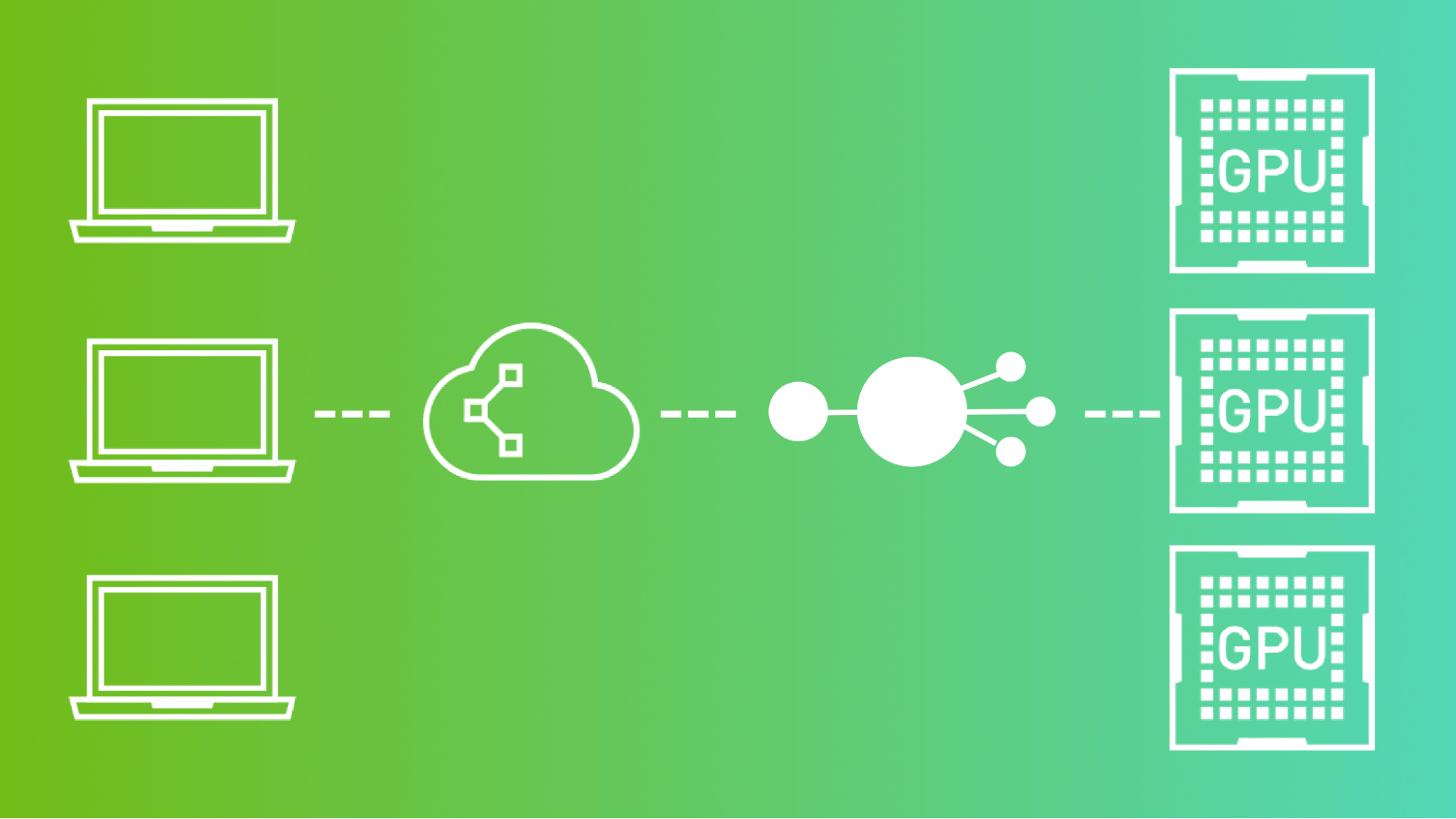
從初創企業到大型企業,企業都使用云市場來尋找快速轉型所需的新解決方案。云市場是在線店面,客戶可以在這里購買具有靈活計費模式的軟件和服務,包括現收現付、訂閱和私人協商優惠。企業進一步受益于以折扣價承諾的支出,以及節省時間和資源的單一賬單和發票來源。
NVIDIA Riva 是最先進的語音和翻譯人工智能服務,在最大的云服務提供商(CSP)市場上:
公司可以快速找到高性能的語音和翻譯人工智能,這些人工智能可以完全定制,以最適合對話管道,如問答服務、智能虛擬助理、數字化身和不同語言的聯絡中心代理助理。
組織可以在公共云上快速運行 Riva ,或將其與云提供商服務集成,從而獲得更大的信心和更好的投資回報。有了云計算中的 NVIDIA Riva ,您現在可以通過瀏覽器即時訪問 Riva 語音和翻譯 AI——即使您目前沒有自己的內部部署 GPU ——加速的基礎設施。
您可以從市場購買 NVIDIA Riva ,或使用現有的云信用。聯系 NVIDIA ,通過 Amazon Web Services,Google Cloud Platform 或 Microsoft Azure 獲取私人報價。
在這篇文章和相關視頻中,以西班牙語到英語的語音轉換(S2S)為例,您將學習如何在單個 CSP 節點上原型和測試 Riva 。本文還介紹了在托管的 Kubernetes 集群上大規模部署 Riva 。
在單個節點上進行原型和測試 Riva
在使用 Riva 啟動和擴展會話應用程序之前,在單個節點上進行原型和測試,以發現缺陷和改進區域,并確保完美的生產性能。
- 在公共 CSP 上選擇并啟動 Riva 虛擬機映像(VMI)
- 訪問 NVIDIA GPU Cloud(NGC)目錄上的 Riva 容器
- 配置 NGC CLI
- 編輯 Riva Skills 快速入門配置腳本并部署 Riva 服務器
- 開始使用教程 Jupyter 筆記本的 Riva
- 運行語音對語音(S2S)翻譯推理
視頻 1 解釋了如何從 Riva VMI 啟動 GCP 虛擬機實例并從終端連接到它。
視頻 2 展示了如何啟動 Riva 服務器并在虛擬機實例中運行西班牙語到英語的語音到語音翻譯。
在公共 CSP 上選擇并啟動 Riva VMI
Riva VMI 提供了一個自包含的環境,使您能夠在公共云服務的單個節點上運行 Riva 。您可以通過以下步驟快速啟動。
轉到您選擇的 CSP:
選擇適當的按鈕開始配置 VM 實例。
- 設置計算區域、 GPU 和 CPU 類型以及網絡安全規則。S2S 翻譯演示程序應該只占用 13-14 GB 的 GPU 內存,并且應該能夠在 16 GB 的 T4 GPU 上運行。
- 如有必要,生成 SSH 密鑰對。
部署 VM 實例并在必要時對其進行進一步編輯。使用 SSH 和本地終端中的密鑰文件連接到 VM 實例(這是最安全的方法)。
使用 SSH 和密鑰文件連接到 GCP VM 實例需要gcloudCLI 而不是內置的 SSH 工具。使用以下命令格式:
gcloud compute ssh --project=<Project_ID> --zone=<Zone> <VM_Name> -- -L 8888:localhost:8888 |
如果您已經添加項目_ID和計算區價值觀gcloudconfig,您可以在命令中省略這些標志。這個-L標志啟用端口轉發,使您能夠在虛擬機實例上啟動 Jupyter,并在本地瀏覽器中訪問它,就像 Jupyter 服務器在本地運行一樣。
訪問 NGC 上的 Riva 容器
NGC catalog 是一套精心策劃的 GPU 加速人工智能模型和 SDK,可幫助您將人工智能快速融入應用程序。
將 Riva 容器和所需模型下載到 VM 實例中的最簡單方法是下載 Riva Skills Quick Start,它具有適當的資源文件夾和 ngc 命令。然后,編輯提供的配置 .sh 腳本,并運行 Riva _init.sh 和 Riva _start.sh 腳本。
Riva VMI 用戶的額外福利是可以訪問 NVIDIA AI Enterprise Catalog on NGC。
配置 NGC CLI 以訪問資源
NGC CLI 配置可確保您可以訪問 NVIDIA 軟件資源。該配置還確定您可以訪問哪個容器注冊表空間。
Riva VMI 已經提供了 NGC CLI,所以您不必下載或安裝它。您仍然需要配置它。
如有必要,生成一個 NGC API 密鑰。在右上角,選擇你的名字和組織的 設置,然后選擇 獲取 API 密鑰 和 生成 API 密鑰。請確保將新生成的 API 密鑰復制并保存到安全的位置。
跑ngc 配置集并粘貼到您的 API 密鑰中。設置對 NGC CLI 的調用結果的輸出格式,并設置您的組織、團隊和 ACE。
編輯 Riva Skills 快速入門配置腳本并部署 Riva 服務器
Riva 包含快速入門腳本,可幫助您開始使用 Riva 語音和翻譯 AI 服務:
- 自動語音識別(ASR)
- 文本到語音(TTS)
- 幾種自然語言處理(NLP)任務
- 神經機器翻譯
在資產的 NGC 概覽頁面上,選擇 下載。如果要將相應的 NGC CLI 命令復制到 VM 實例的終端中,請選擇 CLI:
ngc registry resource download-version "nvidia/riva/riva_quickstart:2.12.1" |
在出版時,2.12.1 是 Riva 的最新版本。有關最新版本號,請查看 NGC 目錄或 Riva 文檔頁面。
在 VM 實例的終端中下載 Riva Skills Quick Start 資源文件夾后,實現西班牙語到英語的語音轉換(S2S)管道。
在 Riva 技能快速入門主目錄中,編輯配置.sh腳本來告訴 Riva 要啟用哪些服務以及要下載.rmir 格式的哪些模型文件。
設置service_enabled_nlp=false但將其他服務保留為真的。您需要西班牙語 ASR、西班牙語到英語 NMT 和英語 TTS。不需要 NLP。
要啟用西班牙語 ASR,請更改language_code=(“en-US”)到language_code=(“es US”).
取消注釋包含rmir_megatronnmt_any_en_500m以實現從西班牙語(以及 30 多種其他語言中的任何一種)到英語的 NMT。
要下載所需的.rmir 文件并進行部署,請運行以下命令。Riva _init.sh包裹在Riva -部署命令
bash riva_init.sh config.sh |
要啟動 Riva 服務器,請運行以下命令:
bash riva_start.sh config.sh |
如果服務器沒有啟動,請將相關的 Docker 日志輸出到一個文件中:
docker logs riva-speech &> docker-logs-riva-speech.txt |
檢查文件。如果您看到任何 CUDA 內存不足錯誤,那么您的模型管道對于 GPU 來說太大了。
通過 Jupyter 筆記本教程開始使用 Riva
開始使用 Riva 的最佳方法之一是在 /nvidia-riva/tutorials GitHub 上進行嘗試。
git clone https://github.com/nvidia-riva/tutorials.git |
VMI 已經包含一個 miniconda Python 分發版,其中包括 Jupyter。從安裝依賴項的基本(默認)環境創建一個新的 conda 環境,然后啟動 Jupyter。
克隆基本(默認)環境:
conda create --name conda-riva-tutorials --clone base |
激活新環境:
conda activate conda-riva-tutorials |
為新環境安裝一個 i Python 內核:
ipython kernel install --user --name=conda-riva-tutorials |
啟動 Jupyter 實驗室:
jupyter lab --allow-root --ip 0.0.0.0 --port 8888 |
如果使用連接到 VM 實例時設置端口轉發gcloud 計算 ssh,選擇包含的鏈接127.0.0.1在本地瀏覽器中運行 Jupyter Lab。如果沒有,請在瀏覽器欄中輸入以下內容以運行 Jupyter 實驗室:
- 您的 VM 實例的外部 IP 地址
- 冒號(:)
- 端口號(大概8888)
- /實驗室?token=<token>
如果您不想在瀏覽器欄中復制和粘貼令牌,瀏覽器會要求您在對話框中輸入令牌。
運行語音到語音的翻譯演示
此語音對語音(S2S)演示由nmt- Python -basics.ipynb教程筆記本。要執行此操作,請執行以下步驟。
導入必要的模塊:
import IPython.display as ipdimport numpy as npimport riva.client |
創建一個 Riva 客戶端并連接到 Riva server:
auth = riva.client.Auth(uri="localhost:50051")riva_nmt_client = riva.client.NeuralMachineTranslationClient(auth) |
加載音頻文件:
my_wav_file = "ASR-Demo-2-Spanish-Non-Native-Elena.wav" |
音頻文件包含一段同事閱讀米格爾·德·塞萬提斯著名小說中一行的片段堂吉訶德“Cuando la vida misma parece lunática,?quién sabe dónde estála locora?”
這可以翻譯成英語,“當生活本身看起來很瘋狂時,誰知道瘋狂在哪里?”
設置音頻塊迭代器,即將音頻文件劃分為不大于給定幀數的塊:
audio_chunk_iterator = riva.client.AudioChunkFileIterator(my_wav_file, chunk_n_frames=4800) |
定義由 ASR、NMT 和 TTS 配置序列組成的 S2S 配置:
s2s_config = riva.client.StreamingTranslateSpeechToSpeechConfig( asr_config = riva.client.StreamingRecognitionConfig( config=riva.client.RecognitionConfig( encoding=riva.client.AudioEncoding.LINEAR_PCM, language_code='es-US', # Spanish ASR model max_alternatives=1, profanity_filter=False, enable_automatic_punctuation=True, verbatim_transcripts=not True, sample_rate_hertz=16000, audio_channel_count=1, ), interim_results=True, ), translation_config = riva.client.TranslationConfig( source_language_code="es-US", # Source language is Spanish target_language_code='en-US', # Target language is English model_name='megatronnmt_any_en_500m', ), tts_config = riva.client.SynthesizeSpeechConfig( encoding=1, sample_rate_hz=44100, voice_name="English-US.Female-1", # Default EN female voice language_code="en-US", ), ) |
向 Riva 語音 API 服務器發出 gRPC 請求:
responses = riva_nmt_client.streaming_s2s_response_generator( audio_chunks=audio_chunk_iterator, streaming_config=s2s_config) |
收聽流媒體響應:
# Create an empty array to store the receiving audio bufferempty = np.array([])# Send requests and listen to streaming response from the S2S servicefor i, rep in enumerate(responses): audio_samples = np.frombuffer(rep.speech.audio, dtype=np.int16) / (2**15) print("Chunk: ",i) try: ipd.display(ipd.Audio(audio_samples, rate=44100)) except: print("Empty response") empty = np.concatenate((empty, audio_samples))# Full translated synthesized speechprint("Final synthesis:")ipd.display(ipd.Audio(empty, rate=44100)) |
這就產生了合成語音的片段和最終的完全組裝的片段。最后剪輯中的合成聲音應該是這樣的:“當生活本身看起來很瘋狂時,誰知道瘋狂在哪里?”
在托管 Kubernetes 平臺上部署 Riva
在啟動 Riva VMI 并訪問企業目錄后,您還可以將 Riva 部署到各種受支持的托管 Kubernetes 平臺,如 AKS、 Amazon EKS 和 GKE。這些托管 Kubernetes 平臺是生產級部署的理想選擇,因為它們能夠實現無縫的自動化部署、輕松的可擴展性和高效的可操作性。
為了幫助您入門,本文將引導您完成 Riva 在 GKE 集群上的示例部署。通過結合 Terraform 和 Helm 的力量,您可以快速建立生產級部署。
- 使用 NVIDIA Terraform 模塊在托管的 Kubernetes 平臺上建立 Kubernete 集群
- 使用 Helm 圖在 Kubernetes 集群上部署 Riva 服務器
- 在 Kubernetes 集群上與 Riva 交互
視頻 3 介紹了如何使用 Terraform 在 Google Kubernetes Engine(GKE)上設置和運行 Riva 。
視頻 4 展示了如何通過使用 Helm 在 Kubernetes 集群上部署 Riva 來擴大和擴大語音 AI 推理。
使用 NVIDIA Terraform 模塊設置 GKE 集群
NVIDIA Terraform 模塊使部署 Riva 就緒的 GKE 集群變得容易。想要了解更多信息,請訪問 nvidia-terraform-modules GitHub。
要開始,請克隆 repo 并在計算機上安裝必備組件:
- kubectl
- gcloud CLI
- 請確保您已經通過運行 gcloud 組件安裝 gke gcloud auth 插件
- 您的 GCP 賬戶應具有Kubernetes Engine Admin權限
- Terraform ( CLI )
從內部NVIDIA 地形模塊/gke目錄中,請確保使用 gcloud CLI 設置了活動憑據。
使現代化地形.tfvar通過取消注釋集群名稱和區域并填寫特定于您項目的值。默認情況下,此模塊會將集群部署到一個新的 VPC 中。要將集群部署到現有的 VPC 中,還必須取消注釋并設置existing_vpc_details變量
或者,可以通過以下任何方式更改任何變量名或參數:
- 將它們直接添加到變量.tf.
- 使用-var旗幟
- 將它們作為環境變量傳入。
- 出現提示時,從命令行傳遞它們。
在里面變量.tf,更新以下變量以供 Riva 使用: GPU 類型和區域。
選擇支持的 GPU 類型:
variable "gpu_type" { default = "nvidia-tesla-t4" description = "GPU SKU To attach to Holoscan GPU Node (eg. nvidia-tesla-k80)"} |
(可選)選擇您所在的地區:
variable "region" { default = "us-west1" description = "The Region resources (VPC, GKE, Compute Nodes) will be created in"} |
運行 gcloud 身份驗證應用程序默認登錄,使您的 Google 憑據可用于地球化可執行文件。有關詳細信息,請參閱 Terraform 文檔中的 為根模塊變量分配值。
- 地形初始化:初始化配置。
- 地形平面圖:查看將應用的內容。
- 地形應用:針對 GKE 環境應用代碼。
使用連接到群集庫貝克特爾通過在創建集群后運行以下命令:
gcloud container clusters get-credentials <CLUSTER_NAME> --region=<REGION> |
要刪除 Terraform 提供的云基礎設施,請運行地形破壞.
NVIDIA Terraform 模塊也可以用于其他 CSP 中的部署,并遵循類似的模式。有關部署 AKS 和 EKS 集群的更多信息,請參閱 NVIDIA/nvidia-terraform-modules GitHub。
使用 Helm 圖表部署 Riva 語音技能 API
Riva 語音技能 Helm 圖表旨在自動部署到 Kubernetes 集群。下載 Helm 圖表后,對圖表進行一些小的調整,使其適應本文其余部分使用 Riva 的方式。
首先下載并取消標記 Riva API Helm 圖表。2.12.1 版本是截至本文發布的最新版本。要下載不同版本的 Helm 圖表,請替換版本標簽以下代碼示例中需要特定版本:
export NGC_CLI_API_KEY=<your NGC API key>export VERSION_TAG="2.12.1"helm fetch https://helm.ngc.nvidia.com/nvidia/riva/charts/riva-api-${VERSION_TAG}.tgz --username='$oauthtoken' --password=$NGC_CLI_API_KEYtar -xvzf riva-api-${VERSION_TAG}.tgz |
在Riva -api文件夾中,按照說明修改以下文件。
在values.yaml文件,在modelRepGenerator.ngcModelConfigs.tritonGroup0,根據需要對特定模型進行注釋或取消注釋,或更改語言代碼。
對于之前使用的 S2S 管道:
- 將 ASR 模型中的語言代碼從美式英語更改為拉丁美洲西班牙語,以便rmir_asr_conformer_en_us_str_thr變成rmir_asr_conformer_es_us_str_thr.
- 取消注釋包含rmir_megatronnmt_any_en_500m.
- 確保服務類型設置為群集 IP而不是負載平衡器。這只會將服務公開給集群中的其他服務,例如本文稍后安裝的代理服務。
在templates/deployment.yaml文件,然后添加節點選擇器約束以確保 Riva 僅部署在正確的 GPU 資源上。將其附加到節點池(在 Amazon EKS 中稱為節點組)。您可以從 GCP 控制臺或通過在終端中運行適當的 gcloud 命令來獲取此信息:
$ gcloud container clusters listNAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUSriva-in-the-cloud-blog-demo us-west1 1.27.3-gke.100 35.247.68.177 n1-standard-4 1.27.3-gke.100 3 RUNNING$ gcloud container node-pools list --cluster=riva-in-the-cloud-blog-demo --location=us-west1NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSIONtf-riva-in-the-cloud-blog-demo-cpu-pool n1-standard-4 100 1.27.3-gke.100tf-riva-in-the-cloud-blog-demo-gpu-pool n1-standard-4 100 1.27.3-gke.100 |
在里面spec.template.spec,在前面的節點池名稱中添加以下內容:
nodeSelector: cloud.google.com/gke-nodepool: tf-riva-in-the-cloud-blog-demo-gpu-pool |
請確保您所在的工作目錄/ Riva -api作為子目錄,然后安裝 Riva Helm 圖表。可以顯式重寫values.yaml文件
helm install riva-api riva-api/ \ --set ngcCredentials.password=`echo -n $NGC_CLI_API_KEY | base64 -w0` \ --set modelRepoGenerator.modelDeployKey=`echo -n tlt_encode | base64 -w0` |
Helm 圖表按順序運行兩個容器:
- A.Riva -模型初始化下載和部署模型的容器。
- A.Riva -語音 api容器來啟動語音服務 API。
根據模型的數量,初始模型部署可能需要一個小時或更長時間。要監視部署,請使用庫貝克特爾描述Riva -apiPod 和查看容器日志。
export pod=`kubectl get pods | cut -d " " -f 1 | grep riva-api`kubectl describe pod $podkubectl logs -f $pod -c riva-model-initkubectl logs -f $pod -c riva-speech-api |
現在已經部署了 Riva 服務器。
與 GKE 集群上的 Riva 交互
雖然這種與服務器交互的方法可能不太適合生產環境,但您可以通過將調用中的 URI 更改為Riva .client.Auth以使 Riva Python 客戶端向Riva -api服務,而不是本地主機。使用獲取適當的 URI庫貝克特爾:
$ kubectl get servicesNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkubernetes ClusterIP 10.155.240.1 <none> 443/TCP 1hriva-api LoadBalancer 10.155.243.119 34.127.90.22 8000:30623/TCP,8001:30542/TCP,8002:32113/TCP,50051:30842/TCP 1h |
這里沒有港口轉運。要從集群外的 Jupyter 筆記本在 GKE 集群上運行西班牙語到英語的 S2S 翻譯管道,請更改以下行:
auth = riva.client.Auth(uri="localhost:50051") |
這是所需的行:
auth = riva.client.Auth(uri="<riva-api IP address>:50051") |
有多種方式可以與服務器進行交互。其中一種方法涉及通過在 Helm 的 Traefik Edge 路由器上部署入口路線。有關詳細信息,請參閱 部署 Traefik 邊緣路由器。
NVIDIA 還通過語音 AI 工作流提供了一個有主見的生產部署配方,包括音頻轉錄和智能虛擬助手。有關詳細信息,請參閱技術簡報。
總結
NVIDIA Riva 可在 Amazon Web Services,Google Cloud 和 Microsoft Azure 市場上找到。通過快速部署的 VMI,在單個節點上開始在云中進行原型設計和測試 Riva。有關詳細信息,請參閱 NVIDIA Riva on GCP 視頻。
使用 NVIDIA Terraform 模塊,可以非常容易地在 Kubernetes 上托管生產級的 Riva 部署。有關詳細信息,請參閱 NVIDIA Riva on GKE 視頻。
通過從 CSP 市場購買許可證,在具有云信用的 CSP 計算資源上部署 Riva :
您也可以通過 Amazon Web Services,Google Cloud 或 Microsoft Azure 獲取私人優惠折扣定價表格。
?