大語言模型(LLMs)已滲透到各行各業,并改變了技術潛力。但是,由于規模龐大,它們對于許多公司目前面臨的資源限制來說并不切實際。
小語言模型 (SLMs)的興起通過創建資源占用更小的模型,將質量和成本聯系起來。SLMs 是語言模型的一個子集,這些模型傾向于專注于特定領域,并使用更簡單的神經架構構建。隨著模型的發展模仿人類感知周圍環境的方式,模型必須接受多種形式的多模態數據。
Microsoft 宣布在 Phi 系列中推出新一代開放式 SLM,并新增兩項功能:
- Phi-4-mini?
- Phi-4-multimodal
Phi-4-multimodal 是第一個加入該系列的多模態模型,接受文本、音頻和圖像數據輸入。
這些模型足夠小,可以在設備上部署。此版本基于 2024 年 12 月發布的 Phi-4 14B 參數 SLM 的研究版本構建而成,可用于兩個新的較小模型的商業用途。
這些新模型可在 Microsoft 的云 AI 平臺 Azure AI Foundry 上使用,用于設計、定制和管理 AI 應用和代理。
您可以通過 NVIDIA API Catalog 測試 Phi 系列的每個成員,這是第一個支持 Phi-4 多模態 的每種模式和工具調用的沙盒環境。立即使用預覽 NIM 微服務將模型集成到您的應用中。
為何投資 SLM?
SLMs 可在內存和計算受限環境中實現生成式 AI 功能。例如,SLMs 可以直接部署在智能手機和多臺消費級設備上。對于必須遵守監管要求的用例,設備端部署可以促進隱私和合規性。
SLM 的其他優勢包括降低延遲,因為與質量相似的 LLM 相比,其本身的推理速度更快。SLM 在處理與其訓練數據相關的專業任務時往往表現得更好。但是,為了補充對不同任務的泛化和適應性,您可以使用檢索增強生成(RAG)或原生函數調用來構建高性能代理系統。
Phi-4-multimodal
Phi-4-multimodal 具有 5.6B 個參數,接受音頻、圖像和文本推理。這使其能夠支持自動語音識別 (ASR)、多模態摘要、翻譯、OCR 和視覺推理等用例。該模型在 512 個 NVIDIA A100-80GB GPUs 上進行了為期 21 天的訓練。
事實證明,該模型在 ASR 方面表現出色,因為它在 Huggingface OpenASR 排行榜上排名第一 ,單詞錯誤率為 6.14%。 詞錯誤率 (WER) 是量化語音識別性能的常用計算方法。WER 計算不正確轉錄的單詞 (替換、插入和刪除) 與正確文本相比所占的百分比。
圖 1 展示了如何在 NVIDIA API Catalog 中預覽圖像數據并詢問 Phi-4 多模態視覺問答。您還可以了解如何調整參數,例如令牌限制、溫度和采樣值。您可以使用 Python、JavaScript 和 Bash 生成示例代碼,以幫助您更輕松地將模型集成到應用中。
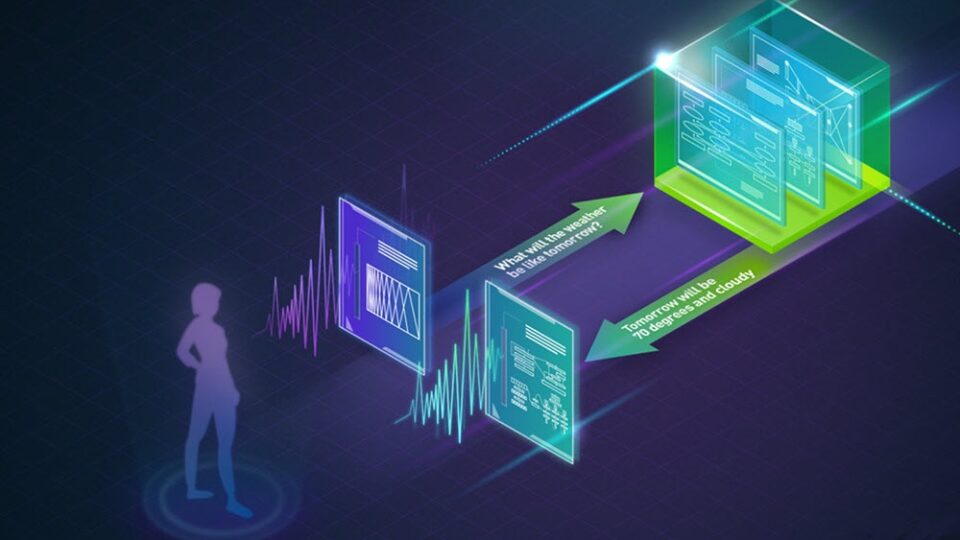
您還可以使用一組預構建代理演示工具調用。圖 2 顯示了用于檢索實時天氣數據的工具。
Phi-4-mini
Phi-4-mini 是一個僅文本、密集、僅解碼器的 Transformer 模型,具有 3.8B 個參數,并針對聊天進行了優化。它包含一個包含 128K 個令牌的長形式上下文窗口。該模型在 1024 個 NVIDIA A100 80GB GPUs 上進行了為期 14 天的訓練。
對于這兩個模型,訓練數據有意地集中在高質量的教育數據和代碼上,從而使模型獲得類似于教科書的質量。您可以在模型卡中找到文本、語音和視覺基準測試數據。
推進社區模式
NVIDIA 是開源生態系統的積極貢獻者,已根據開源許可發布了數百個項目。NVIDIA 致力于優化社區軟件和 open-source licenses 中的項目,如 Phi,它促進了 AI 透明度,并讓用戶廣泛分享在 AI 安全性和彈性方面的工作。
借助 NVIDIA NeMo 平臺,這些開放模型可以根據專有數據進行定制,以便針對各行各業的各種 AI 工作流進行高度調整并提高效率。
NVIDIA 和 Microsoft 有著長期的合作伙伴關系,其中包括推動 Azure 上 GPU 創新的多項合作、為使用 NVIDIA RTX GPU 的 PC 開發者提供的集成和優化,等等,包括從生成式 AI 到醫療健康和生命科學的研究。
立即開始使用
請訪問 build.nvidia.com/microsoft,帶上您的數據并在 NVIDIA 加速平臺上試用 Phi-4。
在 Phi-4 多模態的第一個多模態沙盒中,您可以嘗試使用文本、圖像、音頻以及示例工具調用,以了解此模型在生產環境中的工作原理。
?