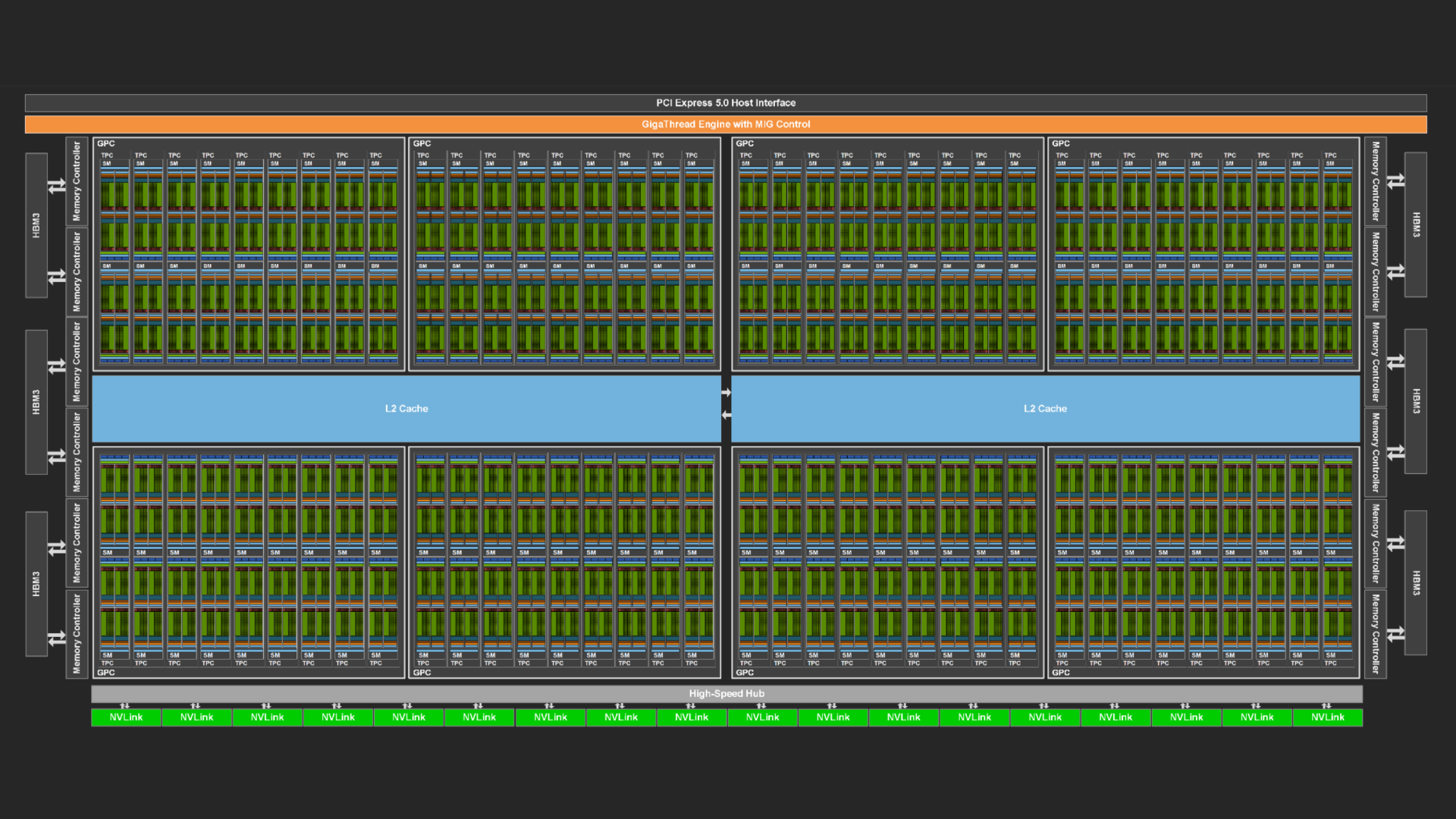
GPU 專為高速處理大量數據而設計。GPU 具有稱為流多處理器 (SM) 的大量計算資源,以及一系列可為其提供數據的設施:高帶寬內存、高大小數據緩存,以及在活躍的線程束用完時切換到其他線程束的能力,而不會產生任何開銷。
然而,數據乏現象可能仍會發生,許多代碼優化都集中在這個問題上。在某些情況下,SMs 不是數據乏,而是指令乏。本文介紹了對 GPU 工作負載的調查,該工作負載因指令緩存丟失而經歷了速度放慢。本文介紹了如何識別此瓶頸,以及消除瓶頸以提高性能的技術。
識別問題
這項研究的起源是基因組學領域的應用程序,在該領域中,必須解決與將 DNA 樣本的小部分與參考基因組進行比對相關的許多小的獨立問題。背景是眾所周知的 Smith-Waterman 算法(但這本身對討論并不重要)。
在強大的 NVIDIA H100 Hopper GPU 上,擁有 114 個 SM 的中型數據集上運行該程序顯示出了良好的前景。用于分析 GPU 上程序執行情況的 NVIDIA Nsight Compute 工具證實了 SM 非常忙碌于有用的計算,但存在一個障礙。
構成整體工作負載的許多小問題(每個問題都由自己的線程處理)可以在 GPU 上同時運行,因此并非所有計算資源都一直被充分利用。這表示為少量非整數波數。
GPU 工作被分割成稱為線程塊的塊,其中一個或多個線程塊可以駐留在一個 SM 上。如果某些 SM 收到的線程塊少于其他 SM,它們將用完工作,必須空閑,而其他 SM 繼續工作。
用線程塊完全填充所有 SM 構成一個波。NVIDIA Nsight Compute 會完整報告每個 SM 的波數。如果該數字恰好為 100.5,則表示并非所有 SM 的工作量相同,一些 SM 不得不空閑。但是,不均勻分布的影響并不大。
大多數時候,SM 上的負載是平衡的。例如,如果波的數量僅為 0.5,這種情況就會發生變化。在更大比例的時間里,SM 會經歷不均勻的工作分布,稱為尾部效應。
解決尾部效應
這種現象正是基因組學工作負載中出現的現象。波的數量只有 1.6。顯而易見的解決方案是讓 GPU 做更多的工作(更多線程,導致每個線程有 32 個線程的更多線程束),這通常不成問題。
原始工作負載相對較小,在實際環境中,必須完成更大的問題。但是,通過將子問題數量增加一倍、三倍和四倍來增加原始工作負載,會導致性能下降而非改善。這是什么原因導致這種結果?
這四種工作負載大小的 NVIDIA Nsight Compute 合并報告說明了相關情況。在名為 Warp State 的部分中,列出了線程無法進行處理的原因,無指令值隨著工作負載大小而顯著增加(圖 1)。

無指令意味著SM無法從內存中獲得足夠快的指令。長記分牌表明SM無法從內存中獲得足夠快的數據。及時獲取指令非常關鍵,因此GPU提供了許多工作站,在獲取指令后,可以在這些工作站放置指令,以使指令保持在SM附近。這些工作站稱為指令緩存,其級別甚至高于數據緩存。
由于無指令導致線程束停滯現象的快速增長,指令緩存丟失顯然也會快速增加,這表明以下幾點:
- 并非代碼最繁忙部分的所有指令都適合該緩存。
- 隨著工作負載大小的增加,對更多不同指令的需求也在增加。
后者的原因有些微妙。由warp組成的多個線程塊同時駐留在SM上,但并非所有warp同時執行。SM內部分為四個分區,每個分區通常可以在每個時鐘周期執行一條warp指令。
當 warp 由于任何原因停止運行時,同樣駐留在 SM 上的另一個 warp 可以接管。每個 warp 都可以獨立于其他 warp 執行自己的指令流。
在此程序的主內核開始時,在每個 SM 上運行的線程束大多數都是同步的。它們從第一個指令開始并持續不斷。但是,它們沒有明確同步。
隨著時間的推移,線程束輪流閑置和執行,它們在執行指令方面的距離越來越遠。這意味著隨著執行的進展,必須激活越來越多的不同指令集,這反過來意味著指令緩存溢出的頻率更高。指令緩存壓力增加,并且丟失次數更多。
解決問題
除非通過同步流,否則無法控制 warp 指令流的逐漸分離。但同步通常會降低性能,因為在沒有基本需求的情況下,它需要 warp 相互等待。
但是,您可以嘗試減少整體指令占用空間,以減少指令緩存溢出的頻率,甚至可能根本不會發生溢出。
相關代碼包含一個嵌套循環集合,大多數循環是展開的。展開通過讓編譯器執行以下操作來提高性能:
- 重新排序 (獨立) 指令以更好地調度。
- 刪除一些可以通過循環的連續迭代共享的指令。
- 減少分支。
- 將同一變量在不同循環迭代中的引用分配給不同的寄存器,以避免等待特定寄存器變得可用。
展開循環具有許多好處,但它確實會增加指令數量。它還往往會增加使用的寄存器數量,這可能會降低性能,因為 SM 上同時駐留的線程束較少。這種減少的線程束占用降低了延遲隱藏能力。
內核的兩個最外圍的循環是重點。實際展開最好由編譯器來完成,編譯器有大量啟發式算法來生成良好的代碼。那就是說,用戶通過在循環頂部之前使用提示(在 C/C++ 中稱為 pragmas)來表達展開預期的好處。
它們采用以下形式:
#pragma unroll X |
在哪里X可以為空 (規范展開),編譯器只被告知展開可能是有益的,但沒有給出要展開多少次迭代的任何建議。
為方便起見,我們對展開系數采用了以下表示法:
- 0 = 完全無需卸載。
- 1 = 不含任何數字的展開實用程序 (規范)。
n大于 1 = 正數,表示以?n?次迭代組展開。
#pragma unroll (n) |
下一個實驗包括一組運行,其中代碼中兩個最外圍循環的unroll factor在 0 和 4 之間變化,從而為四種工作負載大小的每個級別生成性能圖。不需要展開更多,因為實驗表明編譯器不會為該特定程序的更高unroll factor生成不同的代碼。圖 2 顯示了套件的結果。

頂部水平軸顯示最外層循環(頂層)的unroll factors。底部水平軸顯示二級循環的unroll factors。四條性能曲線中任何一條(越高越好)上的每個點都對應兩個unroll factors,每個最外層循環各對應一個系數,如水平軸所示。
圖 2 還顯示了每個展開因子實例的可執行文件大小 (以 500 KB 為單位)。雖然預期可執行文件大小會隨著展開級別的提升而增加,但情況并非如此。展開pragma 是一些提示,如果編譯器認為這些提示不有益,則可能會被編譯器忽略。
與代碼初始版本(由標記為 A 的橢圓表示)對應的測量用于規范展開頂層循環,而非展開二級循環。代碼的異常行為顯而易見,由于指令緩存丟失增加,工作負載規模越大,性能越差。
在下一個單獨的實驗(由標記為 B 的橢圓表示)中,在全套運行之前嘗試了既不展開最外圍的循環。現在,異常行為消失了,更大的工作負載大小會導致預期的性能更好。
但是,絕對性能降低,尤其是對于原始工作負載大小而言。NVIDIA Nsight Compute 揭示的兩種現象有助于解釋這一結果。由于指令內存占用較小,各種大小的工作負載的指令緩存丟失都減少了,這可以從無指令線程束停滯(未說明)已下降到幾乎可以忽略不計的值來推斷。但是,編譯器為每個線程分配了相對較多的寄存器,因此可以駐留在 SM 上的線程束數量并非最佳。
對展開系數進行全面掃描表明,標記為 C 的橢圓中的實驗是眾所周知的亮點。它對應于頂層循環的不展開,以及第二層循環的 2 倍展開。NVIDIA Nsight Compute 仍然顯示無指令線程束停滯(圖 3)的值可以忽略不計,并且每個線程的寄存器數量減少,因此 SM 上可以容納的線程數比實驗 B 多,從而導致更多的延遲隱藏。

雖然最小工作負載的絕對性能仍然落后于實驗 A,但差別不大,而且更大的工作負載的表現越來越好,從而在所有規模的工作負載中實現最佳的平均性能。
對 NVIDIA Nsight Compute 報告中三種不同的展開場景 (A、B 和 C) 的進一步檢查闡明了性能結果。
如圖 2 中的虛線所示,總指令顯存占用大小并不能準確衡量指令緩存壓力,因為它們可能包含僅執行幾次的代碼段。最好研究代碼中“最熱門”部分的聚合大小,這可以通過在 NVIDIA Nsight Compute 的源視圖中查找“Instructions Executed”指標的最大值來識別這些部分。
對于場景 A、場景 B 和場景 C,這些大小分別為 39360、15680 和 16912。顯然,與場景 A 相比,場景 B 和場景 C 的熱指令內存占用空間大大降低,從而降低指令緩存壓力。
結束語
指令緩存丟失會導致指令占用空間較大的核函數的性能下降,而這通常是由大量循環展開引起的。當編譯器通過pragma負責展開時,它對代碼應用啟發式算法以確定最佳實際展開級別,這是必然復雜的,而且程序員并不總是可以預測的。
不妨嘗試不同的編譯器循環展開提示,以獲得具有良好線程束占用和減少指令緩存丟失的最佳代碼。
立即開始使用 Nsight Compute。有關更多信息和教程,請參閱 Nsight 開發者工具教程。
?