
今天的前沿 高性能計算 ( HPC )系統包含數以萬計的 GPU 。在 NVIDIA 系統中, GPU 通過 NVLink 擴展互連在節點上連接,并通過 InfiniBand 等擴展網絡跨節點連接。 GPU 用于并行通信、共享工作和高效運行的軟件庫統稱為 NVIDIA Magnum IO ,是用于并行、異步和智能數據中心 IO 的架構。
對于許多應用,擴展到這樣的大型系統需要 GPU 之間的細粒度通信的高效率。這對于以強伸縮性為目標的工作負載尤其重要,因為在工作負載中添加了計算資源以減少解決給定問題的時間。
NVIDIA Magnum IO NVSHMEM 是一個基于 OpenSHMEM 規范的通信庫,它為 HPC 系統中所有 GPU 的存儲器提供分區全局地址空間( PGAS )數據訪問模型。
由于該庫支持 GPU 集成通信,因此對于以強擴展為目標的工作負載而言,它是一個特別適合且高效的工具。在這個模型中,數據是通過單邊讀、寫和原子更新通信例程訪問的。
由于與 GPU 架構緊密集成,該通信模型通過 NVLink 實現了細粒度數據訪問的高效率。然而,由于主機 CPU 需要管理通信操作,因此節點間數據訪問的高效率仍然是一個挑戰。
本文在 NVSHMEM 中介紹了一種新的通信方法,稱為 InfiniBand GPUDirect 異步( IBGDA ) ,它建立在 GPUDirect Async 系列技術之上。 IBGDA 在 NVSHMEM 2.6.0 中引入,并在 NVSHMEM 2.7.0 和 2.8.0 中進行了顯著改進。它使 GPU 在發出節點間 NVSHMEM 通信時繞過 CPU ,而不會對現有應用程序進行任何更改。如我們所示,這將顯著提高使用 NVSHMEM 的應用程序的吞吐量和擴展能力。
代理啟動的通信
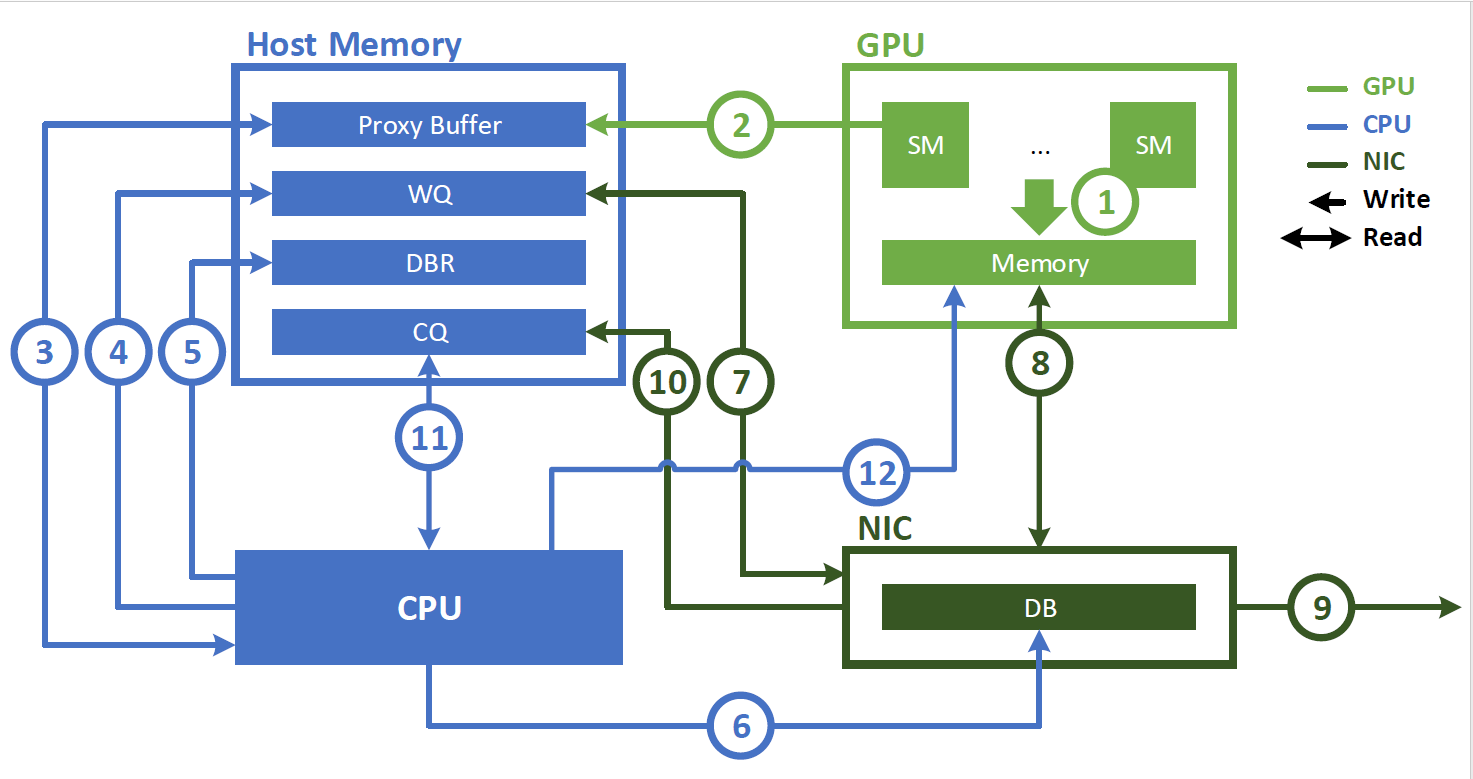
使用 NVLink 進行節點內通信可以通過 GPU 流式多處理器( SM )啟動的加載和存儲指令實現。然而,節點間通信涉及向網絡接口控制器( NIC )提交工作請求以執行異步數據傳輸操作。
在引入 IBGDA 之前, NVSHMEM InfiniBand Reliable Connection ( IBRC )傳輸使用 CPU 上的代理線程來管理通信(圖 1 )。使用代理線程時, NVSHMEM 執行以下操作序列:
- 應用程序啟動 CUDA 內核,在 GPU 內存中生成數據。
- 應用程序調用 NVSHMEM 操作(例如
nvshmem_put)以與另一個處理元件( PE )通信。當執行細粒度或重疊通信時,可以在 CUDA 內核內調用此操作。 NVSHMEM 操作將工作描述符寫入主機內存中的代理緩沖區。 - NVSHMEM 代理線程檢測工作描述符并啟動相應的網絡操作。
以下步驟描述了與 NVIDIA InfiniBand 主機通道適配器( HCA )(如 ConnectX-6 HCA )交互時代理線程執行的操作順序:
- CPU 創建一個工作描述符,并將其排入工作隊列( WQ )緩沖區,該緩沖區位于主機內存中。
- 此描述符指示請求的操作(如 RDMA 寫入),并包含源地址、目標地址、大小和其他必要的網絡信息。
- CPU 更新主機內存中的門鈴記錄( DBR )緩沖區。此緩沖區用于恢復路徑,以防 NIC 將寫入數據丟棄到其門鈴( DB )。
- CPU 通過向其 DB ( NIC 硬件中的寄存器)寫入來通知 NIC 。
- NIC 從 WQ 緩沖區讀取工作描述符。
- NIC 使用 GPUDirect RDMA 直接從 GPU 內存復制數據。
- NIC 將數據傳輸到遠程節點。
- NIC 通過將事件寫入主機存儲器上的完成隊列( CQ )緩沖區來指示網絡操作已完成。
- CPU 輪詢 CQ 緩沖器以檢測網絡操作的完成。
- CPU 通知 GPU 操作已完成。如果存在 GDRCopy ,則直接將通知標志寫入 GPU 存儲器。否則,它會將該標志寫入代理緩沖區。 GPU 在相應的存儲器上輪詢工作請求的狀態。
雖然這種方法是便攜式的,可以為批量數據傳輸提供高帶寬,但它有兩個主要缺點:
- CPU 周期被代理線程連續消耗。
- 由于代理線程存在瓶頸,您無法達到細粒度傳輸的 NIC 吞吐量峰值。現代 NIC 每秒可以處理數以億計的通信請求。雖然 GPU 可以以這種速度生成請求,但 CPU 代理的處理速度要低幾個數量級,這為細粒度通信模式造成了瓶頸。
InfiniBand GPUDirect 異步
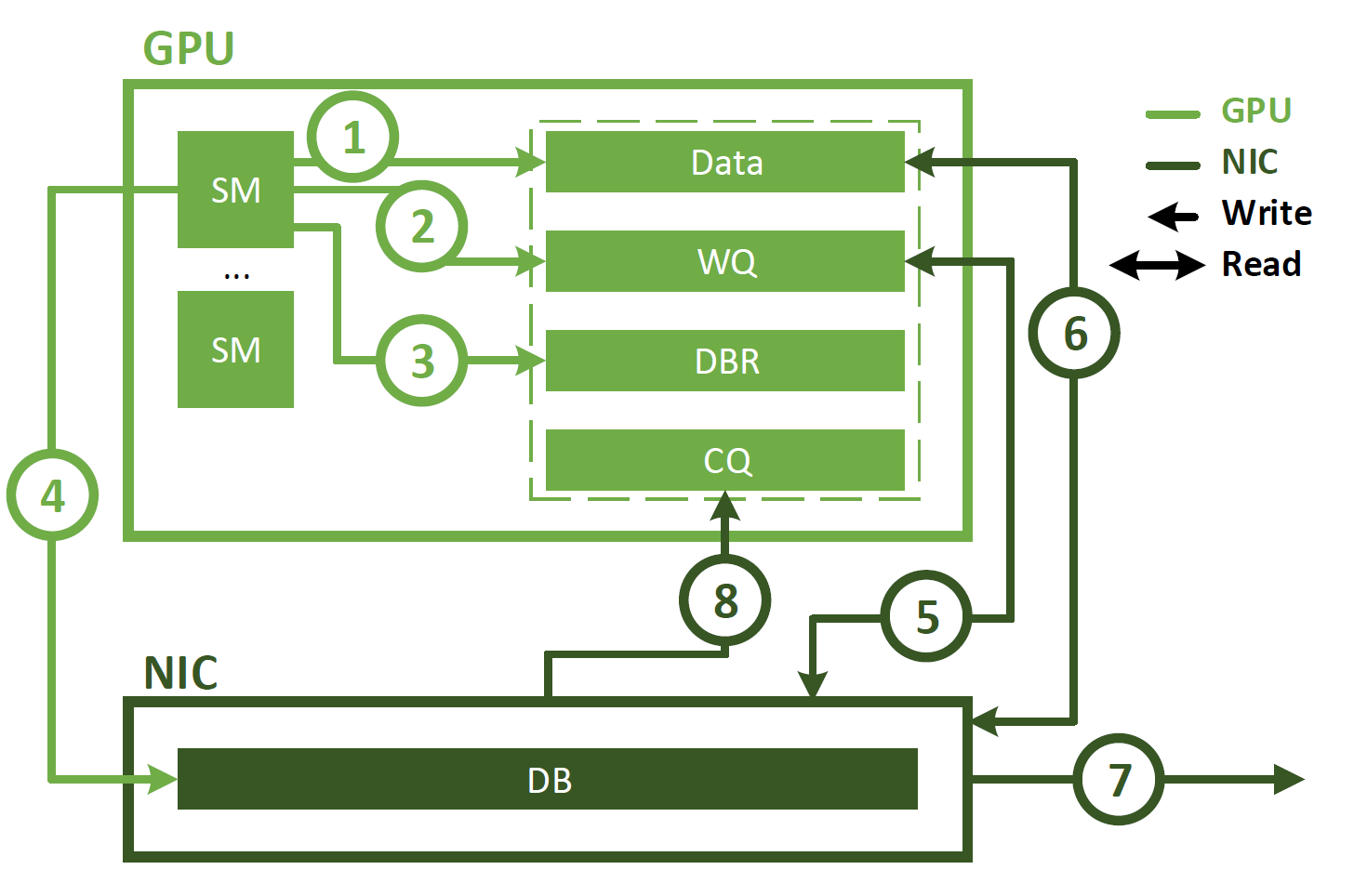
與代理啟動的通信不同, IBGDA 使用 GPUDirect Async – Kernel initiated ( GPUDirectAsync – KI )使 GPU SM 能夠直接與 NIC 交互。這如圖 2 所示,涉及以下步驟。
- 應用程序啟動 CUDA 內核,在 GPU 內存中生成數據。
- 應用程序調用 NVSHMEM 操作(如
nvshmem_put)以與另一個 PE 通信。 NVSHMEM 操作使用 SM 創建 NIC 工作描述符,并將其直接寫入 WQ 緩沖區。與 CPU 代理方法不同,此 WQ 緩沖區駐留在 GPU 內存中。 - SM 更新 DBR 緩沖區,該緩沖區也位于 GPU 存儲器中。
- SM 通過寫入 NIC 的 DB 寄存器來通知 NIC 。
- NIC 使用 GPUDirect RDMA 讀取 WQ 緩沖區中的工作描述符。
- NIC 使用 GPUDirect RDMA 讀取 GPU 內存中的數據。
- NIC 將數據傳輸到遠程節點。
- NIC 通過使用 GPUDirect RDMA 寫入 CQ 緩沖區來通知 GPU 網絡操作已完成。
如圖所示, IBGDA 從通信控制路徑中消除了 CPU 。使用 IBGDA 時, GPU 和 NIC 直接交換通信所需的信息。 WQ 和 DBR 緩沖區也移動到 GPU 存儲器,以提高 SM 訪問時的效率,同時保留 NIC 通過 GPUDirect RDMA 的訪問。
Magnum IO NVSHMEM 評估
我們比較了 NVSHMEMIBGDA 傳輸和 NVSHMEMIBRC 傳輸的性能,后者使用代理線程來管理通信。這兩種傳輸都是標準 NVSHMEM 分發的一部分。所有基準測試和案例研究均在通過 NVIDIA ConnectX-6 200 Gb / s InfiniBand 網絡和 NVIDIA Quantum HDR 交換機連接的四臺 DGX-A100 服務器上運行。
為了突出 IBGDA 的效果,我們禁用了通過 NVLink 的通信。即使 PE 位于同一節點上,這也會強制通過 InfiniBand 網絡執行所有傳輸。
單面輸入帶寬
我們首先運行了shmem_put_bw基準測試,該測試包含在 NVSHMEM 性能測試套件中,并使用nvshmem_double_put_nbi_block發布數據傳輸。該測試測量使用單邊寫入操作在一系列通信參數上傳輸固定數量的總數據時所獲得的帶寬。
對于節點間傳輸,此操作在執行網絡通信時使用線程塊中的一個線程,而不管線程塊中有多少線程。這是已知的,也稱為協作線程陣列( CTA )。在不同的 DGX-A100 節點上啟動了兩個 PE 。設置為每個線程塊一個線程,每個線程塊有一個 QP ( NIC 隊列對,包含 WQ 和 CQ )。
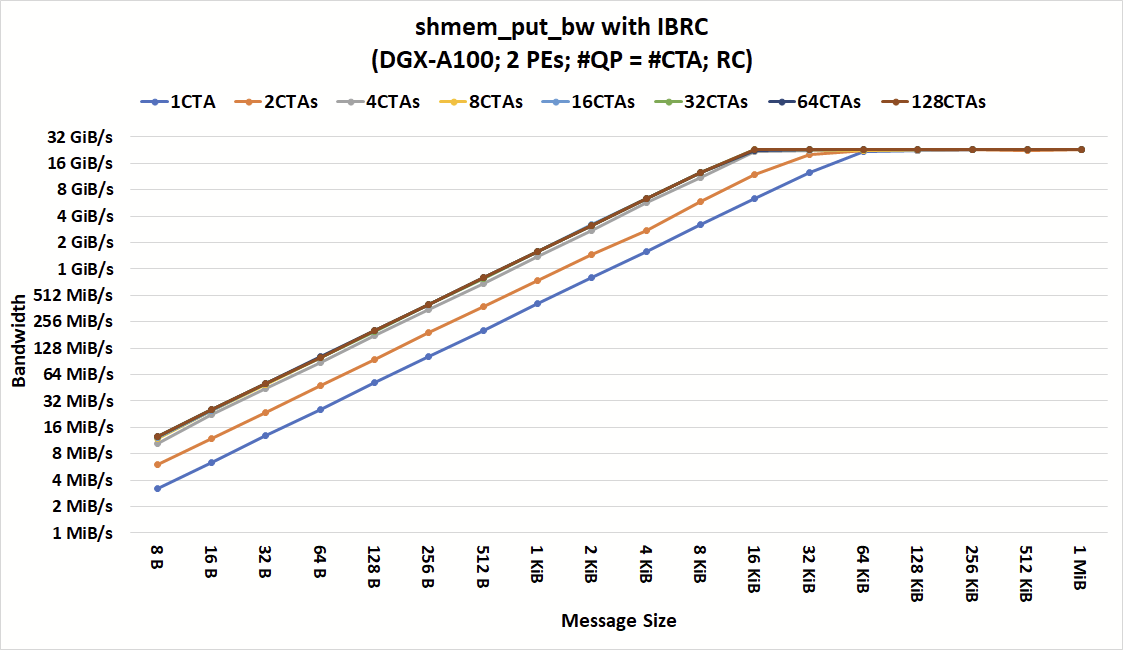
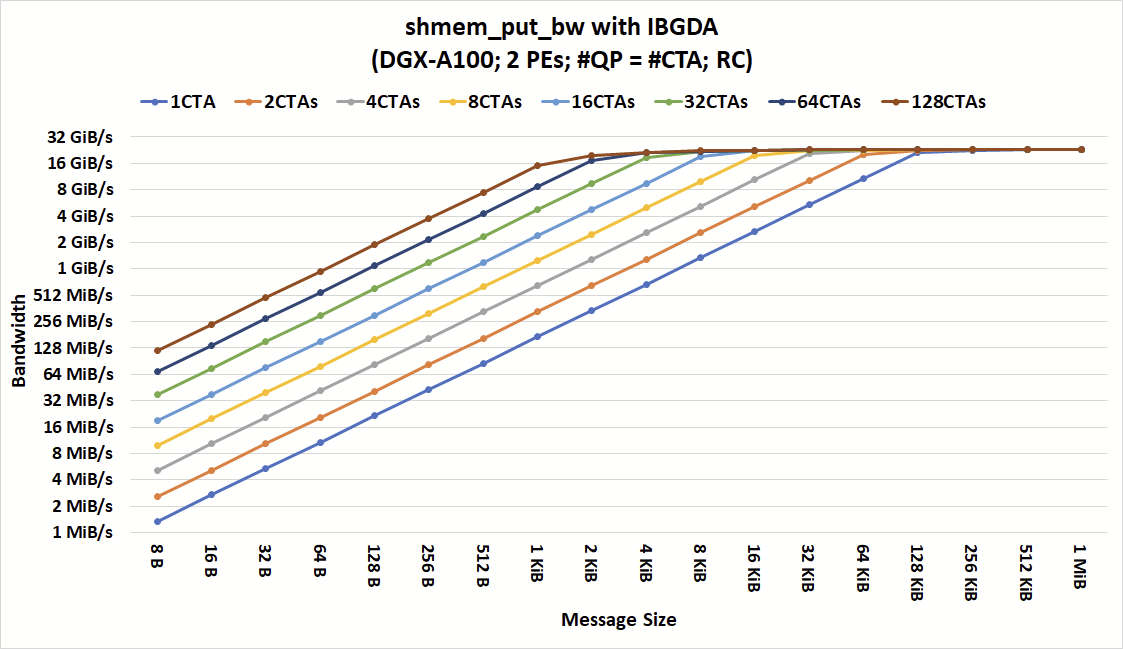
圖 3 和圖 4 顯示了在不同數量的 CTA 和消息大小下,具有 IBRC 和 IBGDA 的shmem_put_bw的帶寬。如圖所示,對于具有大消息的粗粒度通信, IBGDA 和 IBRC 都可以達到峰值帶寬。當應用程序發出來自至少四個 CTA 的通信時, IBRC 可以用小到 16KiB 的消息使網絡飽和。
進一步增加 CTA 的數量不會減少我們觀察到峰值帶寬時的最小消息大小。限制較小消息帶寬的瓶頸在 CPU 代理線程中。雖然這里沒有顯示,但我們也嘗試增加 CPU 代理線程的數量,并觀察到類似的行為。
通過消除代理瓶頸,當 64 個 CTA 發出通信時, IBGDA 實現了峰值帶寬,消息小到 2 KiB 。這一結果突出了 IBGDA 支持更高級別通信并行性的能力以及由此帶來的性能改進。
對于 IBRC 和 IBGDA ,每個 CTA 中只有一個線程參與網絡操作。換句話說,只需要 64 個線程(而不是 1024 × 64 個線程)就可以在 2 KiB 消息大小下實現峰值帶寬。
還表明, IBGDA 帶寬繼續隨著執行通信的 CTA 的數量而擴展,而 IBRC 代理在四個 CTA 時達到其擴展極限。因此, IBGDA 為消息大小小于 1 KiB 的 NVSHMEM 塊放入操作提供了高達 9.5 倍的吞吐量。
提高小郵件的吞吐量
shmem_p_bw基準使用標量nvshmem_double_p操作將數據直接從 GPU 寄存器發送到遠程 PE 。此操作是線程范圍的,這意味著調用此操作的每個線程都傳輸一個 8 字節的數據字。
在接下來的實驗中,我們為每個 CTA 啟動了 1024 個線程,并增加了 CTA 的數量,同時保持 QPs 的數量與 CTA 的數目相等。
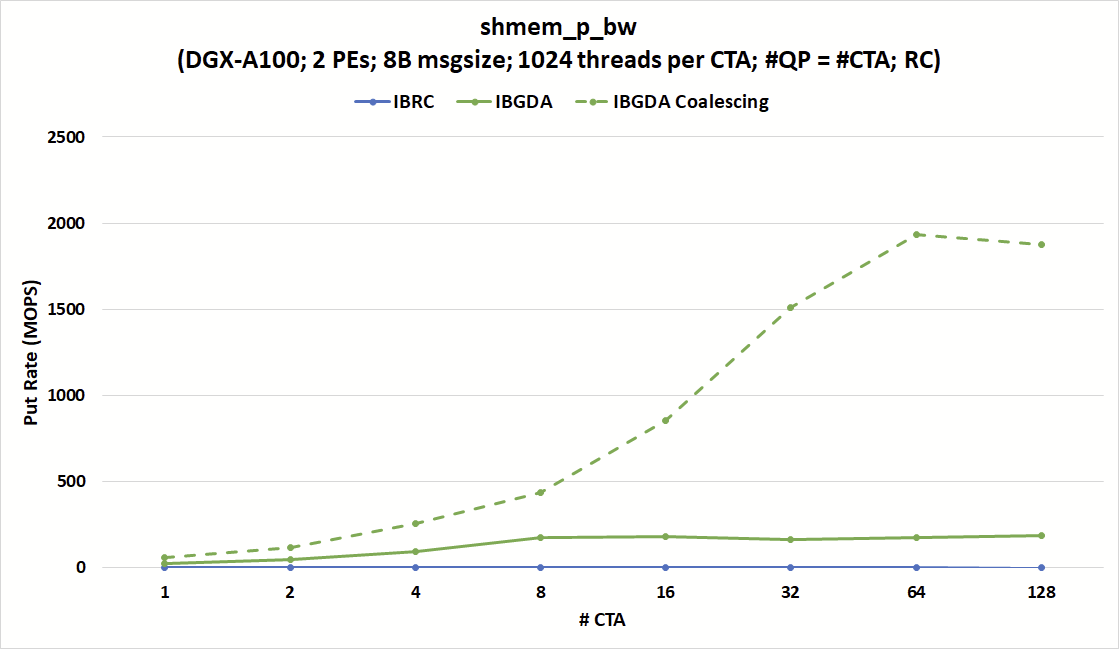
另一方面, IBGDA 的 put 速率可以達到 180 MOPS ,接近 215 MOPS 的峰值 NIC 消息速率限制。該圖還顯示,如果滿足聚結條件, IBGDA 可以達到幾乎 2000 MOPS 。
圖 5 顯示,無論 CTA 和 QP 的數量如何, IBRC 的投入率(單位:百萬次操作/秒( MOPS ))上限為 1.7 MOPS 左右。另一方面, IBGDA 的消息速率隨著 CTA 的數量而增加,接近 NVIDIA ConnectX-6 InfiniBand NIC 的 215 MOPS 硬件限制,只有 8 個 CTA 。
在該配置中, IBGDA 會根據nvshmem_double_p操作向 NIC 發出一個工作請求。這突出了 IBGDA 在涉及大量小消息的細粒度通信中的優勢。
IBGDA 還提供了當目標地址在同一扭曲內連續時的自動數據合并。此功能允許發送一條大消息,而不是 32 條小消息。對于希望將分散的數據直接從 GPU 寄存器傳輸到目的地的連續緩沖區的應用程序來說,它非常有用。
圖 5 顯示了當滿足數據合并條件時, put 速率可以達到超過 NIC 峰值消息速率。
Jacobi 方法案例研究
分析了 NVSHMEM Jacobi 基準 的性能,以證明 IBGDA 在實際應用中的性能與 IBRC 相比。該存儲庫包括 Jacobi 解算器的兩個 NVSHMEM 實現。
在第一個實現中,每個線程使用標量nvshmem_p操作在數據可用時立即發送數據。眾所周知,該實現與 NVLink 配合使用效果良好,但與 IBRC 配合使用效果不佳。
第二種實現在每個 CTA 調用nvshmem_put_nbi_block以發起通信之前將數據聚合到連續的 GPU 緩沖器中。這種數據聚合技術與 IBRC 配合使用很好,但增加了 NVLink 上的開銷,其中nvshmem_p操作可以將數據從寄存器直接存儲到遠程 PE 的緩沖區。這種不匹配突出了優化給定代碼以實現放大和縮小時的一個挑戰。
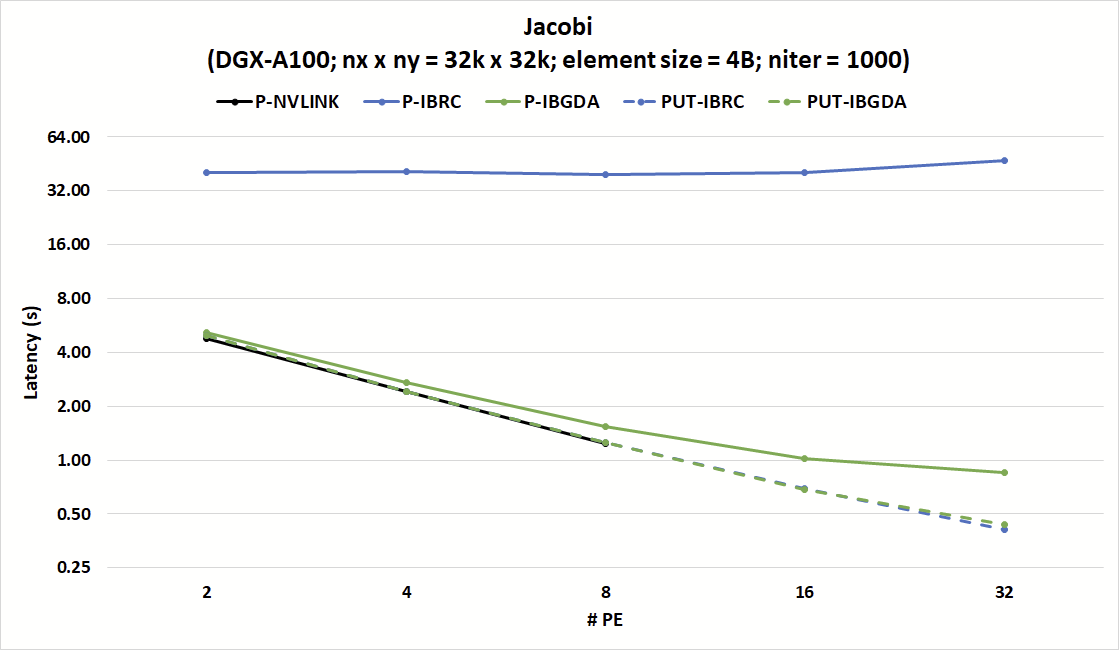
圖 6 顯示, IBGDA 對小消息通信效率的改進有助于解決這些挑戰。該圖表顯示了強縮放實驗中 Jacobi 內核 1000 次迭代的延遲,其中 PE 的數量增加,同時保持固定的矩陣大小。使用 IBRC ,nvshmem_p版本的 Jacobi 的延遲是 nvshmem _ put 版本的 8 倍多。
另一方面,nvshmem_p和nvshmem_put版本均與 IBGDA 兼容,并與 NVLink 上nvshmem_p的效率相匹配。 IBGDA nvshmem_p版本與nvshmem_put與 IBRC 的延遲相匹配。
結果表明,與nvshmem_put相比,具有 IBGDA 的nvshmem_p具有略高的延遲。這是因為與發送許多小消息相比,發送一條大消息會導致較低的網絡開銷。
雖然這些開銷是網絡的基礎,但 IBGDA 可以通過并行向 NIC 提交許多小消息傳輸請求來使應用程序隱藏這些開銷。
全對全延遲案例研究
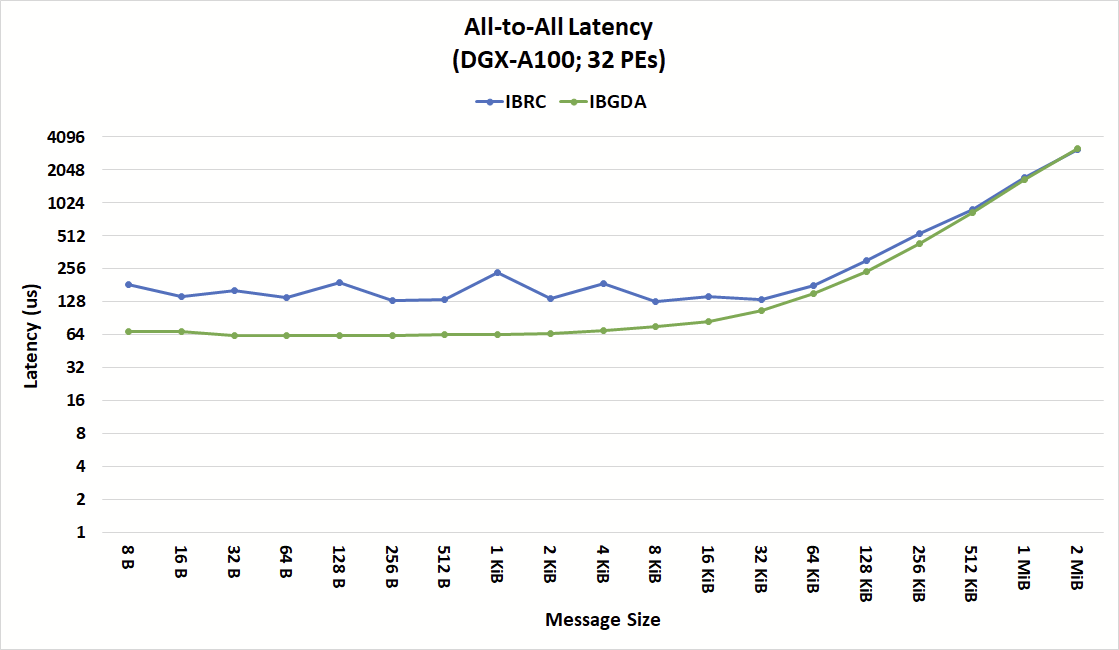
圖 7 顯示了 IBRC 和 IBGDA 的 NVSHMEM 所有對所有集合操作的延遲,突出了 IBGDA 在小消息性能方面的優勢。
對于 IBRC ,代理線程是來自設備的所有操作的序列化點。代理線程成批處理請求以減少開銷。然而,根據何時向設備提交操作,在設備上幾乎同時提交的操作可能會由代理線程的單獨循環處理。
代理的操作串行化會產生額外的延遲,并掩蓋 NIC 和 GPU 的內部并行性。 IBGDA 結果顯示總體延遲更為一致,尤其是對于小于 16KiB 的消息。
Magnum IO NVSHMEM 提高了網絡性能
在本博客中,我們展示了 Magnum IO 如何提高小消息網絡性能,尤其是對于部署在 HPC 數據中心數百或數千個節點上的大型應用程序。 NVSHMEM 2.6.0 引入了 InfiniBand GPUDirect Async ,它使 GPU 的 SM 能夠直接向 NIC 提交通信請求,繞過 CPU 在 NVIDIA InfiniBand 網絡上進行網絡通信。
與管理通信的代理方法相比, IBGDA 可以在更小的消息大小下保持顯著更高的吞吐量。這些性能改進對于需要強大擴展性的應用程序尤其重要,并且隨著工作負載擴展到更大數量的 GPU ,消息大小往往會縮小。
IBGDA 還縮小了 NVLink 和網絡通信之間的小消息吞吐量差距,使您更容易優化代碼,以在當今 GPU 加速的 HPC 系統上進行擴展和擴展。
?






