圖靈體系結構通過使用 網格著色器 引入了一種新的可編程幾何著色管道。新的著色器將計算編程模型引入到圖形管道中,因為協同使用線程在芯片上直接生成緊湊網格( meshlets ),供光柵化器使用。處理高幾何復雜度的應用程序和游戲得益于兩階段方法的靈活性,該方法允許有效的剔除、詳細程度的技術以及程序生成。
這篇博客介紹了新的管道,并給出了 GLSL 中用于 OpenGL 或 Vulkan 渲染的一些具體示例。新功能可以通過 OpenGL 和 Vulkan 中的擴展以及使用 DirectX 12 旗艦版 來訪問。
以下大部分內容摘自此 錄制的演示文稿 ,稍后將提供完整的幻燈片。
動機
?
現實世界是一個視覺豐富、幾何復雜的地方。尤其是室外場景可以由數十萬種元素(巖石、樹木、小植物等)組成。 CAD 模型在復雜形狀的表面以及由許多小零件組成的機械上都存在類似的挑戰。在視覺效果中,大型結構,例如宇宙飛船,通常都用“ greebles ”來詳細說明。圖 1 顯示了幾個例子,其中,具有頂點、細分和幾何體著色器的圖形管道、實例化和間接多重繪制雖然非常有效,但當全分辨率幾何體達到數億個三角形和數十萬個對象時,仍然會受到限制。

上面未顯示的其他用例包括在科學計算中發現的幾何圖形(粒子、字形、代理對象、點云)或程序形狀( ele CTR ic 工程布局、 vfx 粒子、帶狀和軌跡、路徑渲染)。
在這篇文章中,我們研究了 網格著色器 來加速重三角形網格的渲染。原始網格被分割成更小的 meshlets ,如圖 2 所示。理想情況下,每個網格都可以優化其中的頂點重用。使用新的硬件階段和這種分割方案,我們可以并行地繪制更多的幾何圖形,同時獲取較少的總體數據。
 |
 |
例如, CAD 數據可以達到幾千萬到數億個三角形。即使在 遮擋篩選 之后,也可以存在大量的三角形。在這種情況下,管道中的某些固定函數步驟可能會造成浪費的工作和內存負載:
- 通過硬件的 原始分配器 每次掃描 indexbuffer 來批量創建頂點,即使拓撲結構沒有改變
- 獲取不可見數據的頂點和屬性(背面、視錐體或亞像素剔除)
網格著色器 為開發人員提供了避免此類瓶頸的新可能性。(例如,在第 4 個緩存中,與第 4 個緩存相對應)的方法(例如,在第 4 個緩存中,直接讀取第 4 個三角形)。
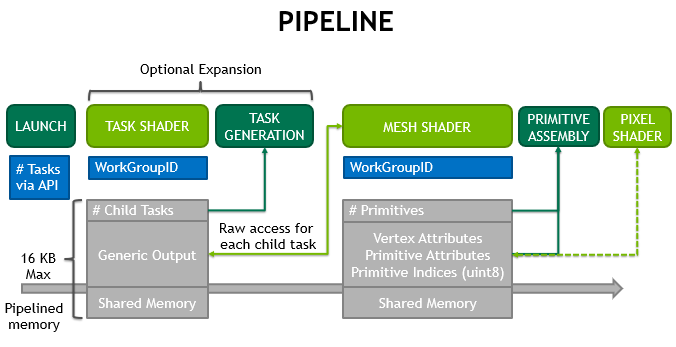
網格著色器階段為光柵化器生成三角形,但在內部使用協作線程模型,而不是使用單線程程序模型,類似于計算著色器。管道中網格著色器前面是任務著色器。任務著色器的操作類似于細分的控制階段,因為它能夠動態生成工作。但是,與網格著色器一樣,它使用協作線程模型,而不是將面片作為輸入,將細分決策作為輸出,而是用戶定義其輸入和輸出。
這簡化了片上幾何體的創建,與之前嚴格且有限的細分和幾何體著色器相比,后者只需將線程用于特定任務,如圖 3 所示。
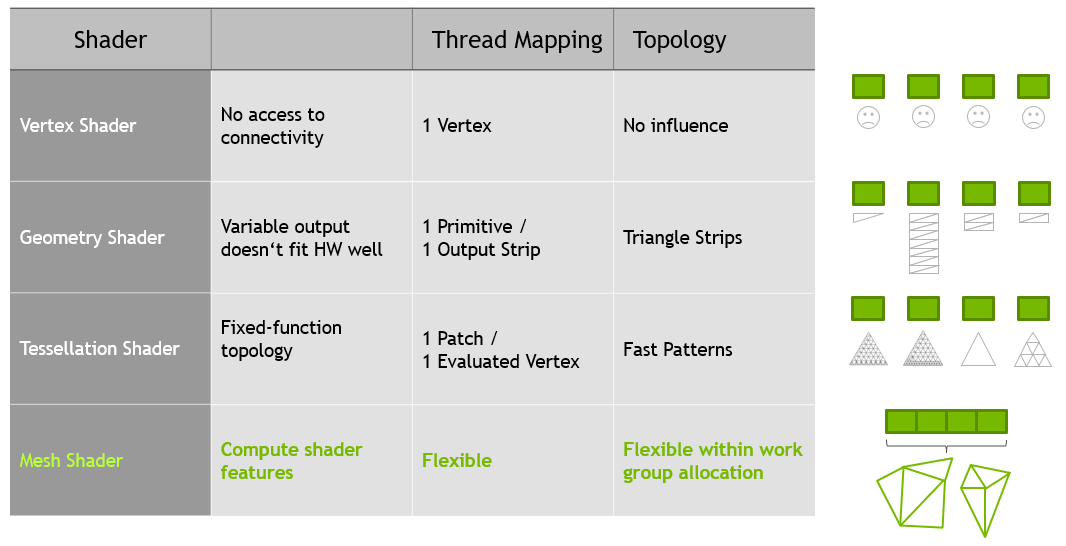
網格著色管線
一個新的兩階段管道替代方案補充了經典的屬性獲取 頂點、細分、幾何體著色器 管道。這條新管道由 任務著色器 和 網格著色器: 組成
- 任務著色器 :可編程單元,在工作組中工作,允許每個單元發射(或不發射)網格著色器工作組
- 網格著色器 :一種可編程單元,在工作組中運行,允許每個工作組生成原語
mesh shader stage 在內部使用上述協作線程模型為光柵化器生成三角形。任務著色器的操作類似于細分的外殼著色器階段,因為它能夠動態生成工作。但是,與網格著色器一樣,任務著色器也使用協作線程模式。它的輸入和輸出是用戶定義的,而不必將面片作為輸入,將細分決策作為輸出。
與 像素/片段著色器 的接口不受影響。傳統的管道仍然可用,并且可以根據用例提供非常好的結果。圖 4 突出顯示了管道樣式的差異。
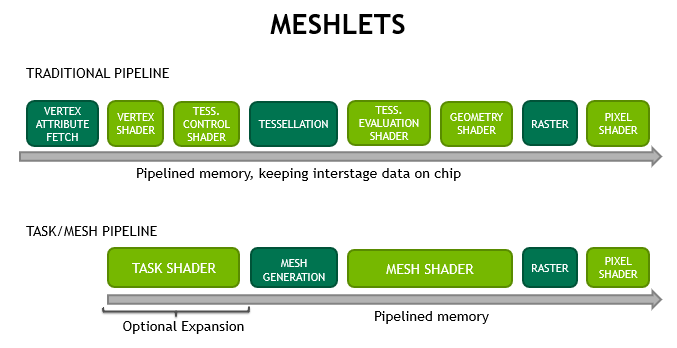
新的網格著色器管道為開發人員提供了許多好處:
- 更高的可擴展性 通過著色器單元來減少原語處理中的固定函數影響。現代 GPUs 的通用用途有助于更多種類的應用程序添加更多內核,并提高著色器的通用內存和算術性能。
- Bandwidth-reduction ,因為頂點的重復數據消除(頂點重用)可以預先完成,并且可以在多個幀上重復使用。當前的 API 模型意味著每次硬件都必須掃描索引緩沖區。較大的網格意味著更高的頂點重用率,也降低了帶寬要求。此外,開發人員可以提出自己的壓縮或過程生成方案。
通過 任務著色器 進行可選的擴展/篩選允許跳過完全獲取更多數據。 - Flexibility 定義網格拓撲和創建圖形工作。以前的 細分著色器 僅限于固定的鑲嵌模式,而 幾何著色器 則存在線程效率低下、編程模型不友好的問題,每個線程都會創建三角形條帶。
網格著色遵循 計算著色器 的編程模型,使開發人員可以自由地將線程用于不同的用途,并在線程之間共享數據。當光柵化被禁用時,這兩個階段還可以用于執行具有一個級別擴展的通用計算工作。
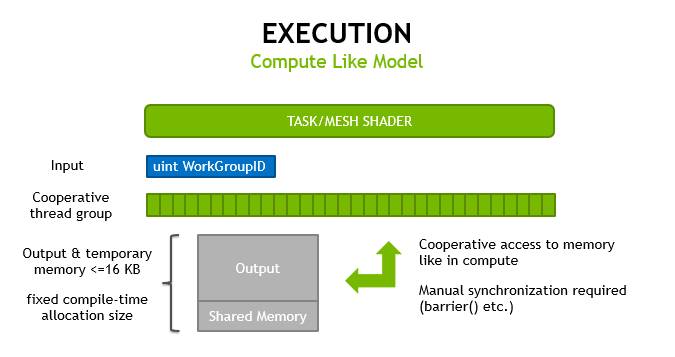
這兩個 網格和任務著色器 都遵循 計算著色器 的編程模型,使用協作線程組來計算結果,并有 除工作組索引外沒有其他輸入 。它們在圖形管道上執行;因此硬件直接管理在級之間傳遞并保存在芯片上的內存。
我們將展示一個例子,說明如何使用它來進行基本體剔除,因為線程稍后可以訪問工作組中的所有頂點。圖 6 說明了任務著色器處理早期剔除的能力。
通過 任務著色器 進行的可選擴展允許對一組原語進行早期篩選或預先做出 LOD 決策。該機制在 GPU 上縮放,因此取代了小網格的實例化或多重繪制間接。此配置類似于 細分控制著色器 設置細分補丁(~ task workgroup )的數量,然后影響創建的 細分評估 調用(~ mesh workgroups )的數量。
單個 任務工作組 可以發射的 工作網格組 數量是有限制的。第一代硬件支持最多 64K 個子級,可以生成 每個任務 。在同一個繪制調用中,所有任務的網格子對象的總數沒有限制。同樣,如果不使用 任務著色器 ,則對 draw 調用生成的網格工作組的數量沒有限制。圖 7 說明了這是如何工作的。
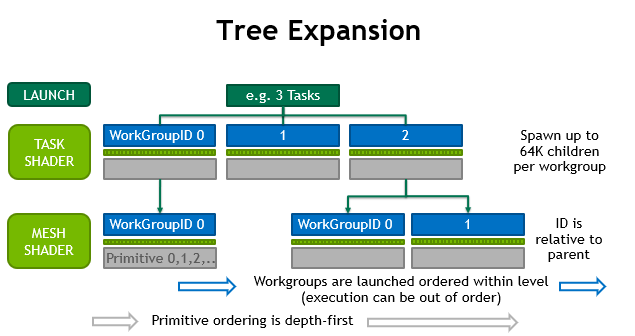
任務 T 的子任務保證在任務 T-1 的子任務之后啟動。但是, task 和 mesh 工作組是完全流水線的,因此不需要等待以前的子任務或任務的完成。
任務著色器 應用于動態工作生成或過濾。靜態設置得益于單獨使用 網格著色器 。
網格及其內部圖元的柵格化輸出順序保持不變。禁用光柵化后,任務著色器和網格著色器都可以用于實現基本計算樹。
網格和網格著色
每個網格單元表示數量可變的頂點和基本體。對于這些原語的連接性沒有限制。但是,它們必須保持在著色器代碼中指定的最大值以下。
3 * 126 + 4 最大化了 3 * 128 = 384 字節塊的大小。超過 126 個三角形將分配接下來的 128 個字節。 84 和 40 是其他適用于三角形的最大值。在每個 GLSL mesh-shader 代碼中,每個工作組在圖形管道中為每個工作組分配固定數量的網格內存。
最大尺寸和原始輸出定義如下:
每個網格單元的分配大小取決于編譯時大小信息以及著色器引用的輸出屬性。分配越小,可以在硬件上并行執行的工作組越多。與 compute 一樣,工作組共享他們可以訪問的片上內存的公共部分。因此,我們建議您盡可能高效地使用所有輸出或共享內存。對于當前著色器,這已經是正確的。但是,內存占用可能會更高,因為我們允許比當前編程中更多的頂點和基元。
// Set the number of threads per workgroup (always one-dimensional). // The limitations may be different than in actual compute shaders. layout(local_size_x=32) in; // the primitive type (points,lines or triangles) layout(triangles) out; // maximum allocation size for each meshlet layout(max_vertices=64, max_primitives=126) out; // the actual amount of primitives the workgroup outputs ( <= max_primitives) out uint gl_PrimitiveCountNV; // an index buffer, using list type indices (strips are not supported here) out uint gl_PrimitiveIndicesNV[]; // [max_primitives * 3 for triangles]
圖靈支持另一個新的 GLSL 擴展, NV_fragment_shader_barycentric ,它使片段著色器能夠獲取構成一個基本體的三個頂點的原始數據,并手動對其進行插值。這種原始訪問意味著我們可以輸出“ uint ”頂點屬性,但是使用各種 pack / unpack 函數將浮點存儲為 fp16 、 unorm8 或 snorm8 。這可以大大減少法線、紋理坐標和基本顏色值的逐頂點占用空間,并有利于標準和網格著色管道。
頂點和基本體的其他屬性定義如下:
out gl_MeshPerVertexNV {
vec4 gl_Position;
float gl_PointSize;
float gl_ClipDistance[];
float gl_CullDistance[];
} gl_MeshVerticesNV[]; // [max_vertices]
// define your own vertex output blocks as usual
out Interpolant {
vec2 uv;
} OUT[]; // [max_vertices]
// special purpose per-primitive outputs
perprimitiveNV out gl_MeshPerPrimitiveNV {
int gl_PrimitiveID;
int gl_Layer;
int gl_ViewportIndex;
int gl_ViewportMask[]; // [1]
} gl_MeshPrimitivesNV[]; // [max_primitives]
一個目標是擁有最小數量的網格,從而最大限度地提高網格中頂點的重用率,從而減少分配的浪費。在生成 meshlet 數據之前,在 indexbuffer 上應用頂點緩存優化器是有益的。例如, Tom Forsyth 的線性速度優化器 可用于此。優化頂點位置和索引緩沖區也是有益的,因為使用 網格著色器 時,原始三角形的順序將保持不變。 CAD 模型通常是用條帶“自然”生成的,因此可以具有良好的數據局部性。更改索引緩沖區可能會對此類數據的 meshlet 的簇剔除屬性產生負面影響(請參見任務級消隱)。
預計算網格
例如,我們呈現靜態內容,其中 索引緩沖區 在許多幀中沒有變化。因此,在將頂點/索引上載到設備內存期間,生成網格數據的成本可以隱藏起來。當 vertex 數據也是靜態的(沒有逐頂點動畫;頂點位置沒有變化)時,還可以獲得額外的好處,允許預先計算對快速剔除整個網格單元有用的數據。
?
數據結構
在以后的示例中,我們將提供一個 meshlet 構建器,它包含一個基本實現,該實現掃描所提供的索引,并在每次遇到大小限制(頂點或基元計數)時創建一個新的 meshlet 。
對于輸入三角形網格,它將生成以下數據:
struct MeshletDesc { uint32_t vertexCount; // number of vertices used uint32_t primCount; // number of primitives (triangles) used uint32_t vertexBegin; // offset into vertexIndices uint32_t primBegin; // offset into primitiveIndices } std::vector<meshletdesc> meshletInfos; std::vector<uint8_t> primitiveIndices; // use uint16_t when shorts are sufficient std::vector<uint32_t> vertexIndices;
為什么有兩個索引緩沖區?
以下原始三角形索引緩沖區序列
// let's look at the first two triangles of a batch of many more triangleIndices = { 4,5,6, 8,4,6, ...}
分為兩個新的索引緩沖區。
當我們迭代三角形索引時,我們建立了一組唯一的頂點索引。此過程也稱為 頂點重復數據消除 。
vertexIndices = { 4,5,6, 8, ...}
// For the second triangle only vertex 8 must be added
// and the other vertices are re-used.
原始索引相對于 vertexIndices 項進行調整。
// original data triangleIndices = { 4,5,6, 8,4,6, ...} // new data primitiveIndices = { 0,1,2, 3,0,2, ...} // the primitive indices are local per meshlet
一旦達到適當的大小限制(要么是唯一頂點太多,要么是基本體太多),就會啟動一個新的網格單元。隨后的網格將創建自己的唯一頂點集。
呈現資源和數據流
在渲染期間,我們使用原始頂點緩沖區。但是,我們使用了三個新的緩沖區,而不是原來的三角形索引緩沖區,如下圖 8 所示:
- 頂點索引緩沖區 如上所述。每個網格單元引用一組唯一的頂點。這些頂點的索引按順序存儲在所有網格單元的緩沖區中。
- 原始索引緩沖區 如上所述。每個網格單元表示不同數量的基本體。每個三角形需要三個原始索引,這些索引存儲在一個緩沖區中。 Note :可以在每個 meshlet 之后添加額外的索引以獲得四字節對齊。
- Meshlet Desc 緩沖區。 存儲每個網格單元的工作負載和緩沖區偏移信息,以及集群剔除信息。
這三個緩沖區實際上比原始索引緩沖區小,因為網格著色允許更高的頂點重用。我們注意到,通常會將索引緩沖區大小減少到原始索引緩沖區大小的 75% 左右。
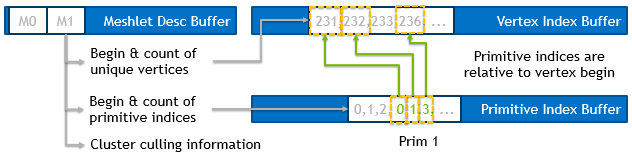
- 網格頂點:
vertexBegin存儲開始獲取頂點索引的起始位置。vertexCount存儲所涉及的連續頂點的數量。頂點在網格單元中是唯一的;沒有重復的索引值。 - 網格元素:
primBegin存儲原始索引的起始位置,我們將從那里開始獲取索引。primCount存儲 meshlet 中涉及的基本體數量。注意,索引的數量取決于基本體類型(這里: 3 表示三角形)。請注意,索引引用的是相對于vertexBegin的頂點,這意味著索引“ 0 ”將引用位于vertexBegin的頂點索引。
下面的偽代碼描述了每個 網格著色器 工作組在原則上執行的操作。它是串行的,僅用于說明目的。
// This code is just a serial pseudo code, // and doesn't reflect actual GLSL code that would // leverage the workgroup's local thread invocations. for (int v = 0; v < meshlet.vertexCount; v++){ int vertexIndex = texelFetch(vertexIndexBuffer, meshlet.vertexBegin + v).x; vec4 vertex = texelFetch(vertexBuffer, vertexIndex); gl_MeshVerticesNV[v].gl_Position = transform * vertex; } for (int p = 0; p < meshlet.primCount; p++){ uvec3 triangle = getTriIndices(primitiveIndexBuffer, meshlet.primBegin + p); gl_PrimitiveIndicesNV[p * 3 + 0] = triangle.x; gl_PrimitiveIndicesNV[p * 3 + 1] = triangle.y; gl_PrimitiveIndicesNV[p * 3 + 2] = triangle.z; } // one thread writes the output primitives gl_PrimitiveCountNV = meshlet.primCount;
當以并行方式編寫時,網格著色器可能看起來如下所示:
void main() { ... // As the workgoupSize may be less than the max_vertices/max_primitives // we still require an outer loop. Given their static nature // they should be unrolled by the compiler in the end. // Resolved at compile time const uint vertexLoops = (MAX_VERTEX_COUNT + GROUP_SIZE - 1) / GROUP_SIZE; for (uint loop = 0; loop < vertexLoops; loop++){ // distribute execution across threads uint v = gl_LocalInvocationID.x + loop * GROUP_SIZE; // Avoid branching to get pipelined memory loads. // Downside is we may redundantly compute the last // vertex several times v = min(v, meshlet.vertexCount-1); { int vertexIndex = texelFetch( vertexIndexBuffer, int(meshlet.vertexBegin + v)).x; vec4 vertex = texelFetch(vertexBuffer, vertexIndex); gl_MeshVerticesNV[v].gl_Position = transform * vertex; } } // Let's pack 8 indices into RG32 bit texture uint primreadBegin = meshlet.primBegin / 8; uint primreadIndex = meshlet.primCount * 3 - 1; uint primreadMax = primreadIndex / 8; // resolved at compile time and typically just 1 const uint primreadLoops = (MAX_PRIMITIVE_COUNT * 3 + GROUP_SIZE * 8 - 1) / (GROUP_SIZE * 8); for (uint loop = 0; loop < primreadLoops; loop++){ uint p = gl_LocalInvocationID.x + loop * GROUP_SIZE; p = min(p, primreadMax); uvec2 topology = texelFetch(primitiveIndexBuffer, int(primreadBegin + p)).rg; // use a built-in function, we took special care before when // sizing the meshlets to ensure we don't exceed the // gl_PrimitiveIndicesNV array here writePackedPrimitiveIndices4x8NV(p * 8 + 0, topology.x); writePackedPrimitiveIndices4x8NV(p * 8 + 4, topology.y); } if (gl_LocalInvocationID.x == 0) { gl_PrimitiveCountNV = meshlet.primCount; }
這就是一個直接的例子。由于所有數據獲取都是由開發人員完成的,自定義編碼、通過子組內部函數或共享內存進行解壓縮,或者暫時使用頂點輸出,都可以節省額外的帶寬。
使用任務著色器進行簇消隱
我們嘗試將更多的信息壓縮到一個 meshlet 描述符中以執行早期剔除。我們已經嘗試使用 128 位描述符對前面提到的值進行編碼,以及 G.Wihlidal 提出的用于背面聚類剔除的相對 bbox 和一個圓錐體。在生成網格時,需要在良好的簇剔除特性和改進的頂點重用之間取得平衡。一方可能對另一方產生負面影響。
下面的任務著色器最多可剔除 32 個網格。
layout(local_size_x=32) in;
taskNV out Task {
uint baseID;
uint8_t subIDs[GROUP_SIZE];
} OUT;
void main() {
// we padded the buffer to ensure we don't access it out of bounds
uvec4 desc = meshletDescs[gl_GlobalInvocationID.x];
// implement some early culling function
bool render = gl_GlobalInvocationID.x < meshletCount && !earlyCull(desc);
uvec4 vote = subgroupBallot(render);
uint tasks = subgroupBallotBitCount(vote);
if (gl_LocalInvocationID.x == 0) {
// write the number of surviving meshlets, i.e.
// mesh workgroups to spawn
gl_TaskCountNV = tasks;
// where the meshletIDs started from for this task workgroup
OUT.baseID = gl_WorkGroupID.x * GROUP_SIZE;
}
{
// write which children survived into a compact array
uint idxOffset = subgroupBallotExclusiveBitCount(vote);
if (render) {
OUT.subIDs[idxOffset] = uint8_t(gl_LocalInvocationID.x);
}
}
}
相應的網格著色器現在使用來自任務著色器的信息來標識要生成的網格。
taskNV in Task {
uint baseID;
uint8_t subIDs[GROUP_SIZE];
} IN;
void main() {
// We can no longer use gl_WorkGroupID.x directly
// as it now encodes which child this workgroup is.
uint meshletID = IN.baseID + IN.subIDs[gl_WorkGroupID.x];
uvec4 desc = meshletDescs[meshletID];
...
}
我們只在渲染大三角形模型的上下文中剔除任務著色器中的網格。其他場景可能涉及到根據細節決策的級別選擇不同的 meshlet 數據,或者完全生成幾何體(粒子、色帶等)。下面的圖 9 來自一個使用任務著色器進行詳細級別計算的演示。

?
Conclusion
一些關鍵的收獲:
- 通過掃描索引緩沖區一次,可以將三角形網格轉換為網格。頂點緩存優化器有助于經典渲染,也有助于提高網格填充效率。更復雜的聚類允許改進任務著色器階段的早期拒絕(更緊密的邊界框、一致的三角形法線等)。
- 在硬件需要為片上 網格著色器 調用分配頂點/基元內存之前, 任務著色器 允許提前跳過一組原語。如果需要,它還可以生成多個子調用。
- 頂點在工作組的線程中并行處理,就像原始的 頂點渲染 一樣。
- 頂點著色器 可以與 網格著色器 兼容,并帶有一些預處理器插入。
- 由于更高的頂點重用,需要提取的數據更少(經典頂點著色器的操作限制為 max _ vertices = 32 , max _ primitives = 32 )。平均三角形網格價意味著使用兩倍數量的三角形作為頂點是有益的。
- 所有數據加載都是通過著色器指令來處理的,而不是經典的固定函數原語 fetch ,因此使用更多的 流式多處理器 可以更好地伸縮。它還允許更容易地使用自定義頂點編碼來進一步減少帶寬。
- 對于頂點屬性的大量使用,同樣并行操作的基本消隱階段可能是有益的。我們可以剔除掉頂點數據。然而,最好的收獲是在任務級別進行有效的篩選。
您可以找到關于圖靈體系結構 here 的更多信息。請在下面的評論部分添加您的想法。示例代碼和驅動程序支持將很快提供。如果您是使用圖靈高級著色器的 NVIDIA 開發人員,請查看 游戲開發者論壇 ,在那里您可以與 NVIDIA 開發人員社區進行交互。
References
- [1]: 倫斯的藝術
- [2]: 克里斯·克里斯蒂安攝 – 模特拉塞爾·伯克夫
- [3]: 使用 Compute 優化圖形管道– Graham Wihlided
- [4]: GPU – 驅動渲染管道 -Ulrich Haar & Sebastian Aaltonen
- [5]: 過濾和剔除的可見性緩沖區—— Wolfgang Engel
附錄: SIGGRAPH 演示
以下是完整的 SIGGRAPH 演示文稿,在此基礎上撰寫此博客,以供您瀏覽。
?