JSON 是一種廣泛采用的格式,用于在系統之間 (通常用于 Web 應用和大語言模型 (LLMs)) 以互操作方式運行的基于文本的信息。雖然 JSON 格式是人類可讀的,但使用數據科學和數據工程工具進行處理十分復雜。
JSON 數據通常采用換行分隔的 JSON 行 (也稱為 NDJSON) 的形式來表示數據集中的多個記錄。將 JSON 行數據讀入數據幀是數據處理中常見的第一步。
在本文中,我們比較了使用以下庫將 JSON 行數據轉換為數據幀的 Python API 的性能和功能:
- pandas
- DuckDB
- pyarrow
- RAPIDS cuDF pandas 加速器模式
我們使用 cudf.pandas 中的 JSON 讀取器展示了良好的擴展性能和高數據處理吞吐量,特別是對于具有復雜模式的數據。我們還審查了 cuDF 中的一組通用 JSON 讀取器選項,這些選項可提高與 Apache Spark 的兼容性,并使 Python 用戶能夠處理引文歸一化、無效記錄、混合類型和其他 JSON 異常。

JSON 解析與 JSON 讀取
當涉及到 JSON 數據處理時,區分解析和讀取非常重要。
JSON 解析器?
JSON 解析器 (例如 simdjson ) 可將字符數據緩沖區轉換為令牌向量。這些令牌代表 JSON 數據的邏輯組件,包括字段名、值、數組開始/結束和映射開始/結束。解析是從 JSON 數據中提取信息的關鍵第一步,并且我們致力于實現高解析吞吐量。
要在數據處理工作流中使用來自 JSON 行的信息,必須經常將令牌轉換為 Dataframe 或列式格式,例如 Apache Arrow 。
JSON 閱讀器?
JSON 讀取器 (例如 pandas.read_json) 將輸入字符數據轉換為按列和行排列的 Dataframe。讀取器流程從解析步驟開始,然后檢測記錄邊界、管理頂層列和嵌套結構體或列表子列、處理缺失和空字段、推理數據類型等。
JSON 讀取器可將非結構化字符數據轉換為結構化 Dataframe,從而使 JSON 數據與下游應用兼容。
JSON Lines 讀取器基準測試
JSON Lines 是一種靈活的數據表示格式。以下是 JSON 數據的一些重要屬性:
- 每個文件的記錄數
- 頂層列的數量
- 每列的結構體或列表嵌套深度
- 值的數據類型
- 字符串長度分布
- 缺少密鑰的百分比
在這項研究中,我們將記錄計數固定為 200K,并將列計數從 2 掃至 200,同時探索了一系列復雜的模式。使用的四種數據類型如下所示:
- 包含兩個子元素的
list<int>和list<str> - 包含單個子元素的
struct<int>和struct<str>
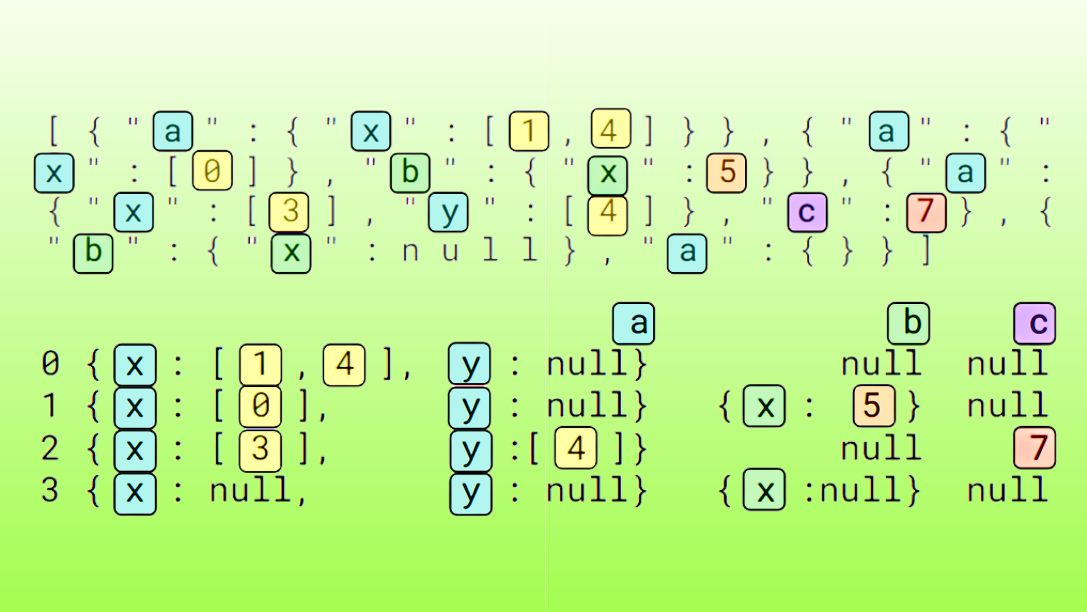
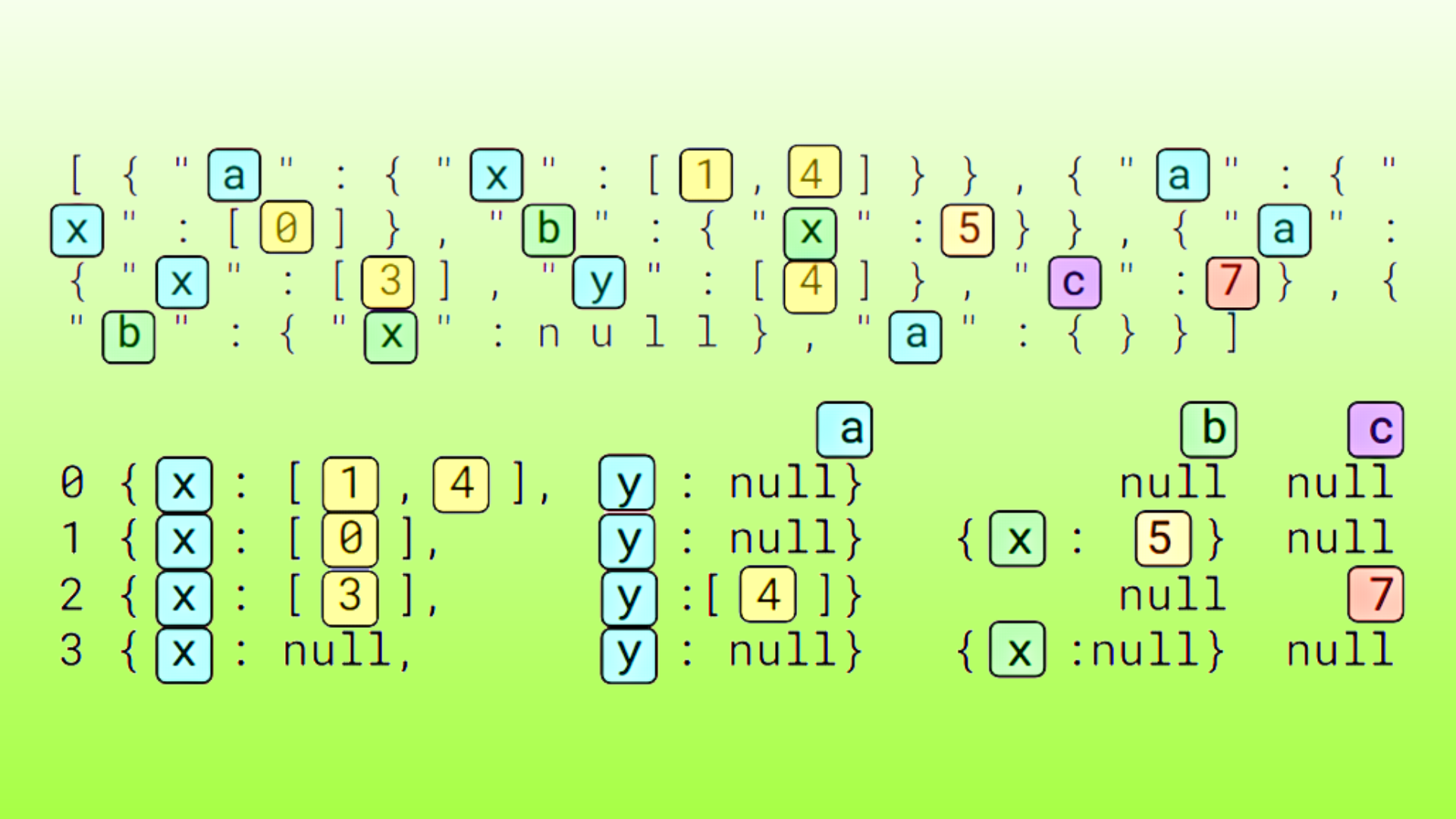
表 1 顯示了前兩列數據類型記錄的前兩列,包括 list<int>、list<str>、struct<int> 和 struct<str>。
| 數據類型 | 記錄示例 |
|---|---|
list<int> |
{"c0":[848377,848377],"c1":[164802,164802],...\n{"c0":[732888,732888],"c1":[817331,817331],... |
list<str> |
{"c0":["FJéBCCBJD","FJéBCCBJD"],"c1":["CHJGGGGBé","CHJGGGGBé"],...\n{"c0":["DFéGHFéFD","DFéGHFéFD"],"c1":["FDFJJCJCD","FDFJJCJCD"],... |
struct<int> |
{"c0":{"c0":361398},"c1":{"c0":772836},...\n{"c0":{"c0":57414},"c1":{"c0":619350},... |
struct<str> |
{"c0":{"c0":"FBJGGCFGF"},"c1":{"c0":"?aFFéaJéJ"},...\n{"c0":{"c0":"éJFHDHGGC"},"c1":{"c0":"FDaBBCCBJ"},... |
表 1 顯示了前兩列數據類型記錄的前兩列,包括 list<int>、list<str>、struct<int> 和 struct<str>
性能統計數據在 cuDF 的 25.02 分支上收集,并包含以下庫版本:pandas 2.2.3、duckdb 1.1.3 和 pyarrow 17.0.0。執行硬件使用 NVIDIA H100 Tensor Core 80 GB HBM3 GPU 和 Intel Xeon Platinum 8480CL CPU 以及 2TiB 的 RAM。計時數據從三次重復的第三次中收集,以避免初始化開銷,并確保輸入文件數據存在于操作系統頁面緩存中。
除了零代碼更改 cudf.pandas 之外,我們還從 py libcudf (用于 libcudf CUDA C++計算核心的 Python API) 收集了性能數據。 py libcudf 運行通過 RAPIDS 內存管理器 (RMM) 使用 CUDA 異步內存資源。使用 JSONL 輸入文件大小和第三次重復的讀取器運行時計算吞吐量值。
以下是來自多個 Python 庫的一些調用 JSON 行讀取器的示例:
# pandas and cudf.pandasimport pandas as pddf = pd.read_json(file_path, lines=True)# DuckDBimport duckdbdf = duckdb.read_json(file_path, format='newline_delimited')# pyarrowimport pyarrow.json as pajtable = paj.read_json(file_path)# pylibcudfimport pylibcudf as plcs = plc.io.types.SourceInfo([file_path])opt = plc.io.json.JsonReaderOptions.builder(s).lines(True).build()df = plc.io.json.read_json(opt) |
JSON 行讀取器性能?
總體而言,我們發現 Python 中的 JSON 讀取器具有各種性能特征,總體運行時間從 1.5 秒到近 5 分鐘不等。
表 2 顯示了在處理 28 個輸入文件 (總文件大小為 8.2 GB) 時,來自 7 個 JSON 讀取器配置的定時數據的總和:
- 使用 cudf.pandas 進行 JSON 讀取顯示,與使用默認引擎的 pandas 相比,速度提高了 133 倍,使用 pyarrow 引擎的 pandas 速度提高了 60 倍。
- DuckDB 和 pyarrow 也表現出良好的性能,在調整塊大小時,DuckDB 的總時間約為 60 秒,而 pyarrow 的總時間為 6.9 秒。
- pylibcudf 生成的最快時間為 1.5 秒,與 pyarrow 相比,使用
block_size調優的速度提高了約 4.6 倍。
| 閱讀器標簽 | 基準運行時 (秒) |
評論 |
| cudf.pandas | 2.1 | 在命令行中使用 -m cudf.pandas |
| pylibcudf | 1.5 | ? |
| pandas | 271 | ? |
| pandas-pa | 130 | 使用 pyarrow 引擎 |
| DuckDB | 62.9 | ? |
| pyarrow | 15.2 | ? |
| pyarrow-20MB | 6.9 | 使用 20 MB 的 block_size 值 |
表 2 包括輸入列計數 2、5、10、20、50、100 和 200,以及數據類型 list<int>、list<str>、struct<int> 和 struct<str>
通過按數據類型和列數量放大數據,我們發現 JSON 讀取器的性能因輸入數據詳細信息和數據處理庫的不同而差異很大,基于 CPU 的庫的性能介于 40 MB/s 到 3 GB/s 之間,而基于 GPU 的 cuDF 的性能介于 2–6 GB/s 之間。
圖 1 顯示了基于 200K 行、2–200 列輸入大小的數據處理吞吐量,輸入數據大小在約 10 MB 到 1.5 GB 之間變化。

在圖 1 中,每個子圖均對應輸入列的數據類型。文件大小標注與 x 軸對齊。
對于 cudf.pandas read_json ,我們觀察到,隨著列數量和輸入數據大小的增加,吞吐量增加了 2–5 GB/秒。我們還發現,列數據類型不會對吞吐量產生重大影響。由于 Python 和 pandas 語義用度較低,pylibcudf 庫的吞吐量比 cuDF-python 高約 1–2 GB/秒。
對于 pandas read_json ,我們測量了默認 UltraJSON 引擎 (標記為“pandas-uj”) 的吞吐量約為 40–50 MB/s。由于解析速度更快 (pandas-pa),使用 pyarrow 引擎 (engine="pyarrow") 可將速度提升高達 70–100 MB/s。由于需要為表中的每個元素創建 Python 列表和字典對象,因此 pandas JSON 讀取器的性能似乎受到限制。
對于 DuckDB read_json ,我們發現 list<str> 和 struct<str> 處理的吞吐量約為 0.5–1 GB/s,而 list<int> 和 struct<int> 的較低值 < 0.2 GB/s。數據處理吞吐量在列數量范圍內保持穩定。
對于 pyarrow read_json ,我們測量了 5-20 列的高達 2–3 GB/s 的數據處理吞吐量,以及隨著列數量增加到 50 及以上而降低的吞吐量值。我們發現,與列數量和輸入數據大小相比,數據類型對讀取器性能的影響較小。如果列數量為 200,且每行的記錄大小約為 5 KB,吞吐量將下降到約 0.6 GB/s。
將 pyarrow block_size reader 選項提升至 20 MB (pyarrow-20MB) 會導致列數量增加 100 或以上的吞吐量增加,同時還會降低 50 或以下列數量的吞吐量。
總體而言,DuckDB 主要因數據類型而顯示吞吐量可變性,而 cuDF 和 pyarrow 主要因列數量和輸入數據大小而顯示吞吐量可變性。基于 GPU 的 cudf.pandas 和 pylibcudf 為復雜列表和結構模式(尤其是輸入數據大小 > 50 MB)提供了超高的數據處理吞吐量。
JSON 行讀取器選項?
鑒于 JSON 格式基于文本的特性,JSON 數據通常包含異常,導致 JSON 記錄無效或無法很好地映射到數據幀。其中一些 JSON 異常包括單引號字段、已裁剪或損壞的記錄,以及混合結構或列表類型。當數據中出現這些模式時,它們可能會中斷工作流中的 JSON 讀取器步驟。
以下是這些 JSON 異常的一些示例:
# 'Single quotes'# field name "a" uses single quotes instead of double quotess = '{"a":0}\n{\'a\':0}\n{"a":0}\n'# ‘Invalid records'# the second record is invalids = '{"a":0}\n{"a"\n{"a":0}\n'# 'Mixed types'# column "a" switches between list and maps = '{"a":[0]}\n{"a":[0]}\n{"a":{"b":0}}\n' |
要在 cuDF 中解鎖高級 JSON 讀取器選項,我們建議您將 cuDF-Python (import cudf) 和 pylibcudf 集成到您的工作流中。如果數據中出現單引號字段名稱或字符串值,cuDF 會提供讀取器選項,用于將單引號歸一化為雙引號。cuDF 支持此功能,可與 Apache Spark 中默認啟用的 allowSingleQuotes 選項兼容。
如果您的數據中出現無效記錄,cuDF 和 DuckDB 都會提供錯誤恢復選項,將這些記錄替換為 null。啟用錯誤處理后,如果記錄生成解析錯誤,則相應行的所有列均標記為 null。
如果混合 list 和 struct 值與數據中的相同字段名相關聯,cuDF 提供一個 dtype 模式覆蓋選項,以將數據類型強制轉換為字符串。DuckDB 使用類似的方法來推理 JSON 數據類型。
對于混合類型,pandas 庫可能是最可靠的方法,使用 Python 列表和字典對象來表示輸入數據。
以下是 cuDF-Python 和 pylibcudf 中的示例,其中顯示了讀取器選項,包括列名稱“a”的 dtype 模式覆蓋。如需了解更多信息,請參閱 cudf.read_json 和 pylibcudf.io.json.read_json 。
對于 pylibcudf,可以在 build 函數之前或之后配置 JsonReaderOptions 對象。
# cuDF-pythonimport cudfdf = cudf.read_json( file_path, dtype={"a":str}, on_bad_lines='recover', lines=True, normalize_single_quotes=True)# pylibcudf import pylibcudf as plcs = plc.io.types.SourceInfo([file_path])opt = ( plc.io.json.JsonReaderOptions.builder(s) .lines(True) .dtypes([("a",plc.types.DataType(plc.types.TypeId.STRING), [])]) .recovery_mode(plc.io.types.JSONRecoveryMode.RECOVER_WITH_NULL) .normalize_single_quotes(True) .build() )df = plc.io.json.read_json(opt) |
表 3 總結了使用 Python API 的多個 JSON 讀取器針對一些常見 JSON 異常的行為。交叉表示讀取器函數引發異常,勾號表示庫已成功返回 Dataframe。在未來版本的庫中,這些結果可能會發生變化。
| ? | 單引號 | 無效記錄 | 混合類型 |
| cuDF-Python、pylibcudf | 歸一化為雙引號 | 設置為 null | 表示為字符串 |
| pandas | *例外 | *例外 | 表示為 Python 對象 |
pandas ( engine="pyarrow “) |
*例外 | *例外 | *例外 |
| DuckDB | *例外 | 設置為 null | 表示為類似 JSON 字符串的類型 |
| pyarrow | *例外 | *例外 | *例外 |
cuDF 支持多個額外的 JSON 讀取器選項,這些選項對于與 Apache Spark 慣例的兼容性至關重要,現在也可供 Python 用戶使用。其中一些選項包括:
- 數字和字符串的驗證規則
- 自定義記錄分隔符
- 根據 dtype 中提供的模式進行列剪枝
- 自定義 NaN 值
有關更多信息,請參閱有關 json_reader_options 的 libcudf C++ API 文檔。
有關多源讀取以高效處理許多較小的 JSON 行文件的更多信息,或有關分解大型 JSON 行文件的字節范圍支持的更多信息,請參閱使用?RAPIDS 進行 GPU 加速的 JSON 數據處理?。
總結?
RAPIDS cuDF 為在 Python 中處理 JSON 數據提供了功能強大、靈活且加速的工具。
從 24.12 版本開始,您還可以在適用于 Apache Spark 的 RAPIDS Accelerator 中使用 GPU 加速的 JSON 數據處理功能。有關信息,請參閱 使用 GPU 在 Apache Spark 上加速 JSON 處理 。
有關更多信息,請參閱以下資源:
- cuDF 文檔
- /rapidsai/cudf GitHub 存儲庫
- RAPIDS Docker 容器 (可用于版本和夜間構建)
- 零代碼更改加速數據科學工作流程 DLI 課程
- 掌握用于 GPU 加速的 cudf.pandas Profiler
?