合成數據在訓練部署在自主移動機器人(AMR)上的感知 AI 模型時起著關鍵作用。這一過程在制造業中變得越來越重要。如果想查看使用合成數據生成可檢測倉庫中托盤的預訓練模型的示例,請參見利用 OpenUSD 和合成數據開發托盤檢測模型。
這篇文章探討了如何訓練 AMR 使用合成數據檢測倉庫托盤搬運車。托盤搬運車通常用于倉庫中提升和運輸重型托盤。在擁擠的倉庫中,AMR 檢測并避免與托盤搬運車碰撞非常重要。
為了實現這一目標,我們需要在各種照明和遮擋條件下,使用大量多樣的數據來訓練人工智能模型。真實數據很少能夠捕捉到所有潛在的場景。合成數據生成 (SDG),這是由 3D 模擬生成的注釋數據,使開發人員能夠克服數據缺口并引導模型訓練過程。
這個用例將再次采用以數據為中心的方法,通過操縱數據,而不是更改模型參數來適應數據。該過程首先使用 NVIDIA Omniverse Replicator 在 NVIDIA Isaac Sim 中生成數據,然后使用這些合成數據來訓練模型,使用的是 NVIDIA TAO 工具包。最后,我們將在真實數據上可視化模型的性能,并修改參數以生成更好的合成數據,從而達到所需的性能水平。
Omniverse Replicator 是 NVIDIA Omniverse 的一部分,這是一個計算平臺,使個人和團隊能夠基于 通用場景描述(OpenUSD) 構建。Replicator 使開發人員能夠構建自定義的合成數據生成管道,以生成用于引導計算機視覺模型訓練的數據。
使用合成數據迭代以提高模型性能
以下部分解釋了團隊如何使用合成數據進行迭代,以提高我們的目標檢測模型的真實世界性能。它使用與 Omniverse Replicator API 配合使用的 Python 腳本來完成各個步驟。
對于每次迭代,我們遞增地更改模型中的各種參數,并生成新的訓練數據集。然后根據實際數據驗證了模型的性能。我們繼續這個過程,直到我們能夠縮小模擬到真實的差距。
改變對象或場景參數的過程被稱為 領域隨機化。您可以隨機化許多參數,包括位置、顏色、紋理、背景、對象和場景的照明,這使您能夠快速生成用于模型訓練的新數據。
OpenUSD 是一個可擴展的框架、3D 場景描述和 NVIDIA Omniverse 的基礎,可以輕松地對場景的不同參數進行實驗。參數可以在各個層中進行修改和測試,用戶可以在這些層的頂部創建非破壞性覆蓋。
準備
要開始使用此示例,您需要一個已安裝最新 NVIDIA Isaac Sim 版本的NVIDIA RTX GPU 。Isaac Sim 是一個可擴展的機器人模擬應用程序,利用 Omniverse Replicator 的核心功能生成合成數據。有關安裝和配置的詳細信息,請參閱 文檔 部分。
當 Isaac Sim 啟動并運行時,您可以從 NVIDIA-AI-IOT/synthetic_data_generation_training_workflow GitHub 上獲取。
迭代 1:更改顏色和相機位置
在第一次迭代中,團隊改變了托盤搬運車的顏色和姿勢,以及相機的姿勢。按照以下步驟在您自己的會話中復制此場景。
從加載階段開始:
ENV_URL = "/Isaac/Environments/Simple_Warehouse/warehouse.usd"open_stage(prefix_with_isaac_asset_server(ENV_URL)) |
然后將托盤搬運車和相機添加到場景中。托盤搬運車可以從 SimReady 資產 圖書館中獲取。
cam = rep.create.camera(clipping_range=(0.1, 1000000)) |
SimReady 或模擬就緒資源是物理上精確的三維對象,包含精確的物理特性和行為。它們預裝了模型訓練所需的元數據和注釋。
接下來,為托盤搬運車和相機添加域隨機化:
with cam: rep.modify.pose(position=rep.distribution.uniform((-9.2, -11.8, 0.4), (7.2, 15.8, 4)),look_at=(0, 0, 0)) # Get the Palletjack body mesh and modify its color with rep.get.prims(path_pattern="SteerAxles"): rep.randomizer.color(colors=rep.distribution.uniform((0, 0, 0), (1, 1, 1))) # Randomize the pose of all the added palletjacks with rep_palletjack_group: rep.modify.pose( position=rep.distribution.uniform((-6, -6, 0), (6, 12, 0)), rotation=rep.distribution.uniform((0, 0, 0), (0, 0, 360)), scale=rep.distribution.uniform((0.01, 0.01, 0.01), (0.01, 0.01, 0.01))) |

最后,配置用于注釋數據的編寫器:
writer = rep.WriterRegistry.get("KittiWriter") writer.initialize(output_dir=output_directory, omit_semantic_type=True,) |
請注意,此示例使用 Replicator 提供的 KittiWriter 以 KITTI 格式存儲對象檢測標簽的注釋。這將確保更容易與培訓管道兼容。
后果
對于第一批合成數據,該團隊使用了LOCO 數據集,這是一個用于物流場景理解的數據集,涵蓋了檢測物流特定對象以及可視化真實世界模型性能的問題。
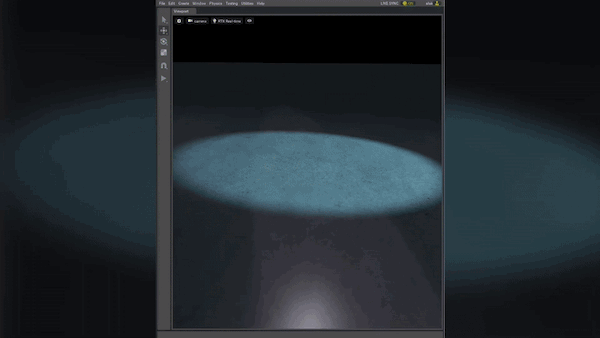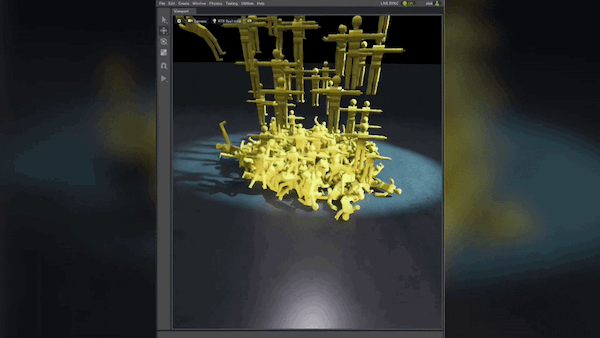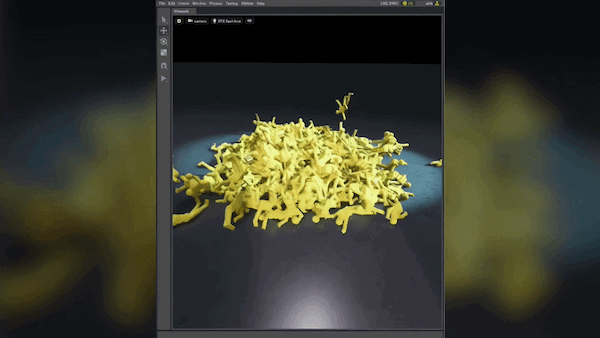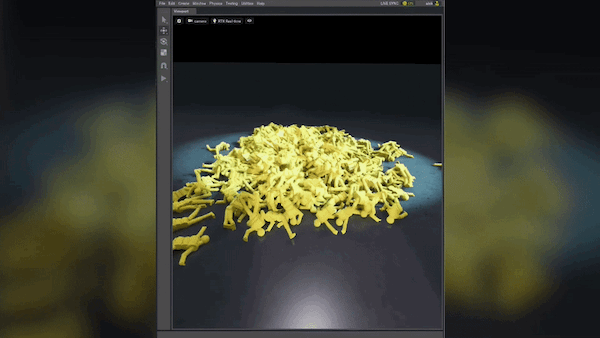
由此產生的圖像顯示,該模型仍在試圖檢測擁擠倉庫中的托盤搬運車(圖 2)。已經在托盤搬運車周圍的對象周圍創建了許多邊界框。這個結果在某種程度上是意料之中的,因為這是第一次訓練迭代。減少領域差距將是后續迭代的重點。

迭代 2:添加紋理和更改環境光
在這次迭代中,除了第一次迭代的托盤顏色和相機位置外,團隊還隨機化了紋理和環境照明。
激活紋理和照明的隨機化:
# Randomize the lighting of the scene with rep.get.prims(path_pattern="RectLight"): rep.modify.attribute("color", rep.distribution.uniform((0, 0, 0), (1, 1, 1))) rep.modify.attribute("intensity", rep.distribution.normal(100000.0, 600000.0)) rep.modify.visibility(rep.distribution.choice([True, False, False, False, False, False, False]))# select floor materialrandom_mat_floor = rep.create.material_omnipbr(diffuse_texture=rep.distribution.choice(textures), roughness=rep.distribution.uniform(0, 1), metallic=rep.distribution.choice([0, 1]), emissive_texture=rep.distribution.choice(textures), emissive_intensity=rep.distribution.uniform(0, 1000),) with rep.get.prims(path_pattern="SM_Floor"): rep.randomizer.materials(random_mat_floor) |
圖 3 顯示了生成的合成圖像。請注意已添加到背景中的各種紋理,以及入射到對象上的不同類型的環境光。

后果
該迭代顯示,通過添加紋理和照明隨機化,誤報數量有所減少。生成合成數據時的一個關鍵因素是確保生成的數據集中的數據具有良好的多樣性。來自合成領域的類似或重復數據可能無助于改進?真實世界模型性能。
若要提高數據集的多樣性,請在場景中添加更多隨機對象。這在第三次迭代中得到了解決,應該有助于提高模型的穩健性。

迭代 3:添加干擾物
此迭代將稱為干擾物的附加對象引入到場景中。這些干擾因素為數據集增加了更多的多樣性。此迭代還包括前兩次迭代中顯示的所有更改。
在場景中添加干擾因素:
DISTRACTORS_WAREHOUSE = ["/Isaac/Environments/Simple_Warehouse/Props/S_TrafficCone.usd", "/Isaac/Environments/Simple_Warehouse/Props/S_WetFloorSign.usd", "/Isaac/Environments/Simple_Warehouse/Props/SM_BarelPlastic_A_01.usd", "/Isaac/Environments/Simple_Warehouse/Props/SM_BarelPlastic_A_02.usd", "/Isaac/Environments/Simple_Warehouse/Props/SM_BarelPlastic_A_03.usd"]# Modify the pose of all the distractors in the scene with rep_distractor_group: rep.modify.pose(position=rep.distribution.uniform((-6, -6, 0), (6, 12, 0)), rotation=rep.distribution.uniform((0, 0, 0), (0, 0, 360)), scale=rep.distribution.uniform(1, 1.5)) |
請注意,此項目中使用的所有資產都可以使用默認的 Isaac Sim 安裝。通過在 nucleus 服務器上指定路徑來加載它們。

后果
圖 6 顯示了第三次迭代的結果。該模型可以準確地檢測托盤搬運車,并且邊界框較少。與第一次迭代相比,模型性能顯著提高。

繼續迭代
該團隊使用 5000 張圖像來訓練每次迭代的模型。您可以通過生成更多的變體,同時增加合成數據的大小,繼續迭代此工作流,以達到所需的準確性水平。
我們曾經使用 NVIDIA TAO 工具包 來訓練具有 resnet18 骨干的 DetectNet_v2 模型用于這些實驗。使用此模型并非工作流程的要求。您可以利用注釋生成的數據來訓練您選擇的架構和框架的模型。
我們在實驗中利用了 KITTI 編寫器。但是,您可以使用 Omniverse Replicator 編寫自己的自定義編寫器,以正確的注釋格式生成數據。這使您能夠與培訓工作流程無縫兼容。
您還可以在訓練過程中嘗試混合真實數據和合成數據。在獲得令人滿意的評估指標后,最終模型可以在 NVIDIA Jetson 上進行優化并部署在現實世界中。
使用 Omniverse Replicator 開發合成數據管道
使用 Omniverse Replicator,您可以構建自己的自定義合成數據生成管道或工具,以編程方式生成大量不同的合成數據集,從而引導您的模型并快速迭代。引入各種類型的隨機化為數據集增加了必要的多樣性,使模型能夠在各種條件下識別感興趣的對象。
要開始使用本文中的工作流程,請訪問在 GitHub 上的?NVIDIA-AI-IOT/synthetic_data_generation_training_workflow 。要了解完整的工作流程,請觀看 NVIDIA 的 Rishabh Chadha 和 Edge Impulse 的 Jenny Plunkett 展示如何使用 Omniverse Replicator 和合成數據來訓練制造過程的對象檢測模型的視頻(視頻 2)。
如果您想構建自己的自定義合成數據生成管道,可以免費下載 Omniverse 并按照說明開始使用 Omniverse Code 中的 Replicator。您也可以參加自定進度的在線課程,如 用于訓練計算機視覺模型的合成數據生成 和 觀看最新的 Omniverse Replicator 教程。
NVIDIA 最近發布了 Omniverse Replicator 1.10,為開發人員構建低代碼 SDG 工作流提供了新的支持。想要了解更多信息,請參閱 NVIDIA Omniverse Replicator 1.10 中的低代碼工作流促進合成數據生成。
NVIDIA Isaac ROS 2.0 和 NVIDIA Isaac Sim 2023.1 現在也提供了性能感知和高保真模擬的主要更新。要了解更多信息,請參閱 在 NVIDIA Isaac 平臺上使用高級模擬和感知工具加速人工智能機器人。
?