諸如 NVIDIA Megatron LM 和 OpenAI GPT-2 和 GPT-3 等語言模型已被用于提高人類生產力和創造力。具體而言,這些模型已被用作編寫、編程和繪制的強大工具。相同的架構可以用于音樂創作。
在這些領域中使用語言模型需要大型數據集。從 50GB 的未壓縮文本文件開始生成語言并不奇怪。這意味著需要 GPU 計算日志來有效地訓練模型,以進行快速開發、原型制作和迭代。
這篇文章介紹了在人工智能音樂領域使用 NVIDIA DGX-2 站臺 DGX-2 極大地促進了數據預處理和訓練語言模型的進步。
人工智能音樂數據集
計算音樂數據集有兩大類。一種方法涉及對表示為純音頻( WAV 文件或 MP3 )的音樂進行訓練。第二種方法不適用于純音頻。相反,您可以將任何類似于樂譜的內容映射到標記表示。
通常,這需要標記哪個音符開始( C 、 D 、 E 、 F 、 G ),經過多少時間(例如四分之一音符或八分之一音符),以及哪個音符結束。在研究和應用中, MIDI 文件已被證明是豐富的音樂素材來源。 MIDI 標準被設計用于電子存儲音樂信息。
這些實驗使用了幾組 MIDI 文件,包括:
- JS Fake Chorales Dataset 有 500 首 J.S.巴赫風格的假合唱
- 運行 MIDI 數據庫 以及其干凈的子集(分別為 176K 和 15K MIDI 文件),混合了各種類型和風格
- MetaMIDI 數據集 具有 463K MIDI 文件,同樣具有不同的類型和風格
視頻 1.使用在 MetaMIDI 數據集上訓練的 GPT 創作的 AI 音樂
MIDI 格式是非人類可讀的音樂表示,為了訓練因果語言模型,必須將其映射到可讀的標記表示。對于此表示,我們從 mmmtrack 編碼 .
這種編碼將音樂片段表示為層次結構。一段音樂由不同樂器的不同曲目組成:例如鼓、吉他、貝司和鋼琴。每個軌道由幾個條組成( 4 、 8 或 16 條,取決于使用情況)。每個條都包含一系列音符開啟、時間增量和音符關閉事件。盡管這種層次結構可以被視為一棵樹,但可以將所有內容編碼為一個線性序列,使其成為僅用于解碼器的語言模型的理想表示。
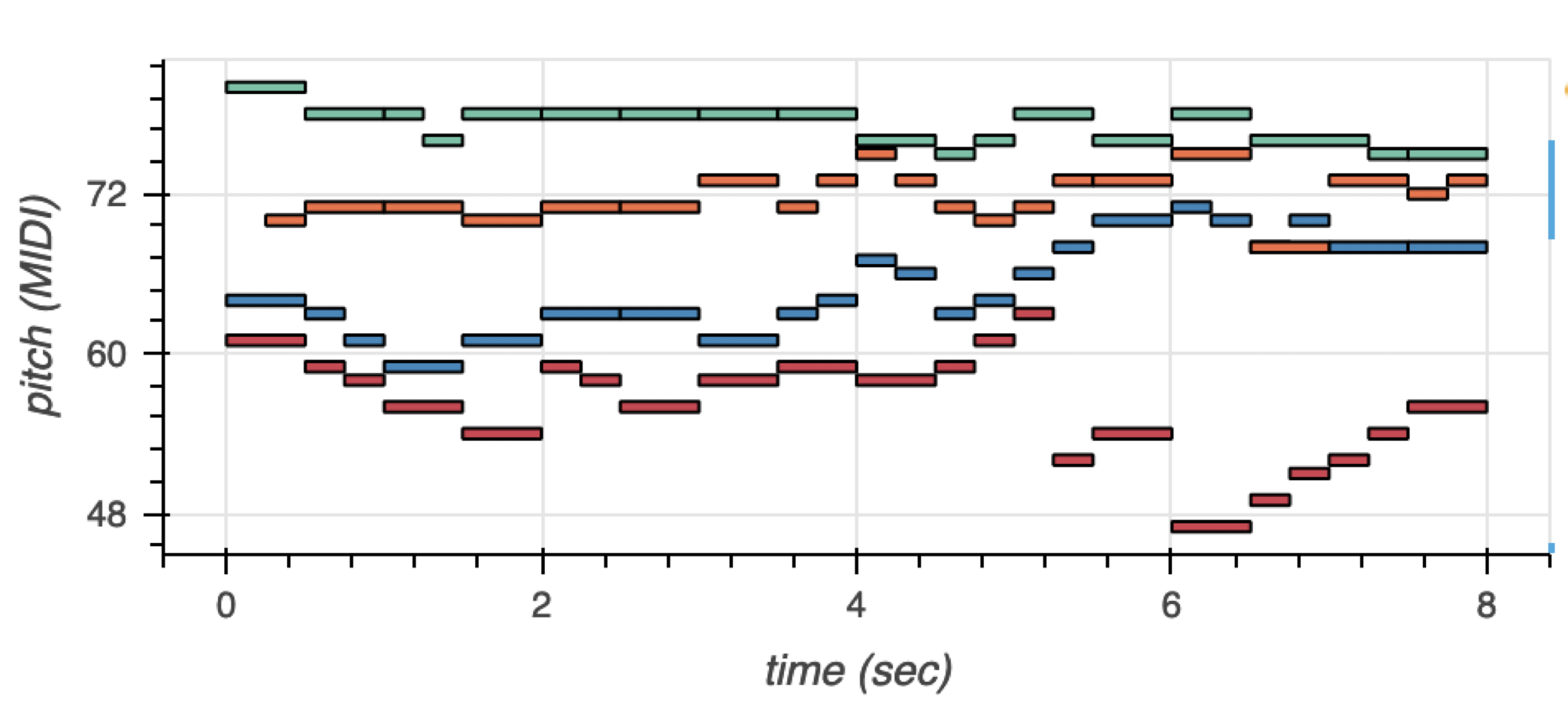
下面的例子是一首四部分的合唱,以鋼琴卷的形式呈現。合唱團有四種聲音:女高音、中音、男高音和低音。女高音和女低音是女聲,男高音和男低音是男聲。通常,四種聲音同時演唱,但音調不同。
圖 1 顯示了帶有音調顏色編碼的語音。女高音為綠色,中音為橙色,男高音為藍色,低音為紅色。您可以將這些具有時間和音調維度的音樂事件編碼為一系列符號。
在 mmmtrack 編碼之后,低音部分將映射到以下令牌表示:
PIECE_START TRACK_START INST=BASS BAR_START NOTE_ON=61 TIME_DELTA=4 NOTE_OFF=61 NOTE_ON=59 TIME_DELTA=2 NOTE_OFF=59 NOTE_ON=58 TIME_DELTA=2 NOTE_OFF=58 NOTE_ON=56 TIME_DELTA=4 NOTE_OFF=56 NOTE_ON=54 TIME_DELTA=4 NOTE_OFF=54 BAR_END BAR_START NOTE_ON=59 TIME_DELTA=2 NOTE_OFF=59 NOTE_ON=58 TIME_DELTA=2 NOTE_OFF=58 NOTE_ON=56 TIME_DELTA=4 NOTE_OFF=56 NOTE_ON=58 TIME_DELTA=4 NOTE_OFF=58 NOTE_ON=59 TIME_DELTA=4 NOTE_OFF=59 BAR_END BAR_START NOTE_ON=58 TIME_DELTA=4 NOTE_OFF=58 NOTE_ON=59 TIME_DELTA=2 NOTE_OFF=59 NOTE_ON=61 TIME_DELTA=2 NOTE_OFF=61 NOTE_ON=63 TIME_DELTA=2 NOTE_OFF=63 NOTE_ON=52 TIME_DELTA=2 NOTE_OFF=52 NOTE_ON=54 TIME_DELTA=4 NOTE_OFF=54 BAR_END BAR_START NOTE_ON=47 TIME_DELTA=4 NOTE_OFF=47 NOTE_ON=49 TIME_DELTA=2 NOTE_OFF=49 NOTE_ON=51 TIME_DELTA=2 NOTE_OFF=51 NOTE_ON=52 TIME_DELTA=2 NOTE_OFF=52 NOTE_ON=54 TIME_DELTA=2 NOTE_OFF=54 NOTE_ON=56 TIME_DELTA=4 NOTE_OFF=56 BAR_END TRACK_END TRACK_START INST=TENOR …
只要稍加練習,人類就能閱讀和理解這種表示。表示以PIECE_START開始,表示一段音樂的開始。TRACK_START表示音軌(或樂器或語音)的開始,而TRACK_END表示音尾。INST=BASS標記表示此曲目包含低音。其他聲音以相同的方式表示。BAR_START和BAR_END分別表示條形圖的開始和結束。NOTE_ON=61是音調為 61 的音符的開頭。
在鋼琴上,這將是音符 C # 5 。TIME_DELTA=4意味著將經過四個十六分音符的持續時間。那將是一張四分之一的鈔票。之后,音符將結束,由NOTE_OFF=61表示。等等等等。在這一點上,這種記法也允許復調。幾個音軌將同時發出音符,每個音軌可以有平行的音符。這使得編碼具有通用性。
每段音樂的小節數不同。很可能對整個歌曲進行編碼將需要較長的序列長度,從而使相應 transformer 的訓練在計算上非常昂貴。這些實驗將大多數數據集編碼為四條,少數編碼為八條。 16 巴的實驗正在進行中。此外,僅使用 4 / 4 計時表中的音樂。這涵蓋了西方音樂的大部分。其他節拍,如 3 / 4 (華爾茲)可以作為未來工作的主題。
這一系列不同的實驗將許多 MIDI 數據集映射到所描述的令牌格式。整個過程中使用了相同的預處理器。一旦預處理器處理小數據集,它立即處理大數據集。
處理時間取決于要編碼的 MIDI 文件的數量,從幾分鐘到幾小時不等。 DGX-2 在所有 96 CPU 上并行運行,最長的預處理時間為 30 小時。據估計,這將需要在最先進的 MacBook Pro 上進行大約 10-14 天的處理。
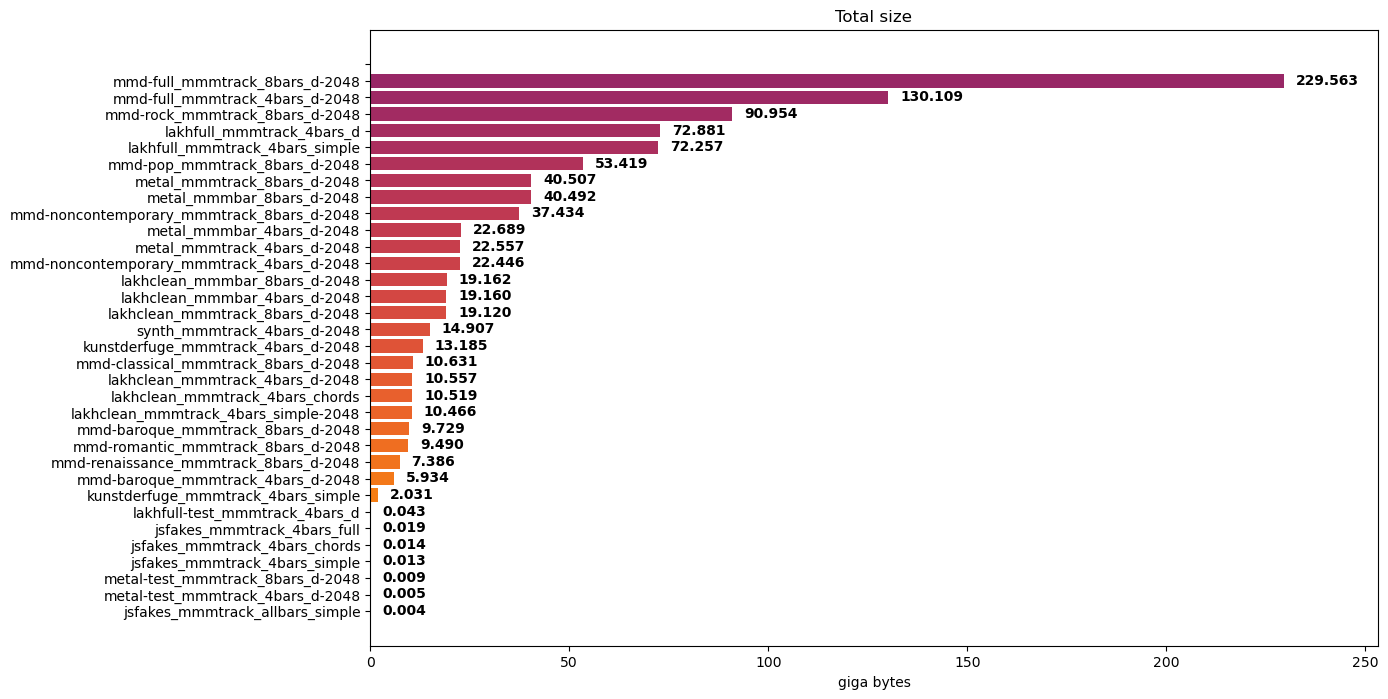
對 MIDI 文件的數據集進行編碼將產生令牌文件的集合。這些標記文件的大小取決于 MIDI 文件的數量和條形圖的數量。考慮一些實驗數據集及其編碼數據集大小:
- JS Fake Chorales 數據集: 14 MB ,每個樣本有四個條
- Lakh MIDI 數據集: 72 GB ,其干凈子集為 19 GB ,每個樣本有四個小節
- MetaMIDI 數據集:每個樣本 130 GB , 4 個小節, 230 GB , 8 個小節
你可以想象,在 14 MB 的 JS 假合唱團上訓練只需要幾個小時。在 130 GB 的 MetaMIDI 數據集上進行訓練需要很多天。這些實驗的訓練持續了 10 至 15 天。
模型訓練
許多模型使用 HuggingFace GPT-2 實現進行了訓練。一些模型在 GPT-2 模式下使用 NVIDIA Megatron LM 進行了訓練。
使用 HuggingFace 進行的訓練歸結為將數據集上傳到 DGX-2 ,然后運行包含所有功能的訓練腳本,包括模型和訓練參數。使用了相同的腳本,只是對所有數據集進行了一些更改。這只是規模問題。
對于Megatron LM 來說,環境設置就像拉動和運行 NGC 一樣簡單 PyTorch Docker 容器 ,然后通過 ssh 隧道進入 DGX-2 機器,立即在瀏覽器中使用 Jupyter 筆記本。
大多數實驗使用相同的 GPT-2 架構:六個解碼器塊和八個注意頭;嵌入大小為 512 ,序列長度為 2048 。雖然這絕對不是一個大語言模型( LLM ),它可以有大約 100 個解碼器塊,但主觀評估表明,對于人工智能音樂來說,這種架構工作起來很有魅力。
使用 NVIDIA DGX-2 在快速迭代中確實起到了作用。在單個 GPU 上訓練多天的數據集,在 DGX-2 上只訓練幾個小時。在單個 GPP 上訓練數月的數據集在 DGX-2 中最多兩周后完成訓練。特別是對于數據集< 25 GB 的實驗,模型收斂非常快。
一些數據集的培訓時間如下:
- 10 個時代和大約 1.5 萬首歌曲的 10 萬首 MIDI Clean 數據集耗時 15 小時
- 10 個時代和大約 175K 首歌曲的 Lakh MIDI 數據集耗時 130 小時
- MetaMIDI 數據集歷時 290 小時,涵蓋了 9 個時代和大約 40 萬首歌曲
請注意, JS Fake Chorales 數據集是較早訓練的,而不是在 DGX-2 上。由于其體積非常小,因此不需要使用 multi- GPU 設置。它甚至可以在 MacBook Pro 上過夜訓練。
NVIDIA DGX-2
本節詳細介紹了 NVIDIA DGX-2 規范。如上所述,該平臺在加速數據集預處理和訓練語言模型方面都非常有效。這一部分將是一個令人愉快的技術部分。

NVIDIA DGX-2 是一個功能強大的系統,具有 16 個完全連接的 Tesla V100 32 GB GPU ,使用 NVSwitch 。它能夠提供 2.4 TB /秒的二等分帶寬。 DGX-2 專為需要性能和可擴展性的人工智能研究人員和數據科學家設計。
對于 transformer 型號, NVIDIA DGX-2 能夠以混合精度提供敢達 517227 個令牌/秒的吞吐量,這使其特別強大。
軟件框架: NVIDIA Megatron LM
要充分利用強大的計算功能,您需要穩定和優化的軟件。使用 NVIDIA Megatron LM 等性能優化框架,隨著 GPT 模型尺寸的縮放,性能幾乎呈線性縮放。有關相關信息,請參見 Megatron?LM :使用模型并行性訓練數十億參數語言模型 .
通過在單個 NVIDIA V100 32 GB GPU 上訓練 12 億個參數的模型來實現基線,該 GPU 支持 39 萬億次浮點運算。這是 DGX-2H 服務器中配置的單個 GPU 的理論峰值觸發器的 30% ,因此是一個強基線。
將模型擴展到 512 GPU 上的 83 億個參數,在整個應用程序中, 8 路模型并行度達到每秒 15.1 萬億次。與單一 GPU 情況相比,這是 76% 的縮放效率。
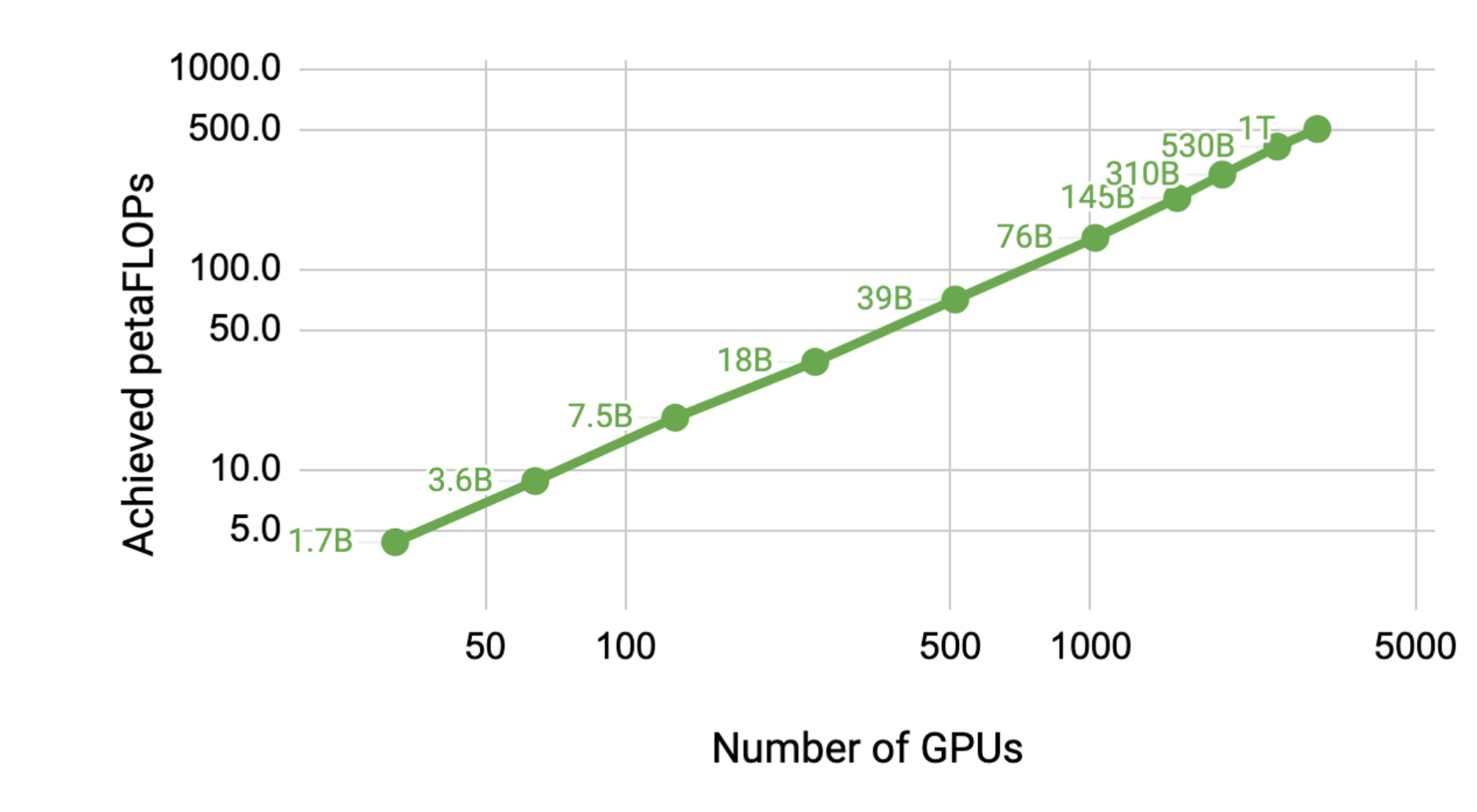
通過修正seq_len,短指針,等于 4096 ,并修改訓練配置,只需幾次迭代即可啟動訓練運行,可以計算實際應用程序作業運行中實現的萬億次浮點百分比。
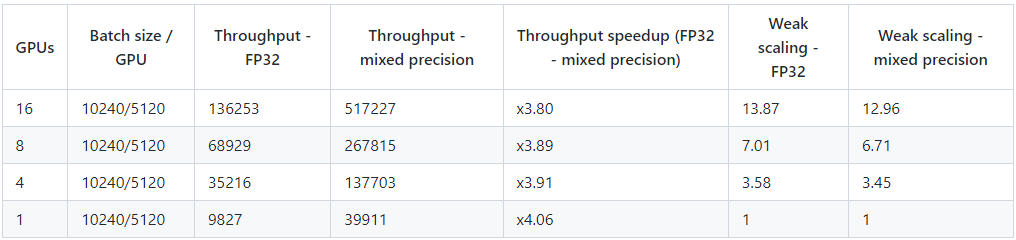
在本機運行后,分析了nvidia-smi和輸出 Nsight 配置文件。測試了不同的配置以獲得最高可能的 teraflop ,如下表所示:
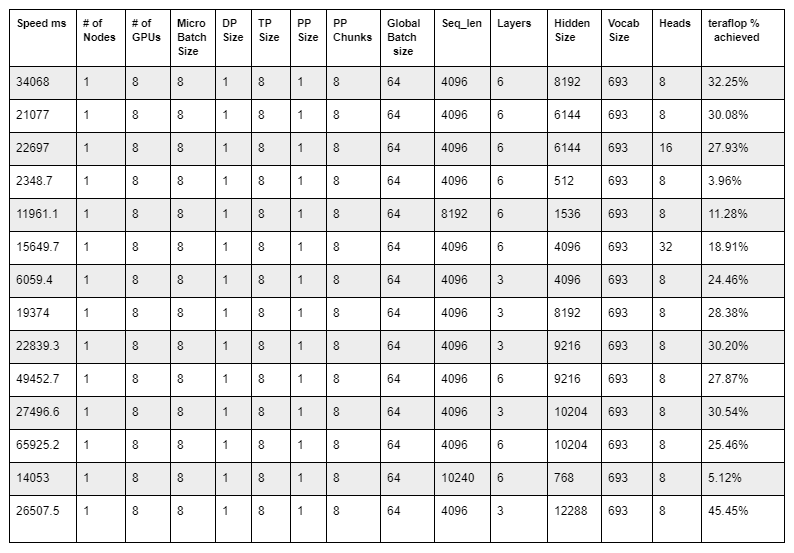
該表最后一行中顯示的訓練配置提供了 45.45% 的最高 teraflop 。
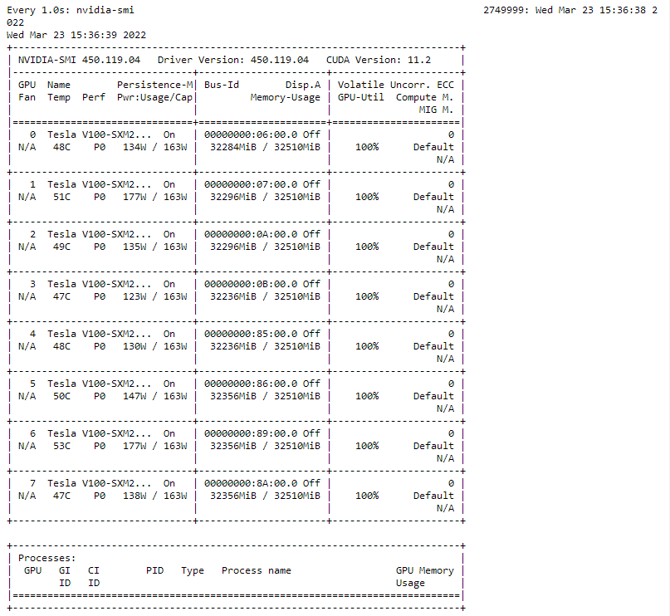
請注意,使用了 8 個 V100 32 GB GPU 而不是 16 GPU ,以縮短運行每個評測作業所需的時間。nvidia-smi 命令用于驗證訓練配置實現了 45.45% 的 teraflops 利用率,如下所示。
總結
這里介紹的人工智能音樂實驗是使用 NVIDIA DGX-2 進行的。我們使用大小從幾兆字節到 230 GB 的數據集訓練語言模型。我們使用了 HuggingFace GPT-2 實現,并表明 NVIDIA Megatron LM 也是一個很好的實驗替代品。
NVIDIA DGX-2 在加速數據集預處理(將 MIDI 文件映射到令牌表示和訓練模型)方面做出了重大貢獻。這允許快速實驗。 DGX-2 在訓練可用的最大 MIDI 數據集(具有 400K 文件的 MetaMIDI )時發揮了巨大的作用。
?
?