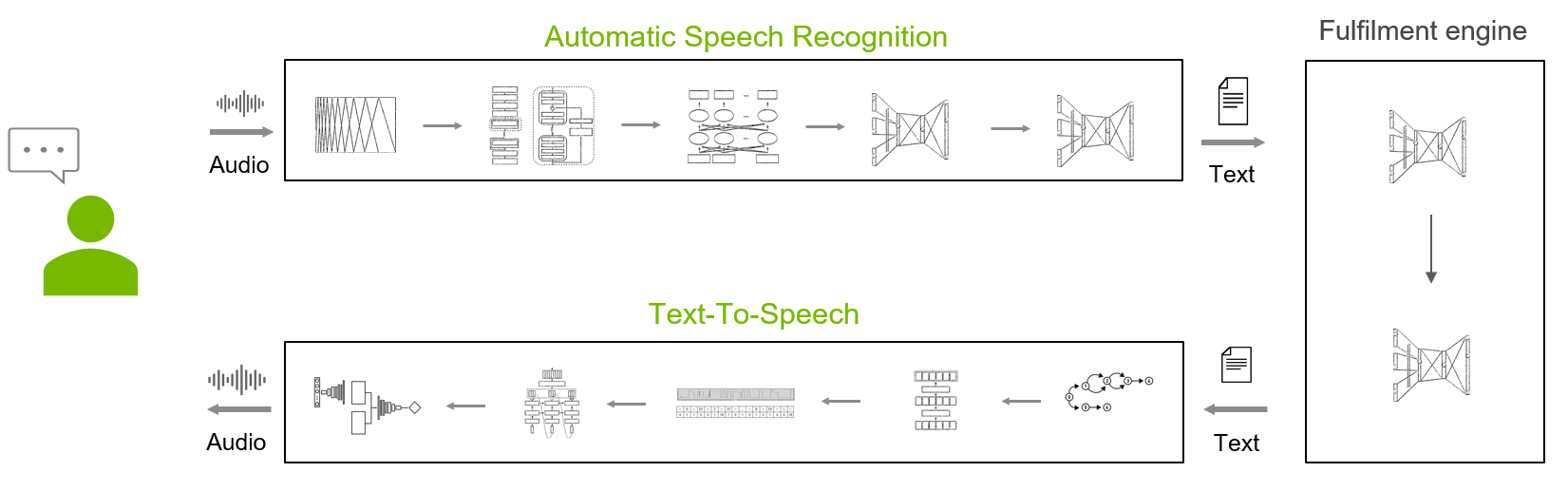
Speech AI 是智能系統使用語音接口與用戶進行通信的能力,語音接口在日常生活中已變得無處不在。人們經常通過語音與智能家居設備、車載助手和手機互動。近年來,語音界面質量得到了突飛猛進的改善,使其比十年前更加愉快、實用和自然。
具有語音 AI 接口的智能系統組件包括:
- 自動語音識別( ASR ): 將音頻信號轉換為文本。
- 履行引擎: 分析文本,識別用戶的意圖并實現它。
- 文字轉語音 (TTS): 將響應的文本元素轉換為高質量、自然的語音
ASR 是任何語音 AI 系統的第一個組件,起著至關重要的作用。 ASR 階段早期出現的任何錯誤都會在隨后的意圖分析和實現階段中出現問題。
目前有超過 6500 種口語在使用,其中大多數沒有商業 ASR 產品。 ASR 服務提供商最多覆蓋幾十家。 NVIDIA Riva 目前涵蓋五種語言(英語、西班牙語、德語、普通話和俄語),更多版本將在未來發布。
雖然這一套還很小,但 Riva 為您提供了現成的工作流、工具和指導,以快速、系統、輕松地為新語言提供 ASR 服務。在這篇文章中,我們介紹了 NVIDIA 工程團隊為提供新的世界級 Riva ASR 服務而采用的工作流程、工具和最佳實踐。開始旅程!
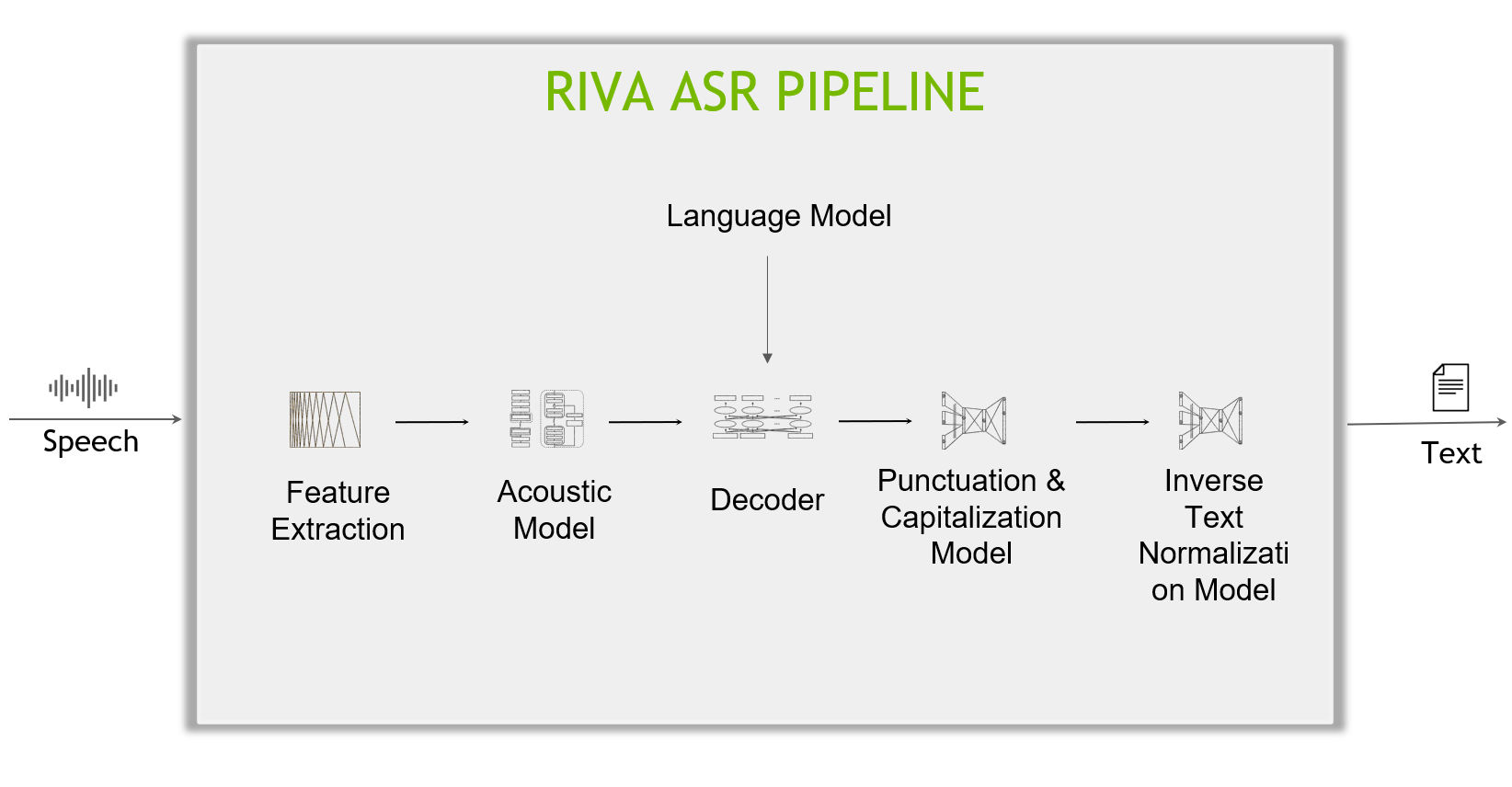
Riva ASR 管道的解剖
深入了解 Riva ASR 管道的內部工作,包括以下主要組件:
- Feature extractor :原始時間音頻信號首先通過特征提取塊,該特征提取塊將數據分割為固定長度的塊(例如,每個塊 80 毫秒),然后將塊從時域轉換為頻域(頻譜圖)。
- Acoustic model :然后將頻譜圖數據輸入聲學模型,該模型在每個時間步長輸出字符(或更一般地,文本標記)的概率。
- 解碼器和語言模型 :解碼器將概率矩陣轉換為字符序列(或文本標記),形成單詞和句子。語言模型可以給出一個句子分數,該分數指示句子出現在其訓練語料庫中的可能性。高級解碼器可以在組合聲學模型分數和語言模型分數并搜索具有最高組合分數的假設的同時檢查多個假設(句子)。
- 標點和大寫( P & C ):解碼器生成的文本沒有標點符號和大寫,這是標點符號與大寫模型的工作。
- 反向文本規范化( ITN ) :最后,應用 ITN 規則將口頭格式的文本轉換為所需的書面格式,例如,“十點鐘”到“ 10 : 00 ”,或“十美元”到“ 10 美元”。
Riva 新語言的 ASR 工作流
與解決其他人工智能和機器學習問題一樣,從頭開始創建新的 ASR 服務是一項涉及數據、計算和專業知識的資本密集型任務。 Riva 顯著降低了這些障礙。
通過 Riva ,為新語言提供新的 ASR 服務至少需要收集數據并訓練新的聲學模型。容易提供特征提取器和解碼器。
語言模型是可選的,但通常被發現可以將管道的準確性提高到百分之幾,這通常是值得努力的。 P & C 和 ITN 進一步提高了文本的可讀性,便于人類消費或進一步處理任務。
Riva 新語言工作流分為以下主要階段:
- 數據收集
- 數據準備
- 培訓和驗證
- Riva 部署
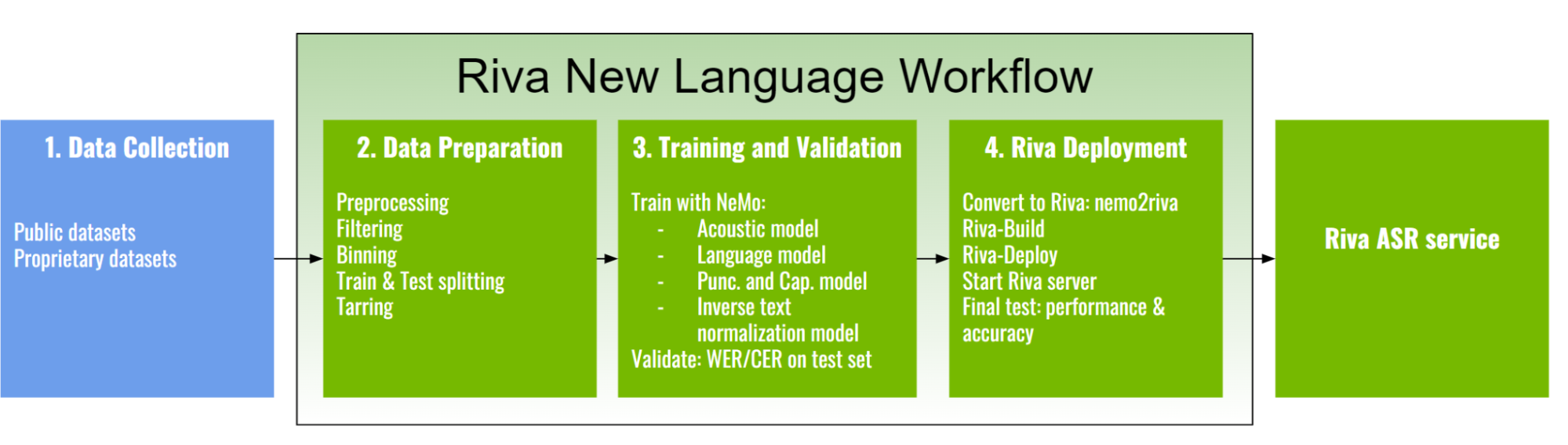
在接下來的部分中,我們將討論每個階段的細節。
第 1 階段:數據收集
當 Riva 適應一種全新的語言時,大量高質量的轉錄音頻數據對于訓練高質量的聲學模型至關重要。在適用的情況下,您可以輕松利用幾個重要的公共數據集來源:
- Mozilla Common Voice (MCV)
- Multilingual LibriSpeech (MLS)
- Voxpopuli
為了訓練 Riva 世界級模型?,我們還獲得了專有數據集。 Riva 生產模型的數據量范圍約為 1700 – 16700 小時。
第 2 階段:數據準備
數據準備階段執行將各種原始音頻數據集轉換為統一格式所需的步驟,該格式可由 NVIDIA NeMo 工具包有效地消化,用于培訓。
- 數據預處理
- 數據清理/過濾
- 數據分箱
- 訓練和試驗分裂
- 數據壓縮
數據預處理
數據預處理需要將音頻或文本數據輸入轉換為機器學習算法的可讀格式。
音頻數據
從各種來源獲取的音頻數據本質上是異構的(文件格式、采樣率、比特深度、音頻通道數等)。作為預處理步驟,您為每個源構建單獨的數據攝取管道,并將音頻數據轉換為通用格式:
- WAV 文件格式
- 16 位的位深度
- 采樣率為 16 kHz
- 單個音頻通道
數據集攝取腳本用于將各種數據集轉換為標準清單格式。
文本數據
文本清理會刪除不屬于語言字母表的字符。例如,我們觀察并刪除了從 MCV、MLS 和 Voxpopuli 收集的德語公共數據集中的一些漢字。
文本規范化將文本從書面形式轉換為口頭形式。它用作預處理 ASR 訓練轉錄本的預處理步驟。
接下來,構建一個文本標記器。聲學模型有兩種幾乎相同的流行編碼選擇:字符編碼和子字編碼。主要區別在于,子字編碼模型接受子字標記化文本語料庫,并在其解碼步驟中發出子字標記。研究和實踐表明,子字編碼有助于提高聲學模型的準確性。
數據清理和過濾
執行此步驟是為了過濾掉數據集中的一些異常樣本。作為最簡單的過程,過濾掉太長、太短或空的樣本。
此外,您還可以過濾掉被認為“有噪聲”的樣本這將包括相對于先前訓練的 ASR 模型具有高字錯誤率( WER )或字符錯誤率( CER )的樣本。
手動檢查這些嘈雜的樣本也會發現一些樣本存在問題,例如轉錄與音頻不匹配。
數據分箱
對于訓練 ASR 模型,可以將不同長度的音頻分組到一個批次中,并使用填充使其長度相同。額外的填充是計算浪費的重要來源。
將訓練樣本拆分為不同長度的桶,并對每個批次從同一桶進行采樣,可提高計算效率。這可能導致訓練加速超過 2 倍。
訓練和試驗分裂
這一步驟是任何深度學習和機器學習開發管道的主要內容,以確保模型在不過度擬合訓練數據的情況下學習概括。對于測試集,使用與訓練數據集不同來源的額外整理數據,如 YouTube 和 TED 演講。
數據壓縮
假設實驗在集群上運行,數據集存儲在分布式文件系統上。在這種情況下,您可能希望避免不斷讀取多個小文件,而是將音頻文件轉換為 tar 。
第 3 階段:培訓和驗證
ASR 管道包括以下模型:
- Acoustic model: 將原始音頻輸入映射到每個時間步的文本標記概率。這個概率矩陣被饋送到解碼器,該解碼器將概率轉換為文本標記序列。
- (Optional) Language model: 用于聲學模型輸出的解碼階段。
- (Optional) P&C model: 格式化原始抄本,用標點符號和大寫字母進行補充。
- (Optional) ITN model: 從口語格式生成所需的書面格式。
聲學模型
聲學模型是 ASR 服務中最重要的部分。它們是資源最密集的模型,需要大量數據在強大的 GPU 服務器或集群上進行訓練。它們對總體 ASR 質量的影響也最大。
Riva 支持的一些聲學模型包括 QuartzNet 、 CitriNet 、 Jasper 和 Conformer 。
跨語言遷移學習在為低資源語言訓練新模型時尤其有用。但是,即使有大量的數據可用,跨語言遷移學習也有助于進一步提高性能。它基于音素表示可以在不同語言之間共享的思想。
在進行轉移學習時,與從頭開始的培訓相比,您必須使用更低的學習率。當訓練 Conformer 和 CitriNet 等模型時,我們還發現使用[2562048]范圍內的大批量有助于穩定訓練損失。
除英語外,生產中的所有 Riva ASR 模型都通過跨語言遷移學習進行了訓練,該模型是用最多的音頻時數訓練的英語基礎模型。

語言模型
語言模型可以給出表示句子出現在其訓練語料庫中的可能性的分數。例如,一個在英語語料庫上訓練的模型判斷“識別語音”比“毀掉一個漂亮的桃子”更有可能。它還判斷“ Ich bin ein Sch ü ler ”很不可能,因為這是一個法語句子。
可以使用語言模型結合波束搜索解碼來進一步改進由聲學模型預測的轉錄。在我們的實驗中,我們通常通過使用簡單的 n-gram model 觀察到額外 1-2% 的 WER 減少。
當與 LM 結合時,解碼器將能夠將其“聽到”的內容(例如“讓我們點燃一根無謂的棍子”)糾正為更具常識性的內容(即“讓我們點一根香棒”),因為 LM 對后一句的評分將高于前一句。
訓練數據: 我們通過組合 ASR 集合中的所有轉錄文本、標準化、清理,然后使用與上述 ASR 轉錄預處理相同的標記化器進行標記化來創建訓練集。 Riva 支持的語言模型是 n-gram 模型,可以使用 Kenlm toolkit 進行訓練。
標點和大寫模型
標點和大寫模型由預先訓練的 Bidirectional Encoder Representations from Transformers (BERT) 和兩個令牌分類頭組成。一個分類主管負責標點符號任務,另一個負責大寫任務。
反向文本規范化模型
我們利用 NeMo 文本反向歸一化 module 來完成任務。 NeMo ITN 基于 weighted finite-state transducer (WFST) grammars 。該工具使用 Pynini 構建 WFST ,創建的語法可以導出并集成到 Sparrowhawk ( the Kestrel TTS text normalization system 的開源版本)中進行生產。
第 4 階段: Riva 部署
一旦所有模型都經過培訓,就應該將它們部署到 Riva 進行服務。
帶上自己的模型
鑒于您迄今為止培訓的最終.nemo模型,以下是在 Riva 上部署所需的步驟和工具:
- Riva 快速啟動腳本提供
nemo2riva轉換工具,以及用于下載servicemaker、riva-speech-server和.rivaDocker 圖像的腳本(riva_init.sh、riva_start.sh和riva-speech-client)。 - 在
servicemaker容器中使用nemo2riva命令構建.riva資產。 - 使用
servicemaker容器中的riva-build工具構建 RMIR 資產。 - 使用
riva-deploy以.rmir格式部署模型。 - 使用
riva-start.sh.啟動服務器
服務器成功啟動后,您可以查詢服務以測量準確性、延遲和吞吐量。
Riva NGC 上的預訓練模型
或者,您可以使用 NGC 上發布的 Riva 預訓練模型。這些模型可以按原樣部署,也可以作為微調和進一步開發的起點。
案例研究:德語
對于德語,有幾個重要的公共數據集來源,您可以輕松訪問:
- Mozilla Common Voice ( MCV )語料庫 7.0 , DE 子集: 571 小時
- Multilingual LibriSpeech ( MLS ), DE 子集: 1918 小時
- Voxpopuli , DE 子集: 214 小時
此外,我們還獲得了總計 3500 小時培訓數據的專有數據!
我們從 NeMo DE Conformer-CTC large model (在 MCV7.0 上訓練 567 小時,在 MLS 上訓練 1524 小時,在 VoxPopuli 上訓練 214 小時)開始訓練最終模型,該模型本身使用 English Conformer model 作為初始化(圖 5 )。

所有 Riva 德國資產都在 NGC 上發布(包括.nemo、.riva、.tlt和.rmir資產)。您可以使用這些模型作為開發的起點。
聲學模型
- Citrinet ASR 德語:
- 符合 ASR 德語
ITN 模型
NGC 提供了一個 OpenFST finite state archive (.far) ,用于開源 Sparrowhawk 標準化引擎和 Riva 。
語言模型
NGC 提供了使用 KenLM 進行 Kneser-Ney 平滑訓練的 4-gram 語言模型 。此目錄還包含手電筒解碼器使用的解碼器字典。
P & C 模型
NGC 提供了 Riva P&C 德語模型?。
案例研究:印地語
對于印地語,您可以輕松訪問 Hindi-Labelled ULCA-asr-dataset-corpus 公共數據集:
- 紐森航空( 791 小時)
- 斯瓦揚普拉巴( 80 小時)
- 多個來源( 1627 小時)
我們從 NeMo En Conformer-CTC medium model 開始訓練印地語 Conformer CTC 介質模型作為初始化。印地語模型的編碼器用英語模型的編碼器權重初始化,解碼器從頭初始化(圖 6 )。

開始并帶上自己的語言
NVIDIA Riva 語音人工智能生態系統(包括 NVIDIA TAO 和 NVIDIA NeMo )為新語言提供了全面的工作流程和工具,使其成為一種系統化的方法,可以將您自己的語言納入其中。
無論您是為特定于領域的應用程序微調現有的語言模型,還是為使用少量或大量數據的全新方言實現語言模型, Riva 都提供了這些功能。
有關 NVIDIA Riva ASR 工程團隊如何開發新語言的更多信息,請參閱 Riva new language tutorial series 并將其應用到您自己的項目中。
?
?