緩存與數組、符號或字符串一樣是計算的基礎。整個堆棧中的各種緩存層在您的 CPU 上掛起時保存來自內存的指令。它們使您能夠在離開時快速重新加載頁面,而無需重新驗證。它們還顯著降低了應用程序的工作負載,并通過不重復運行相同的查詢來提高吞吐量。
NVIDIA Triton Inference Server 對于緩存來說,是一個調整為以張量推理的形式回答問題的系統。運行推理是一項計算成本相對較高的任務,它經常調用相同的推理來重復運行。這自然有助于使用緩存模式。
NVIDIA Triton 團隊最近實施了 Triton response cache,并使用了 Triton local cache 庫。他們還建立了 cache API,以使該緩存模式在 Triton 中可擴展。然后,Redis 團隊利用 API 構建了 NVIDIA Triton 的 Redis cache。
在這篇文章中,Redis 團隊探討了 Redis 的實現 API 的 Triton 緩存。我們將探討如何開始使用 Redis 來增強 NVIDIA Triton 實例的一些最佳實踐。
什么是 Redis?
Redis 是 REmote DIctionary Server 的縮寫。它是一個作為鍵值數據結構存儲操作的 NoSQL 數據庫。Redis 是內存優先的,這意味著 Redis 中的整個數據集都存儲在內存中,并可以根據配置持久化到磁盤。因為 Redis 是一個完全保存在內存中的鍵值數據庫,所以速度非常快。執行時間以微秒為單位,吞吐量以每秒數萬次操作為單位。
Redis 卓越的速度和典型的訪問模式使其成為緩存的理想選擇。Redis 是緩存的代名詞,因此是各種開發人員社區中大多數主要應用程序框架的內置分布式緩存之一。
什么是本地緩存?
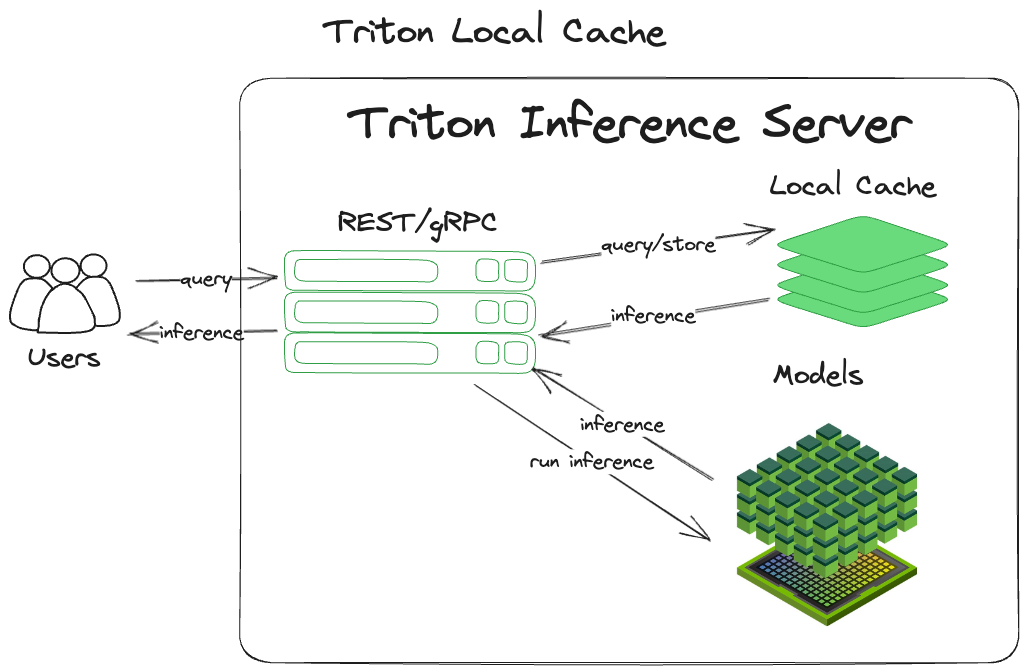
本地緩存是最常見的緩存模式(緩存除外)的內存派生。它簡單高效,易于掌握和實施。 NVIDIA Triton 收到查詢后:
- 計算輸入查詢的哈希,包括張量和一些元數據。這就成為了推理的關鍵。
- 檢查該鍵處該張量的先前推斷結果。
- 返回找到的任何結果。
- 如果未找到結果,則執行推理。
- 使用用于存儲的鍵將推理緩存在內存中。
- 返回推理。
“本地”意味著它保持在進程的本地,并將緩存存儲在系統的主內存中。圖 1 顯示了該模式的實現。
本地緩存的好處
使用這種模式自然會帶來各種好處。因為查詢是緩存的,所以可以很容易地再次檢索它們,而無需通過模型重新運行張量。因為所有東西都在進程內存中本地維護,所以不需要離開進程或機器來檢索緩存的數據。這兩者協同作用可以顯著提高吞吐量,同時降低計算成本。
本地緩存的缺點
這種技術確實有缺點。因為緩存直接綁定到進程內存中,所以每次 Triton 進程重新啟動時,它都會從平方開始(通常稱為冷啟動)。當緩存預熱時,您將看不到緩存帶來的好處。此外,由于緩存被進程鎖定, Triton 的其他實例將無法共享緩存,導致每個節點的緩存重復。
另一個主要缺點是資源爭用。由于本地緩存與進程綁定,因此它僅限于 Triton 運行的系統的資源。這意味著不可能水平擴展分配給緩存的資源(將緩存分布在多臺機器上),這限制了將本地緩存擴展到垂直擴展的選項。這使得運行 Triton 的服務器變得更大。
Redis 分布式緩存的好處
與本地緩存不同,分布式緩存利用外部服務(如 Redis)從本地服務器分發緩存。這為 NVIDIA Triton 緩存 API 帶來了幾個優勢:
- Redis 不與 Triton 綁定到同一臺機器的可用系統資源,也不與單個機器綁定。
- Redis 與 Triton 的進程生命周期解耦,使多個 Triton instance 能夠利用同一個緩存。
- Redis 速度極快(執行時間通常在幾毫秒以下)。
- 與 Triton 本地緩存相比,Redis 是一種更加專業化、功能豐富且可調的緩存服務。
- Redis 提供了對久經考驗的高可用性、水平擴展和緩存清除功能的即時訪問。
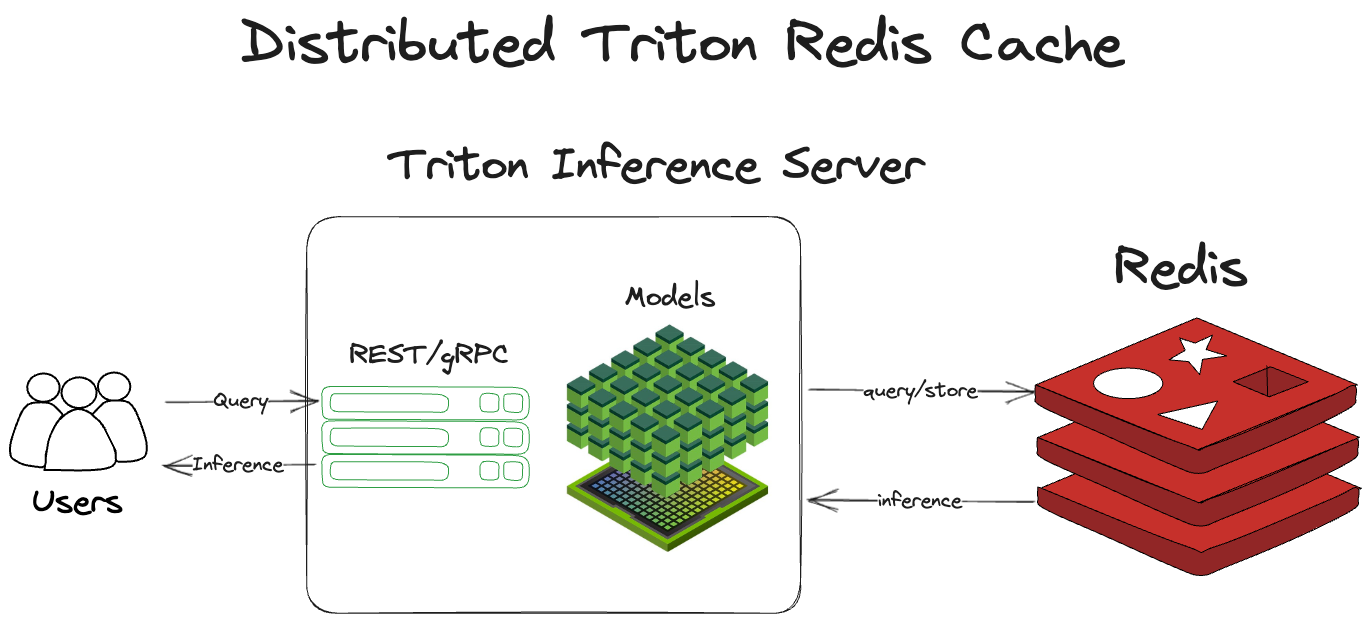
Redis 的分布式緩存與本地緩存的工作方式大致相同。它沒有停留在同一個進程中,而是跨出 Triton 服務器進程到 Redis 來檢查緩存并存儲推斷。 NVIDIA Triton 收到查詢后:
- 計算輸入查詢的哈希,包括張量和一些元數據。這就成為了推理的關鍵。
- 檢查 Redis 是否有以前的運行推斷。
- 返回該推理(如果存在)。
- 如果推理不存在,則通過 Triton 運行張量。
- 將推理存儲在 Redis 中。
- 返回推理。
在體系結構上,如圖 2 所示。
分布式緩存設置和配置
要設置分布式 Redis 緩存,需要兩個頂級步驟:
- 部署您的 Redis 實例。
- 將 NVIDIA Triton 配置為指向 Redis 實例。
Triton 將幫助你處理剩下的事情。如果想了解更多關于 Redis 的信息,請參閱 redis.io,docs.redis.com 和 Redis University。
要將 Triton 配置為指向 Redis 實例,請使用 — 緩存配置選項。在模型配置中,為模型啟用響應緩存,具有{{response_cache{enable:true}}。
tritonserver --cache-config redis,host=localhost --cache-config redis,port=6379
Redis 緩存要求您至少配置 Redis 實例的主機和端口。要查看所有配置選項,請參閱 Triton Redis Cache GitHub。
Redis 的最佳實踐
Redis 重量輕,易于使用,速度極快。即使 Redis 占地面積小且簡單,您也可以在 Redis 中及其周圍進行大量配置,以根據您的用例對其進行優化。本節重點介紹使用和配置 Redis 的最佳實踐。
最小化往返時間
在進程內內存緩存上使用像 Redis 這樣的外部服務的唯一真正缺點是,對 Redis 的查詢至少必須跨進程。它們通常也需要跨越服務器邊界。
因此,最小化往返時間(RTT)對于優化 Redis 作為緩存的使用至關重要。如何最大限度地減少 RTT 的主題太復雜了,這篇文章無法深入探討。幾個關鍵提示:維護 Redis 服務器與 Triton 服務器的位置,并使它們在物理上彼此靠近。如果它們在數據中心,請嘗試將它們放在同一機架或可用區域。
可擴展性和高可用性
Redis 集群使您能夠在多個分片上進行 Redis 實例的水平擴展。集群包括復制 Redis 實例的功能。如果主分片出現故障,可以升級副本以實現高可用性。
最大內存和逐出
如果 Redis 的內存沒有上限,它將使用操作系統釋放給它的所有可用內存,這是由maxmemory 這個在 redis.conf 中的配置鍵控制的。但是,如果設置了 maxmemory,那么當 Redis 的內存用完時會發生什么呢?正如您所期望的,它會默認停止接受對 Redis 的新寫入。
但是,您也可以設置驅逐政策。驅逐政策使用一些基本的情報來決定哪些密鑰可能是從 Redis 中驅逐出去的好候選者。允許 Redis 收回對存儲不再有意義的密鑰,使其能夠在內存充滿時繼續接受新的寫入,而不會中斷。
有關不同 Redis 驅逐策略的完整解釋,請參閱 Redis 手冊中的 key eviction 。
耐久性和持久性
Redis 是內存優先,意味著一切都存儲在內存中。如果你不配置持久性,Redis 進程就會死亡,它基本上會返回到冷啟動狀態。(在您從緩存中獲得好處之前,緩存需要“w Arm 向上”。)
有兩種選項可以持久化 Redis:一種是在 .rdb 文件中定期拍攝 Redis 狀態的快照,另一種是在僅追加文件中記錄所有寫入命令。有關這些方法的完整說明,請參閱 Redis 手冊中的持久化部分。
速度比較
言歸正傳,本節將探討 Triton(無 Redis)和 Triton(有 Redis)之間性能的全面差異。為了簡潔起見,我們使用了 perf_analyzer,這是 Triton 團隊為測量 Triton 性能而構建的工具。我們測試了兩個獨立的模型,DenseNet 和 Simple。
我們在谷歌云平臺(GCP)n1-標準-4 虛擬機上運行了 Docker 服務器 23.06 版,該虛擬機帶有一個 NVIDIA T4 GPU 。我們還在 GCP n2-standard-4 虛擬機上運行了一個普通的開源 Redis 實例。最后,我們在 GCP e2 介質 VM 上運行了 Triton 中的 Triton 客戶端映像。
我們對 DenseNet 和 Simple 型號進行了性能分析,每種緩存配置運行 10 次,包括無緩存,使用 Redis 作為緩存,以及使用本地緩存。然后我們對這些運行結果取平均值。
需要注意的是,這些運行假定緩存命中率為 100%。因此,測量是 Triton 在過去遇到入口時和沒有遇到入口時的性能之間的差異。
我們對 DenseNet 模型使用了以下命令:
perf_analyzer -m densenet_onnx -u triton-server:8000
我們對 Simple 模型使用了以下命令:
perf_analyzer -m simple -u triton-server:8000
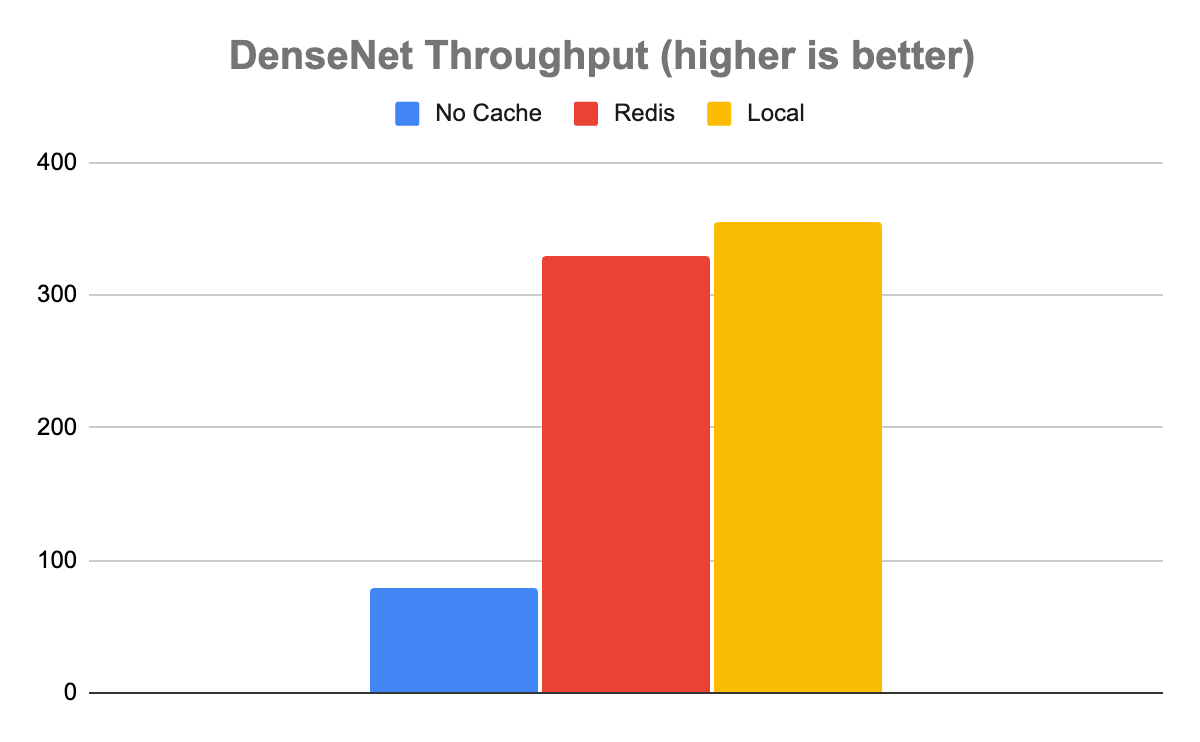
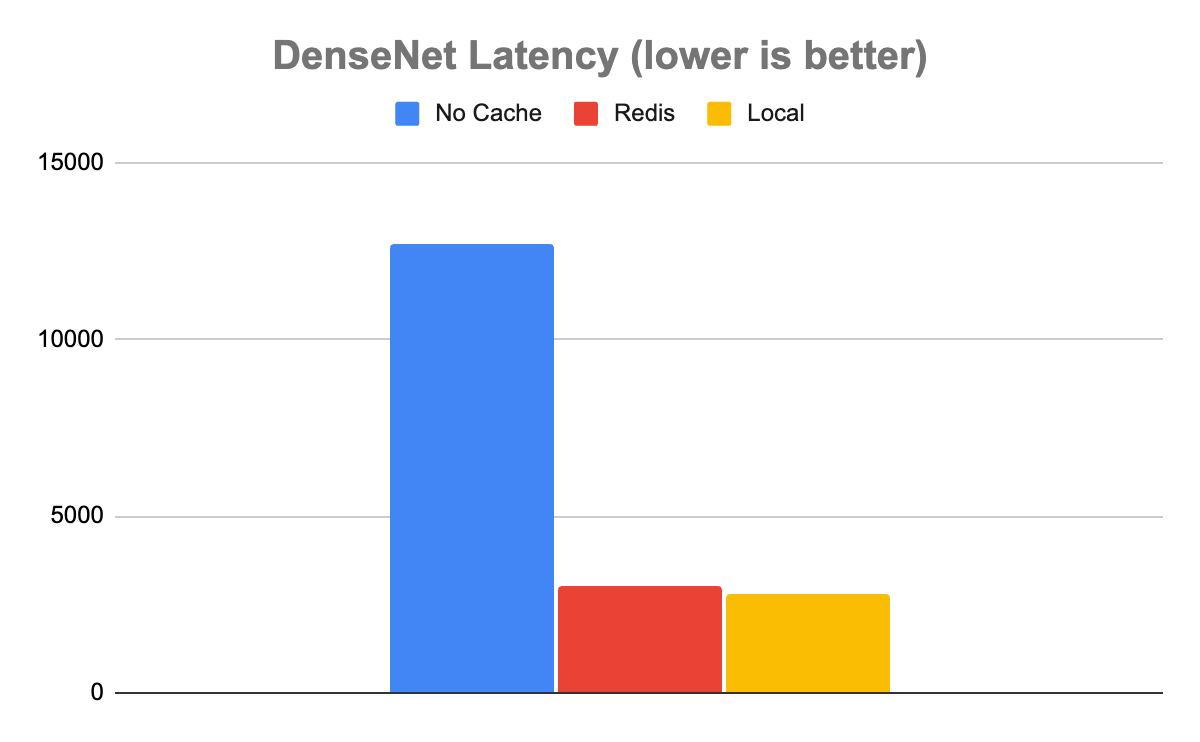
在 DenseNet 模型的情況下,結果表明,使用任一緩存都比不使用緩存要好得多。在沒有緩存的情況下, Triton 每秒能夠處理 80 個推斷(推斷/秒),平均延遲為 12680μs。使用 Redis,它的速度大約快了 4 倍,每秒處理 329 個推理,平均延遲為 3030μs。
有趣的是,雖然本地緩存比 Redis 快一些,正如你所期望的那樣,但它只是稍微快一些。本地緩存的吞吐量為 355 推理/秒,延遲為 2817μs,僅快約 8%。在這種情況下,很明顯,本地緩存與 Redis 中緩存的速度權衡是微不足道的。考慮到使用分布式緩存與本地緩存相比所帶來的所有額外好處,?在處理這些類型的數據時,幾乎可以肯定的是分布式的。
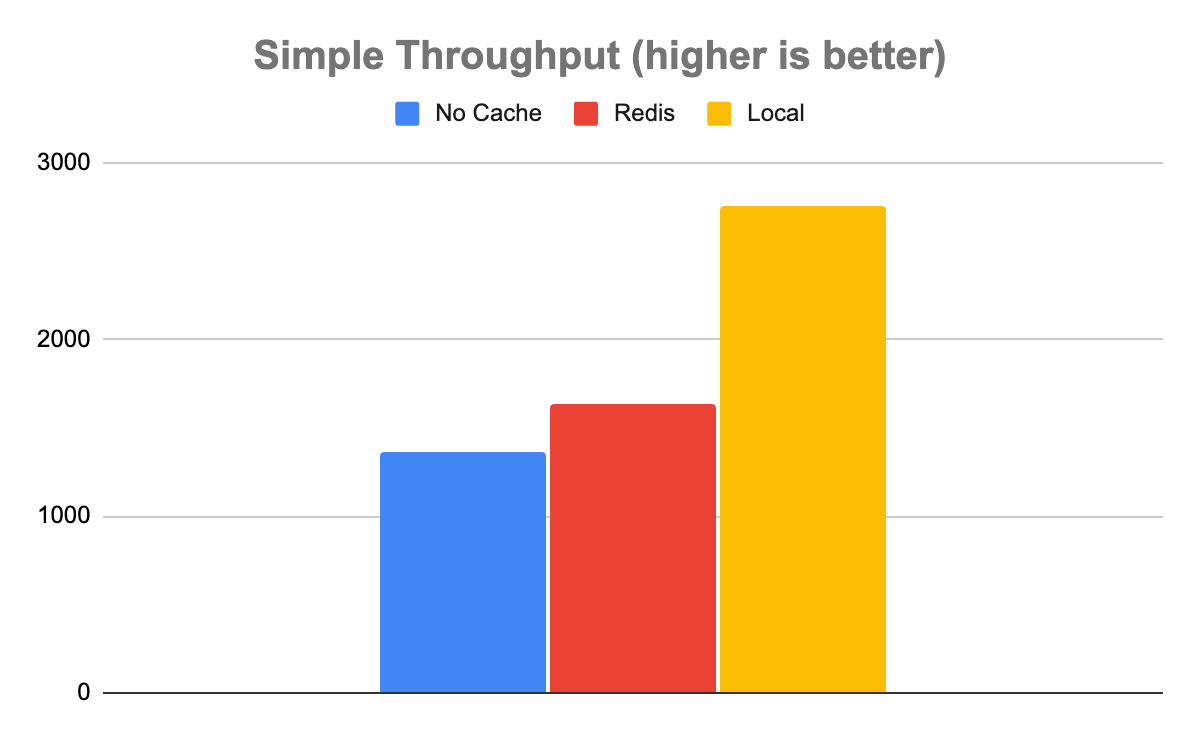
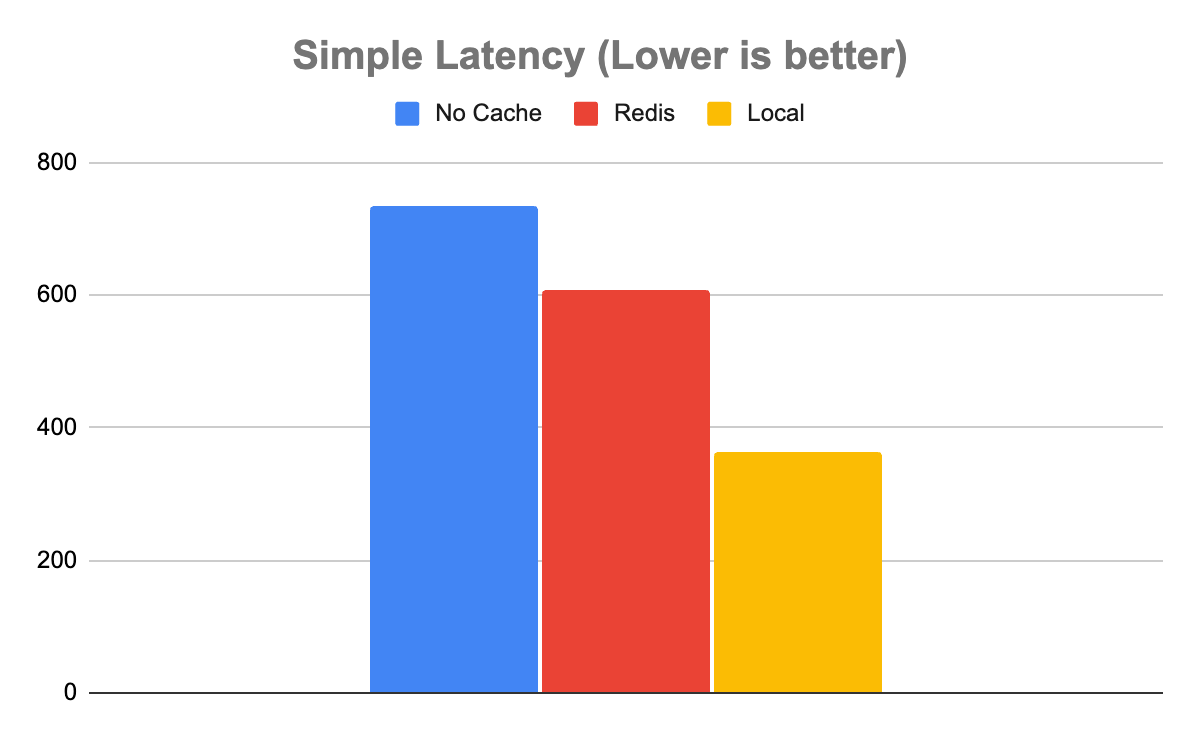
簡單模型告訴了一個稍微復雜一些的故事。在簡單模型的情況下,不使用任何緩存可以實現 1358 推理/秒的吞吐量和 735μs 的延遲。Redis 速度更快,吞吐量為 1639 推理/秒,延遲為 608μs。Local 比 Redis 更快,吞吐量為 2753 推理/秒,延遲為 363μs。
這是一個需要注意的重要案例,因為并非所有用途都是平等的。在這種情況下,記錄系統可能足夠快,不值得為 Redis 的吞吐量增加 20%的額外系統。即使在本地緩存的情況下延遲減半,也可能不值得進行資源爭用,這取決于緩存命中率和可用系統資源等其他因素。
管理權衡的最佳實踐
如實驗所示,模型、預期輸入和預期輸出之間的差異對于評估什么(如果有的話)緩存適合您的 Triton 實例至關重要。
緩存是否增加值在很大程度上取決于查詢的計算成本。查詢的計算成本越高,每個查詢從緩存中獲得的好處就越多。
局部與 Redis 的相對性能在很大程度上取決于模型的輸出張量有多大。輸出張量越大,傳輸成本對 Redis 允許的吞吐量的影響就越大。
當然,輸出張量越大,在空間用完并開始與 Triton 爭奪資源之前,您能夠存儲在本地緩存中的輸出張量就越少。從根本上講,在評估哪種緩存解決方案最適合 Triton 的部署時,需要平衡這些因素。
| 好處 | 缺點 |
| 1.橫向可擴展 2.有效的無限制內存訪問 3.實現高可用性和災難恢復 4.消除資源爭用 5.最大限度地減少冷啟動 |
分布式 Redis 緩存需要調用 通過網絡。當然,你可以 預計吞吐量會有所降低 與本地高速緩存相比具有更高的延遲。 |
總結
分布式緩存是開發人員用來提高系統性能的一個老技巧,同時實現水平可擴展性和關注點分離。隨著為 Triton 推理服務器引入 Redis 緩存,您現在可以利用這項技術大大提高 Triton instance 的性能和效率,同時管理更重的工作負載,并使多個 Triton -instance 共享在同一個緩存中。從根本上講,通過將緩存卸載到 Redis, Triton 可以將其資源集中在其基本角色上——運行推斷。
開始使用 Triton Redis Cache 和 NVIDIA Triton Inference Server。有關設置和管理 Redis 實例的更多信息,請參閱 redis.io 和 docs.redis.com。
?