越來越多的網絡應用程序需要進行 GPU 實時數據包處理,以實現高數據率解決方案:數據過濾、數據放置、網絡分析、傳感器信號處理等。
一個主要動機是 GPU 可以實現并行處理多個數據包的高度并行性,同時提供可擴展性和可編程性。
有關這些技術的基本概念以及基于 DPDK gpudev 庫的初始解決方案的概述,請參見 Boosting Inline Packet Processing Using DPDK and GPUdev with GPUs 。
這篇文章解釋了新的 NVIDIA DOCA GPUNetIO 庫如何克服以前 DPDK 解決方案中的一些限制,向以 GPU 為中心的數據包處理應用程序邁進了一步。
介紹
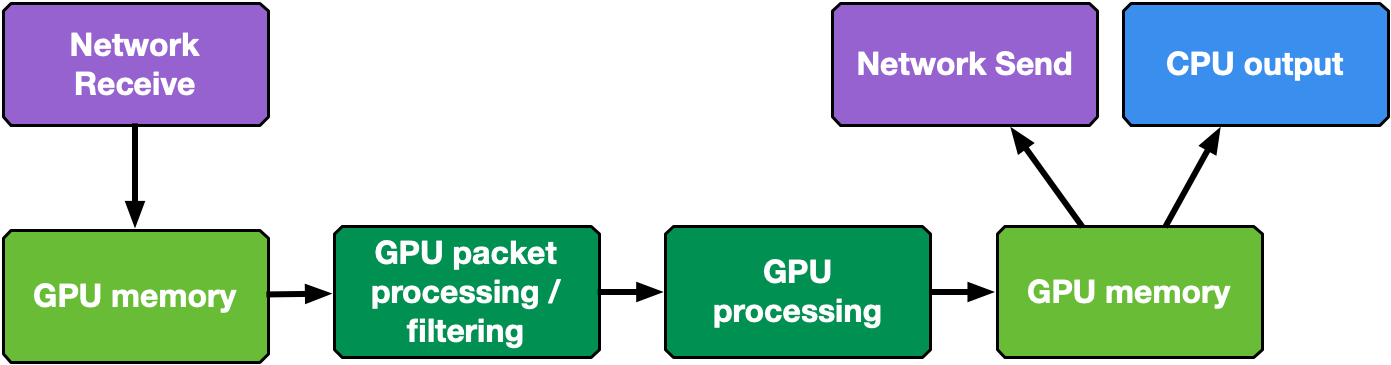
網絡分組的實時 GPU 處理是一種適用于幾個不同應用領域的技術,包括信號處理、網絡安全、信息收集和輸入重建。這些應用程序的目標是實現一個內聯數據包處理管道,以在 GPU 內存中接收數據包(無需通過 CPU 內存暫存副本);與一個或多個 CUDA 內核并行地處理它們;然后運行推斷、評估或通過網絡發送計算結果。
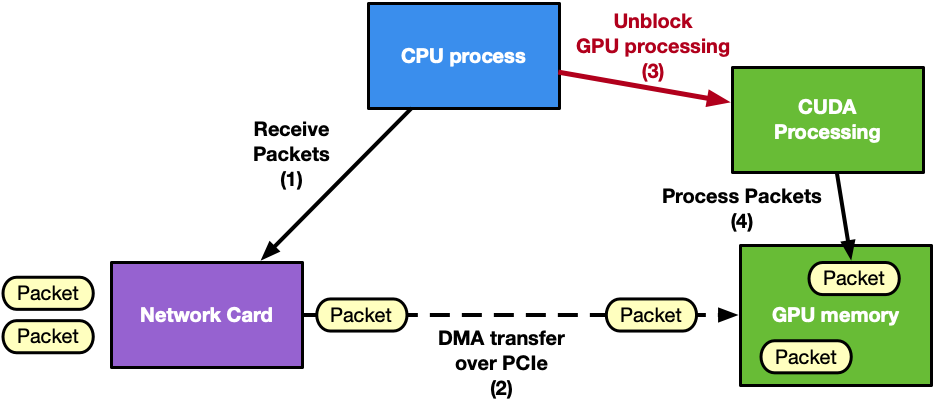
通常,在這個管道中, CPU 是中介,因為它必須使網卡( NIC )接收活動與 GPU 處理同步。一旦 GPU 內存中接收到新的數據包,這將喚醒 CUDA 內核。類似的考慮可以應用于管道的發送端。
Data Plane Development Kit ( DPDK )框架引入了 gpudev library 來為此類應用提供解決方案:使用 GPU 內存( GPUDirect RDMA 技術)結合低延遲 CPU 同步進行接收或發送。有關協調 CPU 和 GPU 活動的不同方法的更多信息,請參見 Boosting Inline Packet Processing Using DPDK and GPUdev with GPUs 。
GPU 啟動的通信
從圖 1 中可以看出, CPU 是主要瓶頸。它在同步 NIC 和 GPU 任務以及管理多個網絡隊列方面承擔了太多的責任。例如,考慮一個具有多個接收隊列和 100 Gbps 傳入流量的應用程序。以 CPU 為中心的解決方案將具有:
- CPU 調用每個接收隊列上的網絡功能,以使用一個或多個 CPU Core 接收 GPU 存儲器中的數據包
- CPU 收集數據包信息(數據包地址、編號)
- CPU 向 GPU 通知新接收的分組
- GPU 處理數據包
這種以 CPU 為中心的方法是:
- 資源消耗:為了處理高速率網絡吞吐量( 100 Gbps 或更高),應用程序可能需要專用整個 CPU 物理核心來接收(和/或發送)數據包
- 不可擴展:為了與不同的隊列并行接收(或發送),應用程序可能需要使用多個 CPU 內核,即使在 CPU Core 的總數可能被限制在較低數量(取決于平臺)的系統上也是如此
- 依賴于平臺:低功耗 CPU 上的相同應用程序將降低性能
GPU 內聯分組處理應用程序的下一個自然步驟是從關鍵路徑中刪除 CPU 。移動到以 GPU 為中心的解決方案, GPU 可以直接與 NIC 交互以接收數據包,因此數據包一到達 GPU 內存,處理就可以開始。同樣的注意事項也適用于發送操作。
GPU 從 CUDA 內核控制 NIC 活動的能力稱為 GPU 啟動的通信。假設使用 NVIDIA GPU 和 NVIDIA NIC ,則可以將 NIC 寄存器暴露給 GPU 的直接訪問。這樣, CUDA 內核可以直接配置和更新這些寄存器,以協調發送或接收網絡操作,而無需 CPU 的干預。
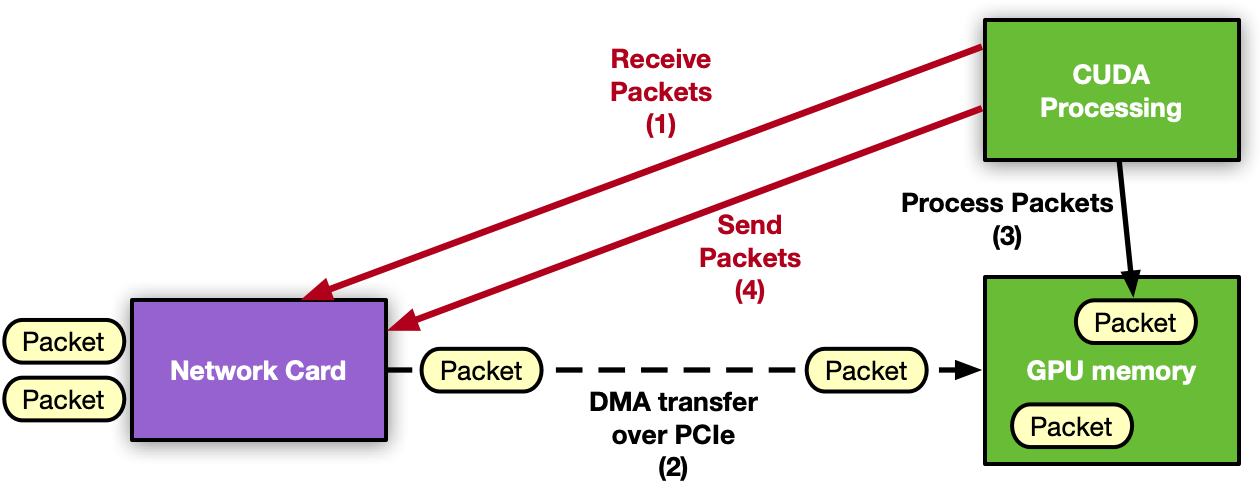
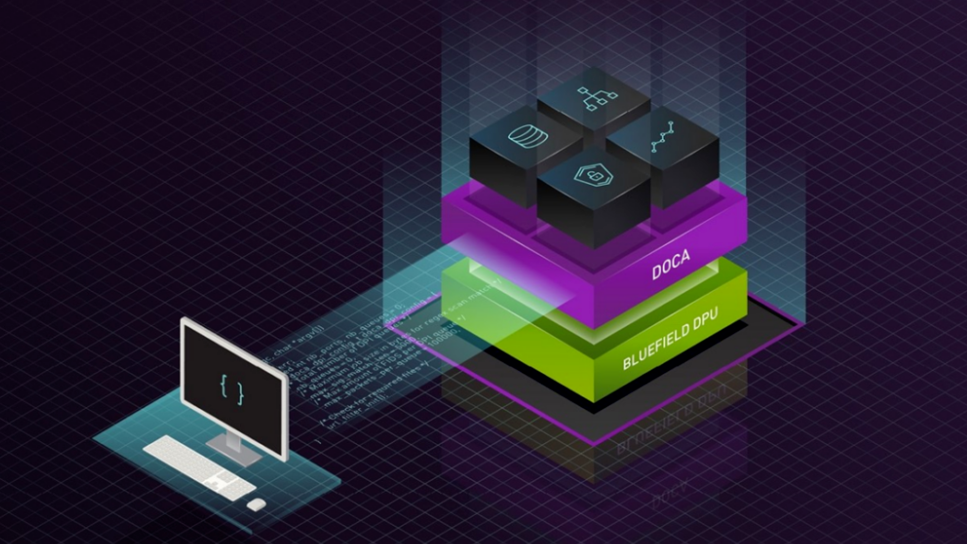
根據定義, DPDK 是 CPU 框架。要啟用 GPU 啟動的通信,需要在 GPU 上移動整個控制路徑,這是不適用的。因此,通過創建新的 NVIDIA DOCA 庫來啟用此功能。
NVIDIA DOCA GPUNetIO 庫
NVIDIA DOCA SDK 是新的 NVIDIA 框架,由驅動程序、庫、工具、文檔和示例應用程序組成。這些資源是利用 NVIDIA 硬件可以在主機系統和 DPU 上公開的網絡、安全性和計算功能來利用應用程序所必需的。
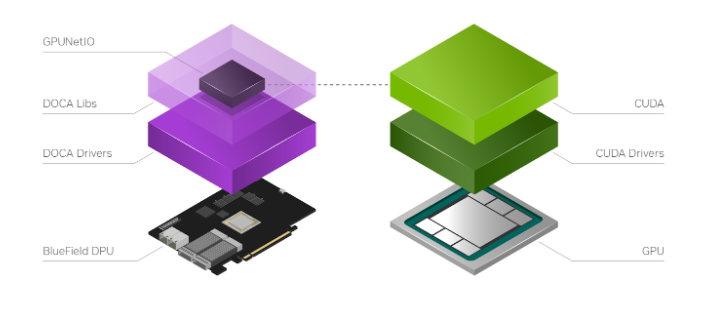
NVIDIA DOCA GPUNetIO 是在 NVIDIA DOCA 1.5 版本的基礎上開發的一個新庫,用于在 DOCA 生態系統中引入 GPU 設備的概念(圖 3 )。為了促進創建以 DOCA GPU 為中心的實時數據包處理應用程序, DOCA GPUNetIO 結合了 GPUDirect RDMA 用于數據路徑加速、智能 GPU 內存管理、 CPU 和 GPU 之間的低延遲消息傳遞技術(通過 GDRCopy 功能)和 GPU 啟動的通信。
這使 CUDA 內核能夠直接控制 NVIDIA ConnectX 網卡。為了最大化性能, DOCA GPUNetIO 庫必須用于 GPUDirect 友好的平臺,其中 GPU 和網卡通過專用 PCIe 網橋直接連接。 DPU converged card 是一個示例,但同樣的拓撲也可以在主機系統上實現。
DOCA GPUNetIO 目標是 GPU 分組處理網絡應用程序,使用以太網協議在網絡中交換分組。對于這些應用程序,不需要像基于 RDMA 的應用程序那樣,通過 OOB 機制跨對等端進行預同步階段。也無需假設其他對等方將使用 DOCA GPUNetIO 進行通信,也無需了解拓撲。在未來的版本中, RDMA 選項將被啟用以覆蓋更多的用例。
DOCA 當前版本中啟用的 GPUNetIO 功能包括:
- GPU 啟動的通信?: DOCA 內核可以調用 CUDA GPUNetIO 庫中的 CUDA device 函數,以指示網卡發送或接收數據包
- 精確的發送調度:通過 GPU 啟動的通信,可以根據用戶提供的時間戳來調度未來的數據包傳輸
- GPUDirect RDMA :以連續固定大小 GPU 內存跨步接收或發送數據包,無 CPU 內存暫存副本
- 信號量:在 CPU 和 GPU 之間或不同 GPU CUDA 內核之間提供標準化的低延遲消息傳遞協議
- CPU 對 CUDA 內存的直接訪問: CPU 可以在不使用 GPU 內存 API 的情況下修改 GPU 內存緩沖區
如圖 4 所示,典型的 DOCA GPUNetIO 應用步驟如下:
- CPU 上的初始配置階段
- 使用 DOCA 識別和初始化 GPU 設備和網絡設備
- 使用 DOCA GPUNetIO 創建可從 CUDA 內核管理的接收或發送隊列
- 使用 DOCA Flow 確定應在每個接收隊列中放置哪種類型的數據包(例如, IP 地址的子集、 TCP 或 UDP 協議等)
- 啟動一個或多個 CUDA 內核(執行數據包處理/過濾/分析)
- CUDA 內核內 GPU 上的運行時控制和數據路徑
- 使用 DOCA GPUNetIO CUDA 設備函數發送或接收數據包
- 使用 DOCA GPUNetIO CUDA 設備函數與信號量交互,以使工作與其他 CUDA 內核或 CPU 同步
以下各節概述了結合 DOCA GPUNetIO 構建塊的可能 GPU 分組處理管道應用程序布局。
CPU 接收和 GPU 處理
第一個示例以 CPU 為中心,不使用 GPU 啟動的通信功能。它可以被視為以下章節的基線。 CPU 創建可從 CPU 自身管理的接收隊列,以接收 GPU 存儲器中的數據包,并為每個隊列分配流量控制規則。
在運行時, CPU 接收 GPU 存儲器中的數據包。它通過 DOCA GPUNetIO 信號量向一個或多個 CUDA 內核通知每個隊列新一組數據包的到達,提供 GPU 內存地址和數據包數量等信息。在 GPU 上, CUDA 內核輪詢信號量,檢測更新并開始處理數據包。
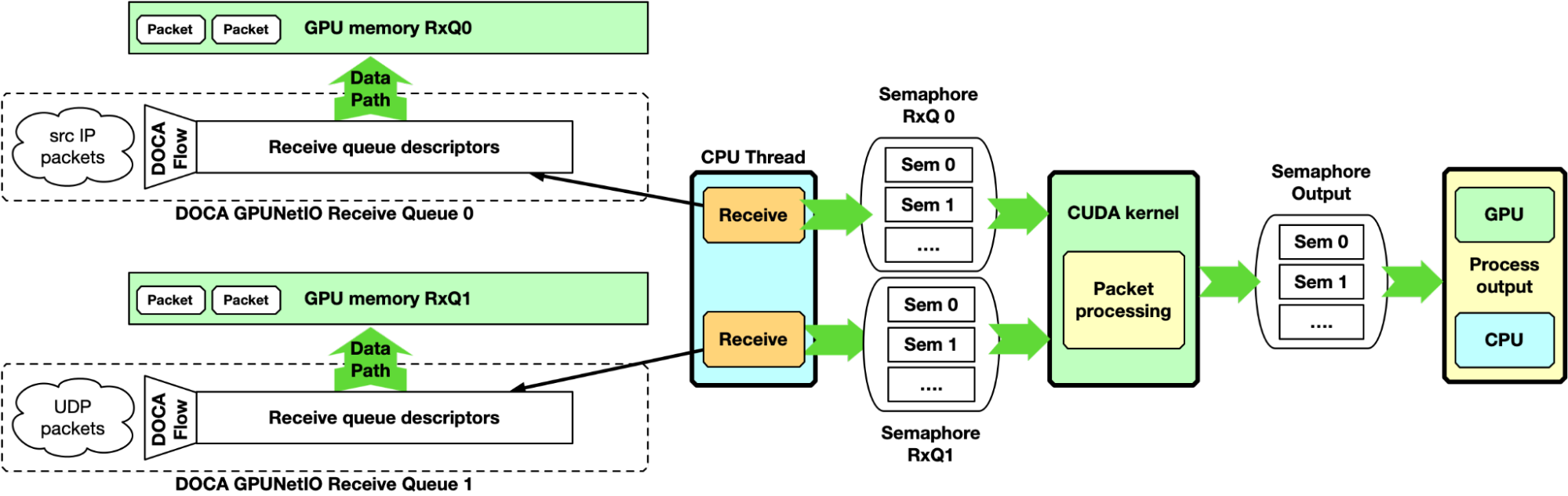
這里, DOCA GPUNetIO 信號量具有類似于 DPDK gpudev communication list 的功能,使得 CPU 接收分組和 GPU 在處理這些分組之前等待接收這些分組之間能夠實現低延遲通信機制。信號量還可用于 GPU 在包處理完成時通知 CPU ,或在兩個 GPU CUDA 內核之間共享關于已處理包的信息。
該方法可作為績效評估的基準。由于它以 CPU 為中心,因此嚴重依賴 CPU 型號、功率和內核數量。
GPU 接收和 GPU process
上一節中描述的以 CPU 為中心的流水線可以通過以 GPU 為中心的方法進行改進,該方法使用 GPU 發起的通信,使用 CUDA 內核管理接收隊列。以下部分提供了兩個示例:多 CUDA 內核和單 CUDA 內核。
多 CUDA 內核
使用這種方法,至少涉及兩個 CUDA 內核,一個專用于接收分組,另一個專用用于分組處理。接收機 CUDA 內核可以通過信號量向第二 CUDA 內核提供分組信息。
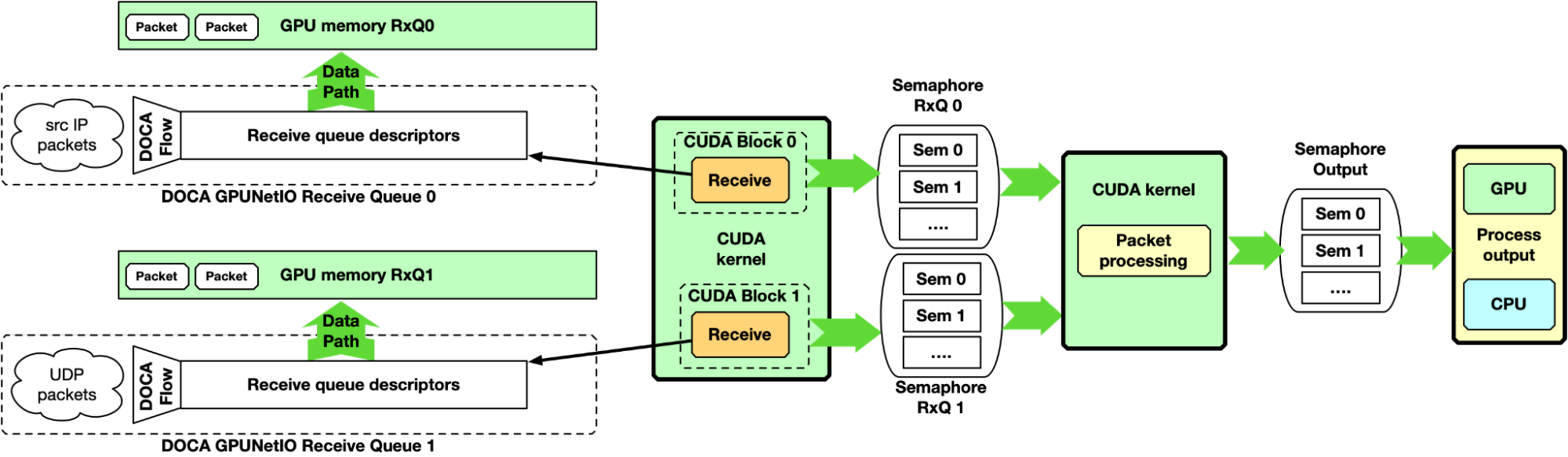
這種方法適用于高速網絡和延遲敏感的應用,因為兩個接收操作之間的延遲不會被其他任務延遲。期望將接收機 CUDA 內核的每個 CUDA 塊關聯到不同的隊列,并行地接收來自所有隊列的所有分組。
單 – CUDA 內核
通過使單個 CUDA 內核負責接收和處理分組,仍然為每個隊列專用一個 CUDA 塊,可以簡化先前的實現。
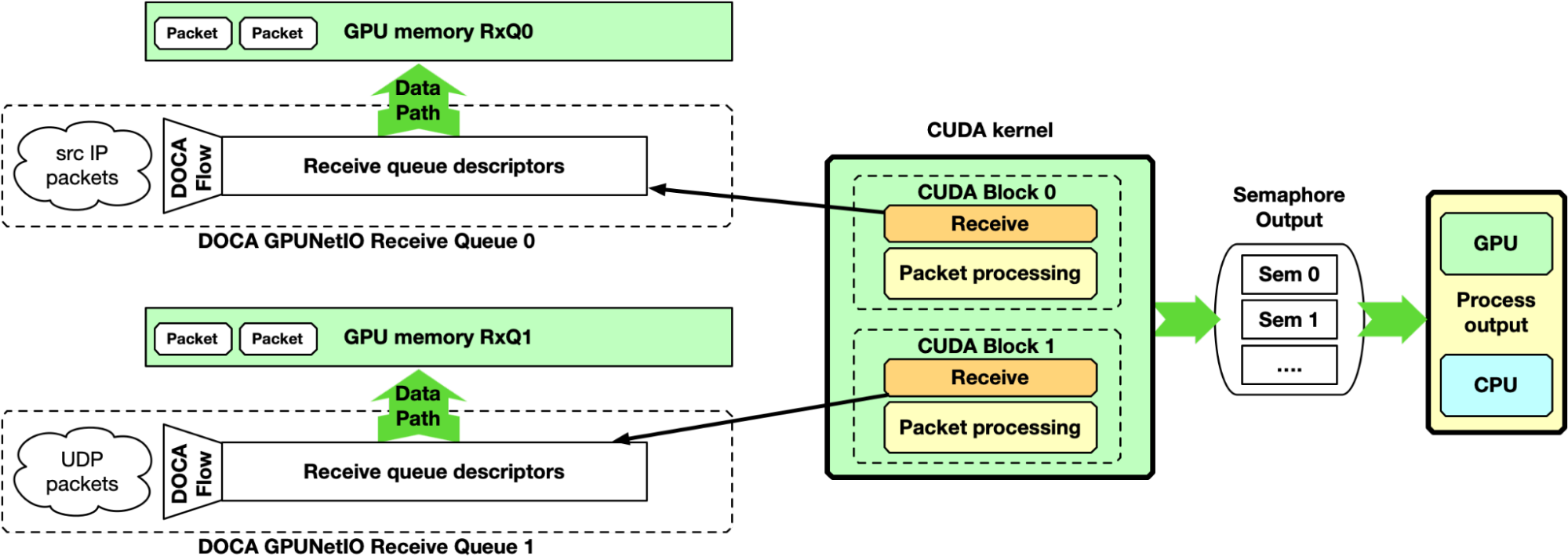
這種方法的一個缺點是每個 CUDA 塊兩個接收操作之間的延遲。如果數據包處理需要很長時間,應用程序可能無法跟上在高速網絡中接收新數據包的速度。
GPU 接收、 GPU 處理和 GPU send
到目前為止,大多數關注點都集中在管道的“接收和處理”部分。然而, DOCA GPUNetIO 還可以在 GPU 上生成一些數據,制作數據包并從 CUDA 內核發送,而無需 CPU 干預。圖 8 描述了一個完整的接收、處理和發送管道的示例。
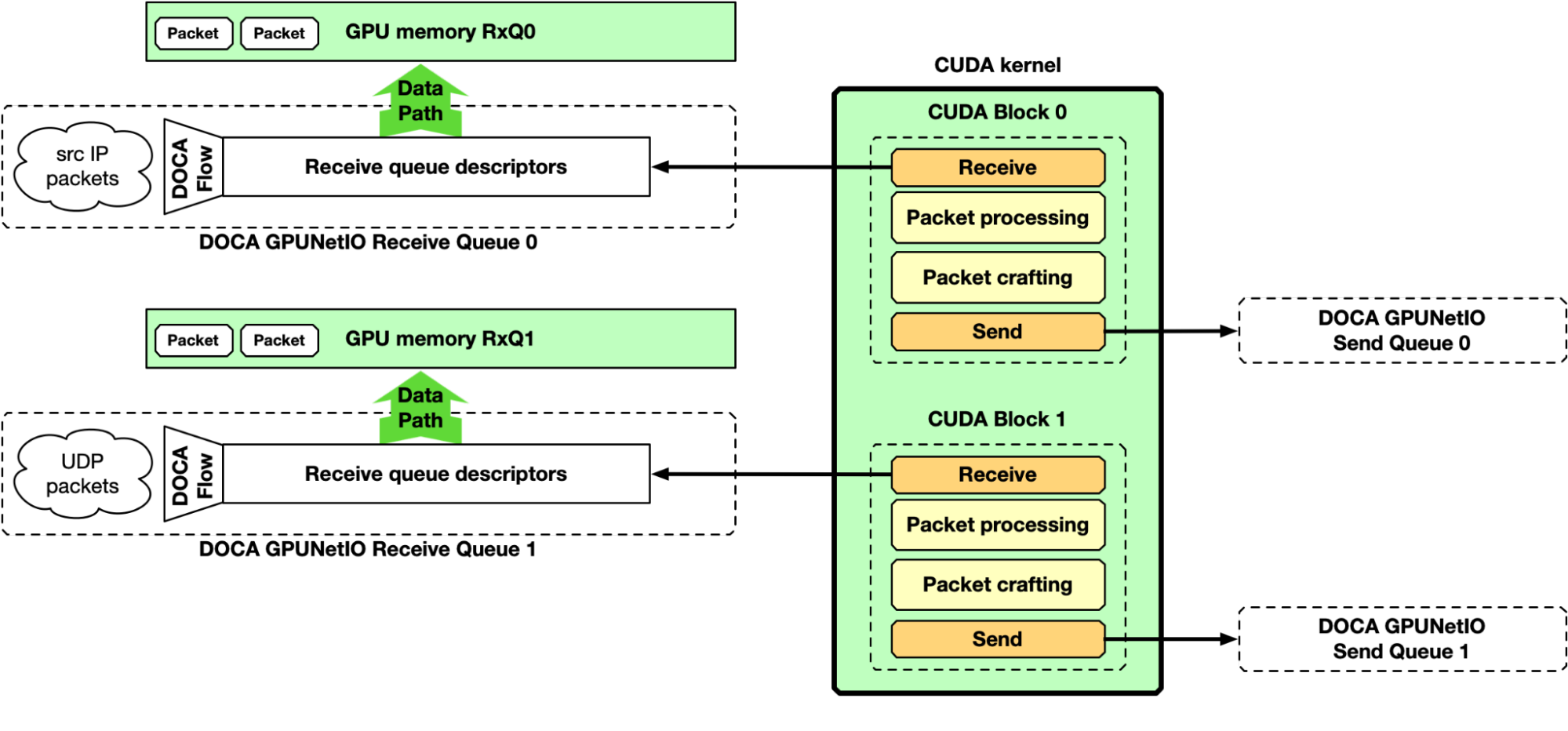
NVIDIA DOCA GPUNetIO 示例應用程序
與任何其他 NVIDIA DOCA 庫一樣, DOCA GPUNetIO 有一個專用應用程序,用于 API 使用參考和測試系統配置和性能。該應用程序實現了前面描述的管道,提供了不同類型的數據包處理,如 IP 校驗和、 HTTP 數據包過濾和流量轉發。
以下部分概述了應用程序的不同操作模式。報告了一些性能數據,將其視為可能在未來版本中更改和改進的初步結果。使用兩個基準系統,一個用于接收數據包,另一個用于發送數據包,背靠背連接(圖 9 )。
運行 DOCA GPUNetIO 應用程序的接收器是帶有 NVIDIA BlueField-2X DPU converged card 的 Dell PowerEdge R750 。該配置為嵌入式 CPU 模式,因此應用程序使用 NIC NVIDIA ConnectX-6 Dx 和 DPU 的 GPU A100X 在主機系統 CPU 上運行。軟件配置為 Ubuntu 20.04 、 MOFED 5.8 和 CUDA 18.1 。
發送器是千兆字節 Intel Xeon Gold 6240R ,具有與 NVIDIA ConnectX-6 Dx 的 PCIe Gen 3 連接。此計算機不需要任何 GPU ,因為它運行 T-Rex DPDK packet generator v2.99 。軟件配置為 Ubuntu 20.04 和 MOFED 5.8 。
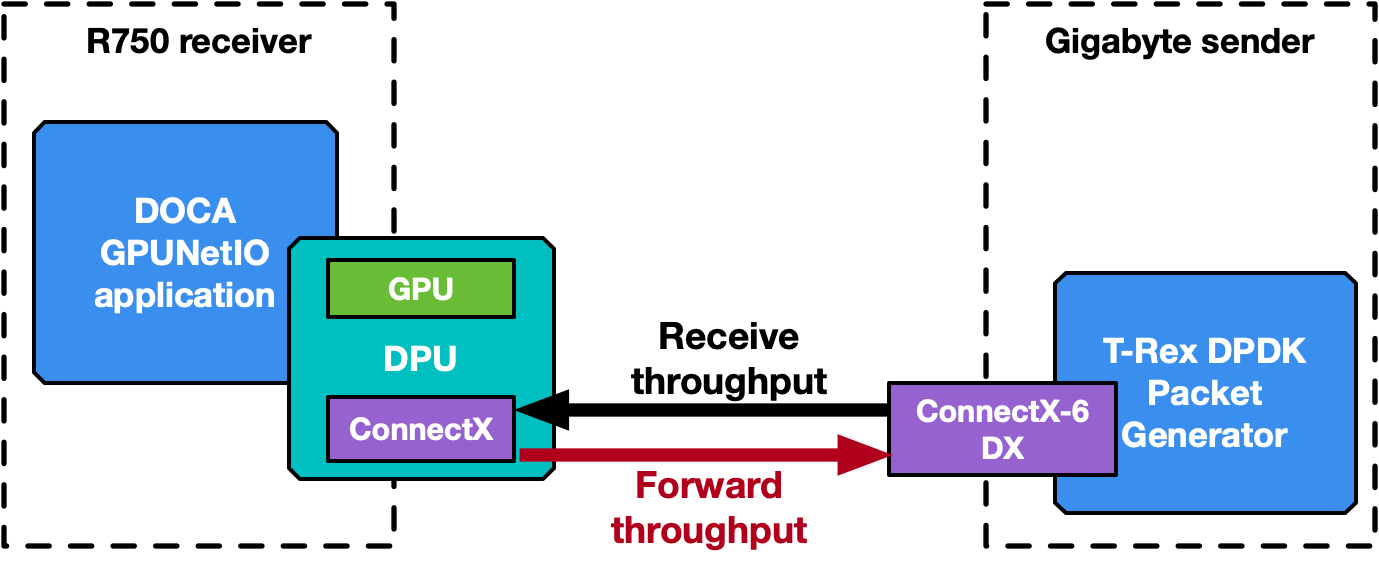
該應用程序也已在 DPU Arm 內核上執行,導致了相同的性能結果,并證明了以 GPU 為中心的解決方案與 CPU 無關。
請注意, DOCA GPUNetIO 最低要求是具有 GPU 和具有直接 PCIe 連接的 NIC 的系統。 DPU 不是嚴格要求。
IP 校驗和, GPU 僅接收
應用程序使用 GPU 發起的通信來創建一個或多個接收隊列以接收分組。可以使用單 CUDA 內核或多 CUDA 內核模式。
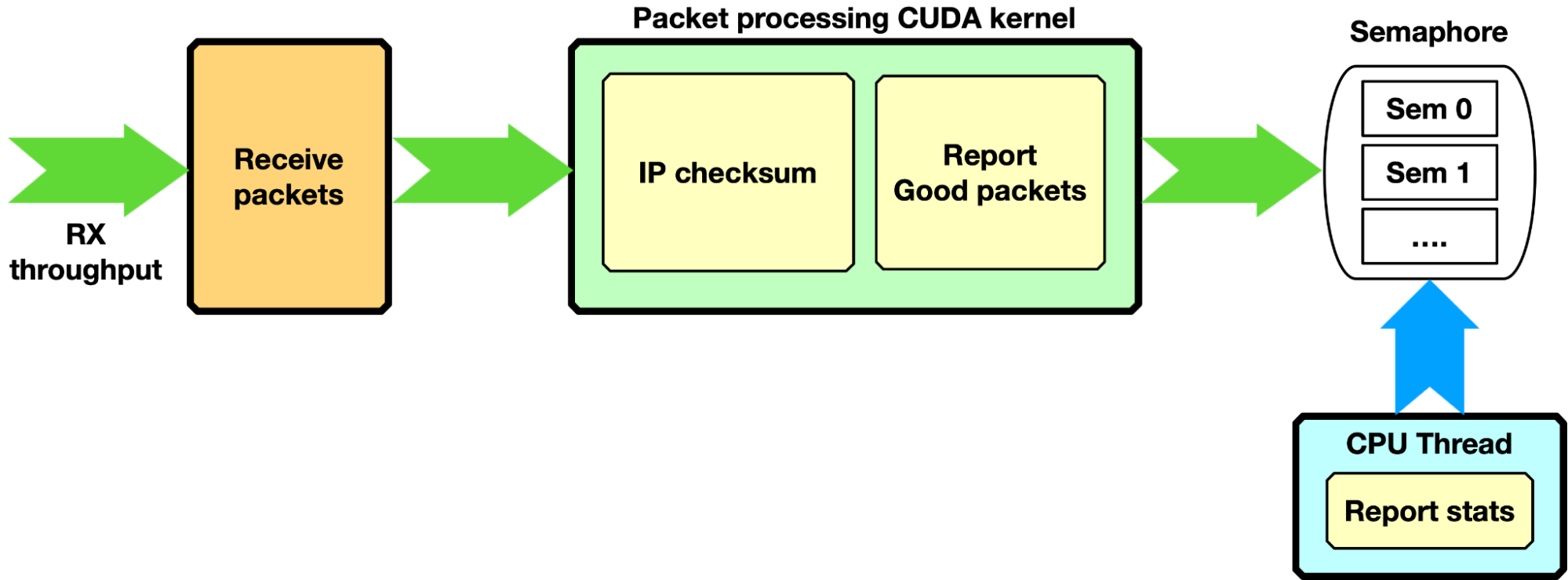
每個數據包都通過簡單的 IP 校驗和驗證進行處理,只有通過此測試的數據包才算作“好數據包”。通過信號量,好數據包的數量被報告給 CPU , CPU 可以在控制臺上打印報告。
通過使用 T-Rex 數據包生成器以約 100 Gbps (約 11.97 Mpps )的速度發送 30 億個 1 KB 大小的數據包,并在 DOCA GPUNetIO 應用程序端報告相同數量的數據包以及正確的 IP 校驗和,實現了單隊列零數據包丟失。相同的配置在 BlueField-2 融合卡上進行了測試,結果相同,證明了 GPU 啟動的通信是一個獨立于平臺的解決方案。
由于數據包大小為 512 字節, T-Rex 數據包生成器無法發送超過 86 Gbps (約 20.9 Mpps )的數據包。即使每秒數據包的數量幾乎是兩倍, DOCA GPUNetIO 也沒有報告任何數據包丟失。
HTTP 過濾, GPU 僅接收
假設一個更復雜的場景,數據包處理 CUDA 內核只過濾具有特定特征的 HTTP 數據包。它將“好包”信息復制到第二個 GPU 內存 HTTP 包列表中。一旦此 HTTP 數據包列表中的下一個項目充滿了數據包,通過專用信號量,過濾 CUDA 內核就會解除第二個 CUDA 內核的阻止,從而對累積的 HTTP 數據包進行一些推斷。信號量還可用于向 CPU 線程報告統計信息。
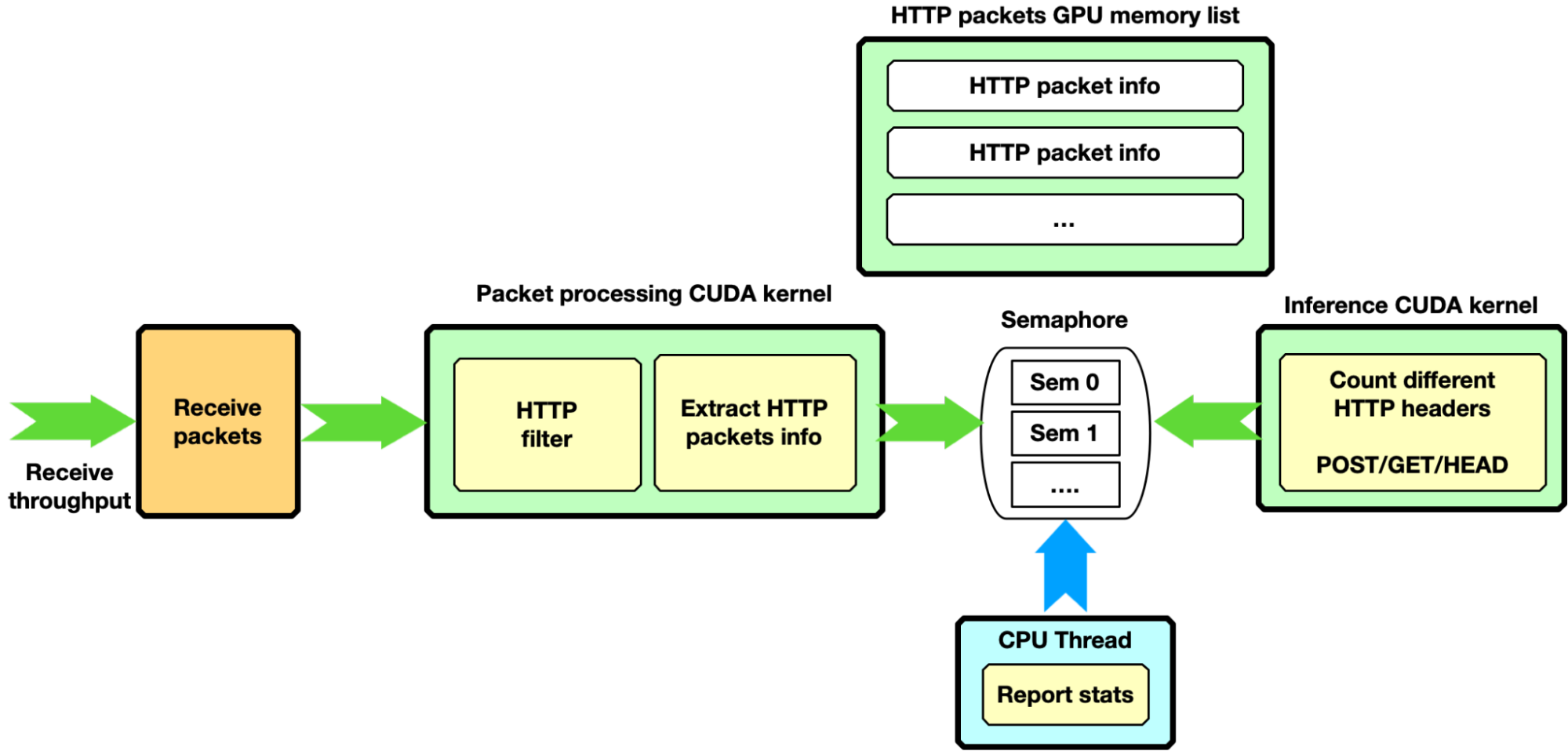
該流水線配置提供了復雜流水線的示例,該復雜流水線包括多個數據處理和過濾階段以及諸如 AI 流水線之類的推理功能。
前方交通量
本節介紹如何通過 GPU 啟動的通信使用 DOCA GPUNetIO 啟用流量轉發。在每個接收到的數據包中,在通過網絡發送回數據包之前,交換 MAC 和 IP 源地址和目的地址。
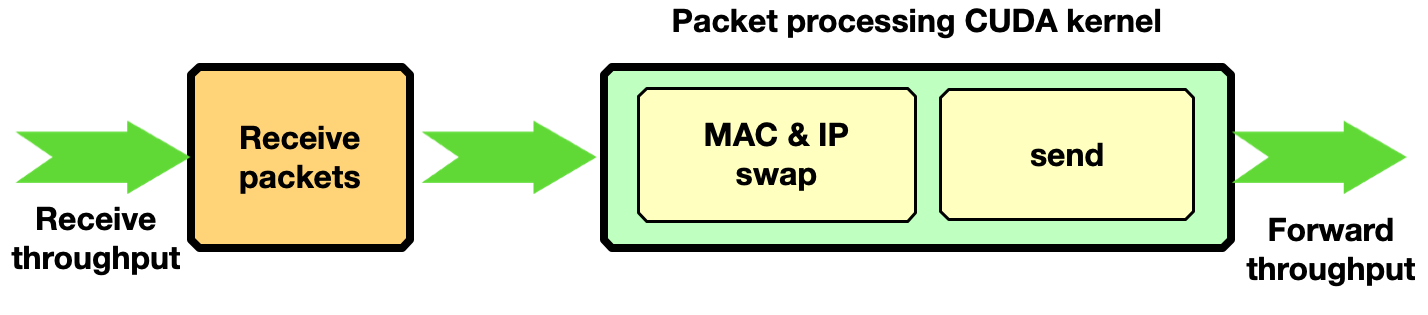
通過使用 T-Rex 數據包生成器以~ 90 Gbps 的速度發送 30 億個 1KB 大小的數據包,實現了只有一個接收隊列和一個發送隊列的零數據包丟失。
用于 5G 的 NVIDIA Aerial SDK
決定采用以 GPU 為中心的解決方案的動機可能是性能和低延遲要求,但也可能是為了提高系統容量。 CPU 在處理連接到接收器應用程序的越來越多的對等點時可能成為瓶頸。 GPU 提供的高度并行化可以提供可擴展的實現,以并行處理大量對等體,而不會影響性能。
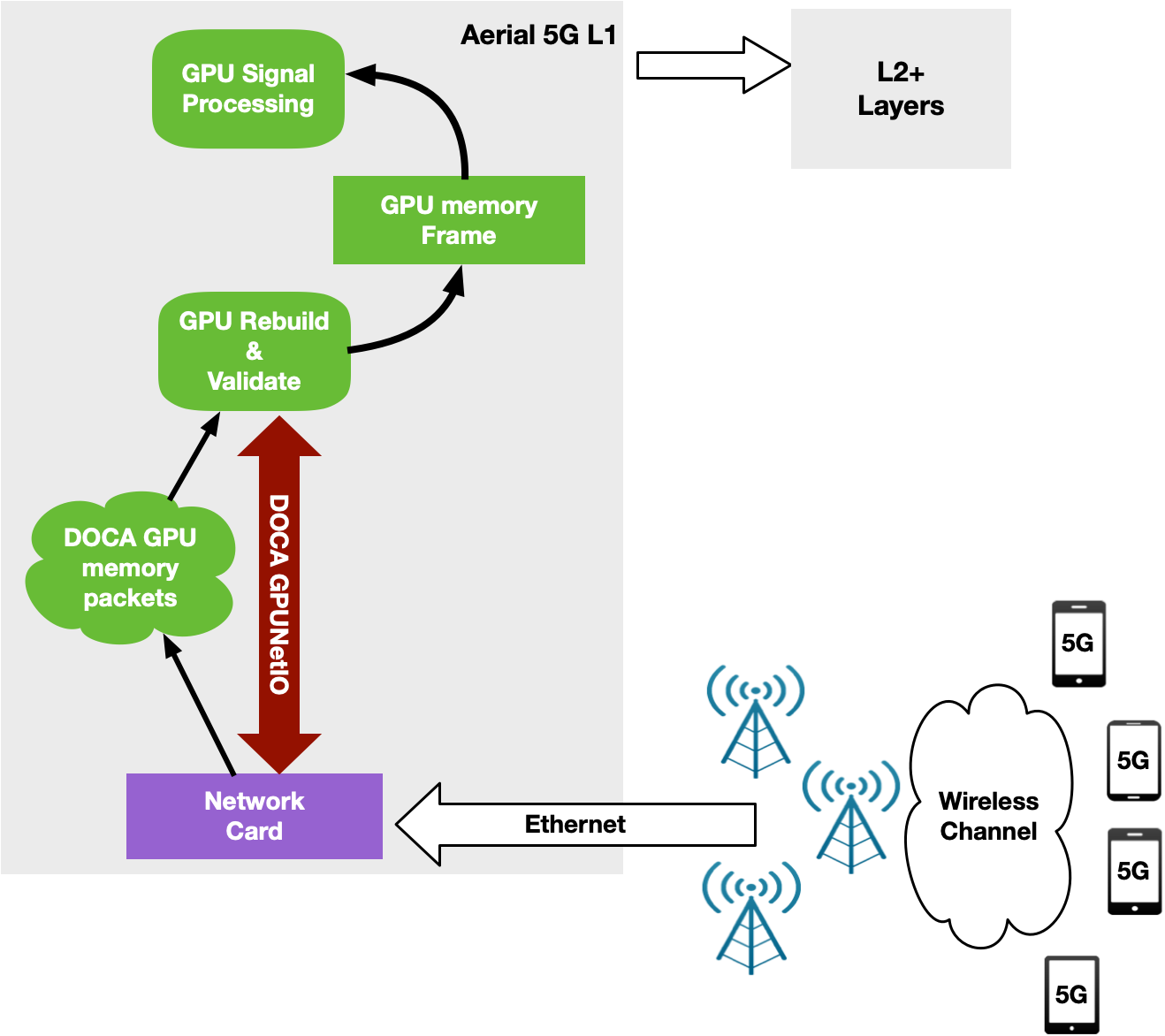
NVIDIA Aerial 是一個用于構建高性能、軟件定義的 5G L1 堆棧的 SDK ,該堆棧通過 GPU 上的并行處理進行了優化。具體而言, NVIDIA Aero SDK 可用于構建基帶單元( BBU )軟件,該軟件負責通過無線電單元( RU )發送(下行鏈路)或接收(上行鏈路)無線客戶端數據幀,該數據幀被拆分為多個以太網包。
在上行鏈路中, BBU 接收分組,驗證分組,并在觸發信號處理之前重建每個 RU 的原始數據幀。使用 NVIDIA Aerial SDK ,這在 GPU 中發生: GPU 內核專用于每個時隙的每個 RU ,以重建幀并觸發 CUDA 信號處理的 CUDA 內核序列。
通過 DPDK gpudev 庫實現了網卡接收數據包以及 GPU 重新排序和處理數據包的編排(圖 13 )。
第一個實現在現代 Intel x86 系統上僅使用一個 CPU 內核,就能夠以 25 Gbps 的速度保持 4 RU 的工作速度。然而,隨著小區數量的增加,網卡和 GPU 之間的 CPU 功能成為瓶頸。
A CPU 按順序工作。隨著單個 CPU 核心接收和管理越來越多的 RU 的流量,同一 RU 的兩次接收之間的時間取決于 RU 的數量。對于 2 個 CPU 核,每個核在 RU 的子集上工作,相同 RU 的兩次接收之間的時間減半。然而,這種方法對于越來越多的客戶機是不可擴展的。此外, PCIe 事務的數量從 NIC 增加到 CPU ,然后從 CPU 增加到 GPU (圖 14 )。
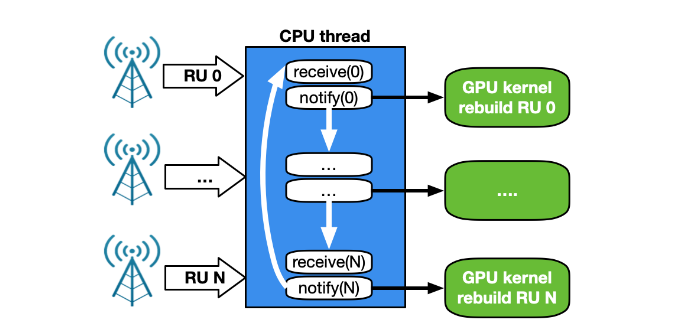
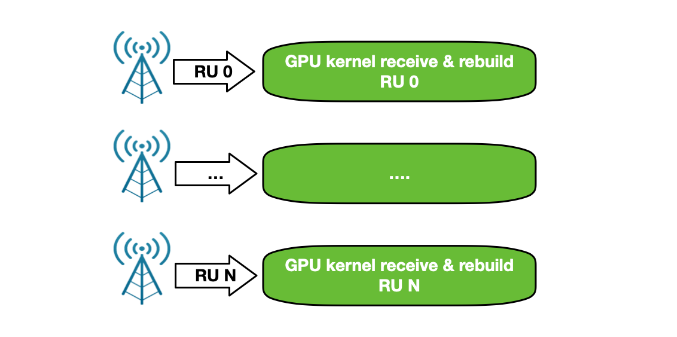
為了克服所有這些問題, NVIDIA Aerial SDK 的以 GPU 為中心的新版本已通過 DOCA GPUNetIO 庫實現。每個 CUDA 內核負責在每個時隙重建來自特定 RU 的數據包,并通過接收能力進行了改進(圖 15 )。
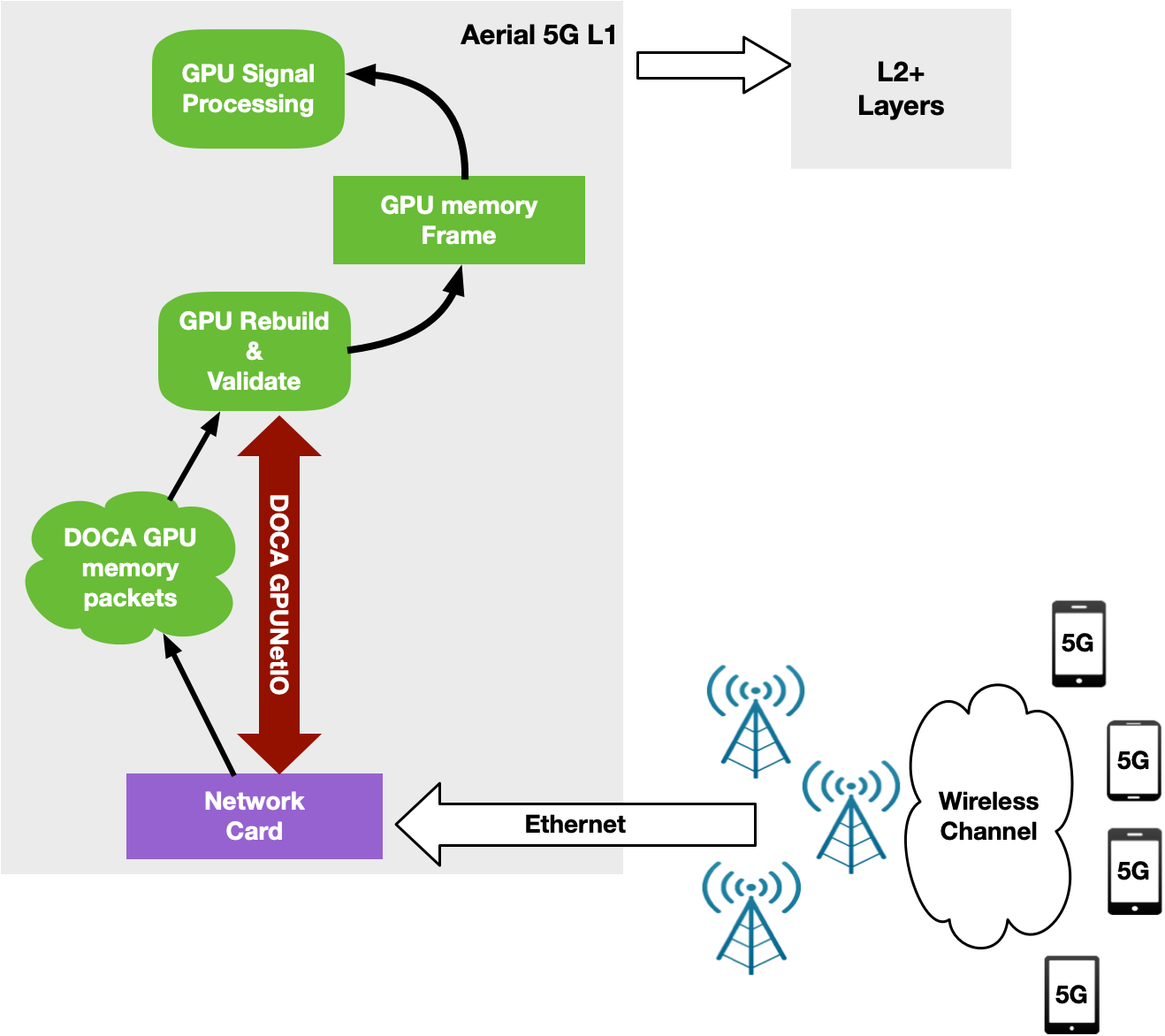
此時,關鍵路徑中不需要 CPU ,因為每個 CUDA 內核都是完全獨立的,能夠并行和實時處理越來越多的 RU 。這增加了系統容量,并減少了每個插槽處理數據包的延遲和 PCIe 事務的數量。 CPU 不必與 GPU 通信以提供分組信息。
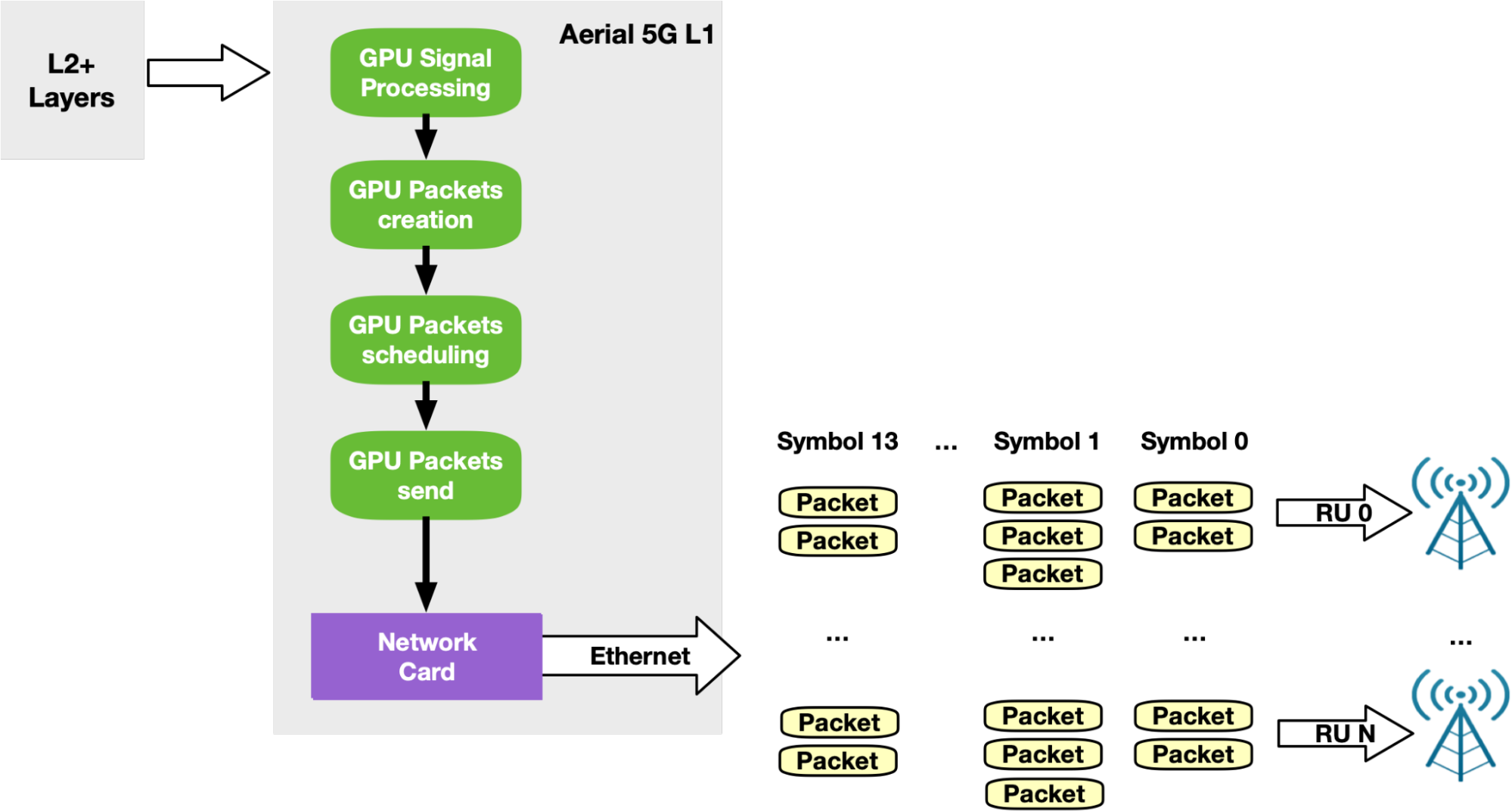
根據標準, 5G 網絡必須根據特定模式交換數據包。每個時隙(例如 500 微秒),數據包應該以 14 個所謂的符號發送。每個符號由若干個數據包組成(取決于使用情況),這些數據包將在較小的時間窗口(例如, 36 微秒)內發送。為了在下行鏈路側支持這種定時傳輸模式, NVIDIA Aerial SDK 通過 DOCA GPUNetIO API 將 GPU 啟動的通信與精確發送調度相結合。
一旦 GPU 信號處理準備好要在未來時隙中發送的數據,每個 RU 的專用 CUDA 內核將該數據分割成每個 RU 的以太網分組,并在未來的特定時間調度它們的未來傳輸。然后,同一 CUDA 內核將數據包推送到 NIC , NIC 將負責在正確的時間發送每個數據包(圖 17 )。
盡早訪問 NVIDIA DOCA GPUNetIO
作為研究項目的一部分, DOCA GPUNetIO 包處于實驗狀態。它可以早期訪問,是最新 DOCA 版本的擴展。它可以安裝在主機系統或 DPU 融合卡上,包括:
- 應用程序初始設置階段的一組 CPU 函數,用于準備環境并創建隊列和其他對象
- 您可以在 CUDA 內核中調用一組特定于 GPU 的函數,以發送或接收數據包,并與 DOCA GPUNetIO 信號量交互
- 您可以構建和運行應用程序源代碼來測試功能,并了解如何使用 DOCA GPUNetIO API
硬件要求是 ConnectX-6 Dx 或更新的網卡和 GPU Volta 或更新的。強烈建議在兩者之間使用專用 PCIe 網橋。軟件要求為 Ubuntu 20.04 或更新版本、 CUDA 11.7 或更新版本以及 MOFED 5.8 或更新版本。
如果您有興趣了解更多信息并獲得 NVIDIA DOCA GPUNetIO 的實際經驗,以幫助您開發下一個關鍵應用程序 contact NVIDIA Technical Support for early access 。請注意, DOCA GPUNetIO 庫目前僅在 NVIDIA 的 NDA 下可用。
?