涉及基于人工智能的實時云規模應用程序計算機視覺正在迅速增長。用例包括圖像理解、內容創建、內容審核、映射、推薦系統和視頻會議。
然而,由于對處理復雜性的需求增加,這些工作負載的計算成本也在增長。從靜止圖像到視頻的轉變現在也正在成為消費者互聯網流量的主要組成部分。鑒于這些趨勢,迫切需要構建高性能但具有成本效益的計算機視覺工作負載。
基于人工智能的計算機視覺管道通常涉及圍繞人工智能推理模型的數據預處理和后處理步驟,這可能占整個工作負載的 50-80% 。這些步驟中常見的運算符包括以下內容:
- 調整大小
- 裁剪
- 正火
- 去噪
- 張量轉換
雖然開發人員可能會使用 NVIDIA GPU 來顯著加速他們管道中的人工智能模型推理,但預處理和后處理仍然通常使用基于 CPU 的庫來實現。這導致整個人工智能管道的性能出現瓶頸。通常是人工智能圖像或視頻處理管道一部分的解碼和編碼過程也可能在 CPU 上受到瓶頸,影響整體性能。
CV-CUDA 優化
CV-CUDA是一個開源庫,使您能夠構建高效的云級人工智能計算機視覺管道。該庫提供了一組專門的 GPU 加速計算機視覺和圖像處理內核,作為獨立的操作員,可以輕松實現人工智能管道的高效預處理和后處理步驟。
CV-CUDA 可以用于各種常見的計算機視覺管道,如圖像分類、對象檢測、分割和圖像生成。有關詳細信息,請參閱NVIDIA GTC Fall 2022 的主題發布。
在這篇文章中,我們展示了使用 CV- CUDA 為典型的人工智能計算機視覺工作負載實現端到端 GPU 加速的好處,實現了約 5 倍至 50 倍的總吞吐量加速。這可以每年節省數億 USD 的云成本,并在數據中心每年節省數百 GWh 的能源消耗。
CPU 加速解決的瓶頸
CV- CUDA 提供高度優化的 GPU 加速內核,作為計算機視覺處理的獨立操作符。這些內核可以有效地實現預處理和后處理流水線,從而顯著提高吞吐量。
編碼和解碼操作也可能是管道中的潛在瓶頸。通過優化NVIDIA 視頻處理框架( VPF ),您也可以有效地優化和運行它們。 VPF 是 NVIDIA 的一個開源庫,與 Python 綁定到 C ++庫。它為 GPU 上的視頻解碼和編碼提供了全硬件加速。
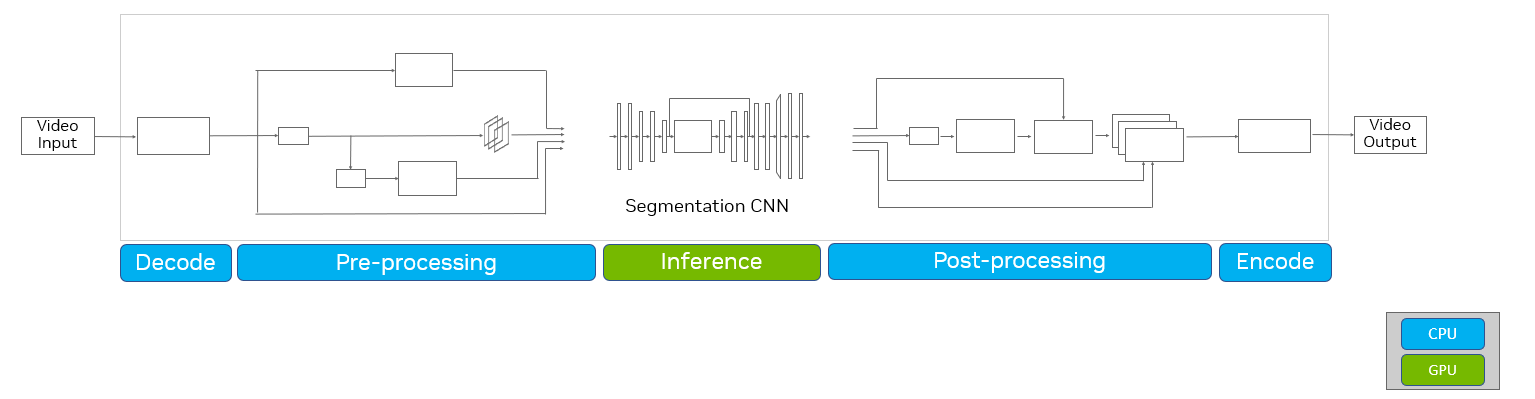
為了加速 GPU 上的整個端到端 AI 流水線(圖 2 ),請使用 CV- CUDA ,以及用于解碼/編碼加速的 VPF 和用于進一步推理優化的 TensorRT 。您可以通過四個端口實現高達 50 倍的端到端吞吐量改進NVIDIA L4 GPUs,與典型管道中基于 CPU 的實現相比。
改進程度取決于推理 DNN 的復雜性、所需的預處理和后處理步驟以及硬件等因素。對于多個 GPU 節點,對于給定的管道,加速因子可以線性縮放。
CV-CUDA 如何實現高性能
CV-CUDA 使用 GPU 的功率來實現高性能:
- 預先分配的內存池,以避免在推理階段重復分配 GPU 內存
- 異步操作
- 內核融合實現使用一個 GPU 內核的運算符組合,以最大限度地減少不必要的數據傳輸和內核啟動延遲
- 通過矢量化全局內存訪問和使用快速共享內存提高內存訪問效率
- 計算效率、快速數學、減少扭曲/塊
案例研究:視頻分割流水線的端到端加速
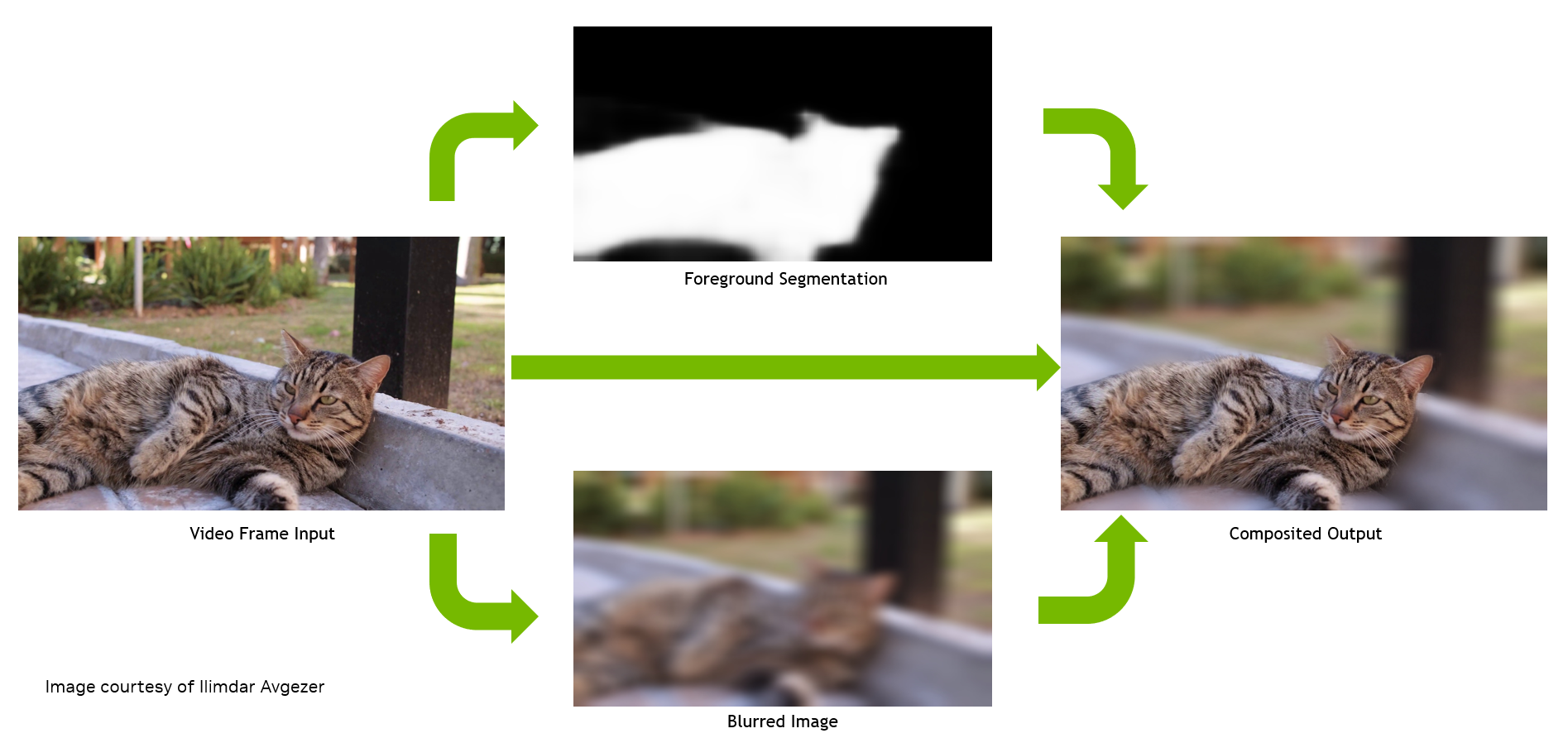
基于視頻的分割是一種常見的人工智能技術,它根據像素的屬性對視頻幀中的像素進行分割。例如,在視頻會議中的虛擬背景或背景模糊應用程序中,它對前景人物或對象和背景進行分割。
在這項研究中,我們討論了使用NVIDIA T4AWS 上的張量核心 GPU 實例,特別關注計算成本優化。連接到實例的 CPU 是 Intel Xeon Platinum 8362 。
當整個端到端 AI 管道在 GPU 上執行時,您可以預期顯著的成本節約。然后,我們討論了相同工作負載的吞吐量性能加速對數據中心能耗的影響。
為了進行實驗,我們將 GPU 與 CV-CUDA AI 管道與同一管道的 CPU 與 OpenCV 實現進行了比較,假設兩種情況下的推理工作負載都在 GPU 上運行。具體而言,我們部署了 ResNet-101 視頻分割模型管道(圖 2 ),以執行 AI 背景模糊。
在這種情況下,我們測量了不同階段的延遲和整個端到端管道的最大吞吐量。該管道包括多個階段(圖 4 ):
- 視頻解碼
- 使用“縮小”、“規格化”和“重新格式化”等操作進行預處理
- 使用 PyTorch 進行推斷
- 使用 Reformat 、 Upscale 、 BilateralFilter 、 Composition 和 Blur 等操作進行后處理
- 視頻編碼
對于 CPU 和 GPU 管道,我們假設推理工作負載分別使用 PyTorch 和 TensorRT 在 GPU ‘上運行。
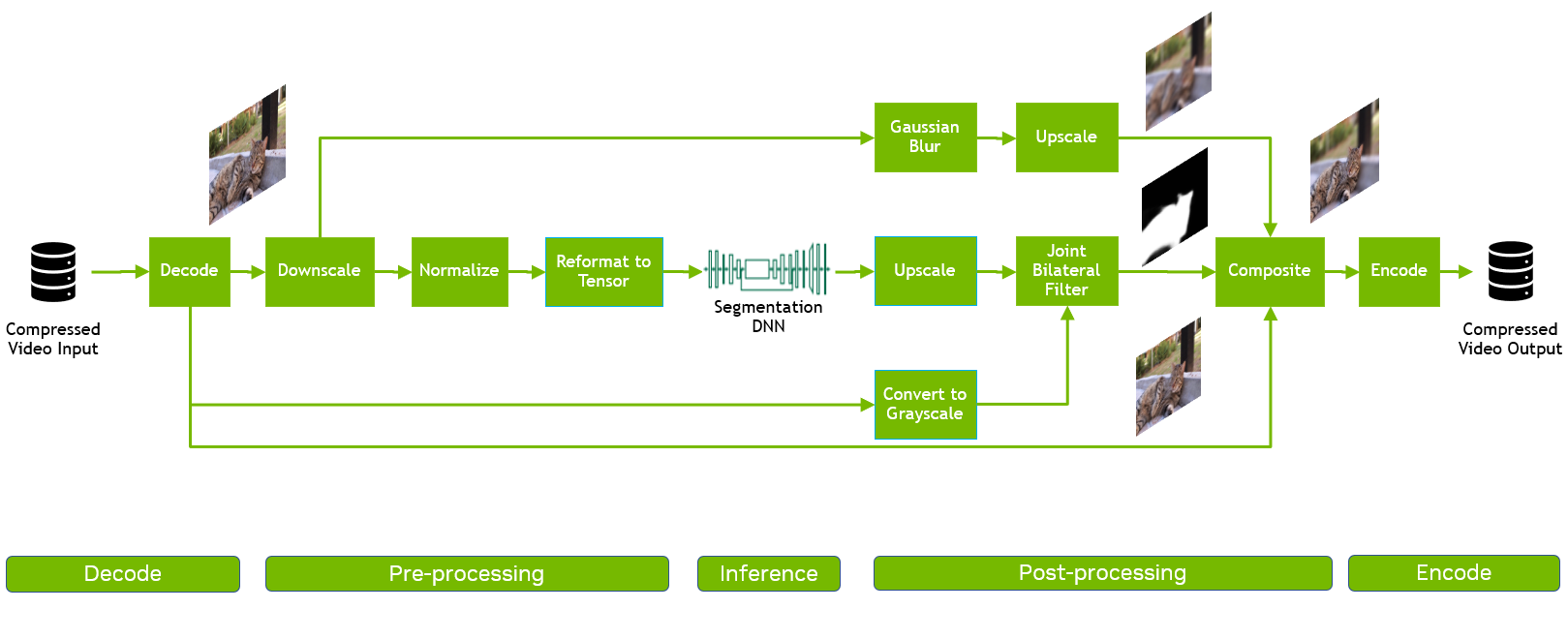
傳統的管道是用 OpenCV 和 PyTorch ( GPU )構建的,在 Python 中實現,因為這是客戶的典型模式。輸入視頻的分辨率為 1080p ,由 474 幀組成,批量大小為 1 。在這個管道中,由于 PyTorch , GPU 僅用于推理,而過程的其余部分是基于 CPU 的:
- 使用 OpenCV / ffmpeg 對幀進行解碼。
- 解碼后的圖像使用 OpenCV 進行預處理,并輸入 PyTorch 供電的 DNN ,以檢測哪些像素屬于貓,從而生成掩碼。
- 在后處理階段,前一階段的輸出掩碼與原始圖像及其模糊版本合成,導致前景中的貓和背景模糊。
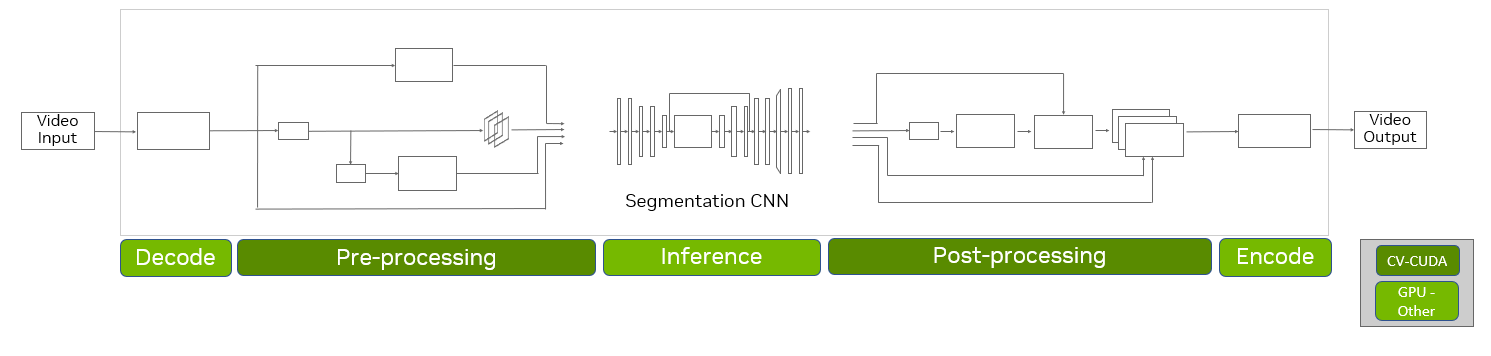
對于基于 GPU 的管道(圖 4 ),我們使用 CV-CUDA 庫中的優化運算符實現了預處理和后處理階段,并使用 NVIDIA TensorRT 庫進行了推理。我們還使用 VPF 加速了 GPU 上流水線的解碼和編碼部分。
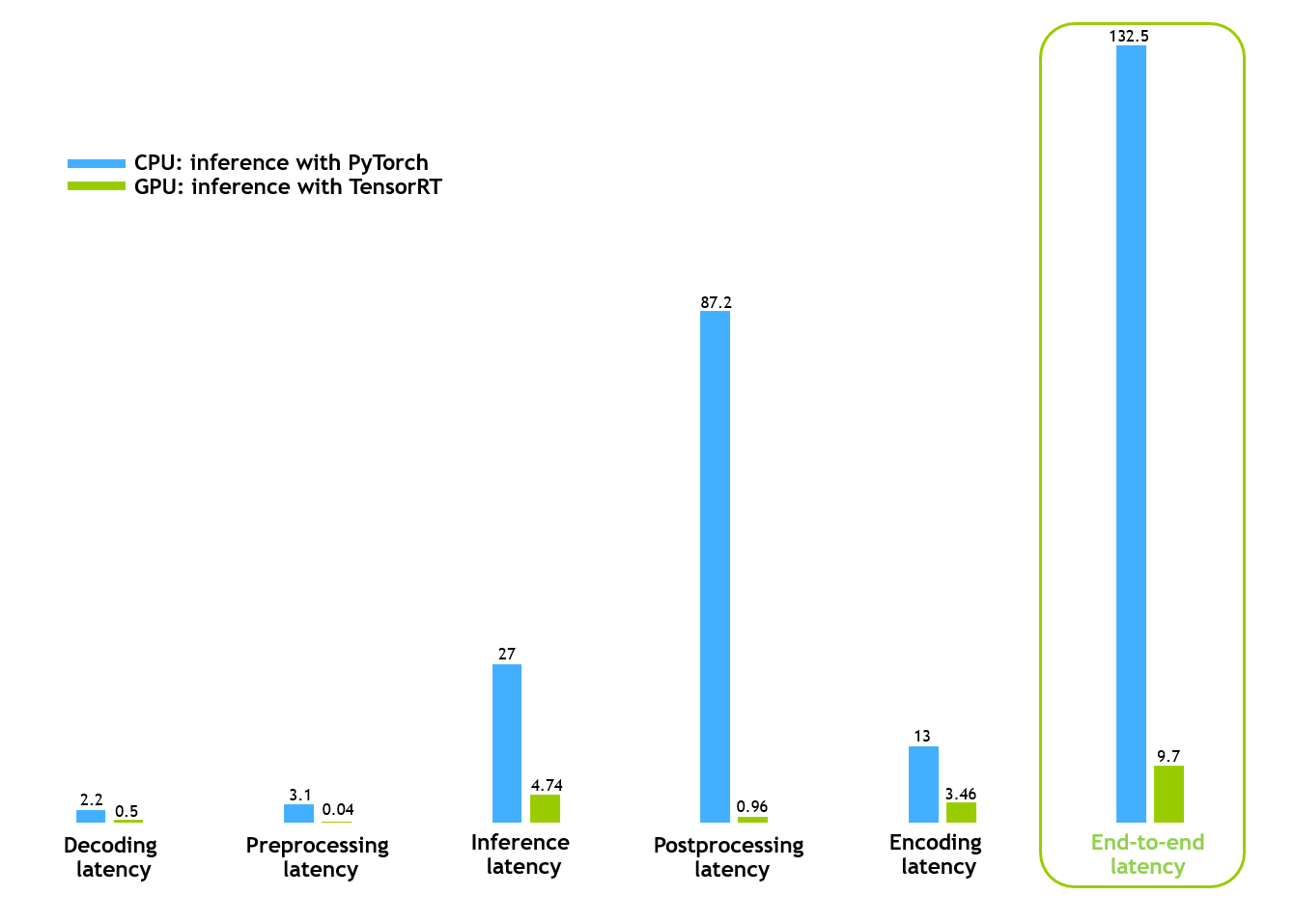
圖 5 顯示,一幀批次的端到端時間從 132 毫秒減少到大約 10 毫秒,這表明 GPU 管道實現了令人印象深刻的延遲減少。通過使用單個 NVIDIA T4 GPU ,與 CPU 管道相比, CV-CUDA 管道的速度快了約 13 倍。
這一結果是通過對單個視頻進行處理的單個過程獲得的。通過部署多個進程來同時處理多個視頻,這些優化可以在相同的硬件下實現更高的吞吐量,從而顯著節省成本和能源。
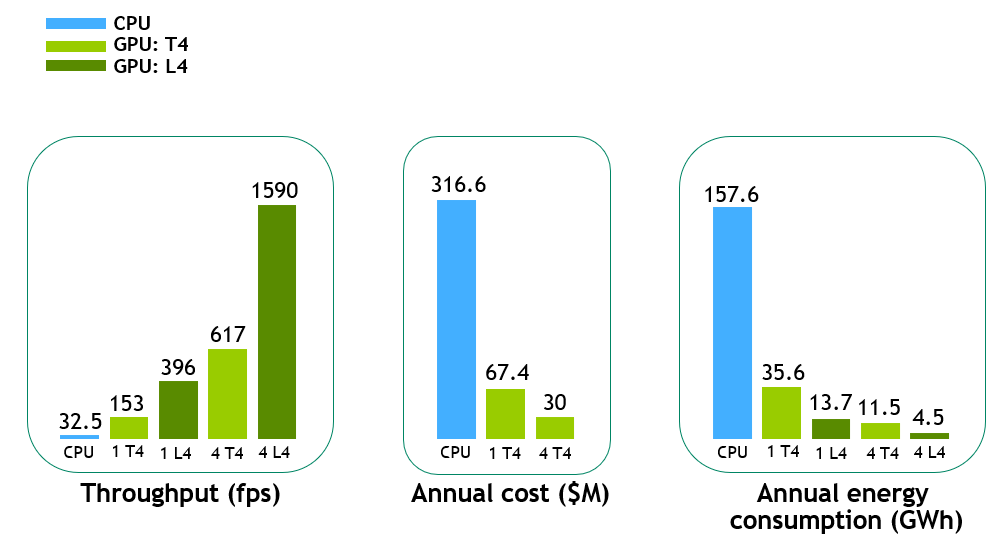
為了更好地展示 CV-CUDA 所帶來的好處,我們在不同的實例(一個 T4 GPU 、一個 L4 GPU 、四個 T4 GPU 和四個 L4 GPU )上執行了 z1K 管道。
新引入的NVIDIA L4 Tensor Core GPU,由NVIDIA Ada Lovelace 架構,為視頻、人工智能、視覺計算、圖形和虛擬化提供了低成本、高能效的加速。
在圖 6 中,與 CPU 基線相比,單個 T4 GPU 上的端到端吞吐量加速約為 5 倍,而新 L4 GPU 上的加速進一步提高至約 12 倍。在多個 GPU 實例的情況下,性能幾乎呈線性擴展,例如,在四個 T4 GPU 和四個 L4 GPU 上分別為~ 19x 和~ 48x 。
為了計算每年的云成本和能耗,我們假設每分鐘上傳 500 個視頻小時到視頻流平臺的典型視頻工作負載。對于年度云成本,我們只考慮了 T4 GPU ( L4 GPU ‘將在未來可用),并假設Amazon EC2 G4 Instances.
考慮到這一點,單個 T4 GPU 視頻工作負載的年成本約為 CPU 管道的 1 / 5 。這預測了對于這樣的工作負載,典型的云成本節約估計約為數億 USD 。
對于數據中心來說,除了處理如此巨大的工作負載所需的硬件成本外,能源效率對于降低能源成本和環境影響至關重要。
在圖 6 (右)中,根據服務器上的平均每小時功耗,計算了具有相應硬件的相同視頻工作負載的年能耗(以 GWh 為單位)。單個 L4 系統的能耗約為 CPU 服務器的 1 / 12 。對于像示例視頻這樣的工作量(每分鐘 500 小時的視頻),每年的節能估計約為數百 GWh 。
這些能源節約意義重大,因為這相當于避免了每年行駛約 11000 英里的數萬輛乘用車的溫室氣體排放。
CV- CUDA Beta v0 . 3 . 0 功能
既然您已經看到了使用 CV- CUDA 加速人工智能計算機視覺工作負載的好處,以下是一些關鍵功能:
- 開源: Apache 2.0GitHub 上的授權開源軟件。
- 支持的運算符:CV- CUDA 提供了 30 多名專業操作員,通常用于人工智能計算機視覺工作負載的前處理和后處理步驟。這些無狀態、獨立的操作符可以很容易地插入到現有的自定義處理框架中。常見的操作符包括 ConvertTo 、 Custom crop 、 Normalize 、 PadStack 、 Reformat 和 Resize 。有關詳細信息,請參閱CV-CUDA Developer Guide.
- 新操作員:CV- CUDA Beta v0 . 3 . 0 提供了新的操作符,如重映射、查找輪廓、非最大值抑制、閾值和自適應閾值。
- 的自定義后端 NVIDIA Triton:現在,您可以在使用示例應用程序構建計算機視覺管道時,將 CV- CUDA 集成到自定義后端中。
- 多語言 API :CV- CUDA 包括 C / C ++和 Python 的 API 。
- 框架接口:到現有 DL 框架(如 PyTorch 和 TensorFlow )的易于使用和零拷貝接口。
- 批量支持:支持所有 CV- CUDA 運算符,因此可以實現更高的 GPU 利用率和更好的性能。
- 統一和可變形狀批量支持:CV- CUDA 接受具有相同或不同維度的張量。
- 示例應用程序:端到端加速圖像分類、對象檢測和視頻分割示例應用程序。
- 單線 PIP 安裝。
- 安裝、入門和 API 參考指南。
CV-CUDA 可供下載
的公測版( v0 . 3 . 0 )CV-CUDA is now available on GitHub.
CV-CUDA 能夠使用優化的圖像和視頻處理內核在云中加速復雜的人工智能計算機視覺工作負載。 Python 友好的庫可以很容易地集成到現有的管道中,具有與 PyTorch 和 TensorFlow 等常見深度學習框架的零拷貝接口。
CV-CUDA ,以及 VPF 和TensorRT,進一步優化了終端人工智能工作負載,以實現顯著的成本和能源節約。這使得它適用于云規模的用例:
- Video content creation and enhancement
- Image understanding
- Recommender systems
- Mapping
- Video conferencing
有關更多信息,請參閱以下資源:
- CV-CUDA documentation
- NVIDIA Announces Microsoft, Tencent, Baidu Adopting CV-CUDA for Computer Vision AI
- Runway Optimizes AI Image and Video Generation Tools Using CV-CUDA(視頻)
- Overcome Pre- and Post-Processing Bottlenecks in AI-Based Imaging and Computer Vision Pipelines with CV-CUDA(視頻,需要免費注冊)
- Build AI-Based HD Maps for Autonomous Vehicles(視頻,需要免費注冊)
- Advance AI Applications with Custom GPU-Powered Plugins for NVIDIA DeepStream(視頻,需要免費注冊)
- FastDeploy: Full-Scene, High-Performance AI Deployment Tool (Presented by Baidu)(視頻,需要免費注冊)
- Accelerate Modern Video Applications in the Cloud using Video Codec SDK, CV-CUDA, and TensorRT on GPU(普通話視頻,需要免費注冊)
使用或考慮 CV-CUDA ?Engage the product team for support。我們很想聽聽你的意見。
?