 在前面的 兩 文章 中,我們研究了如何在主機和設備之間高效地移動數據。在我們的 CUDA C / C ++系列的第六篇文章中,我們將討論如何有效地從內核中訪問設備存儲器,特別是 全局內存 。
在前面的 兩 文章 中,我們研究了如何在主機和設備之間高效地移動數據。在我們的 CUDA C / C ++系列的第六篇文章中,我們將討論如何有效地從內核中訪問設備存儲器,特別是 全局內存 。
在 CUDA 設備上有幾種內存,每種內存的作用域、生存期和緩存行為都不同。到目前為止,在本系列中,我們已經使用了駐留在設備 DRAM 中的 全局內存 ,用于主機和設備之間的傳輸,以及內核的數據輸入和輸出。這里的名稱 global 是指作用域,因為它可以從主機和設備訪問和修改。全局內存可以像下面代碼片段的第一行那樣使用 __device__ de Clara 說明符在全局(變量)范圍內聲明,或者使用 cudaMalloc() 動態分配并分配給一個常規的 C 指針變量,如第 7 行所示。全局內存分配可以在應用程序的生命周期內保持。根據設備的 計算能力 ,全局內存可能被緩存在芯片上,也可能不在芯片上緩存。
__device__ int globalArray[256];
void foo()
{
...
int *myDeviceMemory = 0;
cudaError_t result = cudaMalloc(&myDeviceMemory, 256 * sizeof(int));
...
}
在討論全局內存訪問性能之前,我們需要改進對 CUDA 執行模型的理解。我們已經討論了如何將 線程被分組為線程塊 分配給設備上的多處理器。在執行過程中,有一個更精細的線程分組到 warps 。 GPU 上的多處理器以 SIMD ( 單指令多數據 )方式為每個扭曲執行指令。所有當前支持 CUDA – 的 GPUs 的翹曲尺寸(實際上是 SIMD 寬度)是 32 個線程。
全局內存合并
將線程分組為扭曲不僅與計算有關,而且與全局內存訪問有關。設備 coalesces? 全局內存加載并存儲由一個 warp 線程發出的盡可能少的事務,以最小化 DRAM 帶寬(在計算能力小于 2 . 0 的舊硬件上,事務合并在 16 個線程的一半扭曲內,而不是整個扭曲中)。為了弄清楚 CUDA 設備架構中發生聚結的條件,我們在三個 Tesla 卡上進行了一些簡單的實驗: a Tesla C870 (計算能力 1 . 0 )、 Tesla C1060 (計算能力 1 . 3 )和 Tesla C2050 (計算能力 2 . 0 )。
我們運行兩個實驗,使用如下代碼( GitHub 上也有 )中所示的增量內核的變體,一個具有數組偏移量,這可能導致對輸入數組的未對齊訪問,另一個是對輸入數組的跨步訪問。
#include
#include
// Convenience function for checking CUDA runtime API results
// can be wrapped around any runtime API call. No-op in release builds.
inline
cudaError_t checkCuda(cudaError_t result)
{
#if defined(DEBUG) || defined(_DEBUG)
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %sn", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
#endif
return result;
}
template
__global__ void offset(T* a, int s)
{
int i = blockDim.x * blockIdx.x + threadIdx.x + s;
a[i] = a[i] + 1;
}
template
__global__ void stride(T* a, int s)
{
int i = (blockDim.x * blockIdx.x + threadIdx.x) * s;
a[i] = a[i] + 1;
}
template
void runTest(int deviceId, int nMB)
{
int blockSize = 256;
float ms;
T *d_a;
cudaEvent_t startEvent, stopEvent;
int n = nMB*1024*1024/sizeof(T);
// NB: d_a(33*nMB) for stride case
checkCuda( cudaMalloc(&d_a, n * 33 * sizeof(T)) );
checkCuda( cudaEventCreate(&startEvent) );
checkCuda( cudaEventCreate(&stopEvent) );
printf("Offset, Bandwidth (GB/s):n");
offset<<>>(d_a, 0); // warm up
for (int i = 0; i <= 32; i++) {
checkCuda( cudaMemset(d_a, 0.0, n * sizeof(T)) );
checkCuda( cudaEventRecord(startEvent,0) );
offset<<>>(d_a, i);
checkCuda( cudaEventRecord(stopEvent,0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
printf("%d, %fn", i, 2*nMB/ms);
}
printf("n");
printf("Stride, Bandwidth (GB/s):n");
stride<<>>(d_a, 1); // warm up
for (int i = 1; i <= 32; i++) {
checkCuda( cudaMemset(d_a, 0.0, n * sizeof(T)) );
checkCuda( cudaEventRecord(startEvent,0) );
stride<<>>(d_a, i);
checkCuda( cudaEventRecord(stopEvent,0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
printf("%d, %fn", i, 2*nMB/ms);
}
checkCuda( cudaEventDestroy(startEvent) );
checkCuda( cudaEventDestroy(stopEvent) );
cudaFree(d_a);
}
int main(int argc, char **argv)
{
int nMB = 4;
int deviceId = 0;
bool bFp64 = false;
for (int i = 1; i < argc; i++) {
if (!strncmp(argv[i], "dev=", 4))
deviceId = atoi((char*)(&argv[i][4]));
else if (!strcmp(argv[i], "fp64"))
bFp64 = true;
}
cudaDeviceProp prop;
checkCuda( cudaSetDevice(deviceId) )
;
checkCuda( cudaGetDeviceProperties(&prop, deviceId) );
printf("Device: %sn", prop.name);
printf("Transfer size (MB): %dn", nMB);
printf("%s Precisionn", bFp64 ? "Double" : "Single");
if (bFp64) runTest(deviceId, nMB);
else runTest(deviceId, nMB);
}
此代碼可以通過傳遞“ fp64 ”命令行選項以單精度(默認值)或雙精度運行偏移量內核和跨步內核。每個內核接受兩個參數,一個輸入數組和一個表示訪問數組元素的偏移量或步長的整數。內核在一系列偏移和跨距的循環中被稱為。
未對齊的數據訪問
下圖顯示了 Tesla C870 、 C1060 和 C2050 上的偏移內核的結果。
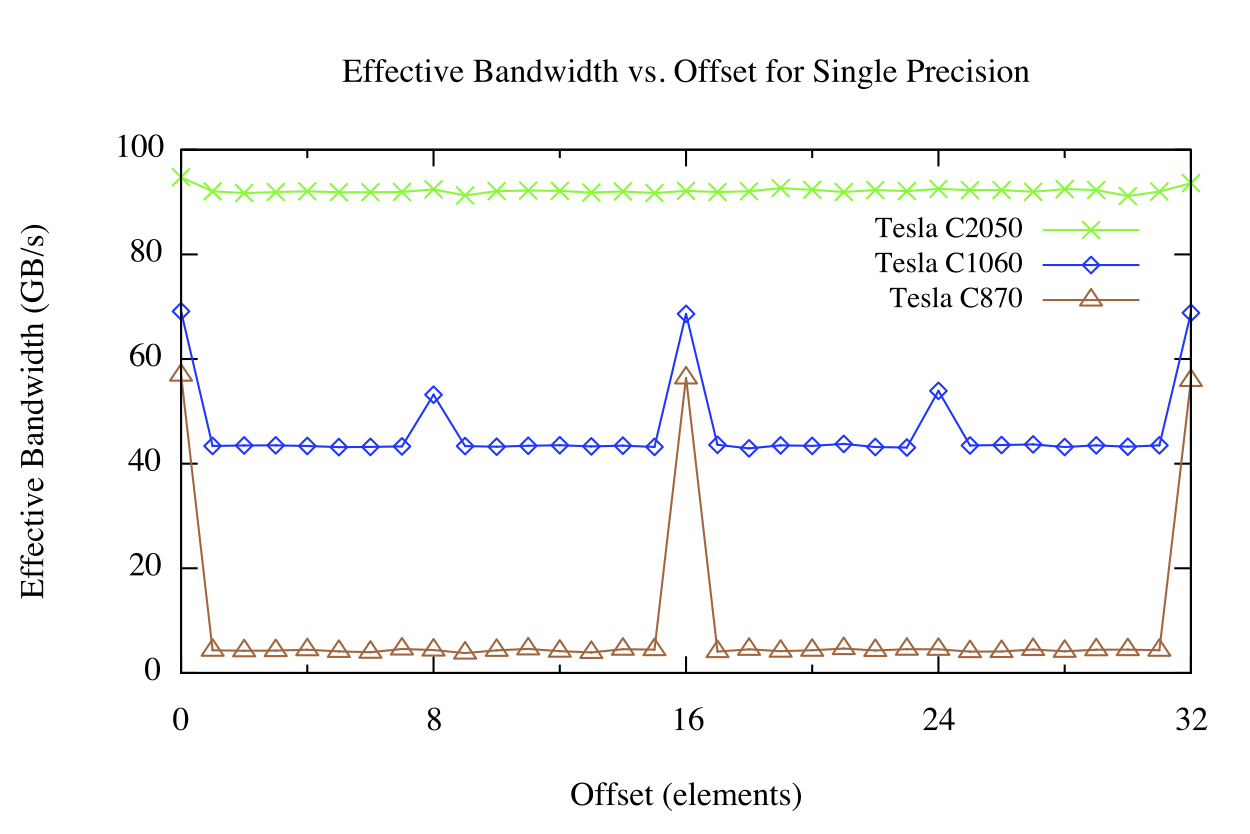
設備內存中分配的數組由 CUDA 驅動程序與 256 字節內存段對齊。該設備可以通過 32 字節、 64 字節或 128 字節的事務來訪問全局內存。對于 C870 或計算能力為 1 . 0 的任何其他設備,半線程的任何未對齊訪問(或半扭曲線程不按順序訪問內存的對齊訪問)將導致 16 個獨立的 32 字節事務。由于每個 32 字節事務只請求 4 個字節,因此可以預期有效帶寬將減少 8 倍,這與上圖(棕色線)中看到的偏移量(不是 16 個元素的倍數)大致相同,對應于線程的一半扭曲。
對于計算能力為 1 . 2 或 1 . 3 的 Tesla C1060 或其他設備,未對準訪問的問題較少。基本上,通過半個線程對連續數據的未對齊訪問在幾個“覆蓋”請求的數據的事務中提供服務。由于未請求的數據正在傳輸,以及不同的半翹曲所請求的數據有些重疊,因此相對于對齊的情況仍然存在性能損失,但是這種損失遠遠小于 C870 。
計算能力為 2 . 0 的設備,如 Tesla C250 ,在每個多處理器中都有一個 L1 緩存,其行大小為 128 字節。該設備將線程的訪問合并到盡可能少的緩存線中,從而導致對齊對跨線程順序內存訪問吞吐量的影響可以忽略不計。
快速內存訪問
步幅內核的結果如下圖所示。
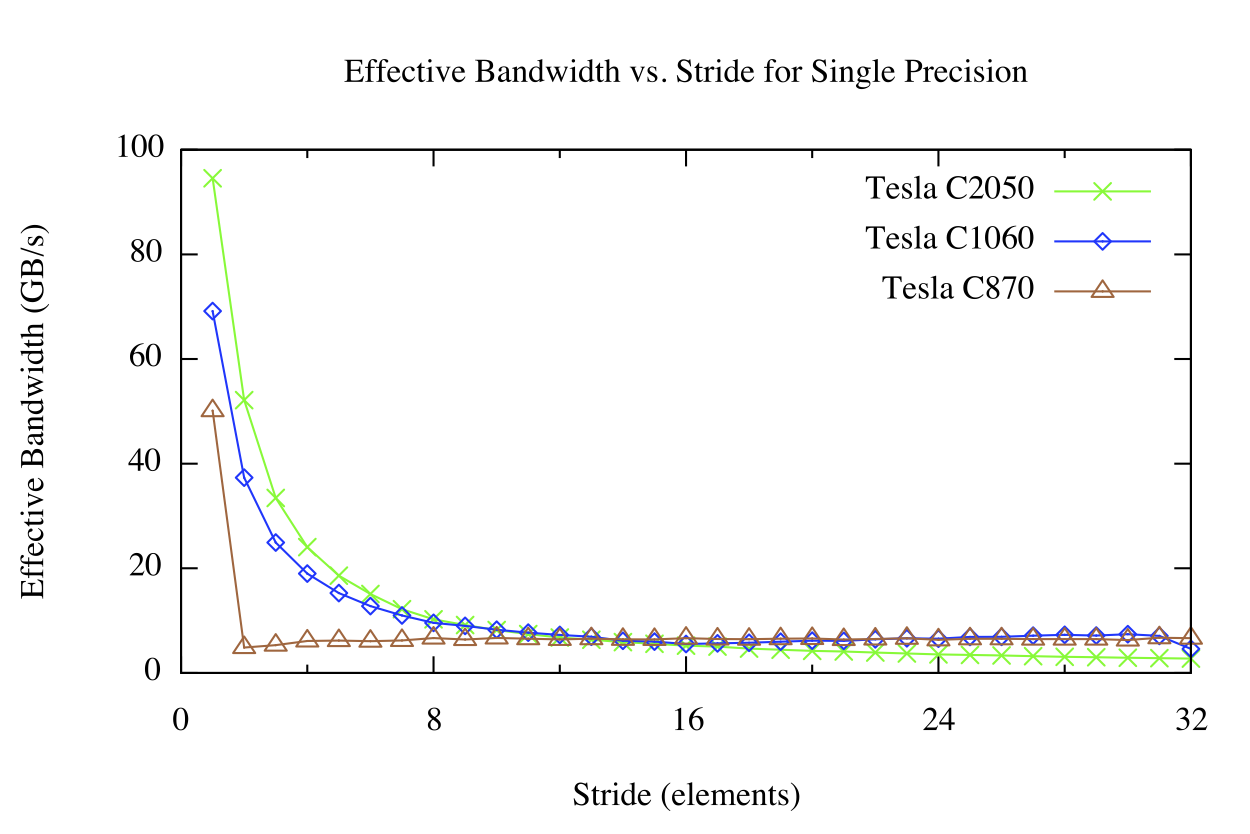
對于快速的全局內存訪問,我們有不同的看法。對于大步進,無論架構版本如何,有效帶寬都很差。這并不奇怪:當并發線程同時訪問物理內存中相距很遠的內存地址時,硬件就沒有機會合并這些訪問。從上圖中可以看出,在 Tesla C870 上,除 1 以外的任何步幅都會導致有效帶寬大幅降低。這是因為 compute capability 1 . 0 和 1 . 1 硬件需要跨線程進行線性、對齊的訪問以進行合并,因此我們在 offset 內核中看到了熟悉的 1 / 8 帶寬。 Compute capability 1 . 2 及更高版本的硬件可以將訪問合并為對齊的段( CC 1 . 2 / 1 . 3 上為 32 、 64 或 128 字節段,在 CC 2 . 0 及更高版本上為 128 字節緩存線),因此該硬件可以產生平滑的帶寬曲線。
當訪問多維數組時,線程通常需要索引數組的更高維,因此快速訪問是不可避免的。我們可以使用一種名為 共享內存 的 CUDA 內存來處理這些情況。共享內存是一個線程塊中所有線程共享的片上內存。共享內存的一個用途是將多維數組的 2D 塊以合并的方式從全局內存提取到共享內存中,然后讓連續的線程跨過共享內存塊。與全局內存不同,對共享內存的快速訪問沒有懲罰。我們將在下一篇文章中詳細介紹共享內存。
概括
在這篇文章中,我們討論了如何從 CUDA 內核代碼中有效地訪問全局內存的一些方面。設備上的全局內存訪問與主機上的數據訪問具有相同的性能特征,即數據局部性非常重要。在早期的 CUDA 硬件中,內存訪問對齊和跨線程的局部性一樣重要,但在最近的硬件上,對齊并不是什么大問題。另一方面,快速的內存訪問會損害性能,使用片上共享內存可以減輕這種影響。在 下一篇文章 中,我們將詳細探討共享內存,之后的文章中,我們將展示如何使用共享內存來避免在 矩陣轉置 過程中出現跨步全局內存訪問。
?