更新: Jetson Nano 和 JetBot 網絡研討會 我們對 Jetson Nano 和 JetBot 非常感興趣,因此我們將舉辦兩次網絡研討會來討論這些主題。 Jetson Nano 網絡研討會討論了如何實現機器學習框架、在 Ubuntu 中開發、運行基準測試以及集成傳感器。 注冊 Jetson 納米網絡研討會。 Jetbot 網絡研討會提供了 Python GPIO 庫教程和關于如何使用 Jetbot 訓練神經網絡和執行實時對象檢測的信息。 注冊參加 JetBot 網絡研討會。 這兩個網絡研討會大約有一個小時長,最后都有一個問答環節。

GPU 在 2019 年 NVIDIA NVIDIA 技術會議( GTC )上宣布推出了 Jetson Nano 開發者套件 ,這是一款售價 99 美元的計算機,目前可供嵌入式設計師、研究人員和 DIY 制造商使用,在一個緊湊、易于使用的平臺上實現了現代人工智能的強大功能,具有完全的軟件可編程性。 Jetson Nano 通過一個四核 64 位 ARMCPU 和一個 128 核集成的 NVIDIA GPU ,提供 472 GFLOPS 的計算性能。它還包括 4GB LPDDR4 內存在一個高效的低功耗封裝中,具有 5W / 10W 電源模式和 5V 直流輸入,如圖 1 所示。
最新發布的 JetPack 4 . 2 SDK 開發包 為基于 Ubuntu 18 . 04 的 Jetson Nano 提供了一個完整的桌面 Linux 環境,支持加速的圖形,支持 NVIDIA CUDA toolk10 . 0 ,以及 cuDNN 7 . 3 和 TensorRT 5 等庫。 SDK 還包括在本地安裝流行的開源機器學習( ML )框架,如 TensorFlow , PyTorch 、 Caffe 、 Keras 和 MXNet ,以及 OpenCV 和 ROS 等計算機視覺和機器人開發框架。
與這些框架和 NVIDIA 領先的人工智能平臺完全兼容,使得將基于人工智能的推理工作負載部署到 Jetson 上比以往任何時候都容易。 Jetson Nano 為各種復雜的深層神經網絡( DNN )模型帶來了實時計算機視覺和推理。這些功能使多傳感器自主機器人、具有智能邊緣分析的物聯網設備和先進的人工智能系統成為可能。甚至傳輸學習也可以使用 ML 框架在 Jetson Nano 上重新訓練網絡。
Jetson Nano 開發套件的尺寸僅為 80×100 毫米,具有四個高速 USB 3 . 0 端口、 MIPI CSI-2 攝像頭接口、 HDMI 2 . 0 和 DisplayPort 1 . 3 、千兆以太網、 M . 2 Key-E 模塊、 MicroSD 卡插槽和 40 針 GPIO 頭。端口和 GPIO 頭可以與各種流行的外圍設備、傳感器和現成的項目一起使用,例如 NVIDIA 在 GitHub 上開源的 3D 可打印深度學習 噴氣式飛機。 。
devkit 從一個可移動 MicroSD 卡啟動,該卡可以在任何帶有 SD 卡適配器的 PC 上格式化和成像。 devkit 可以方便地通過 Micro-USB 端口或 5V 直流桶形插孔適配器供電。攝像頭連接器與價格合理的 MIPI CSI 傳感器兼容,包括基于 8MP IMX219 的模塊,可從 Jetson 生態系統合作伙伴處獲得。同時支持的還有 Raspberry Pi 攝像頭模塊 v2 ,它包括 JetPack 中的驅動程序支持。主要規格見表 1 。
| Processing | ? |
| CPU | 64-bit Quad-core ARM A57 @ 1.43GHz |
| GPU | 128-core NVIDIA Maxwell @ 921MHz |
| Memory | 4GB 64-bit LPDDR4 @ 1600MHz | 25.6 GB/s |
| Video Encoder* | 4Kp30 | (4x) 1080p30 | (2x) 1080p60 |
| Video Decoder* | 4Kp60 | (2x) 4Kp30 | (8x) 1080p30 | (4x) 1080p60 |
| Interfaces | ? |
| USB | 4x USB 3.0 A (Host) | USB 2.0 Micro B (Device) |
| Camera | MIPI CSI-2 x2 (15-position Flex Connector) |
| Display | HDMI | DisplayPort |
| Networking | Gigabit Ethernet (RJ45) |
| Wireless | M.2 Key-E with PCIe x1 |
| Storage | MicroSD card (16GB UHS-1 recommended minimum) |
| Other I/O | (3x) I2C | (2x) SPI | UART | I2S | GPIOs |
devkit 是圍繞一個 260 針 SODIMM 風格的系統 on Module ( SoM )構建的,如圖 2 所示。 SoM 包含處理器、內存和電源管理電路。 Jetson 納米計算模塊尺寸為 45x70mm ,將于 2019 年 6 月開始發貨,售價 129 美元( 1000 單位體積),供嵌入式設計師集成到生產系統中。生產計算模塊將包括 16GB eMMC 板載存儲和增強 I / O , PCIe Gen2 x4 / x2 / x1 、 MIPI DSI 、附加 GPIO 和 12 通道 MIPI CSI-2 在 x4 / x2 配置中,最多可連接三個 x4 攝像頭或四個攝像頭。 Jetson 的統一內存子系統在 CPU 、 GPU 和多媒體引擎之間共享,提供了流線型的零拷貝傳感器攝取和高效的處理管道。

深度學習推理基準
Jetson Nano 可以運行多種高級網絡,包括流行 ML 框架的完整本機版本,如 TensorFlow 、 PyTorch 、 Caffe / Caffe2 、 Keras 、 MXNet 等。這些網絡可用于構建自主機器和復雜的人工智能系統,實現強大的功能,如圖像識別、目標檢測和定位、姿勢估計、語義分割、視頻增強和智能分析。
圖 3 顯示了來自在線可用的流行模型的推理基準測試的結果。有關在您的 Jetson Nano 上運行這些基準測試的說明,請參見 在這里 。該推斷使用批次大小 1 和 FP16 精度,使用了 Jetpack4 . 2 中包含的 NVIDIA 的 TensorRT 加速器庫。 Jetson Nano 在許多場景下都能達到實時性能,并且能夠處理多個高清視頻流。
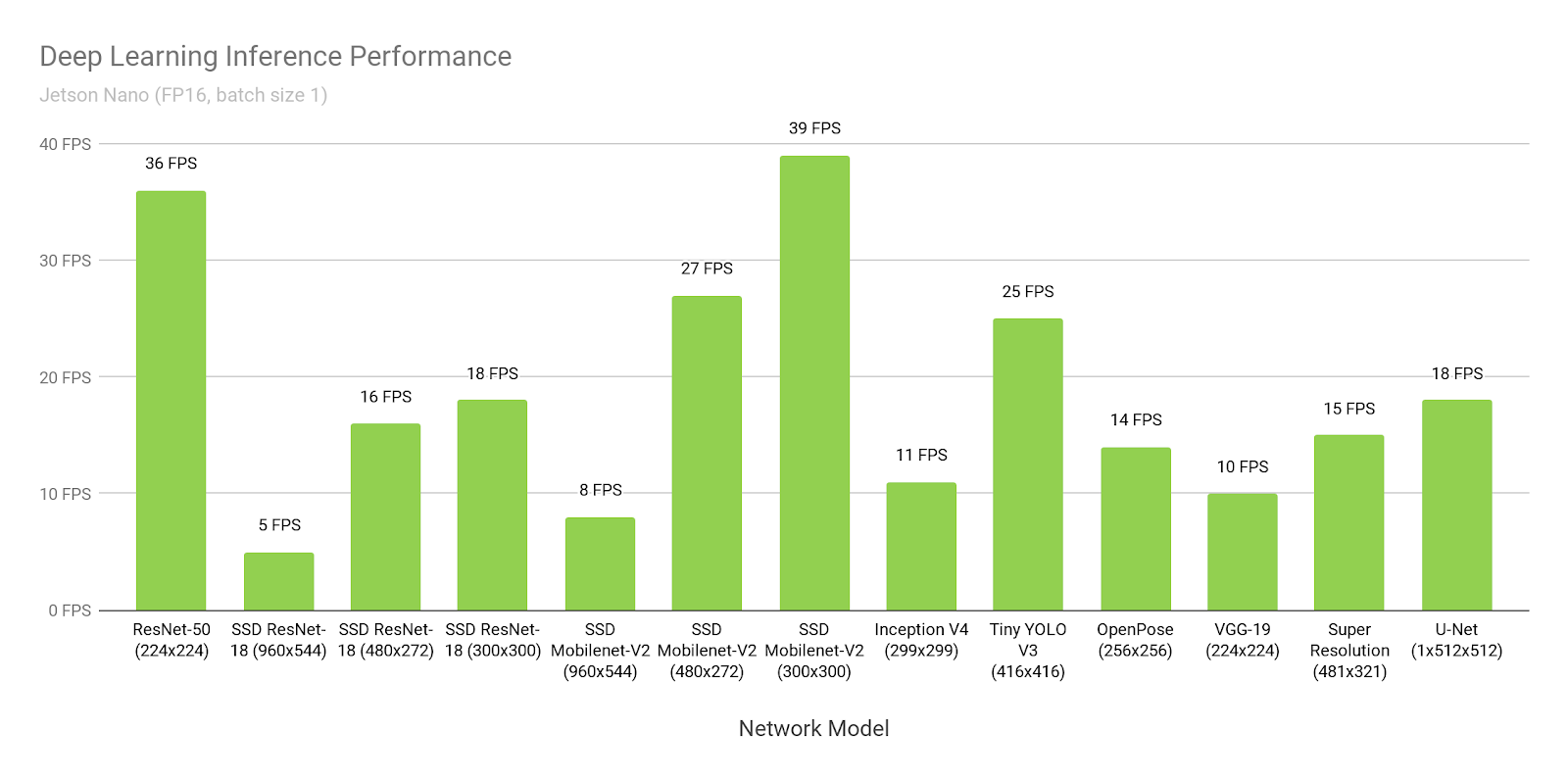
表 2 提供了完整的結果,包括 Raspberry Pi3 、 Intel Neural Compute Stick 2 和 Google Edge TPU Coral Dev Board 等其他平臺的性能:
| Model | Application | Framework | NVIDIA Jetson Nano | Raspberry Pi 3 | Raspberry Pi 3 + Intel Neural Compute Stick 2 | Google Edge TPU?Dev Board |
| ResNet-50 (224×224) |
Classification | TensorFlow | 36 FPS | 1.4 FPS | 16 FPS | DNR |
| MobileNet-v2 (300×300) |
Classification | TensorFlow | 64 FPS | 2.5 FPS | 30 FPS | 130 FPS |
| SSD ResNet-18 (960×544) | Object Detection | TensorFlow | 5 FPS | DNR | DNR | DNR |
| SSD ResNet-18 (480×272) | Object Detection | TensorFlow | 16 FPS | DNR | DNR | DNR |
| SSD ResNet-18 (300×300) | Object Detection | TensorFlow | 18 FPS | DNR | DNR | DNR |
| SSD Mobilenet-V2 (960×544) | Object Detection |
TensorFlow | 8 FPS | DNR | 1.8 FPS | DNR |
| SSD Mobilenet-V2 (480×272) | Object Detection | TensorFlow | 27 FPS | DNR | 7 FPS | DNR |
| SSD Mobilenet-V2
? (300×300) |
Object Detection | TensorFlow | 39 FPS | 1 FPS | 11 FPS | 48?FPS |
| Inception V4
? (299×299) |
Classification | PyTorch | 11 FPS | DNR | DNR | 9?FPS |
| Tiny YOLO V3
? (416×416) |
Object Detection | Darknet | 25 FPS | 0.5 FPS | DNR | DNR |
| OpenPose
? (256×256) |
Pose Estimation | Caffe | 14 FPS | DNR | 5 FPS | DNR |
| VGG-19 (224×224) | Classification | MXNet | 10 FPS | 0.5 FPS | 5 FPS | DNR |
| Super Resolution (481×321) | Image Processing | PyTorch | 15 FPS | DNR | 0.6 FPS | DNR |
| Unet
? (1x512x512) |
Segmentation | Caffe | 18 FPS | DNR | 5 FPS | DNR |
由于內存容量有限、不受支持的網絡層或硬件/軟件限制,經常出現 DNR (未運行)結果。固定函數神經網絡加速器通常支持相對狹窄的用例集,硬件支持專用層操作,網絡權重和激活需要適應有限的片上緩存,以避免嚴重的數據傳輸損失。它們可以依靠主機 CPU 來運行硬件不支持的層,并且可能依賴于支持框架的簡化子集的模型編譯器(例如 TFLite )。
Jetson Nano 靈活的軟件和完整的框架支持、內存容量和統一的內存子系統,使其能夠運行各種不同的網絡,達到全高清分辨率,包括同時在多個傳感器流上運行可變的批量大小。這些基準測試代表了流行網絡的一個樣本,但是用戶可以在 Jetson Nano 上部署各種模型和定制架構,從而提高性能。而且 Jetson Nano 不僅僅局限于 DNN 推斷。它的 CUDA 體系結構可用于計算機視覺和數字信號處理( DSP ),使用包括 FFT 、 BLAS 和 LAPACK 運算在內的算法,以及用戶定義的 CUDA 內核。
多流視頻分析
Jetson Nano 可實時處理多達 8 個高清全動態視頻流,可作為網絡視頻錄像機( NVR )、智能攝像頭和物聯網網關的低功耗邊緣智能視頻分析平臺進行部署。 NVIDIA 的 DeepStream 軟件開發工具包 使用 ZeroCopy 和 TensorRT 優化端到端推斷管道,以在邊緣和本地服務器上實現最終性能。下面的視頻顯示 Jetson Nano 在 8 個 1080p30 流上同時執行目標檢測,基于 ResNet 的模型以全分辨率運行,吞吐量為每秒 5 億像素( MP / s )。
基于 ResNet 在 Jetson Nano 上運行的 DeepStream 應用程序
在八個獨立的 1080p30 視頻流上并發的目標檢測器。
圖 4 中的框圖顯示了一個使用 Jetson Nano 的 NVR 架構示例,該架構使用深度學習分析技術,通過千兆以太網接收和處理多達 8 個數字流。該系統可以解碼 500mp / s 的 H . 264 / H . 265 視頻和 250mp / s 的 H . 264 / H . 265 視頻。
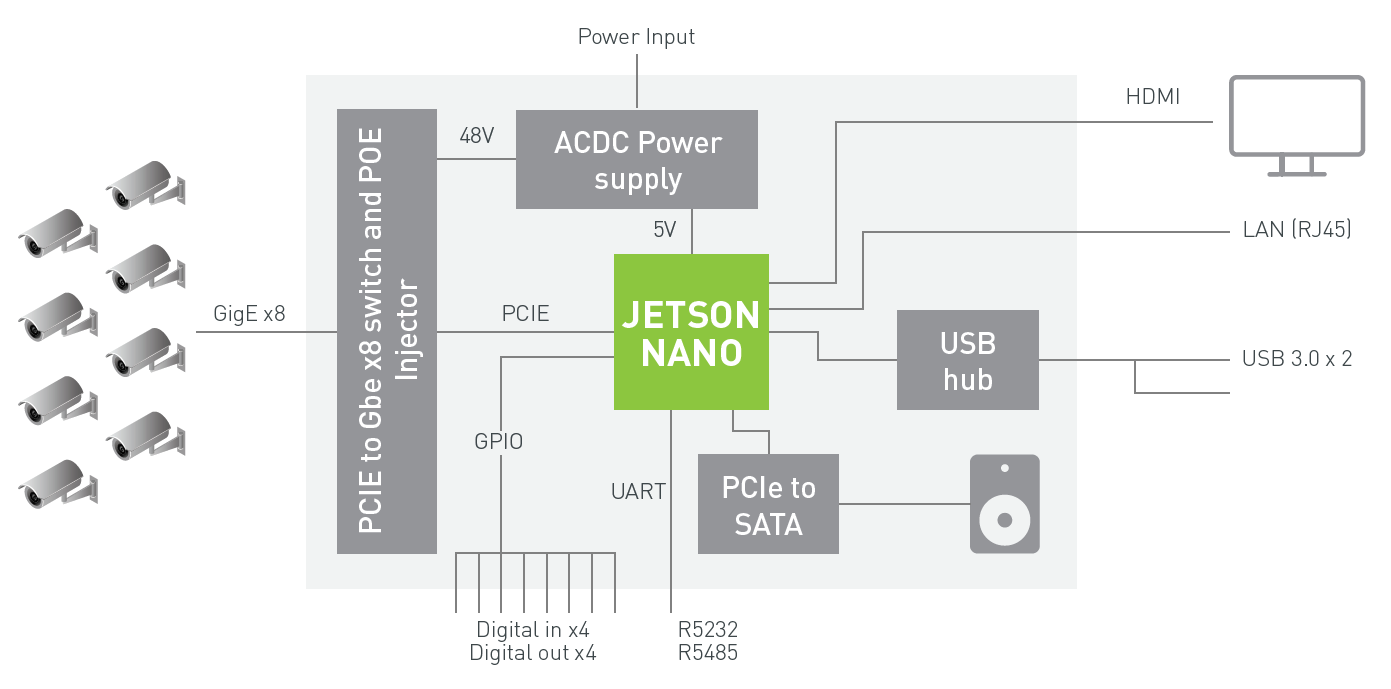
Jetson Nano 的 DeepStream SDK 支持計劃于 2019 年第 2 季度發布。請加入 DeepStream 開發者計劃 以接收有關即將發布的通知。
噴氣式飛機。
圖 5 中所示的 NVIDIA 噴氣式飛機。 是一個新的開源自主機器人工具包,它提供了所有的軟件和硬件計劃,以低于 250 美元的價格構建一個人工智能驅動的深度學習機器人。硬件材料包括 Jetson Nano 、 IMX219 8MP 攝像頭、 3D 打印機箱、電池組、電機、 I2C 電機驅動器和配件。

該項目通過 Jupyter 筆記本為您提供了簡單易學的示例,介紹了如何編寫 Python 代碼來控制電機,如何訓練 JetBot 來檢測障礙物,如何跟蹤人和家庭對象等對象,以及如何訓練 JetBot 跟蹤地板周圍的路徑。通過擴展代碼和使用 AI 框架,可以為 JetBot 創建新的功能。
還有 ROS 節點 可用于 JetBot ,為那些希望集成基于 ROS 的應用程序和功能(如 SLAM 和高級路徑規劃)的用戶提供 ROS Melodic 支持。包含 JetBot ROS 節點的 GitHub 存儲庫還包括 Gazebo 3D 機器人模擬器的模型,允許在虛擬環境中開發和測試新的 AI 行為,然后再部署到機器人上。 Gazebo 模擬器生成合成相機數據,并在 Jetson 納米上運行。
你好,人工智能世界
你好,人工智能世界 為開始使用 TensorRT 和體驗人工智能的力量提供了一個很好的方法。只需幾個小時,您就可以在帶有 JetPack SDK 和 NVIDIA NVIDIA 的 Jetson Nano Developer Kit 上建立并運行一組用于實時圖像分類和對象檢測的深度學習推理演示。本教程側重于與計算機視覺相關的網絡,并包括實時攝像機的使用。你還可以在 C ++中編寫自己易于理解的識別程序。可用的 深度學習 ROS 節點 將這些識別、檢測和分段推斷功能與 ROS 公司 集成,以集成到先進的機器人系統和平臺中。這些實時推斷節點可以很容易地放入現有的 ROS 應用程序中。圖 6 突出了一些示例。

想要嘗試訓練自己模型的開發人員可以按照完整的“ 還有兩天就要演示了 ”教程進行,該教程涵蓋了圖像分類、對象檢測和語義分割模型的再培訓和定制,并使用轉移學習。傳輸學習微調特定數據集的模型權重,避免了從頭訓練模型。傳輸學習最有效地在帶有 NVIDIA 離散 GPU 的 PC 或云實例上執行,因為培訓需要比推斷更多的計算資源和時間。
然而,由于 Jetson Nano 可以運行完整的培訓框架,如 TensorFlow 、 PyTorch 和 Caffe ,它還可以通過轉移學習為那些可能無法訪問另一臺專用培訓機器并愿意等待更長時間等待結果的人進行再培訓。表 3 列出了將兩天的學習轉移到演示教程中的一些初步結果,其中 PyTorch 使用 Jetson Nano 在 20 萬張圖像上訓練 Alexnet 和 ResNet-18 , ImageNet 的 22 . 5GB 子集:
| Network | Batch Size | Time per Epoch | Images/sec |
| AlexNet | 64 | 1.16 hours | 45 |
| ResNet-18 | 64 | 3.22 hours | 16 |
每個歷元的時間是完全通過 200K 圖像的訓練數據集所需的時間。分類網絡可能只需要 2-5 個周期就可以得到可用的結果,生產模型應該在離散 GPU 系統上為更多的時代進行訓練,直到它們達到最大的精度。然而, Jetson Nano 可以讓你在一個低成本的平臺上進行深度學習和人工智能的實驗,讓網絡在一夜之間重新訓練。并非所有的自定義數據集都可能像這里使用的 22 . 5GB 示例那樣大。因此,圖像/秒表示 Jetson Nano 的訓練性能,每歷元時間隨數據集大小、訓練批大小和網絡復雜性而變化。隨著訓練時間的增加,其他模型也可以在 Jetson Nano 上重新訓練。
所有人的 AI
Jetson Nano 的計算性能、緊湊的占地面積和靈活性為開發人員創造以人工智能為動力的設備和嵌入式系統帶來了無限的可能性。今天就開始使用 Jetson 納米開發工具包,只需 99 美元,它將通過我們的 全球主要經銷商 銷售,也可以從制造商渠道 Seeed 工作室 和 Spark 功能 購買。請訪問我們的 嵌入式開發區 下載軟件和文檔,并瀏覽 Jetson Nano 的 開源項目 。加入 Jetson DevTalk 論壇 上的社區尋求支持,并確保分享您的項目。我們期待看到你創造的!
?






