 CPU 上運行 GPU 可以實現 66 倍的加速!即使在最壞的情況下,您仍然可以獲得 4 倍的加速比。
人力資源規劃的關鍵經驗
盡管 HRP 最初是為了演示機器學習如何應用于投資組合優化,但與反向方差相比,它可能會降低風險,并比現代投資組合理論具有更高的夏普比率。洛佩斯·德·普拉多在他的 建立多樣化的投資組合,其表現優于樣本之外的投資組合 論文中進一步證實了這一點,證明合成數據的提取率和方差較低。
投資者在尋找管理風險的方法或與其他金融技術相結合以降低所需回報率的風險時,可能會求助于 HRP 。
借助于 RAPIDS 提供的 GPU 加速, HRP 可以以相對較低的計算成本成為可行的投資組合優化工具。