自7多年前推出至今, CUDA 統一內存編程模型一直在開發人員中廣受歡迎。統一內存為 GPU 應用程序的原型設計提供了一個簡單的接口,而無需在主機和設備之間手動 MIG 評級內存。
從 NVIDIA Pascal 更容易擴展到更大的問題規模體系結構開始,支持統一內存的應用程序可以使用系統 CPU 中所有可用的 CPU 和 GPU 內存。有關使用統一內存開始 GPU 計算的更多信息,請參閱 CUDA 更簡單的介紹。
您是否希望使用大型數據集無縫運行應用程序,同時保持內存管理簡單?統一內存可用于使虛擬內存分配大于可用 GPU 內存。在發生超額訂閱時, GPU 自動開始將內存頁逐出到系統內存,以便為活動的在用虛擬內存地址騰出空間。
但是,應用程序性能在很大程度上取決于內存訪問模式、數據駐留和運行的系統。在過去幾年中,我們發表了幾篇關于使用統一內存實現 GPU 內存超額訂閱的文章。我們通過各種編程技術(如預取和內存使用提示)為您的應用程序實現更高的性能提供了幫助。
在這篇文章中,我們深入研究了一個微基準測試的性能特征,它強調了超額訂閱場景中不同的內存訪問模式。它可以幫助您分解并了解統一內存的所有性能方面:什么時候適合,什么時候不適合,以及您可以做些什么。正如您將從我們的結果中看到的,根據平臺、超額訂閱因素和內存提示,性能可能會變化 100 倍。我們希望這篇文章能讓您更清楚地知道何時以及如何在應用程序中使用統一內存!
基準設置和訪問模式
要評估統一內存超額訂閱性能,可以使用分配和讀取內存的簡單程序。使用cudaMallocManaged分配一大塊連續內存,然后在 GPU 上訪問該內存,并測量有效的內核內存帶寬。不同的統一內存性能提示,如cudaMemPrefetchAsync和cudaMemAdvise修改分配的統一內存。我們將在本文后面討論它們對性能的影響。
我們定義了一個名為“ oversubscription factor ”的參數,它控制分配給測試的可用 GPU 內存的分數。
- 值為 1 . 0 表示 GPU 上的所有可用內存都已分配。
- 小于 1 . 0 的值表示 GPU 未被超額認購
- 大于 1 . 0 的值可以解釋為給定 GPU 的超額認購量。例如,具有 32 GB 內存的 GPU 的超額訂閱因子值為 1 . 5 意味著使用統一內存分配了 48 GB 內存。
我們在微基準測試中測試了三種內存訪問內核:網格步長、塊邊和隨機每扭曲。網格跨步和塊跨步是許多 CUDA 應用程序中最常見的順序訪問模式。然而,非結構化或隨機訪問在新興的 CUDA 工作負載中也非常流行,如圖形應用程序、哈希表和推薦系統中的嵌入。我們決定測試這三個。
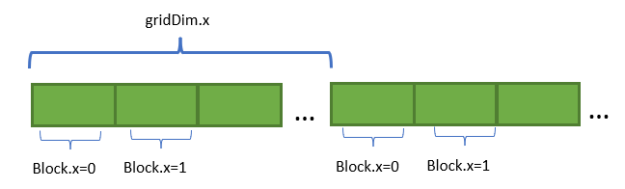
網格步長
每個線程塊在循環迭代中訪問相鄰內存區域中的元素,然后進行網格跨步(blockDim.x * gridDim.x)。
template<typename data_type>
__global__ void read_thread(data_type *ptr, const size_t size)
{
size_t n = size / sizeof(data_type);
data_type accum = 0;
for(size_t tid = threadIdx.x + blockIdx.x * blockDim.x; tid < n; tid += blockDim.x * gridDim.x)
accum += ptr[tid];
if (threadIdx.x == 0)
ptr[0] = accum;
}
擋步
每個線程塊訪問一大塊連續內存,這是根據分配的總內存大小確定的。在任何給定的時間, SM 上的駐留塊都可以訪問不同的內存頁,因為分配給每個塊的內存域很大。
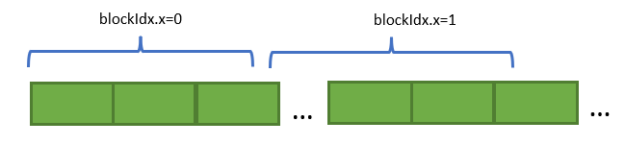
template<typename data_type>
__global__ void read_thread_blockCont(data_type *ptr, const size_t size)
{
size_t n = size / sizeof(data_type);
data_type accum = 0;
size_t elements_per_block = ((n + (gridDim.x - 1)) / gridDim.x) + 1;
size_t startIdx = elements_per_block * blockIdx.x;
for (size_t rid = threadIdx.x; rid < elements_per_block; rid += blockDim.x) {
if ((rid + startIdx) < n)
accum += ptr[rid + startIdx];
}
if (threadIdx.x == 0)
ptr[0] = accum;
}
隨機翹曲
在此訪問模式中,對于 warp 的每個循環迭代,選擇一個隨機頁面,然后訪問一個連續的 128B ( 4B 的 32 個元素)區域。這將導致線程塊的每個扭曲跨所有線程塊訪問隨機頁面。扭曲的循環計數由扭曲的總數和分配的總內存決定。

內核使用線程塊和網格參數啟動,以實現 100% 的占用率。內核的所有塊始終駐留在 GPU 上。
硬件設置
本文中的基準測試使用了以下三種不同硬件設置中的一種 GPU 。
| System | GPU architecture | GPU memory size | CPU-GPU Interconnect | Theoretical one-way interconnect bandwidth (GB/s) | Config name |
| DGX 1V | V100 | 32 GB | PCIe Gen3 | 16 | V100-PCIe3-x86 |
| DGX A100 | A100 | 40 GB | PCIe Gen4 | 32 | A100-PCIe4-x86 |
| IBM Power9 | V100 | 32 GB | NVLink 2.0 | 75 | V100-NVLink-P9 |
我們研究了不同的內存駐留技術,以提高這些訪問模式的超額訂閱性能。從根本上說,我們試圖消除統一內存頁錯誤,并找到最佳的數據分區策略,以獲得基準測試的最佳讀取帶寬。在本文中,我們將討論以下內存模式:
- 按需 MIG 定額
- Zero-copy
- CPU 和 GPU 之間的數據分區
在下面的部分中,我們將深入到性能分析和所有優化的解釋中。我們還討論了哪些工作負載能夠與統一內存一起很好地解決超額訂閱問題。
基線實施:按需 MIG 定額
在此測試用例中,使用cudaMallocManaged執行內存分配,然后按照以下方式在系統( CPU )內存上填充頁面:
cudaMallocManaged(&uvm_alloc_ptr, allocation_size);
// all the pages are initialized on CPU
for (int i = 0; i < num_elements; i++)
uvm_alloc_ptr[i] = 0.0f;
然后,執行 GPU 內核,并測量內核的性能:
read_thread<float><<<grid, block, 0, task_stream>>>((float*)uvm_alloc_ptr, allocation_size);
我們使用了上一節中描述的三種訪問模式之一。這是使用統一內存進行超額訂閱的最簡單方法,因為程序員不需要提示。
在內核調用時, GPU 嘗試訪問駐留在主機上的虛擬內存地址。這會觸發一個頁面錯誤事件,導致通過 CPU – GPU 互連將內存頁面 MIG 分配到 GPU 內存。內核性能受生成的頁面錯誤模式和 CPU – GPU 互連速度的影響。
頁面錯誤模式是動態的,因為它取決于流式多處理器上塊和扭曲的調度。然后是 GPU 線程發出的內存加載指令。

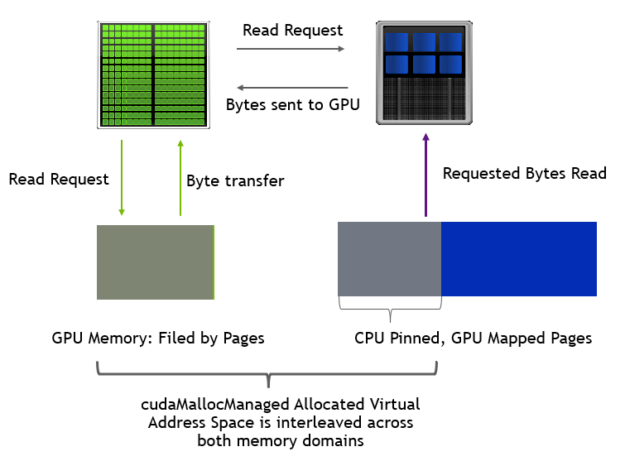
圖 5 顯示了如何在空 GPU 和超額訂閱 GPU 上處理頁面錯誤。在超額訂閱時,首先將內存頁從 GPU 內存移出到系統內存,然后將請求的內存從 CPU 轉移到 GPU 。

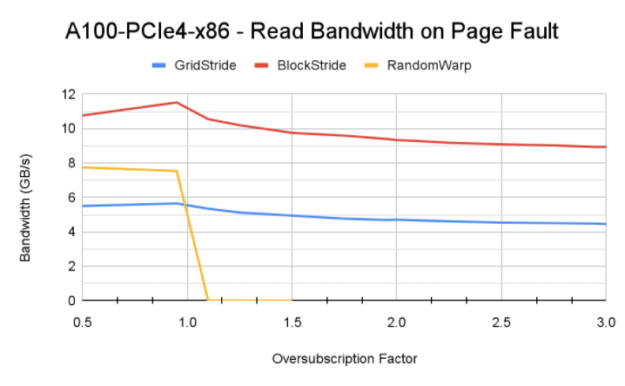
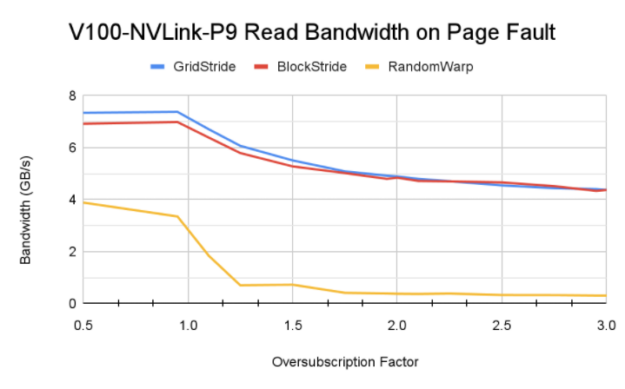
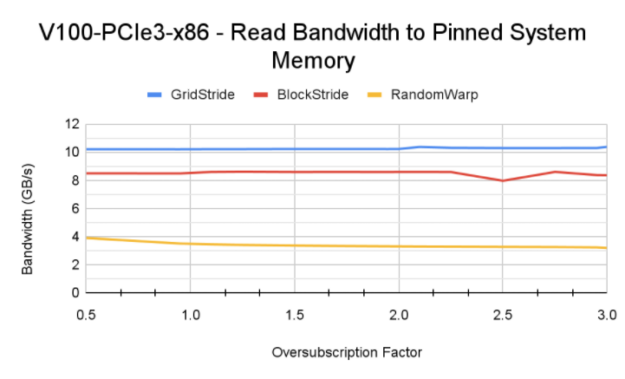
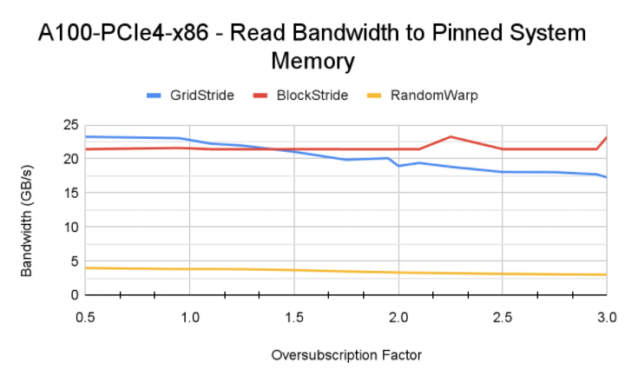
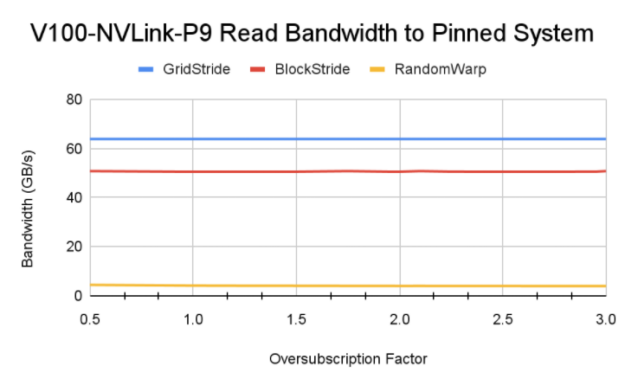
圖 6 顯示了使用 Power9 CPU 在 V100 、 A100 和 V100 上通過不同訪問模式獲得的內存帶寬。

順序存取分析
訪問模式和不同平臺之間頁面故障驅動的內存讀取帶寬的差異可以通過以下因素來解釋:
- 訪問模式的影響:傳統上,已知網格跨步訪問模式在訪問 GPU 駐留內存時可實現最大內存帶寬。這里,由于該模式生成的頁面錯誤通信量,塊跨步訪問模式實現了更高的內存帶寬。還值得注意的是, Power9 CPU 上的默認系統內存頁大小為 64 KB ,而 x86 系統上為 4 KB 。這有助于在觸發頁面錯誤事件時,統一內存錯誤 MIG 將較大的內存塊從 CPU 移動到 GPU 。
- 對 GPU 體系結構和互連的敏感性: DGX A100 在 CPU 和 GPU 之間具有更快的 PCIe Gen4 互連。這可能是 A100 實現更高帶寬的原因。然而,互連帶寬并不是飽和的。更高帶寬的主要因素是 A100 GPU 和 108 個流式多處理器可以產生更多的頁面錯誤,因為 GPU 上有更多的活動線程塊。 P9 測試也證實了這一理解,盡管 GPU – CPU 之間的 NVLink 連接理論峰值帶寬為 75 GB / s ,但讀取帶寬低于 A100 。
Tip:在這篇文章的實驗中,我們發現流式網格和塊跨步內核訪問模式對線程塊大小和塊內同步不敏感。但是,為了使用討論的其他優化方法獲得更好的性能,我們在一個塊中使用了 128 個線程,在每個循環展開時進行塊內同步。這確保了塊的所有扭曲有效地使用 SM 的地址轉換單元。要了解塊內同步的內核設計,請參閱本文發布的源代碼。嘗試使用不同塊大小的同步和不同步變體。
隨機存取分析
在 x86 平臺的超額訂閱域中,由于許多頁面錯誤以及由此產生的從 GPU 到 GPU 的內存 MIG 比率,隨機扭曲訪問模式僅產生幾百 KB / s 的讀取帶寬。由于訪問是隨機的,因此使用了 MIG 額定內存的一小部分。額定為 MIG 的內存可能最終被逐出回 CPU ,以便為其他內存片段騰出空間。
但是,在 Power9 系統上啟用了訪問計數器,從而從 GPU 進行 CPU 映射內存訪問,并且并非所有訪問的內存片段都立即被 MIG 評級為 GPU 。這導致了一致的內存讀取帶寬,與 x86 系統相比,內存抖動更少。
優化 1 :直接訪問系統內存(零拷貝)
除了通過互連將內存頁從系統內存移動到 GPU 內存之外,您還可以直接從 GPU 訪問固定系統內存。這種內存分配方法也稱為零拷貝內存。
可使用 CUDA API 調用cudaMallocHost或通過將虛擬地址范圍的首選位置設置為 CPU ,從統一內存接口分配固定系統內存。
cudaMemAdvise(uvm_alloc_ptr, allocation_size, cudaMemAdviseSetPreferredLocation, cudaCpuDeviceId); cudaMemAdvise(uvm_alloc_ptr, allocation_size, cudaMemAdviseSetAccessedBy, current_gpu_device);

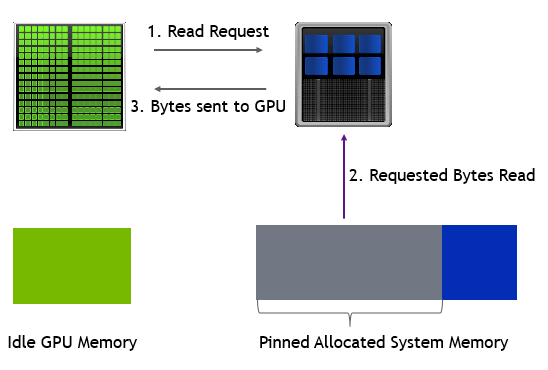
圖 9 顯示了讀內核實現的內存帶寬。在 x86 平臺上, A100 GPU 可以實現比 V100 更高的帶寬,因為 DGX A100 上 CPU 和 GPU 之間的 PCIe Gen4 互連速度更快。類似地, Power9 系統通過網格跨步訪問模式實現接近互連帶寬的峰值帶寬。 A100 GPU 上的網格跨步帶寬模式會隨著過度訂閱而降低,因為 GPU MMU 地址轉換未命中會增加加載指令的延遲。
對于所有測試的系統,隨機扭曲訪問在超額訂閱域中產生 3-4 GB / s 的恒定帶寬。這比前面介紹的故障驅動場景要好得多。
收獲
從數據中可以清楚地看出,零拷貝方法實現了比基線更高的帶寬。當您希望避免從 CPU 和 GPU 取消映射和映射內存時,固定系統內存是有利的。如果應用程序只使用分配的數據一次,那么使用零拷貝內存直接訪問更好。但是,如果應用程序中存在數據重用,則根據訪問模式和重用情況,對 GPU 的錯誤和 MIG 評級數據可以產生更高的聚合帶寬。
優化 2 :在 CPU – GPU 之間進行數據分區的直接內存訪問
對于前面解釋的故障驅動 MIG 比率, GPU MMU 系統在 GPU 上達到所需的內存范圍之前會出現額外的暫停開銷。為了克服這一開銷,您可以在 CPU 和 GPU 之間分配內存,并將內存從 GPU 映射到 CPU ,以便于無故障內存訪問。
在 CPU 和 GPU 之間分配內存有幾種方法:
- 為內存分配設置了
SetAccessedBy統一內存提示的cudaMemPrefetchAsyncAPI 調用。 - CPU 和 GPU 之間的手動混合內存分配,帶有手動預取和使用
SetPreferredLocation和SetAccessedBy提示。
我們發現,這兩種方法在許多訪問模式和體系結構組合中表現相似,只有少數例外。在本節中,我們主要討論手動頁面分發。您可以在unified-memory-oversubscription GitHub repo 中查找這兩者的代碼。
在混合內存分發中,很少有內存頁可以固定到 CPU ,并使用cudaMemAdvise API 調用將setAccessedBy提示設置為 GPU 設備顯式映射內存。在我們的測試用例中,我們以循環方式將多余的內存頁映射到 CPU ,其中到 CPU 的映射取決于 GPU 的超額訂閱量。例如,在超額訂閱因子值為 1 . 5 時,每三個頁面映射到 CPU 。超額認購系數為 2 . 0 時,每隔一頁將映射到 CPU 。
在我們的實驗中,內存頁設置為 2MB ,這是 GPU MMU 可以操作的最大頁大小。
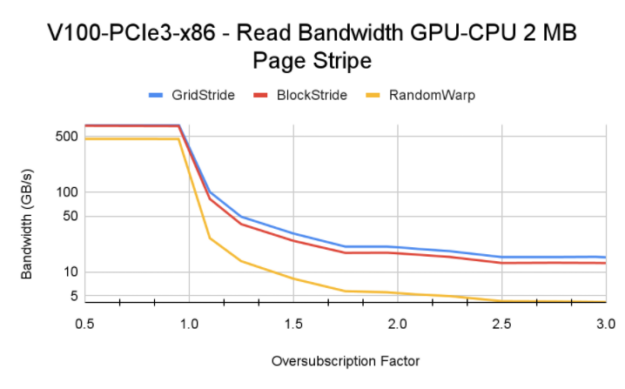
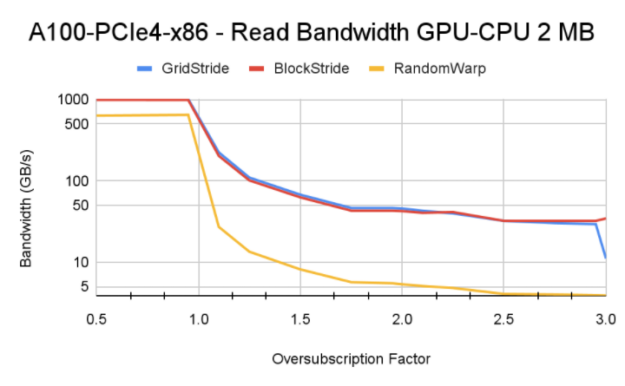
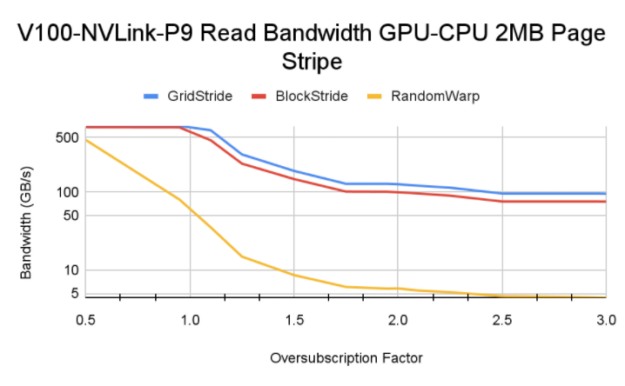
對于小于 1 . 0 的超額訂閱值,所有內存頁都駐留在 GPU 上。與超額認購率大于 1 . 0 的情況相比,您可以看到更高的帶寬。對于大于 1 . 0 的超額訂閱值,基本 HBM 內存帶寬和 CPU – GPU 互連速度等因素控制最終內存讀取帶寬。
Tip:在 Power9 系統上進行測試時,我們遇到了顯式大容量內存預取的有趣行為(選項 a )。因為在 P9 系統上啟用了訪問計數器,所以移出的內存并不總是固定在 GPU 上,統一內存驅動程序可以啟動從 CPU 到 GPU 的數據 MIG 分配。這將導致從 GPU 逐出,并且該循環將在內核的整個生命周期內持續。這個過程會對流塊和網格步長內核產生負面影響,并且它們比手動頁面分發獲得的帶寬更低。
解決方案:單一 GPU 超額認購
在使用統一內存的 GPU 超額訂閱的三種不同內存分配策略中,給定應用程序分配方法的最佳選擇取決于內存訪問模式和 GPU 內存的重用。
當您在故障和固定系統內存分配之間進行選擇時,后者在所有平臺和 GPU 上的性能始終更好。如果內存子區域的 GPU 駐留從總體應用程序速度中受益,那么 GPU 和 CPU 之間的內存頁分配是一種更好的分配策略。
嘗試統一內存優化
在這篇文章中,我們回顧了一個具有一些常見訪問模式的基準測試,并分析了從 x86 到 P9 ,以及 V100 和 A100 GPU s 的各種平臺上的性能。您可以使用這些數據作為參考來進行預測,并考慮在代碼中使用統一內存是否有益。我們還介紹了多種數據分布模式和統一內存模式,它們有時會帶來顯著的性能優勢。有關更多信息,請參閱 GitHub 上的unified-memory-oversubscription微基準源代碼。
在上一篇文章中,我們證明了基于統一內存的超額訂閱對大數據分析和大深度學習模型特別有效。請嘗試在代碼中使用統一內存進行超額訂閱,并讓我們知道它如何幫助您提高應用程序性能。
?