這篇文章最初發表在 Mellanox 博客上。
讓我們來談談網絡流遙測技術以及您需要它的原因。您是否曾經在嘗試重新創建問題時遇到過問題,或者很難找出數據包丟失的原因?可能您是一名網絡管理員,因為應用程序中斷或服務器或存儲性能問題而受到指責。如果這些聽起來很熟悉,那么您需要良好的網絡遙測。因為網絡使應用程序能夠被訪問、共享數據并連接到存儲器,所以良好的網絡流遙測也是良好的應用程序遙測。
你們中的一些人可能會問,什么是遙測?
什么是遙測?
當你駕駛汽車時,遙測是速度表、轉速表、煤氣表、機油壓力表、發動機溫度和儀表板警告燈。這就是你需要的所有數據,可以讓你安全地到達你想去的地方,并了解汽車在途中的運行情況。無論你是駕駛汽車還是駕駛飛機,你都需要良好的遙測技術,而且你的速度越快,它就越關鍵。
如果您正在運行數據中心、部署 VM 和容器或管理存儲部署,則情況也是如此。您需要了解網絡結構內部的情況。您的網絡運行越快,或者網絡性能對您的業務越重要,它就變得越重要。切換流式遙測技術可以為您提供關鍵的可視性。
從協議轉向流式遙測
網絡管理的傳統立場是越多越好:協議越多,捕獲的數據包越多,在出現問題時,對捕獲的數據包進行更深入的挖掘,找出原因,然后進行修復。但在過去幾年中,數據中心網絡出現了簡化的趨勢。數據中心越大或越先進,他們喜歡運行的協議就越少。
回到我的技術支持時代,我們曾經有一句諺語,“客戶越聰明,配置文件越短。”總是遇到問題的客戶似乎是那些啟用了所有可能的功能和協議的客戶。您可以通過配置文件的長度來估計問題的數量。我已經看到了這種趨勢,從 L2 和所有版本的生成樹,以及根保護、循環保護、 BPDU 保護等創可貼,轉向更多的 L3 。

簡化趨勢的主要例外是需要更多的可見性,因為聰明的人希望看到他們的網絡中發生了什么。隨著網絡越來越大、越來越快,精明的管理員使用的協議越來越少,但他們的目標是更多的網絡遙測,以實現更好的可視性。
一些網絡管理員希望通過更好的流式遙測來提高他們的“平均無罪時間”。他們希望加快找到問題根本原因的時間,這樣他們就可以排除問題的根源,并證明這是否真的是服務器團隊的錯誤(或者可能是存儲團隊的錯誤)。
其他人則試圖從他們的網絡中獲得更多。大多數網絡團隊并不知道他們的網絡是被使用不足還是被過度使用,因為他們對實際情況的可見性很差。如果沒有這種理解,就不可能有效地運行網絡或適當地擴展網絡。
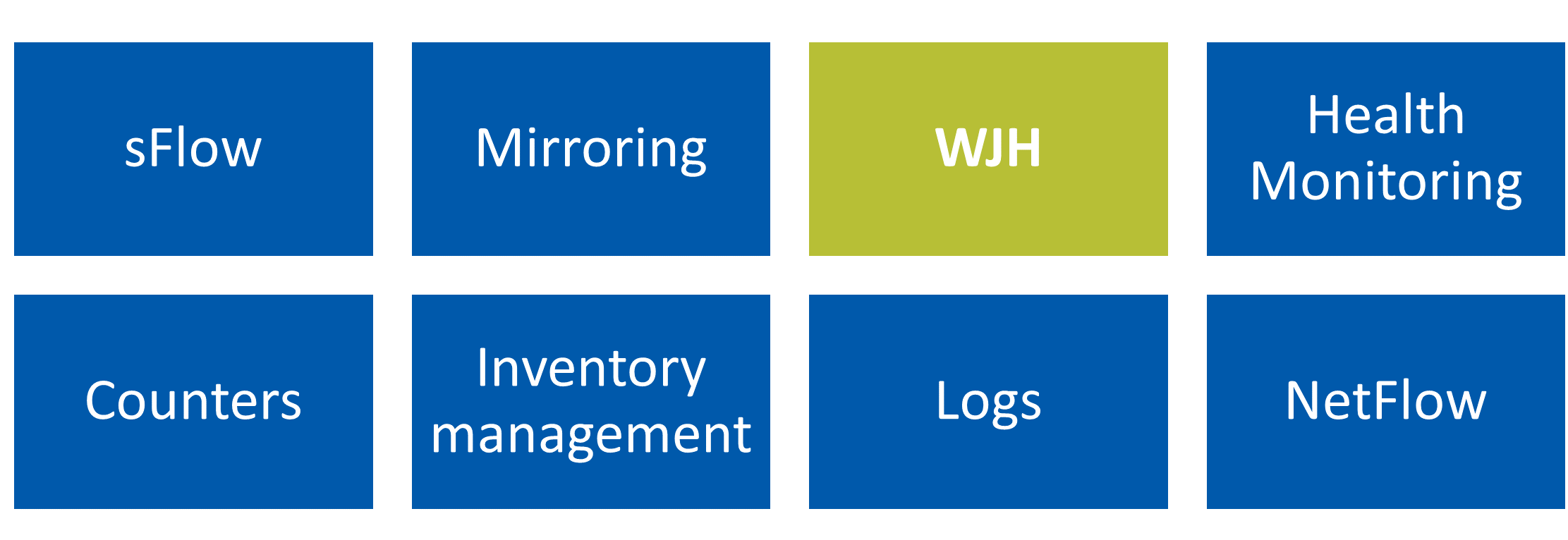
WJH 是一種交換機級監控解決方案,交換機 ASIC 監控以線路速率傳輸的數據流,并在數據包丟失、擁塞事件、路由循環等導致性能問題時向您發出警報。
例如,如果您因為壞電纜或壞光纖而丟棄數據包, WJH 會向您顯示這些丟棄的數據包,并告訴您它們被丟棄的原因。 WJH 會提醒您出現擁塞、緩沖區問題,甚至安全問題。例如,如果您遇到一堆 ACL ,而它們正在丟棄數據包,您想知道原因,因為可能是服務器或 VM 已損壞。或者,可能是您的 ACL 配置不好,導致了問題。
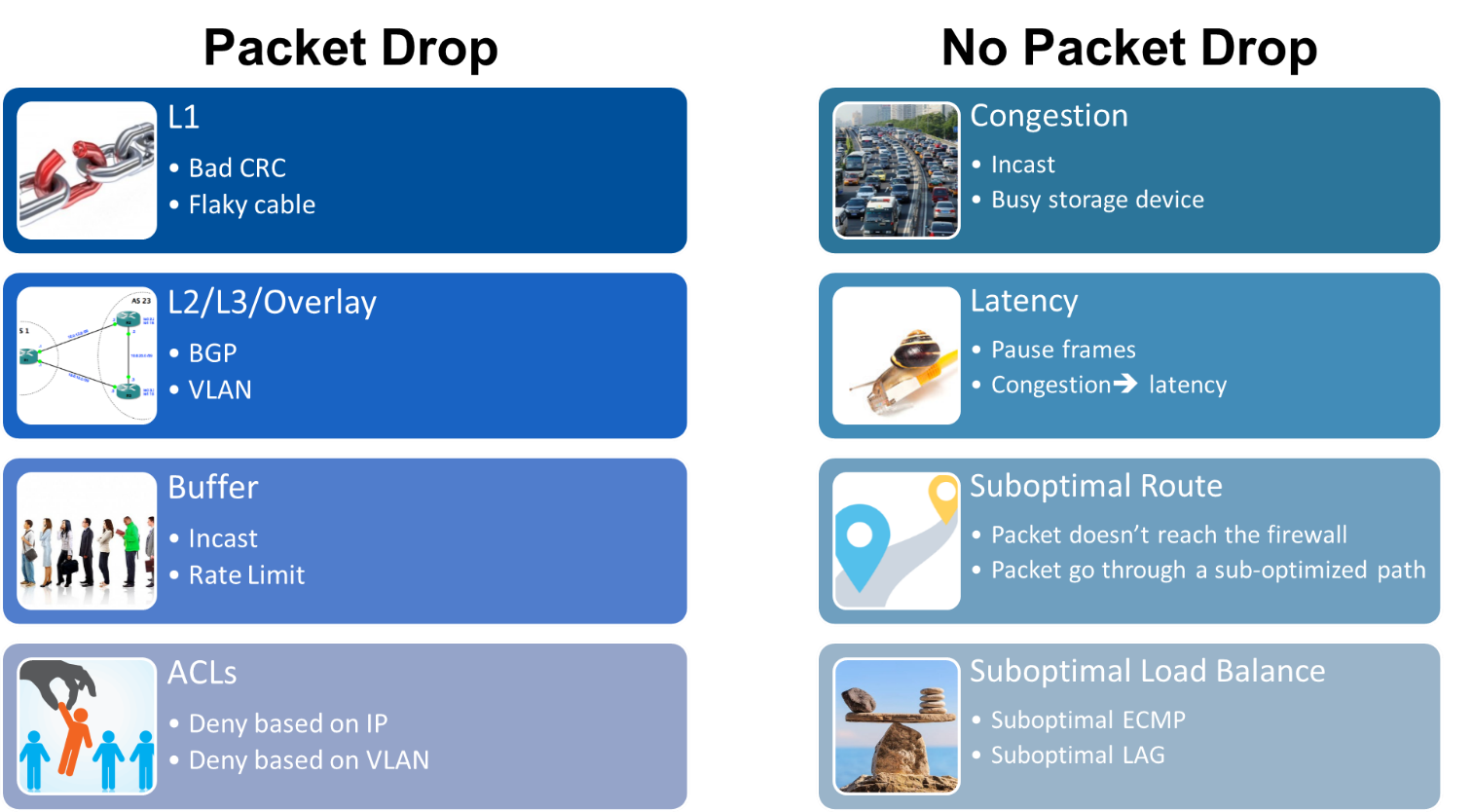
在無損環境中,如在RoCE上運行的 NVMe over Fabrics (NVMe-oF),即使您沒有丟棄數據包,也會出現性能問題。性能問題可能是由于擁塞問題、過多的暫停幀、,或延遲問題。通常會發現根本原因是LAG或ECMP組之間的負載平衡不平衡。無論您的問題是丟包還是沒有丟包的性能不佳,WJH都是為了深入了解這些問題,并為您提供最佳的流式遙測,以實現卓越的網絡可視性。
世界上幾乎每一個網絡都會有一些數據包丟失。有時是因為不好的原因,有時是因為好的原因。許多其他交換機遙測解決方案無法提供足夠的數據來診斷和解決問題。當一個非 NVIDIA 交換機丟棄一個數據包時,該數據包被發送到比特天堂,再也看不到了。數據包和所有有用的診斷信息都消失了。
這些開關所做的最多的事情就是增加一個模糊的計數器。當你檢查計數器時,交換機會說,“哦,由于一個壞的 VLAN ,你現在丟棄了 504 個數據包。”這些交換機不會告訴你關于丟棄的數據包的任何信息,也不會告訴你它是什么時候丟棄的,也不會告訴你為什么丟棄的,只是告訴你它是被丟棄的。您不知道數據包是否因為交換機配置錯誤、服務器配置錯誤或其他原因而被丟棄。
其他交換機或網絡管理解決方案對每個交換機上每個端口的數據包執行統計采樣。這會產生驚人的大量數據包,但不是所有的問題數據包,因此它不會記錄數據包丟失的時間、原因或方式。它也沒有正確地解釋擁塞是如何開始的,是什么導致了不可接受的高延遲,或者為什么流量變得不平衡或被錯誤路由。當懷疑出現問題時,您必須對保存的大量數據包進行分類,并嘗試推斷(或猜測)到底發生了什么以及原因。
在這些情況下,您同時擁有過多的數據(過多的采樣數據包),但卻沒有足夠的信息(關于問題數據包的詳細信息不足)。網絡上的一切都變得可疑,確定真正發生的事情可能需要數小時。有更好的方法!
WJH 是如何工作的?
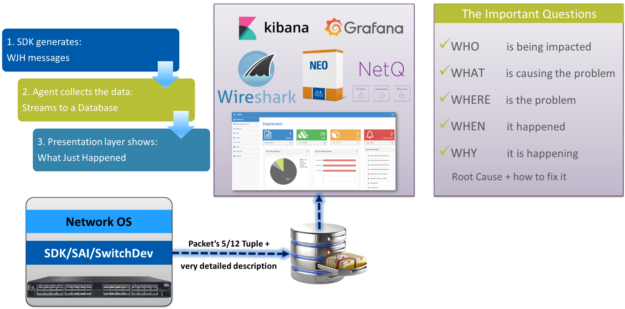
NVIDIA 剛剛發生的事情( WJH )是一種硬件加速遙測技術,其中交換機 ASIC 保留丟棄數據包的重要部分。交換機不會保留整個數據包或所有正常數據包,因為這將消耗大量空間,幾乎沒有什么好處。
相反,交換機保留問題數據包的重要部分,如源和目標 IP 地址、 MAC 、端口號等,以及關于丟棄原因、時間和地點的詳細描述。因為涉及到交換機,它知道要保存哪些數據包,以及為什么這些數據包被丟棄、太慢或路由錯誤。通過硬件加速,交換機可以記錄所有相關數據包以及重要的細節,即使在驅動 25 、 40 、 50 或 100 (很快就是 200 )千兆以太網的許多端口時也是如此。
對于小型部署,您可以登錄到交換機并快速查看網絡中出現的問題。對于較大的部署, WJH 可以使用 gRPC 將這些數據包流式輸出到一個集中的數據庫。這適用于 NVIDIA NEO 等交鑰匙解決方案,因為它位于標準數據庫中,所以它適用于 Kabana 和 Grafana 等開源工具。
如果您是一名網絡專家,或者曾經去過 Sniffer 大學,并且想要查看實際的數據包捕獲,交換機可以生成一個包含所有丟棄數據包的p.cap文件,以便您可以使用 Wireshark 查看它。 WJH 通過顯示誰受到影響、哪些應用程序、哪些服務器、問題的原因、問題出現的時間和地點,幫助您找到問題的根源。
網絡遙測的新希望
WJH 是一種新的網絡監控方式。傳統的網絡監控工具收集大量無辜的數據和計數器。他們甚至可能使用 sFlow 對隨機數據包進行采樣,以為您正在收集所有這些信息以猜測網絡中出現了什么問題。

出于某種原因,最棘手的網絡問題通常發生在晚上或周末。然后,你必須離開晚餐或你的家人的時間來篩選堆積如山的數據,并找到根本原因。你試著猜猜是什么引起了所有的麻煩。甚至有預測性分析工具 MIG ht 能給你 60-70% 的信心,讓你相信他們已經找到了根本原因。歸根結底,這仍然只是猜測。問題是您有太多的數據(來自數據包采樣),但通常不是最重要的數據(什么、在哪里、何時以及為什么)。
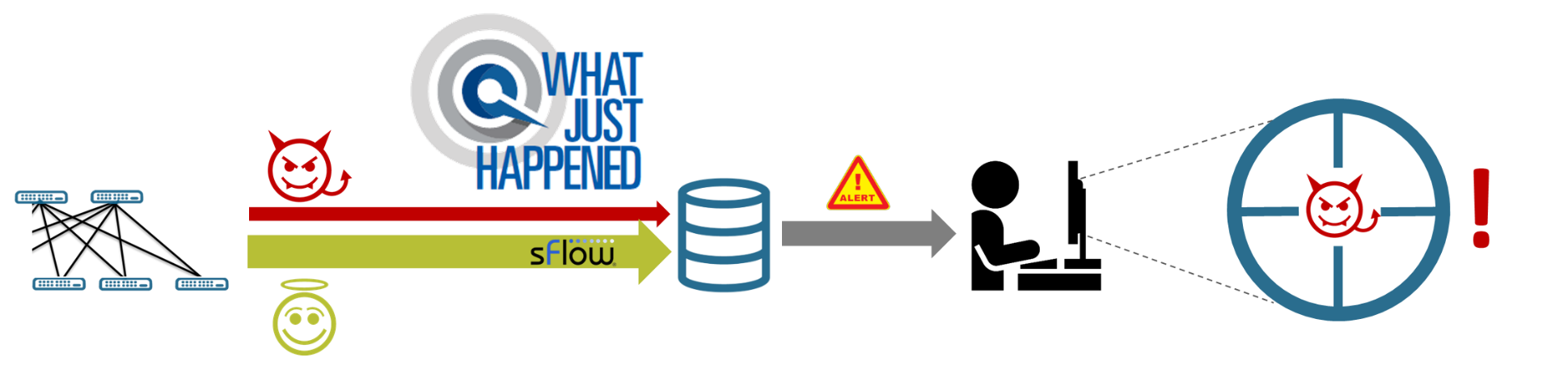
WJH 是一種新的監控網絡的方法,它關注數據平面異常情況,旨在讓您在晚上和周末返回。 WJH 快速向您顯示網絡中的受害者和數據包麻煩制造者或帶寬霸主。您可以不斷收集有關無辜設備和事件的大量數據,并嘗試處理它們,但是 WJH 給出了實際的根本原因,由不得不丟棄數據包的交換機直接記錄。
沒有更多的問題/再創作戲劇!
WJH 還打破了問題/重新創建周期:
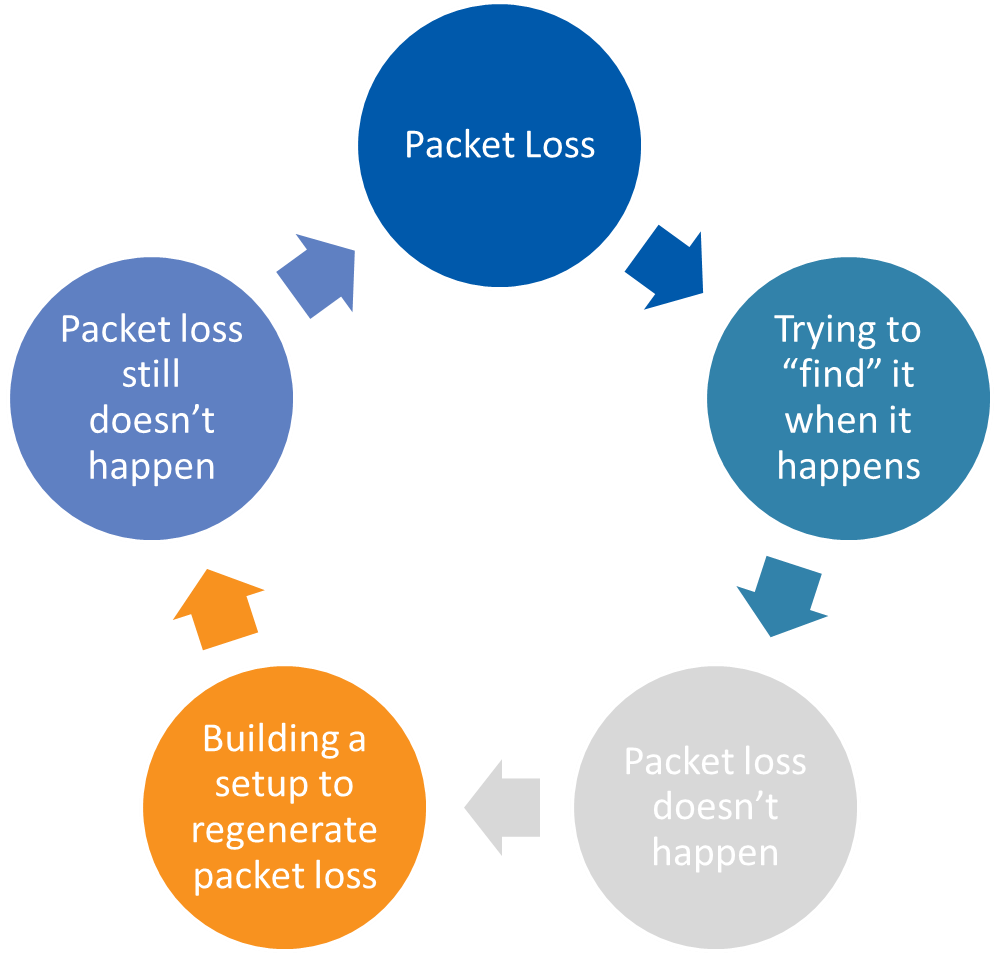
猜測問題何時會再次出現的舊方法,在測試臺或數據包跟蹤上設置一個重新創建的場景,只是為了不讓問題暴露出來,所以您可以在下一周……和下一周……重試…。這就是 WJH 的動力:先進的遙測技術。因為 WJH 保留著那些被丟棄的數據包并報告它們,所以它可以幫助你找到根本原因。 WJH 為您提供網絡可視性,而無需重現問題以解決問題。
如何部署 WJH ?
現在我知道你們中的一些人可能在想,“這聽起來很神奇,但我不能用 NVIDIA 交換機取代我的整個網絡。” WJH 的優點在于它獨立于網絡的其他部分工作。在一個交換機上運行的 WJH 可以報告該層網絡中其他交換機上可能發生的錯誤,這些交換機具有類似的功能。這與帶內遙測不同,后者最適用于同一供應商的所有交換機。
開始使用 WJH 非常簡單。
WJH 部署
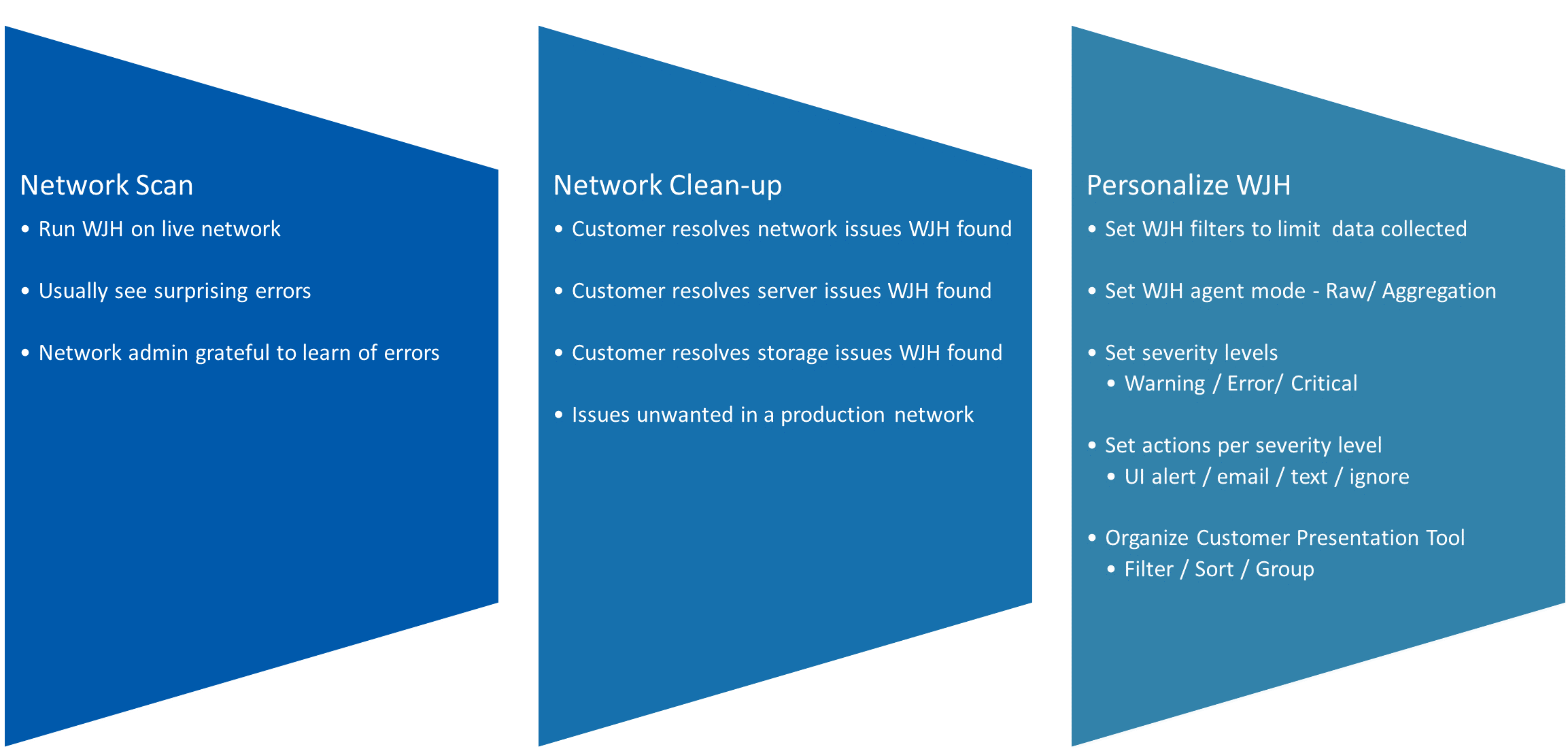
第一步
大多數人開始使用 WJH 時都會進行網絡掃描,這是通過在插入生產網絡的交換機上啟用 WJH 來實現的。人們幾乎總是對他們所了解到的錯誤感到驚訝。網絡管理員非常高興了解網絡中正在發生的事情。第一步就是打開 WJH ,看看你的網絡里到底發生了什么。
步驟 2
接下來是清理階段,在該階段,人們解決 WJH 發現的網絡問題以及 WJH 發現的服務器問題和存儲問題。
步驟 3
在這里,您可以根據您的網絡和管理需要對 WJH 進行個性化設置:
- 您或許設置了一些過濾器,因為您不需要報告某些類型的“正常”錯誤,甚至不需要記錄或存儲它
- 如果同一數據包的 1000 秒內會出現各種問題,則或許會將 WJH 代理設置為聚合模式。聚合模式只存儲該問題數據包的一個副本,而不是 1000 個相同的問題數據包。
- 您或許設置對您來說重要的問題的嚴重性級別。有些可能很關鍵,需要立即通知,而有些則可以稍后檢查,甚至忽略。
- 您可以設置嚴重性級別的操作。例如,您可能希望在關鍵問題上發送文本,在重大問題上發送電子郵件,而在次要問題上不發送警報。
概括
WJH 對于高級網絡負責人以及網絡新手來說是一個很好的工具,他們只想用一種簡單的方法從服務器和存儲問題中識別網絡問題。有了 WJH ,您不必成為網絡專家就可以快速找到性能問題的根本原因。
先進的流式遙測技術有利于您的業務。它可以幫助您從付費的網絡中獲得更高的性能、正常運行時間和生產率。