
在過去幾年中,作為廣泛的 AI 革命的一部分, 生成式 AI 和 大語言模型 (LLMs) 越來越受歡迎。隨著基于 LLMs 的應用在各個企業中的推廣,我們需要確定不同 AI 服務解決方案的成本效益。部署 LLM 應用的成本取決于它每秒可以處理的查詢數量,同時響應最終用戶并支持可接受的響應準確度。本文特別關注 LLMs 吞吐量和延遲測量,以評估 LLM 應用成本。
NVIDIA 為開發者提供涵蓋芯片、系統和軟件的全棧創新。NVIDIA 推理軟件堆棧包括 NVIDIA Dynamo 、 NVIDIA TensorRT-LLM 和 NVIDIA NIM 微服務。為支持開發者實現基準測試推理性能,NVIDIA 還提供了開源生成式 AI 基準測試工具 GenAI-Perf 。詳細了解如何 使用 GenAI-Perf 進行基準測試 。
可以使用各種工具來評估 LLMs 的性能。這些客戶端工具為基于 LLMs 的應用提供特定指標,但在定義、衡量和計算不同指標方面有所不同。這可能令人困惑,并且可能導致難以將一種工具的結果與另一種工具的結果進行比較。
在本文中,我們將闡明常見指標,以及熱門基準測試工具。
負載測試和性能基準測試
負載測試和性能基準測試是評估 LLM 部署的兩種不同方法。負載測試側重于模擬對模型的大量并發請求,以評估其大規模處理真實流量的能力。此類測試有助于識別與服務器容量、autoscaling 策略、網絡延遲和資源利用率相關的問題。
相比之下,如 NVIDIA GenAI-Perf 工具所示,性能基準測試關注的是衡量模型本身的實際性能,例如吞吐量、延遲和 token 級指標。此類測試有助于識別與模型效率、優化和配置相關的問題。
雖然負載測試對于確保模型能夠處理大量請求至關重要,但性能基準測試對于了解模型高效處理請求的能力至關重要。通過結合使用這兩種方法,開發者可以全面了解其 LLM 部署能力,并確定需要改進的方面。
LLM 推理的工作原理
在檢查基準指標之前,務必要了解 LLM 推理的工作原理,并熟悉相關術語。LLM 應用在推理階段生成結果。對于給定的特定 LLM 應用,這些階段包括:
- 提示: 用戶提供了一個查詢
- 隊列:查詢加入處理隊列
- 預填充: LLM 模型處理提示
- 生成:LLM 模型一次輸出一個 token 的響應
AI token 是 LLM 特有的概念,也是 LLM 推理性能指標的核心。它是 LLM 用于分解和處理自然語言的單位或最小的語言實體。所有 token 的集合稱為詞匯表。 每個 LLM 都有自己的 tokenizer,從數據中學習,以便高效地表示輸入文本。 作為近似值,對于許多熱門 LLM,每個 token 大約為 0.75 個英語單詞。
序列長度 是數據序列的長度。 輸入序列長度 (ISL) 是指 LLM 獲得的 token 數量。它包括用戶查詢、任何系統提示 (例如模型說明) 、之前的聊天記錄、 Chain of Thought (CoT) 推理以及 Retrieval-Augmented Generation (RAG) 工作流中的文檔。 輸出序列長度 (OSL) 是指 LLM 生成的 token 數量。 上下文長度 是指 LLM 在每個生成步驟中使用的 token 數量,包括到該點生成的輸入和輸出 token。每個 LLM 都有一個可分配給輸入和輸出 token 的最大上下文長度。如需深入了解 LLM 推理,請參閱 Mastering LLM Techniques: Inference Optimization 。
流式傳輸選項允許以增量生成的 token 塊的形式將部分 LLM 輸出流式傳輸給用戶。這對于聊天機器人應用很重要,希望快速收到初始響應。當用戶摘要部分內容時,下一個結果塊將在后臺到達。相比之下,在非流模式下,系統會一次性返回完整答案。
LLM 推理指標
本節將解釋業內使用的一些常見指標,包括首次啟動 token 的時間(time to first token)和 token 間延遲(intertoken latency),如圖 1 所示。雖然它們看起來很簡單,但各種基準測試工具之間存在一些細微但顯著的差異。
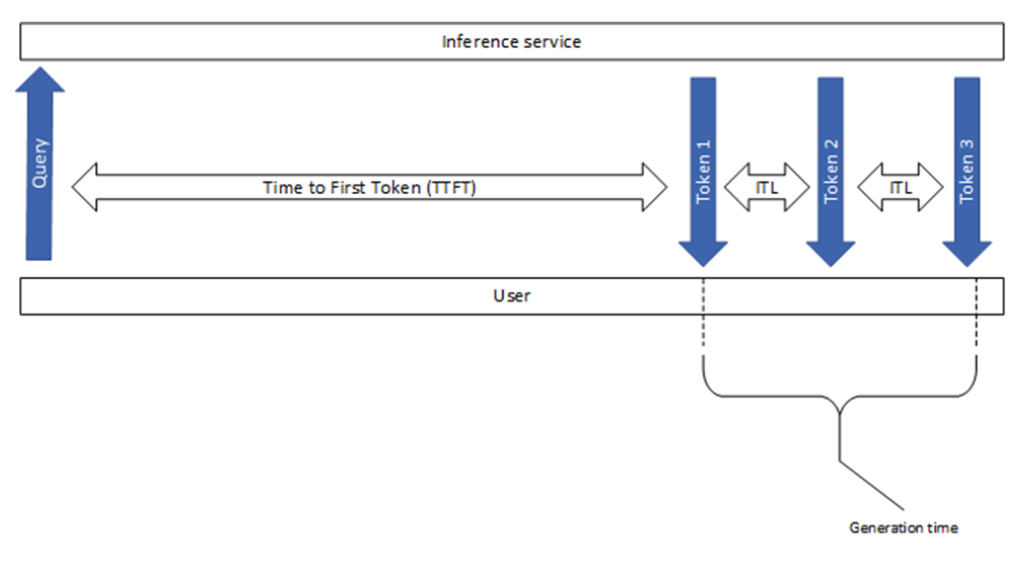
第一個 token 的時間
第一個 token (TTFT) 的時間是處理提示并生成第一個 token 所需的時間 (圖 2) 。換言之,它用于測量用戶在看到模型輸出之前必須等待的時間。
請注意,GenAI-Perf 和 LLMPerf 基準測試工具都會忽略沒有內容或內容且帶有空字符串 (不存在 token) 的初始響應。這是因為當第一個響應沒有token 時,TTFT 測量毫無意義。
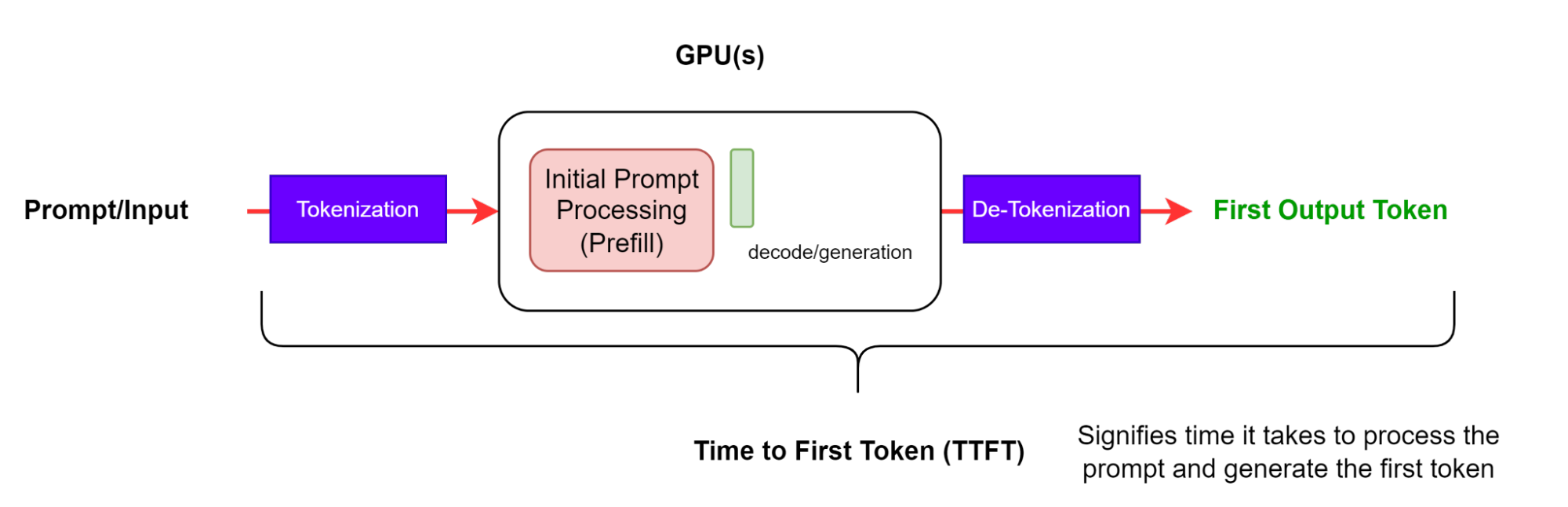
TTFT 通常包括請求排隊時間、預填充時間和網絡延遲。提示時間越長,TTFT 就越大。這是因為注意力機制需要整個輸入序列來計算和創建所謂的 key-value (KV) 緩存 ,從該點開始迭代生成循環。此外,生產應用可能有多個請求正在進行中,因此一個請求的預填充階段可能會與另一個請求的生成階段重疊。
端到端請求延遲
端到端請求延遲 (e2e_latency) 表示從提交查詢到接收完整響應所需的時間,包括排隊和批處理的時間以及網絡延遲 (圖 3) 。請注意,在流式傳輸模式下,將部分結果返回給用戶時,可以多次執行 detokenization 步驟。

對于單個請求,端到端請求延遲是發送請求與接收最終 token 之間的時間差:

請注意,generation_time 是從收到第一個 token 到收到最終 token 的持續時間 (圖 1) 。此外,GenAI-Perf 會刪除最后一個 (done) 信號或空響應,因此這些內容不包含在 e2e_latency 中。
Token 間延遲
Token 間延遲 (ITL) 是在序列中生成連續 token 之間的平均時間。也稱為每輸出 token 時間 (TPOT)。
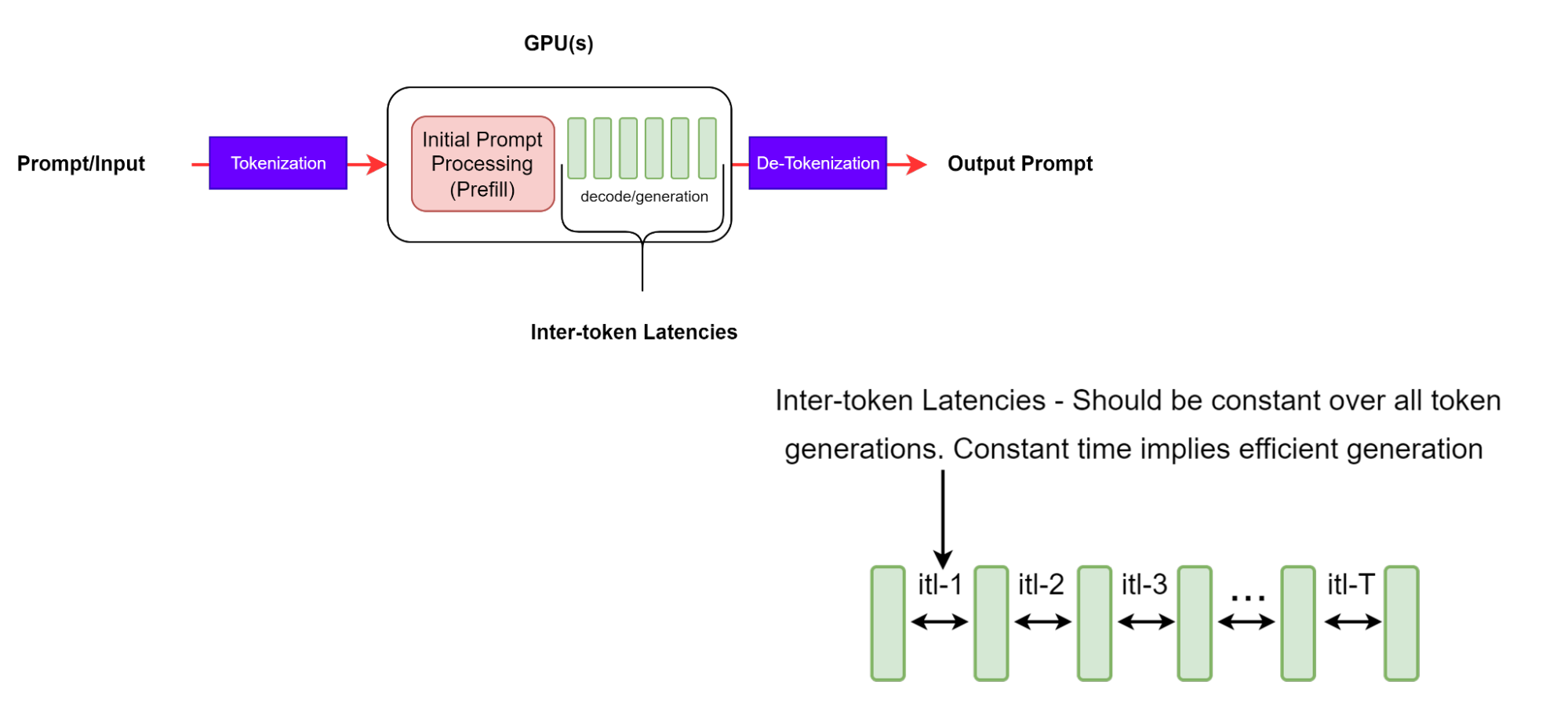
雖然這似乎是一個簡單的定義,但通過不同的基準測試工具收集指標的方式存在一些復雜的差異。例如,GenAI-Perf 在平均計算中不包括 TTFT (與包含 TTFT 的 LLMPerf 不同)。
GenAI-Perf 使用以下方程定義了 ITL:

用于此指標的方程不包括第一個標記 (因此在分母中減去 1) 。這樣做的目的是使 ITL 僅成為請求處理解碼部分的特征。
需要注意的是,隨著輸出序列的延長,KV 緩存會增長,因此內存成本也會增長。注意力計算成本也在增加:對于每個新 token,此成本在迄今為止生成的輸入和輸出序列的長度上是線性的。但是,這種計算通常不受計算限制。一致的 ITL 意味著高效的內存管理、更好的內存帶寬以及高效的注意力計算。
每秒 token 數
每個系統的 每秒 token 數 (TPS) 表示每秒吞吐量的總輸出 token 數,這也是同時發生的所有請求的組成部分。隨著請求數量的增加,每個系統的總 TPS 將增加,直到所有可用 GPU 計算資源達到飽和點,超過此點,TPS 可能會降低。
在圖 5 所示的示例中,假設整個基準測試的時間軸包含 n 個請求總數。事件定義如下:
- Li:第 i 次請求的端到端延遲
- T_start: 基準測試開始時間
- Tx: 第一個請求的時間
- Ty:上次請求的最后一次響應的時間戳
- T_end: 基準測試結束

GenAI-Perf 將 TPS 定義為總輸出 token 除以第一個請求與最后一個請求的最后一個響應之間的端到端延遲:

LLMPerf 將 TPS 定義為總輸出 token 除以整個基準測試持續時間:

因此,LLM-perf 在指標中還包含以下開銷:
- 輸入提示生成
- 請求準備
- 存儲響應。
根據我們的觀察,在單一并發場景中,這些開銷有時會占整個基準測試持續時間的 33%。
請注意,TPS 計算是以批量方式完成的,不是實時運行的指標。此外,GenAI-Perf 還使用滑窗技術來尋找穩定的測量值。這意味著給定的測量結果將來自完全完成的請求的代表性子集,這意味著在計算指標時不包括“warming up”和“cooling down”請求。
每位用戶的 TPS 代表單個用戶的吞吐量,其定義如下:

此定義適用于每個用戶的請求,隨著輸出序列長度的增加,這些請求逐漸接近 1/ITL。請注意,隨著系統中并發請求的數量增加,整個系統的總 TPS 將增加,而每位用戶的 TPS 則會隨著延遲的增加而降低。
每秒請求數
每秒請求數 (Requests per second,RPS) 是系統在 1 秒內可以成功完成的平均請求數。計算公式如下:

基準測試參數和最佳實踐
本節介紹一些重要的測試參數及其掃描范圍,確保進行有意義的基準測試和質量保證。
應用用例及其對 LLM 性能的影響
應用程序的特定用例將影響序列長度 (ISL 和 OSL) ,而這反過來又會影響系統消化輸入以形成 KV 緩存并生成輸出 token 的速度。更長的 ISL 將增加預填充階段的內存需求,從而增加 TTFT。更長的 OSL 將增加生成階段的內存需求 (帶寬和容量) ,從而增加 ITL。了解 LLM 部署中輸入和輸出的分布非常重要,這樣才能更好地優化硬件利用率。
常見用例和可能的 ISL/OSL 對包括:
- 翻譯: 包括語言和代碼之間的翻譯,其特點是具有相似的 ISL 和 OSL,每個大約 500~2000 個 token。
- 生成: 包括通過搜索生成代碼、故事、電子郵件內容和通用內容。其特征是具有 O(1,000) 個 token的 OSL,比 O(100) 個 token 的 ISL 長很多。
- 摘要:包括檢索、思維鏈提示和多輪對話。其特點是具有 O (1000) 個 token 的 ISL,比 O (100) 個 token的 OSL 要長得多。
- 推理:近期的推理模型通過一種顯式的思維鏈、自我反思和驗證推理方法生成大量輸出標記,以解決編碼、數學或謎題等復雜問題。其特征是 O (100) token 的短 ISL 和 O (1000-10000) token 的大型 OSL。
負載控制參數
本節中定義的負載控制參數用于在 LLM 系統上誘導負載。
并發 N 是并發用戶的數量,每個用戶都有一個活動請求,或者等效的是由 LLM 服務同時服務的請求數量。在每個用戶的請求收到完整響應后,系統會發送另一個請求,以確保系統在任何時候都有 N 個請求。并發最常用于描述和控制推理系統引起的負載。
請注意,LLMPerf 批量發送 N 個請求,但有一個耗盡期,它會等待所有請求完成,然后再發送下一批請求。因此,在批量接近尾聲時,并發請求的數量逐漸減少到 0。這與 GenAI-Perf 的不同之處在于,GenAI-Perf 可確保在整個基準測試期間始終存在 N 個活躍請求。
最大批量大小參數 定義了推理引擎可以同時處理的最大請求數,其中 batch 是推理引擎同時處理的一組請求。這可能是并發請求的子集。
如果并發次數超過最大批量大小乘以活動副本的數量,則某些請求必須在隊列中等待后續處理。在這種情況下,由于等待插槽打開的排隊效應,您可能會看到 TTFT 值增加。
請求速率 是另一個參數,可用于通過確定發送新請求的速率來控制負載。使用常量 (或靜態) 請求速率 r 意味著每 1/r 秒發送一次請求,而使用 Poisson (或指數級) 請求速率則決定平均到達時間。
GenAI-Perf 支持并發和請求速率。但是,我們建議使用并發性。與請求速率一樣,如果每秒請求數超過系統吞吐量,則未完成請求的數量可能會無限增加。
在指定要測試的并發次數時,最好能掃描一系列值,從最小值 1 到不超過最大批量大小的最大值。這是因為,當并發量大于引擎的最大批量大小時,某些請求必須在隊列中等待。因此,系統的吞吐量通常在最大批量大小附近飽和,而延遲將繼續穩步增加。
其他參數
此外,一些相關的 LLM 服務參數可能會影響推理性能以及基準測試的準確性。
大多數 LLM 都有一個特殊的序列結束 (EOS) token,這表示生成的結束。這表示 LLM 已生成完整的響應,并應停止。一般情況下,LLM 推理應遵循此信號并停止生成更多 token。這個 ignore_eos parameter 通常會指示 LLM 推理框架是否應忽略 EOS token 并繼續生成 token,直到達到 max_tokens 限制。出于基準測試目的,應將此參數設置為 True,以達到預期的輸出長度并獲得一致的測量值。
不同的采樣參數 (例如 greedy、top_p、top_k 和 temperature) 可能會影響 LLM 生成速度。例如,只需選擇具有最高 logit 的 token,即可實現 greedy。無需對 token 的概率分布進行歸一化和排序,從而節省計算時間。無論選擇哪種采樣方法,最好在相同的基準設置中保持一致。有關不同采樣方法的詳細說明,請參閱 How to Generate Text: Using Different Decoding methods for Language Generation with Transformers 。
開始使用
LLM 性能基準測試是確保大規模提供高性能和經濟高效的 LLM 服務的關鍵步驟。本文討論了對 LLM 推理進行基準測試時最重要的指標和參數。如需了解詳情,請查看以下資源:
探索 NVIDIA AI 推理平臺,查看最新的 AI 推理性能數據。TensorRT、TensorRT-LLM 和 TensorRT Model Optimizer 庫中的優化經過組合,可通過使用 NVIDIA NIM 微服務的生產就緒型部署使用。
?





