
人工智能正在迅速改變工業視覺檢測。在工廠環境中,目視檢查用于許多問題,包括在組裝過程中檢測缺陷和丟失或不正確的零件。計算機視覺可以幫助及早發現產品的問題,減少產品交付給客戶的機會。
然而,對于邊緣人工智能開發人員來說,開發準確且通用的物體檢測模型仍然具有挑戰性。穩健的對象檢測模型需要訪問全面且具有代表性的數據集。在許多制造場景中,真實世界的數據集在捕捉實際場景的復雜性和多樣性時顯得不足。狹窄環境和有限變化的限制對訓練模型有效適應一系列情況提出了挑戰。
團隊可以利用合成數據在與現實世界場景非常相似的多樣化隨機數據上訓練模型,以解決數據集差距。其結果是更準確、適應性更強的人工智能模型,可用于工業自動化、醫療保健和制造業等領域的廣泛邊緣人工智能應用。
從合成數據生成到人工智能訓練
Edge Impulse 是一個集成開發平臺,使開發人員能夠為邊緣設備創建和部署人工智能模型。它支持數據收集、預處理、模型訓練和部署,幫助用戶將人工智能功能有效地集成到應用程序中。
借助 NVIDIA Omniverse Replicator,這是 NVIDIA Omniverse 的核心擴展,用戶可以在 Universal Scene Description 中,也稱為 OpenUSD,創建圖像。然后,這些圖像可以用于在 Edge Impulse 平臺上訓練對象檢測模型。
NVIDIA Omniverse 是一個計算平臺,使個人和團隊能夠開發基于通用場景描述(OpenUSD )的 3D 工作流和應用程序。
OpenUSD 是一種高度通用且可互操作的 3D 可互換格式,由于其可擴展性、性能、版本控制和資產管理功能,它在合成數據生成方面表現出色,是創建復雜逼真數據集的理想選擇。有一個龐大的 3D 內容工具生態系統,連接到 OpenUSD 和 基于 USD 的 SimReady 資產,這使得將基于物理的對象集成到場景中變得容易,并加速了我們的合成數據生成工作流程。
Omniverse Replicator 使 USD 數據能夠在多個域中隨機化,以表示反映對象檢測模型可能遇到的現實世界可能性的場景。
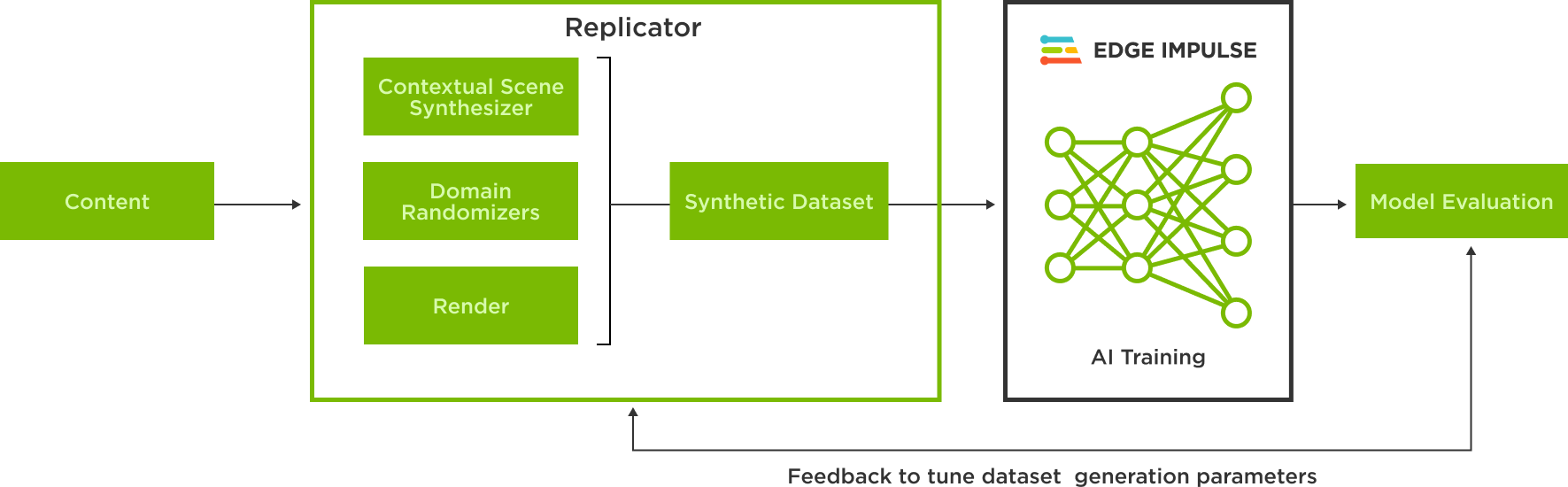
在新的 Edge Impulse Omniverse 擴展中,使用 USD 中合成生成的圖像在 Edge Impulsion 中訓練模型只需點擊幾下。
該擴展是使用 Omniverse Kit Python 擴展模板,用戶可以連接到 Edge Impulse API 并選擇數據集來上傳他們的合成數據。Kit Python 擴展模板是一個簡單明了的資源,用于代碼片段選項和快速開發擴展。
生成對象檢測模型的合成數據
要了解使用 Omniverse Replicator 生成合成數據并使用它在 Edge Impulse 中訓練模型的工作流程,請以檢測汽水罐模型為例。

該過程的第一步是構建一個虛擬復制品,或者說是代表真實場景環境的數字孿生。生成合成圖像的場景由可移動和不可移動的物體組成。不可移動的設備包括燈、一條傳送帶和兩臺攝像機,而可移動的物體則由汽水罐組成。通過使用 領域隨機化,可以更改許多屬性,包括選定的不可移動和可移動對象的位置、照明、顏色、紋理、背景和前景。
這些資產通過 OpenUSD 在 Omniverse Replicator 中表示。3D 模型文件可以轉換為 USD ,并使用 Omniverse CAD Importer 擴展名導入 Omniverse Replicator。
照明在真實感圖像生成中起著關鍵作用。矩形燈光可以模擬面板生成的燈光,而圓頂燈光可以照亮整個場景。可以隨機化燈光的各種參數,如燈光的溫度、強度、比例、位置和旋轉。
以下腳本顯示了通過從正態分布中采樣而隨機化的溫度和強度,以及按均勻分布隨機化的量表。燈光的位置和旋轉是固定的,以保持不變。
python
# Lightning setup for Rectangular light and Dome light
def rect_lights(num=1):
lights = rep.create.light(
light_type="rect",
temperature=rep.distribution.normal(6500, 500),
intensity=rep.distribution.normal(0, 5000),
position=(45, 110, 0),
rotation=(-90, 0, 0),
scale=rep.distribution.uniform(50, 100),
count=num
)
return lights.node
rep.randomizer.register(rect_lights)
def dome_lights(num=3):
lights = rep.create.light(
light_type="dome",
temperature=rep.distribution.normal(6500, 500),
intensity=rep.distribution.normal(0, 1000),
position=(45, 120, 18),
rotation=(225, 0, 0),
count=num
)
return lights.node
rep.randomizer.register(dome_lights)
大多數場景都有對環境很重要的不可移動物體,比如桌子,或者在這種情況下是傳送帶。這些對象的位置可以是固定的,而對象的材質可以隨機化以反映真實世界的可能性。
下面的腳本在 USD 中生成一個傳送帶,罐子將放置在該傳送帶上。它還固定其位置和旋轉。在這個例子中,我們沒有隨機化傳送帶的材料。
python
# Import and position the conveyor belt
conveyor = rep.create.from_usd(CONVEYOR_USD, semantics=[('class', 'conveyor')])
with conveyor:
rep.modify.pose(
position=(0, 0, 0),
rotation=(0, -90, -90),
)
為了保證高質量的數據集,最好使用多個不同分辨率的相機,并在場景中戰略性地定位它們。攝影機的位置也可以隨機化。該腳本設置了兩個不同分辨率的相機,它們戰略性地放置在場景中的不同位置。
# Multiple setup cameras and attach to render products
camera = rep.create.camera(focus_distance=focus_distance, focal_length=focal_length,
position=cam_position, rotation=cam_rotation, f_stop=f_stop)
camera2 = rep.create.camera(focus_distance=focus_distance2, focal_length=focal_length2,
position=cam_position2, rotation=cam_rotation, f_stop=f_stop)
# Render images
render_product = rep.create.render_product(camera, (1024, 1024))
render_product2 = rep.create.render_product(camera2, (1024, 1024))

最后一步是隨機化可移動物體的位置,同時將它們保持在相關區域中。在這個腳本中,我們初始化了五個 3D 罐頭模型實例,這些實例是從可用的罐頭資產集合中隨機選擇的。
cans = list()
for i in range(TOTAL_CANS):
random_can = random.choice(cans_list)
random_can_name = random_can.split(".")[0].split("/")[-1]
this_can = rep.create.from_usd(random_can, semantics=[('class', 'can')])
with this_can:
rep.modify.pose(
position=(0, 0, 0),
rotation=(0, -90, -90)
)
cans.append(this_can)
然后,罐子的姿勢被隨機化并分散在兩個平面上,使罐子保持在傳送帶上,同時避免碰撞。
with rep.trigger.on_frame(num_frames=50, rt_subframes=55):
planesList=[('class','plane1'),('class','plane2')]
with rep.create.group(cans):
planes=rep.get.prims(semantics=planesList)
rep.modify.pose(
rotation=rep.distribution.uniform(
(-90, -180, 0), (-90, 180, 0)
)
)
rep.randomizer.scatter_2d(planes, check_for_collisions=True)

注釋數據、構建模型和使用真實對象進行測試
生成圖像后,只需幾次點擊,就可以使用 Edge Impulse Omniverse 擴展將圖像上傳到 Edge Impulse Studio。在 Edge Impulse Studio 中,您可以使用模型對數據集進行注釋和訓練,例如 Yolov5 物體檢測模型。版本控制系統實現了跨不同數據集版本和超參數的模型性能跟蹤,以優化精度。
如果您想用真實世界的對象來測試模型的準確性,您可以流式傳輸實時視頻,并使用 Edge Impulse CLI 工具。
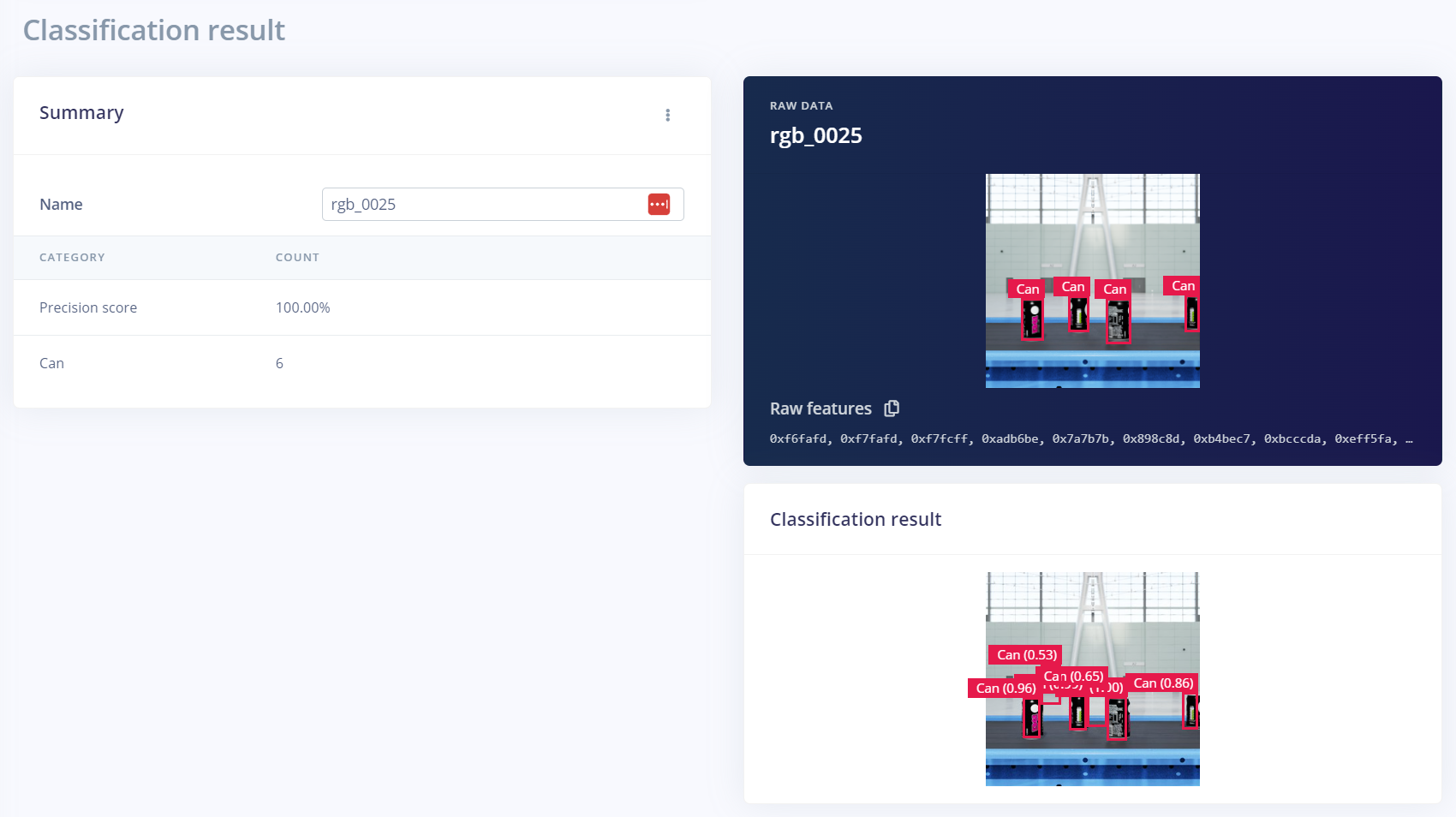
如果模型不能準確地檢測到對象,則必須在其他數據集上對模型進行訓練。當涉及到人工智能模型訓練時,這種迭代過程是常態。合成數據的另一個好處是,可以通過編程完成后續迭代中所需的變化。
在本例中,生成了一個額外的合成數據集,用于訓練模型以提高性能。額外的數據集使用了距離輸送機更遠的攝像機距離。其他參數,如相機的角度和材料,可以在額外的數據集中進行修改,以提高性能。
采用以數據為中心的方法,即圍繞模型的故障點創建更多數據,對于解決 ML 問題至關重要。參數的額外訓練和微調可以使模型在不同的方向、材料和其他相關條件下很好地推廣。
開始使用合成數據訓練和部署邊緣人工智能
在 Omniverse Replicator 中生成物理上準確的合成數據非常容易。只需 下載 Omniverse 免費版 并按照以下說明 開始使用 Omniverse Code 中的 Replicator。
您可以使用 Edge Impulse 在 Omniverse 中生成的合成數據來訓練 ML 模型。請注冊并從今天開始使用嵌入式機器學習模型。
與 NVIDIA 產品管理總監 Amit Goel 一起參加Imagine 2023 基調。了解行業對人工智能和機器學習的見解,以及NVIDIA Omniverse 和 Omniverse 復制器。
通過訂閱電子報,并繼續關注我們 Instagram, Medium和 Twitter。有關更多資源,請查看我們的 論壇。
?






