人工智能模型無處不在,形式包括聊天機器人、分類和摘要工具、用于分割和檢測的圖像模型、推薦模型等。人工智能機器學習( ML )模型有助于實現許多業務流程的自動化,從數據中生成見解,并提供新的體驗。
Python 是 AI/ML 開發中最受歡迎的語言之一。本文將教您如何使用 NVIDIA Triton Inference Server,并利用新的 PyTriton 接口。
更具體地說,您將學習如何在 Python 開發環境中使用生產類工具對人工智能模型進行原型化和測試推理,以及如何使用 PyTriton 接口進行生產。與 FastAPI 或 Flask 等通用 web 框架相比,您還將了解使用 PyTriton 的優勢。這篇文章包括幾個代碼示例,說明如何激活高性能的批處理、預處理和多節點推理;并實施在線學習。
什么是 PyTriton ?
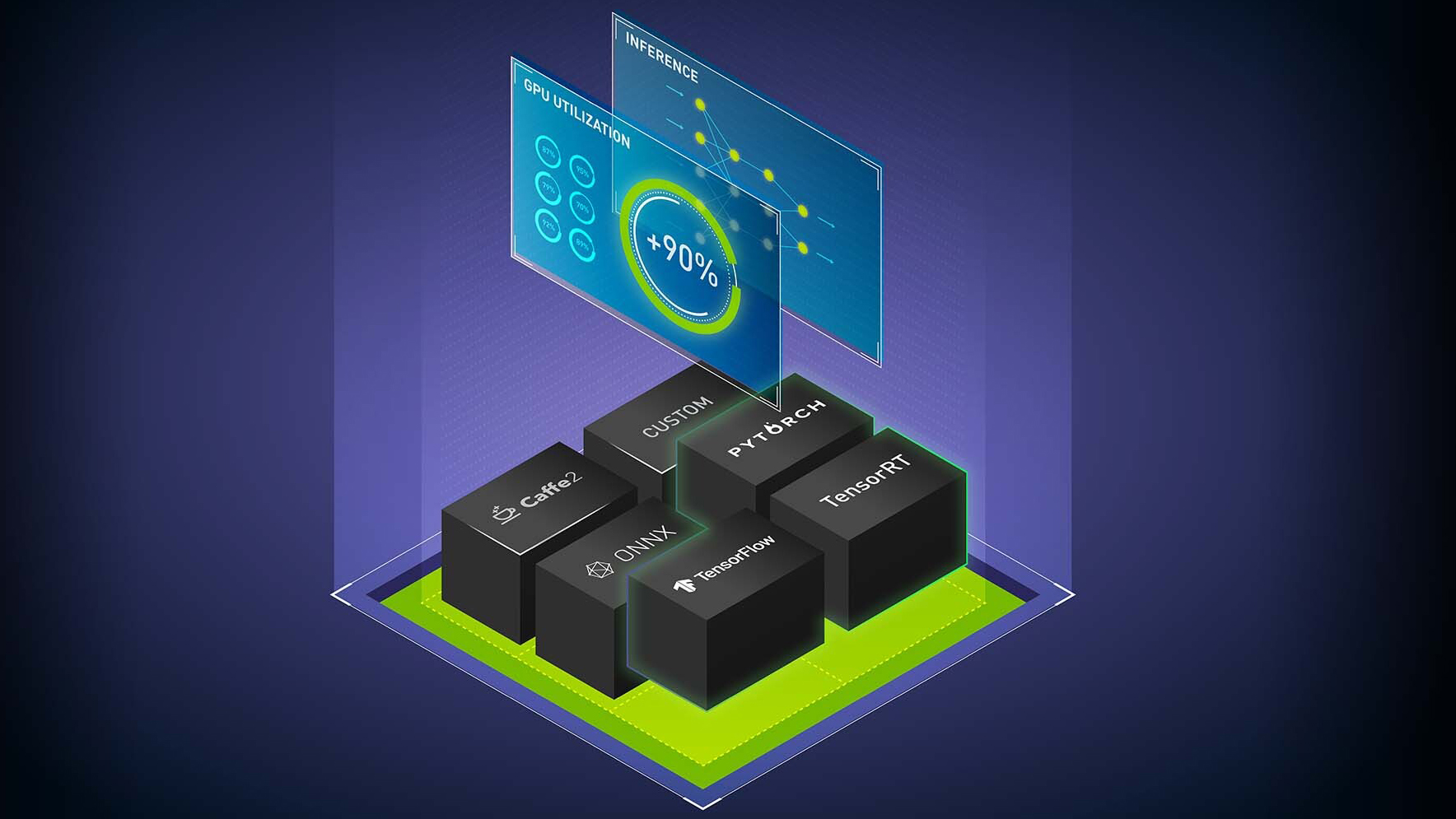
PyTriton 是一個簡單的接口,可讓 Python 開發人員使用 Triton 推理服務器為 Python 代碼中的人工智能模型、簡單處理功能或整個推理管道提供服務。Triton 推理服務器是一款開源的多框架推理服務軟件,在 CPU 和 GPU 上具有較高的性能。
PyTriton 可以實現快速原型設計和測試 ML 模型,同時實現高 GPU 利用率的性能和效率。只需一行代碼,就可以調出 Triton 推理服務器,提供 動態批處理、并發模型執行以及從 GPU 代碼中支持 GPU 和 Python 的優勢。
PyTriton 消除了建立模型存儲庫和將模型從開發環境移植到生產環境的需要。現有的推理管道代碼也可以在不進行修改的情況下使用。這對于較新類型的框架(如 JAX )或復雜的管道(它們是 Triton 推理服務器中沒有專用后端的應用程序代碼的一部分)尤其有用。
Flask 的簡單性
Flask 和FastAPI 是通用的 Python Web 框架,用于部署各種各樣的 Python 應用程序。由于它們的簡單性和廣泛采用,許多開發人員在生產中使用它們來部署和運行人工智能模型。然而,這種方法存在顯著的缺點,包括:
- 通用網絡服務器缺乏對人工智能推理功能的支持。沒有現成的支持來利用像 GPU 這樣的加速器,或者打開動態批處理或多節點推理。
- 用戶需要構建邏輯來滿足特定用例的需求,如音頻/視頻流輸入、有狀態處理或預處理輸入數據以適應模型。
- 關于計算和內存利用率或推理延遲的指標不容易用于監控應用程序的性能和規模。
Triton Inference Server包含對上述功能以及更多功能的內置支持。PyTriton 提供了 Flask 的簡單性和 Python 中 Triton 的示例部署。HuggingFace 文本分類管道使用 PyTriton 如下所示:
import logging
import numpy as np
from transformers import BertTokenizer, FlaxBertModel # pytype: disable=import-error
from pytriton.decorators import batch
from pytriton.model_config import ModelConfig, Tensor
from pytriton.triton import Triton
logger = logging.getLogger("examples.huggingface_bert_jax.server")
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(name)s: %(message)s")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = FlaxBertModel.from_pretrained("bert-base-uncased")
@batch
def _infer_fn(**inputs: np.ndarray):
(sequence_batch,) = inputs.values()
# need to convert dtype=object to bytes first
# end decode unicode bytes
sequence_batch = np.char.decode(sequence_batch.astype("bytes"), "utf-8")
last_hidden_states = []
for sequence_item in sequence_batch:
tokenized_sequence = tokenizer(sequence_item.item(), return_tensors="jax")
results = model(**tokenized_sequence)
last_hidden_states.append(results.last_hidden_state)
last_hidden_states = np.array(last_hidden_states, dtype=np.float32)
return [last_hidden_states]
with Triton() as triton:
logger.info("Loading BERT model.")
triton.bind(
model_name="BERT",
infer_func=_infer_fn,
inputs=[
Tensor(name="sequence", dtype=np.bytes_, shape=(1,)),
],
outputs=[
Tensor(name="last_hidden_state", dtype=np.float32, shape=(-1,)),
],PyTriton 為 Flask 用戶提供了一個熟悉的界面,便于安裝和設置,并提供了以下好處:
- ?用一行代碼調出 NVIDIA Triton
- 無需設置模型存儲庫和模型格式轉換(對于使用 Triton 推理服務器的高性能實現非常重要)
- 使用現有推理管道代碼而不進行修改
- 支持許多裝飾器來調整模型輸入
無論是在generative AI應用程序還是其他模型中,PyTriton 可以讓您在自己的開發環境中獲得 Triton InferenceServer 的好處。它可以幫助利用 GPU 在很短的時間內(毫秒或秒,取決于用例)生成推理響應。它還有助于以高容量運行 GPU ,并且可以同時為許多推理請求提供服務,且基礎設施成本低。
PyTriton 代碼示例
本節提供了一些可以用來開始 PyTriton 的代碼示例。它們從本地機器開始,這是測試和原型的理想選擇,并為大規模部署提供 Kubernetes 配置。
動態配料支持
Flask/FastAPI 和 PyTriton 之間的一個關鍵區別是,動態批處理允許對來自模型的多個調用應用程序的推理請求進行批處理,同時保留延遲要求。兩個示例是HuggingFace BART PyTorch和HuggingFace ResNET PyTorch。
在線學習
在線學習是指在生產中不斷從新數據中學習。使用 PyTriton,您可以控制支持推理服務器的不同模型實例的數量,從而使您能夠同時訓練和服務同一個模型。想要了解更多關于如何使用 PyTriton 在 MNIST 數據集上同時訓練和推斷模型的信息,請訪問 PyTriton 的示例。
大型語言模型的多節點推理
太大而無法放入單個 GPU 內存的大型語言模型(LLM)需要將模型劃分為多個 GPU,在某些情況下,還需要跨多個節點進行推理。要查看示例,請訪問 Hugging Face OPT 模型在 JAX 中的多節點推理。
想要查看NeMo Megatron GPT 模型部署,使用NVIDIA NeMo 1.3B 參數模型。使用 Slurm 和 Kubernetes 展示了多節點推理部署編排。
穩定擴散
使用 PyTriton ,您可以使用預處理裝飾器來執行高級批處理操作,例如使用簡單的定義將相同大小的圖像批處理在一起:
@batch
@group_by_values("img_size")
@first_value("img_size")
想了解更多信息,請查看此示例,該示例使用 Hugging Face 的 Stable Diffusion 1.5 圖像生成管道。
總結
PyTriton 提供了一個簡單的接口,使 GPU 開發人員能夠使用 NVIDIA Triton InferenceServer 為模型、簡單的處理功能或整個推理管道提供服務。這種對 Python 中的 Triton 推理服務器的本地支持使 ML 模型的快速原型設計和測試具有性能和效率。一行代碼就會顯示 Triton 推理服務器。動態批處理、并發模型執行以及 Python 代碼中對 GPU 和 Python 的支持都是其中的好處。 PyTriton 提供了 Flask 的簡單性和 Python 中 Triton InferenceServer 的優點。
使用本文中的示例,或者使用您自己的模型,嘗試 PyTriton。您可以參考Migrating to the Triton Inference Server,了解從 Flask 遷移到 PyTriton 和 Triton InferenceServer 的信息。要獲取更多信息,請訪問Triton Inference Server頁面和PyTriton 存儲庫在 GitHub 上。
?