 在上一期的 C / C ++ 文章 中,我們討論了如何在主機和設備之間高效地傳輸數據。在這篇文章中,我們討論了如何將數據傳輸與主機上的計算、設備上的計算相重疊,在某些情況下,主機和設備之間的其他數據傳輸。實現數據傳輸和其他操作之間的重疊需要使用 CUDA 流,所以首先讓我們了解一下流。
在上一期的 C / C ++ 文章 中,我們討論了如何在主機和設備之間高效地傳輸數據。在這篇文章中,我們討論了如何將數據傳輸與主機上的計算、設備上的計算相重疊,在某些情況下,主機和設備之間的其他數據傳輸。實現數據傳輸和其他操作之間的重疊需要使用 CUDA 流,所以首先讓我們了解一下流。
CUDA 流
CUDA 中的 stream 是按照主機代碼發出的順序在設備上執行的操作序列。雖然流中的操作被保證按規定的順序執行,但是不同流中的操作可以被交錯,并且在可能的情況下,它們甚至可以并發運行。
默認流
CUDA 中的所有設備操作(內核和數據傳輸)都在一個流中運行。如果沒有指定流,則使用默認流(也稱為“空流”)。默認流與其他流不同,因為它是關于設備上操作的同步流:在所有先前發出的操作 在設備上的任何流中 完成之前,默認流中的任何操作都不會開始,并且默認流中的操作必須在任何其他操作(在設備上的任何流中)之前完成就要開始了。
請注意, 2015 年發布的 CUDA 7 引入了一個新的選項,即每個主機線程使用單獨的默認流,并將每個線程的默認流視為常規流(即它們不與其他流中的操作同步)。在文章 GPU 專業提示: CUDA 7 流簡化并發 中閱讀更多關于這種新行為的信息。
讓我們看一些使用默認流的簡單代碼示例,并從主機和設備的角度討論操作是如何進行的。
cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice); increment<<<1,N>>>(d_a) cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);
在上面的代碼中,從設備的角度來看,所有三個操作都被發布到同一個(默認)流中,并將按照它們發出的順序執行。
從主機的角度看,隱式數據傳輸是阻塞或同步傳輸,而內核啟動是異步的。由于第一行上的主機到設備的數據傳輸是同步的, CPU 線程在主機到設備的傳輸完成之前不會到達第二行的內核調用。一旦內核被發出, CPU 線程將移動到第三行,但由于設備端的執行順序,該行上的傳輸無法開始。
內核從主機的角度啟動的異步行為使得重疊的設備和主機計算非常簡單。我們可以修改代碼以添加一些獨立的 CPU 計算,如下所示。
cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice); increment<<<1,N>>>(d_a) myCpuFunction(b) cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);
在上面的代碼中,一旦 increment() 內核在設備上啟動, CPU 線程就執行 myCpuFunction() ,它在 CPU 上的執行與在 GPU 上的內核執行重疊。無論是主機功能還是設備內核先完成,都不會影響后續的設備到主機的傳輸,只有在內核完成后才會開始,從設備的角度來看,上一個例子沒有什么變化,設備完全不知道 myCpuFunction() 。
非默認流
在下面的代碼中, CUDA C / C ++的非默認流被聲明、創建和銷毀。
cudaStream_t stream1; cudaError_t result; result = cudaStreamCreate(&stream1) result = cudaStreamDestroy(stream1)
為了向非默認流發出數據傳輸,我們使用了 cudaMemcpyAsync() 函數,它類似于前一篇文章中討論的 cudaMemcpy() 函數,但將流標識符作為第五個參數。
result = cudaMemcpyAsync(d_a, a, N, cudaMemcpyHostToDevice, stream1)
cudaMemcpyAsync() 在主機上是非阻塞的,因此在發出傳輸之后,控制權立即返回到主機線程。此例程有 cudaMemcpy2DAsync() 和 cudaMemcpy3DAsync() 變體,它們可以在指定的流中異步傳輸 2D 和 3D 數組部分。
為了向非默認流發出內核,我們將流標識符指定為第四個執行配置參數(第三個執行配置參數分配共享設備內存,我們將在后面討論;現在使用 0 )。
increment<<<1,N,0,stream1>>>(d_a)
與流同步
由于非默認流中的所有操作相對于宿主代碼都是非阻塞的,因此您將遇到需要將宿主代碼與流中的操作同步的情況。“重錘”的方法是使用 cudaDeviceSynchronize() ,它會阻止主機代碼,直到之前在設備上發出的所有操作都完成為止。在大多數情況下,這是一種過度殺戮,并且會由于整個設備和主機線程的暫停而影響性能。
CUDA 流 API 有多種不太嚴格的同步主機與流的方法。函數 cudaStreamSynchronize(stream) 可用于阻止主機線程,直到指定流中以前發出的所有操作都已完成。函數 cudaStreamQuery(stream) 測試向指定流發出的所有操作是否已完成,而不阻止主機執行。函數 cudaEventSynchronize(event) 和 cudaEventQuery(event) 的行為與它們的流對應項相似,只是它們的結果基于是否記錄了指定的事件,而不是基于指定的流是否空閑。您還可以使用 cudaStreamWaitEvent ( event )在單個流中同步特定事件的操作(即使事件記錄在不同的流中,或者記錄在不同的設備上)。
重疊的內核執行和數據傳輸
前面我們演示了如何將默認流中的內核執行與主機上的代碼執行重疊。但我們在這篇文章中的主要目標是向您展示如何將內核執行與數據傳輸重疊。要做到這一點有幾個要求。
- 設備必須能夠“并發復制和執行”。這可以從
cudaDeviceProp結構的deviceOverlap字段或從 CUDA SDK / Toolkit 附帶的deviceQuery示例的輸出中進行查詢。幾乎所有具有計算能力 1 . 1 及更高版本的設備都具有此功能。 - 要重疊的內核執行和數據傳輸必須同時發生在 different 、 non-default 流中。
- 數據傳輸所涉及的主機內存必須是 pinned 內存。
因此,讓我們從上面修改我們的簡單主機代碼,以使用多個流,看看是否可以實現任何重疊。這個例子的完整代碼是 在 Github 上提供 。在修改后的代碼中,我們將大小為 N 的數組分解為 streamSize 元素的塊。由于內核對所有元素都是獨立操作的,因此每個塊都可以獨立處理。使用的(非默認)流數為 nStreams=N/streamSize 。有多種方法可以實現數據的域分解和處理;一種方法是循環使用數組中每個塊的所有操作,如本示例代碼所示。
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&d_a[offset], &a[offset], streamBytes, cudaMemcpyHostToDevice, stream[i]);
kernel<<<streamSize/blockSize, blockSize, 0, stream[i]>>>(d_a, offset);
cudaMemcpyAsync(&a[offset], &d_a[offset], streamBytes, cudaMemcpyDeviceToHost, stream[i]);
}
另一種方法是將類似的操作批處理在一起,首先發出所有主機到設備的傳輸,然后是所有的內核啟動,然后是所有設備到主機的傳輸,如下面的代碼所示。
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&d_a[offset], &a[offset],
streamBytes, cudaMemcpyHostToDevice, cudaMemcpyHostToDevice, stream[i]);
}
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
kernel<<<streamSize/blockSize, blockSize, 0, stream[i]>>>(d_a, offset);
}
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&a[offset], &d_a[offset],
streamBytes, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToHost, stream[i]);
}
上面顯示的兩個異步方法都會產生正確的結果,并且在這兩種情況下,依賴操作都會按照它們需要執行的順序發布到同一個流。但根據所使用的 GPU 的特定代數,這兩種方法的性能截然不同。在 Tesla C1060 (計算能力 1 . 3 )上運行測試代碼(來自 Github )給出以下結果。
Device : Tesla C1060 Time for sequential transfer and execute (ms ): 12.92381 max error : 2.3841858E -07 Time for asynchronous V1 transfer and execute (ms ): 13.63690 max error : 2.3841858E -07 Time for asynchronous V2 transfer and execute (ms ): 8.84588 max error : 2.3841858E -07
在 Tesla C2050 (計算能力 2 . 0 )上,我們得到以下結果。
Device : Tesla C2050 Time for sequential transfer and execute (ms ): 9.984512 max error : 1.1920929e -07 Time for asynchronous V1 transfer and execute (ms ): 5.735584 max error : 1.1920929e -07 Time for asynchronous V2 transfer and execute (ms ): 7.597984 max error : 1.1920929e -07
這里第一次報告的是使用阻塞傳輸的順序傳輸和內核執行,我們將其作為異步加速比較的基線。為什么這兩種異步策略在不同的體系結構上表現不同?要破解這些結果,我們需要更多地了解 CUDA 設備如何調度和執行任務。 CUDA 設備包含用于各種任務的引擎,這些引擎在發出操作時對操作進行排隊。不同引擎中的任務之間的依賴關系得到維護,但是在任何引擎中,所有外部依賴關系都會丟失;每個引擎隊列中的任務將按照它們的發出順序執行。 C1060 有一個拷貝引擎和一個內核引擎。在 C1060 上執行示例代碼的時間線如下圖所示。
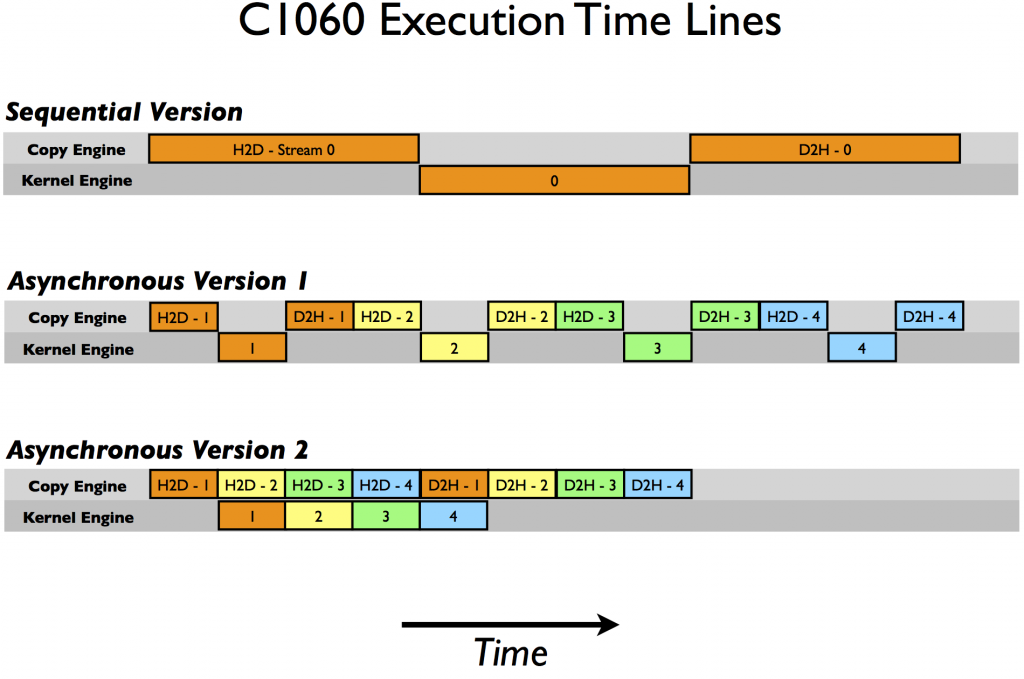
在這個示意圖中,我們假設主機到設備傳輸、內核執行和設備到主機傳輸所需的時間大致相同(選擇內核代碼是為了實現這一點)。正如順序內核所期望的那樣,任何操作中都沒有重疊。對于我們代碼的第一個異步版本,復制引擎中的執行順序是: H2D stream ( 1 )、 D2H stream ( 1 )、 H2D stream ( 2 )、 D2H stream ( 2 )等等。這就是為什么我們在 C1060 上使用第一個異步版本時看不到任何加速:任務是按照排除內核執行和數據傳輸重疊的順序被發送到復制引擎的。然而,對于版本 2 ,在所有主機到設備的傳輸在任何設備到主機的傳輸之前發出,重疊是可能的,如較低的執行時間所示。根據我們的示意圖,我們期望異步版本 2 的執行時間是順序版本的 8 / 12 ,或者 8 . 7ms ,這在前面給出的計時結果中得到了確認。
在 C2050 上,兩個功能相互作用導致與 C1060 不同的行為。 C2050 有兩個復制引擎,一個用于主機到設備的傳輸,另一個用于設備到主機的傳輸,以及一個內核引擎。下圖說明了我們的示例在 C2050 上的執行。
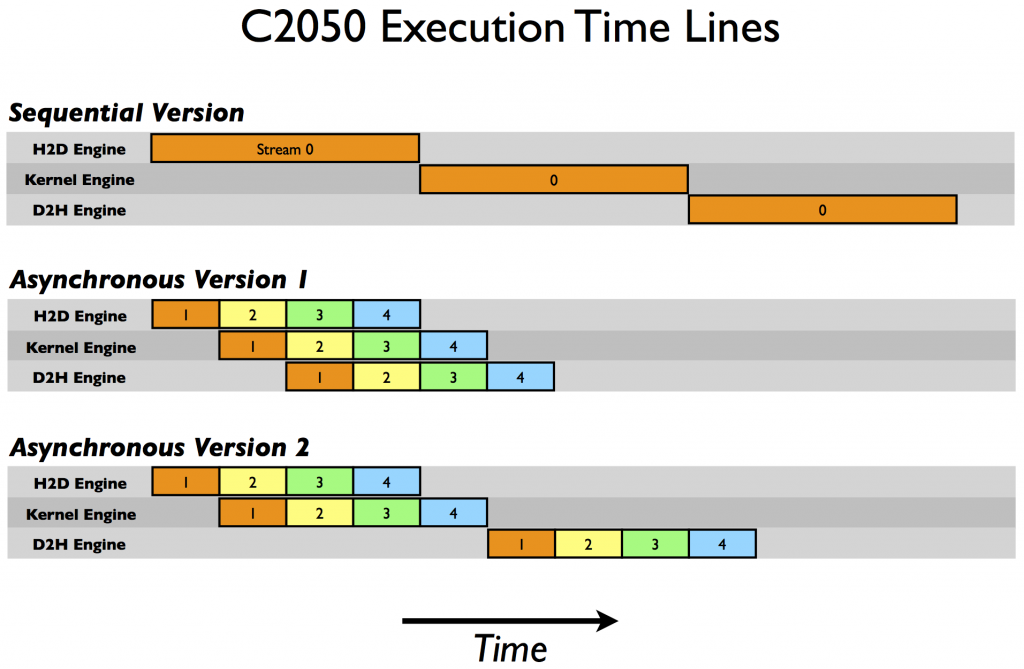
有兩個復制引擎解釋了為什么異步版本 1 在 C2050 上實現了很好的加速:流[i] 不阻止流中數據的主機到設備傳輸 [i + 1]中數據的主機到設備的傳輸,因為 C2050 上的每個復制方向都有一個單獨的引擎。示意圖預測了執行情況相對于順序版本,時間被縮短一半,這大致就是我們的計時結果顯示的。
但是在 C2050 上的異步版本 2 中觀察到的性能下降呢?這與 C2050 并發運行多個內核的能力有關。當多個內核在不同(非默認)流中背靠背地發出時,調度程序嘗試啟用這些內核的并發執行,結果會延遲通常在每個內核完成后出現的信號(這負責啟動設備到主機的傳輸),直到所有內核完成。因此,雖然在第二個版本的異步代碼中,主機到設備的傳輸和內核的執行之間有重疊,但是內核執行和設備到主機的傳輸之間沒有重疊。示意圖預測異步版本 2 的總時間是順序版本的 9 / 12 ,即 7 . 5 毫秒,這一點由我們的計時結果證實。
CUDA Fortran 異步數據傳輸 中提供了關于本文中使用的示例的更詳細的描述,好消息是對于具有計算能力 3 . 5 ( K20 系列)的設備, Hyper-Q 特性消除了定制發布順序的需要,因此上述任何一種方法都可以工作。我們將在以后的文章中討論使用開普勒特性,但是現在,這里是在 Tesla K20c GPU 上運行示例代碼的結果。如您所見,這兩個異步方法在同步代碼上實現了相同的加速。
Device : Tesla K20c Time for sequential transfer and execute (ms): 7.101760 max error : 1.1920929e -07 Time for asynchronous V1 transfer and execute (ms): 3.974144 max error : 1.1920929e -07 Time for asynchronous V2 transfer and execute (ms): 3.967616 max error : 1.1920929e -07
概括
這篇文章和 上一個 討論了如何優化主機和設備之間的數據傳輸。上一篇文章集中討論了如何最小化執行這種傳輸的時間,這篇文章介紹了流,以及如何使用流通過并發執行副本和內核來屏蔽數據傳輸時間。
在一篇關于流的文章中,我應該提到,雖然使用默認流可以方便地開發代碼,但同步代碼更簡單,最終您的代碼應該使用非默認流或 CUDA 7 對每線程默認流的支持(讀 GPU 專業提示: CUDA 7 流簡化并發 )。這在編寫庫時尤其重要。如果庫中的代碼使用默認流,那么最終用戶就沒有機會將數據傳輸與庫內核執行重疊。
現在您已經知道如何在主機和設備之間高效地移動數據,所以我們將研究如何在 下一篇文章 中的內核中高效地訪問數據。
?