
NVIDIA 今天在 GTC 2025 宣布發布 NVIDIA Dynamo 。NVIDIA Dynamo 是一個高吞吐量、低延遲的開源推理服務框架,用于在大規模分布式環境中部署生成式 AI 和推理模型。在 NVIDIA Blackwell 上運行開源 DeepSeek-R1 模型時,該框架最多可將請求數量提升 30 倍。NVIDIA Dynamo 與 PyTorch、SGLang 等開源工具兼容, NVIDIA TensorRT-LLM 和 vLLM,加入不斷擴大的推理工具社區,助力開發者和 AI 研究人員加速 AI。
NVIDIA Dynamo 引入了幾項關鍵創新,包括:
- 分解預填充和解碼推理階段,提高每個 GPU 的吞吐量
- 根據不斷變化的需求動態調度 GPU,以優化性能
- 可感知 LLM 的請求路由,以避免 KV 緩存重新計算成本
- 加速 GPU 之間的異步數據傳輸,縮短推理響應時間
- 跨不同內存層次結構的 KV 緩存卸載,以提高系統吞吐量
從今天開始,NVIDIA Dynamo 可供開發者在 ai-dynamo/dynamo GitHub 存儲庫中使用。對于希望縮短生產時間并獲得企業級安全性、支持和穩定性的企業,NVIDIA Dynamo 將包含在 NVIDIA NIM 微服務中,這是 NVIDIA AI Enterprise 的一部分。
本文介紹了 NVIDIA Dynamo 的架構和關鍵組件,重點介紹了它們如何促進從單個 GPU 到數千個 GPU 的生成式 AI 模型的經濟高效的分解服務和擴展。
視頻 1。了解 NVIDIA Dynamo 如何將整個 AI 模型的性能提升高達 30 倍
在多節點部署中加速 AI 推理
AI 推理將幫助開發者將推理模型集成到其工作流中,從而創建新的突破性應用,使應用能夠以更直觀的方式理解用戶并與之交互。然而,這也會產生巨大的經常性成本,對于那些希望經濟高效地擴展模型以滿足對 AI 永無止境的需求的人來說,這帶來了巨大的挑戰。
2018 年,NVIDIA 首次推出了 NVIDIA Triton Inference Server,其目標是加速 AI 創新并降低推理成本。 Triton 是首款將定制框架特定的推理服務 (包括 TensorFlow、PyTorch、ONNX、OpenVINO 等) 整合到單個統一平臺的開源 AI 推理服務器 ,可顯著降低推理成本并加快新 AI 模型的上市時間 (TTM)。
Triton 已從 NVIDIA NGC 下載超過 100 萬次,目前已被一些世界領先的組織用于在生產環境中部署 AI 模型,包括 Amazon 、 Microsoft 、 Oracle Cloud 、 DocuSign 、 Perplexity 、 Snap 等。
自 Triton 發布以來,開源模型的規模已大幅增長 (幾乎增加了 2000 倍) ,并且現在越來越多地集成到需要與多個其他模型交互的代理式 AI 工作流中。在生產環境中部署這些模型和工作流需要將它們分布到多個節點上,這需要在大型 GPU 集群中進行仔細的編排和協調。由于引入了新的分布式推理優化方法 (如 disaggregated serving) ,將對單個用戶請求的響應分散到不同的 GPU,因此復雜性進一步加劇。這使得二者之間的協作和高效數據傳輸更具挑戰性。
為應對分布式生成式 AI 推理服務的挑戰,我們將發布 NVIDIA Dynamo。NVIDIA Dynamo 是 Triton 的后續產品,基于其成功經驗,提供了一種新的模塊化架構,旨在為多節點分布式環境中的生成式 AI 模型提供服務。
NVIDIA Dynamo 支持跨 GPU 節點和動態 GPU 工作負載分配無縫擴展推理工作負載,以高效響應不斷變化的用戶需求,并處理多模型 AI 工作流中的流量瓶頸。NVIDIA Dynamo 支持所有主要的 LLM 框架,包括 NVIDIA TensorRT-LLM、vLLM 和 SGLang。它融合了先進的 LLM 推理服務優化技術,例如 disaggregated serving,將不同的推理階段分離到不同的 GPU 設備上,以提高推理性能。
將 NVIDIA GB200 NVL72 的推理性能提升 30 倍
傳統的 LLM 部署將推理的預填充和解碼階段放在單個 GPU 或節點上,盡管每個階段都有不同的資源需求。這種方法阻礙了性能優化,并使開發者無法充分利用 GPU 資源。
預填充階段處理用戶輸入以生成第一個輸出令牌,且受計算限制,而解碼階段則生成后續令牌并受內存限制。將這些階段共同放置在同一 GPU 或 GPU 節點上會導致資源使用效率低下,尤其是對于長輸入序列而言。此外,每個階段的不同硬件需求限制了模型并行的靈活性,導致錯過性能機會。
為解決這些問題,解服務將預填充和解碼階段分離到不同的 GPU 或節點上。這使得開發者能夠獨立優化每個階段,應用不同的模型并行策略,并為每個階段分配不同的 GPU 設備(圖 1)。

例如,低張量并行可用于預填充階段,以減少通信開銷,而高張量并行可改善解碼階段的內存操作。這種方法可以更高效地分配資源,降低推理服務成本,并更好地控制服務水平目標(SLO),例如 TTFT 和令牌間延遲(ITL)。
在基于 NVIDIA GB200 NVL72 為開源 DeepSeek-R1 模型提供服務時,NVIDIA Dynamo 使用解耦服務將所服務的請求數量增加了多達 30 倍。NVIDIA Dynamo 在 NVIDIA Hopper 上為 Llama 70B 模型提供服務時,吞吐量性能提高了一倍以上。

左圖:TensorRT-LLM,FP4,ISL/OSL:32K/8K。不使用 Dynamo:Inflight Batching,TEP16PP4DP4。使用 Dynamo:Disaggregated Serving,Context:EP4DP16,Generation:EP64DP3。預測性能可能會發生變化。右側:vLLM,FP8,ISL/OSL:3K/50。不使用 Dynamo:Inflight Batching,TP8DP2。使用 Dynamo:Disaggregated Serving,Context:TP2DP4,Generation:TP8。
為實現大規模分布式和解式推理服務,NVIDIA Dynamo 包含四項關鍵創新:
- NVIDIA Dynamo 規劃器
- NVIDIA Dynamo 智能路由器
- NVIDIA Dynamo 分布式 KV 緩存管理器
- NVIDIA 推理傳輸庫 (NVIDIA Inference Transfer Library, NIXL)
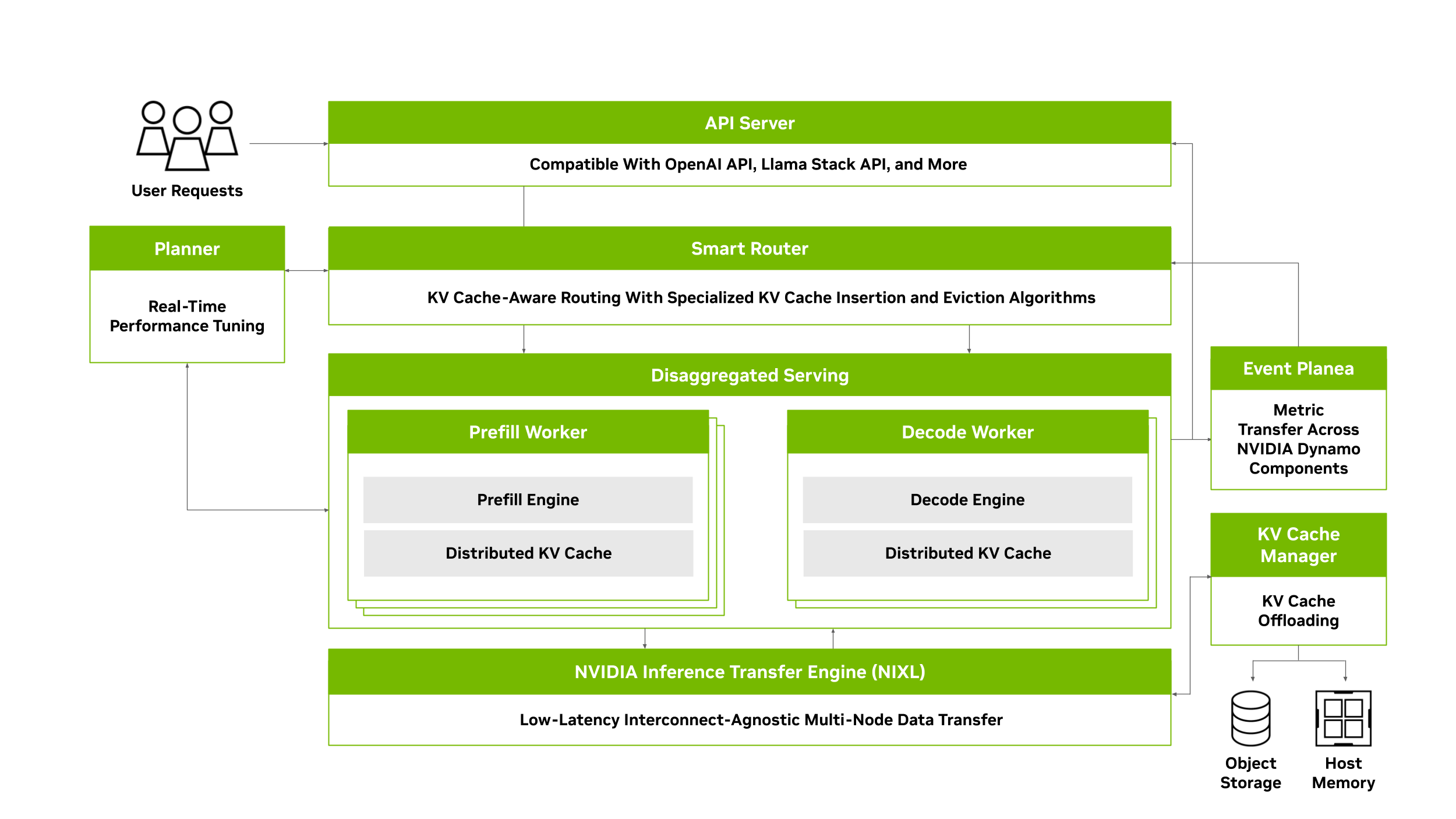
NVIDIA Dynamo Planner:針對分布式推理優化 GPU 資源
在大規模分布式和解耦服務推理系統中,高效管理 GPU 資源對于最大限度地提高吞吐量和降低延遲至關重要。雖然解耦服務可以顯著提高推理吞吐量和效率,但對于每個傳入的請求,它可能并不總是最有效的解決方案。
想象一下這樣的場景:大量具有長輸入序列長度(ISL)但短輸出序列長度(OSL)的摘要請求使預填充 GPU 不堪重負。雖然解碼 GPU 仍未得到充分利用,但預填充 GPU 成為瓶頸。在這種情況下,允許解碼 GPU 以傳統聚合方式執行預填充和解碼任務,或允許切換解碼 GPU 以執行預填充任務,可能會更高效。這種方法有助于平衡負載,減輕預填充 GPU 的壓力,并最終提高整體吞吐量。
在確定解和聚合服務之間,或為每個階段分配多少個 GPU 時,需要仔細考慮幾個因素。這些因素包括在預填充和解碼 GPU 之間傳輸 KV 緩存所需的時間、GPU 對傳入請求的隊列等待時間,以及分解和聚合配置的預計處理時間。在擁有數百個 GPU 的大規模環境中,這些決策可能會很快變得非常復雜。
這正是 NVIDIA Dynamo Planner 發揮作用的地方。它持續監控分布式推理環境中的關鍵 GPU 容量指標,并將其與應用 SLO(例如 TTFT 和 ITL)相結合,以做出明智的決策,決定是否通過或不通過分解來服務傳入的請求,或者是否應在這兩個階段中添加其他 GPU。NVIDIA Dynamo Planner 可確保在預填充和解碼之間高效分配 GPU 資源,從而適應不斷變化的工作負載,同時保持峰值系統性能。

NVIDIA Dynamo 智能路由器:減少 KV 緩存的昂貴重新計算
在響應用戶提示之前,LLMs 必須構建對輸入請求(稱為 KV 緩存)的上下文理解。此過程是計算密集型過程,會隨著輸入請求的大小而進行二次擴展。重用 KV 緩存可避免從頭開始重新計算,從而減少推理時間和計算資源。這在經常執行相同請求的用例中尤為有利,例如系統提示、單用戶多圈聊天機器人交互和代理式工作流。需要一個高效的數據管理機制來檢查何時以及何處可以重復使用 KV 緩存。
NVIDIA Dynamo 智能路由器可在多節點和解部署中追蹤大型 GPU 集群中的 KV 緩存,并高效路由傳入的請求,從而最大限度地減少對昂貴的重新計算的需求。它對傳入的請求進行哈希處理,并將其存儲在 Radix Tree 中,以便在大規模分布式推理環境中跟蹤 KV 位置。它還利用專門的算法進行 KV 緩存插入和移除,確保保留最相關的塊。

2 個 HGX-H100 節點。8 塊 DeepSeek-R1-Distill-Llama-70B。vLLM、FP8、Tensor 并行:2 D 數據源: 10 萬個真實 R1 請求,平均 ISL/OSL:4K/800
當新的推理請求到達時,NVIDIA Dynamo 智能路由器會計算傳入請求與分布式集群中所有 GPU 的所有內存中已處于活動狀態的 KV 緩存塊之間的重疊分數。通過考慮重疊分數和整個 GPU 車隊中的工作負載分配,它可以智能地將請求路由到最合適的工作節點,最大限度地減少 KV 緩存的重新計算,同時確保整個集群的負載均衡。
與循環或基于負載的路由不同,這種方法通過考慮緩存命中率、工作負載平衡和 GPU 容量來優化整體系統性能,確保高效的請求處理并消除資源瓶頸。通過減少不必要的 KV 緩存重新計算,NVIDIA Dynamo Smart Router 釋放了 GPU 資源。這使 AI 服務提供商能夠響應更多用戶請求,更大限度地提高加速計算投資的回報。
NVIDIA Dynamo 分布式 KV 緩存管理器:將 KV 緩存卸載到經濟高效的存儲中
為用戶請求計算 KV 緩存需要大量資源,因此成本高昂。重復使用 KV 緩存以最大限度地減少對其重新計算的需求是常見的做法。然而,隨著 AI 需求的增加,必須存儲在 GPU 內存中以便重復使用的 KV 緩存量可能會迅速變得過于昂貴,令人望而卻步。這給試圖在不超過預算的情況下高效管理 KV 緩存重用的 AI 推理團隊帶來了重大挑戰。
NVIDIA Dynamo KV Cache Manager 功能通過將較舊或較不頻繁訪問的 KV 緩存塊卸載到更具成本效益的內存和存儲解決方案 (例如 CPU 主機內存、本地存儲或網絡對象存儲) 來解決這一挑戰。這種能力使組織能夠存儲高達 PB 的 KV 緩存數據,而成本僅為 GPU 內存中的一小部分。通過將 KV 緩存卸載到其他內存層次結構,開發者可以釋放寶貴的 GPU 資源,同時仍然保留和重復使用歷史 KV 緩存,以降低推理計算成本。

NVIDIA Dynamo KV Cache Manager 使用高級緩存策略,優先將頻繁訪問的數據放置在 GPU 內存中,而訪問較少的數據則移動到共享 CPU 主機內存、SSD 或網絡對象存儲。它包含智能拆遷策略,可在過度緩存 (可能會導致查找延遲) 和不足緩存 (導致漏查和 KV 緩存重新計算) 之間取得平衡。
此外,此功能可以管理跨多個 GPU 節點的 KV 緩存,支持分布式和分解推理服務,并提供分層緩存功能,在 GPU、節點和集群級別創建卸載策略。
NVIDIA Dynamo KV Cache Manager 設計為與框架無關,可支持各種后端 (包括 PyTorch、SGLang、TensorRT-LLM 和 vLLM) ,并可使用 NVIDIA NVLink 、 NVIDIA Quantum 交換機和 NVIDIA Spectrum 交換機促進跨大型分布式集群擴展 KV 緩存存儲。
NVIDIA Inference Transfer Library (NIXL):低延遲、與硬件無關的通信
大規模分布式推理利用模型并行技術,如 Tensor、pipeline 和 expert 并行,這些技術依賴于節點間和節點內、低延遲、高吞吐量的通信,利用 GPUDirect RDMA。這些系統還需要在解服務環境中的預填充和解碼 GPU 工作者之間快速傳輸 KV 緩存。
此外,它們必須支持與硬件和網絡無關的加速通信庫,能夠跨 GPU 和內存層次結構(包括存儲)高效移動數據(例如 CPU 內存以及塊、文件和對象存儲),并與一系列網絡協議兼容。

NVIDIA 推理傳輸庫 (NVIDIA Inference Transfer Library, NIXL) 是一個高吞吐量、低延遲的點對點通信庫,可提供一致的數據移動 API,以便使用相同的語義在不同的內存和存儲層之間快速異步地移動數據。它專門針對推理數據移動進行了優化,支持各種類型的內存和存儲之間的非阻塞和非連續數據傳輸。
NIXL 支持異構數據路徑、不同類型的內存和本地 SSD,以及來自 NVIDIA 的主要存儲合作伙伴的網絡存儲。
借助 NIXL,無論傳輸是通過 NVLink (C2C 或 NVSwitch) 、InfiniBand、RoCE 還是 Ethernet 進行,NVIDIA Dynamo 都能使用通用 API 與其他通信庫交互,例如 GPUDirect Storage、UCX 和 S3。NIXL 與 NVIDIA Dynamo 策略引擎相結合,可自動選擇最佳后端連接,并抽象出多種類型的內存和存儲之間的差異。這是通過通用的“內存部分”實現的,這些“內存部分”可以是 HBM、DRAM、本地 SSD 或網絡存儲 (Block、Object 或 File)。
開始使用 NVIDIA Dynamo
現代 LLM 在參數大小、推理能力方面進行了擴展,并且越來越多地嵌入到代理式 AI 工作流中。因此,它們在推理過程中會生成更多的 token,并且需要在分布式環境中進行部署,從而導致成本增加。因此,優化推理服務策略以降低成本并支持分布式環境中的無縫擴展至關重要。
NVIDIA Dynamo 在其前代 NVIDIA Triton 的成功基礎上構建,具有新的模塊化架構、分布式推理功能以及對解服務的支持,使其能夠在多節點部署中提供出色的擴展性能。
部署新生成式 AI 模型的開發者現在可以從 ai-dynamo/dynamo GitHub repo 開始。AI 推理開發者和研究人員受邀在 GitHub 上為 NVIDIA Dynamo 做出貢獻。加入新的 NVIDIA Dynamo Discord 服務器 ,這是 NVIDIA 官方服務器,面向分布式推理框架 NVIDIA Dynamo 的開發者和用戶。
使用 SGLang、TensorRT-LLM 或 vLLM 作為后端的 Triton 用戶可以在 NVIDIA Dynamo 中部署這些后端,以在大規模部署中獲得分布式和解耦的推理服務的優勢。擁有其他 AI 后端的 Triton 用戶可以探索 NVIDIA Dynamo,并使用 GitHub 上的技術文檔指南和教程創建將 AI 工作負載過渡到 NVIDIA Dynamo 的遷移計劃。使用 Triton 的 NVIDIA AI Enterprise 客戶將繼續獲得針對其現有 Triton 部署的生產分支支持。NVIDIA Dynamo 計劃由 NVIDIA AI Enterprise 提供支持 ,并通過 NVIDIA NIM 微服務提供,以實現快速輕松的部署。
?
?





