
隨著 代理式 AI 系統 的發展并成為優化業務流程的關鍵,開發者必須定期更新這些系統,以適應不斷變化的業務和用戶需求。通過 AI 和人類反饋不斷完善這些智能體,可確保它們保持有效性和相關性。
NVIDIA NeMo 微服務是一種完全加速的企業級解決方案,旨在簡化穩健數據飛輪的創建和維護,幫助 AI 代理保持適應性、高效率和最新狀態。
在本文中,我將全面介紹 NVIDIA NeMo 微服務,讓您深入了解其保持 AI 智能體以峰性能運行的關鍵功能。
需要 AI 數據飛輪
與傳統系統不同,AI 智能體可以自主運行,推理復雜的場景,并在動態環境中做出決策。隨著這些系統的發展,企業開始構建 多智能體系統 ,其中 AI 智能體跨平臺集成并與人類團隊協作以增強運營,保持整個系統的更新以保持相關性和有效性變得越來越具有挑戰性。
解決方案在于采用 數據飛輪 策略,即通過學習有關每個 agent 交互的反饋來不斷調整為每個 agent 提供支持的每個模型。數據飛輪是一種自我增強的循環,其中來自人類反饋、現實世界和 AI 交互的數據不斷增強系統,使其能夠適應和完善決策制定 (圖 1)。
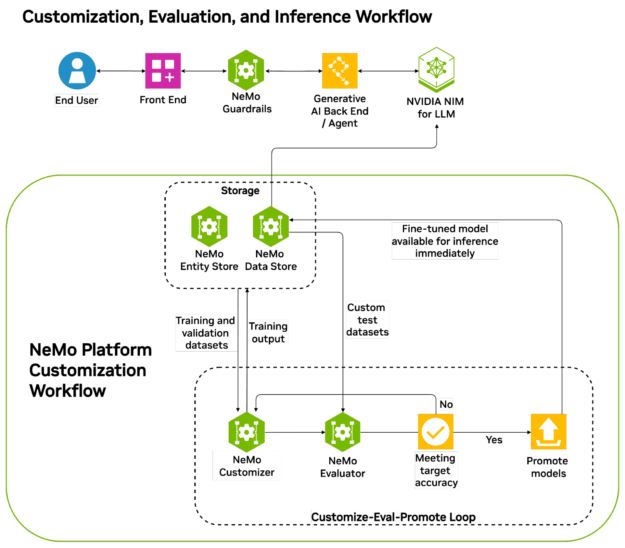
為了保持有效的 AI 數據飛輪,至關重要的是管理數據生命周期,建立集中反饋系統來評估代理的績效,并確保及時更新以防止響應過時,同時減少對耗時的人工干預的依賴。
使用 NVIDIA NeMo 微服務開發和部署 AI 智能體
NVIDIA NeMo 微服務是一個端到端的全加速平臺,用于構建數據飛輪。您可以使用行業標準 API 和 Helm 圖表來簡化代理系統的開發和部署。您還可以設置數據飛輪,使 AI 智能體不斷更新最新信息,同時保留對專有數據的完全控制。
此外,您還可以構建在任何 GPU 加速環境 (包括本地) 上運行的安全、靈活的工作流,并開發具有企業級安全性和支持的高性能代理式系統。
借助 NeMo 微服務簡化 AI 數據飛輪
NeMo 微服務提供了以下一組功能強大的工具,用于管理 AI 智能體的整個生命周期,并構建高效的數據飛輪,從而利用新的相關數據不斷改進底層模型,從而在 AI 驅動的系統中實現持續改進、適應性和復合價值:
- NeMo Curator:GPU 加速模塊,用于管理高質量的多模態訓練數據。
- NeMo Customizer:高性能、可擴展的微服務,可簡化 大語言模型(LLMs) 對下游任務的微調。
- NeMo Evaluator:使用學術和自定義基準自動評估自定義 AI 模型。
- NeMo Retriever: 經過微調的微服務,可為多模態數據集構建具有可擴展文檔提取和高級 檢索增強生成 (RAG) 功能的 AI 查詢引擎 。
- NeMo Guardrails:用于構建穩健安全層的無縫編排器,可確保準確、適當且安全的代理交互。
- NIM Operator: Kubernetes Operator,旨在促進在 Kubernetes 集群上部署、管理和擴展 NeMo 和 NIM 微服務。
使用 NeMo 構建數據飛輪的真實示例
在 NVIDIA,我們使用 NeMo 微服務創建了一個數據飛輪,該飛輪可持續提升我們內部由 AI 驅動的系統 NVInfo bot 的性能。此智能系統可協助員工完成任務、信息檢索和系統導航,從而提高員工工作效率。
NVInfo 機器人具有一個路由器代理,可將查詢引導至相應的專家代理,并由使用 NeMo Curator、NeMo Retriever 和 NVIDIA NIM 的檢索系統提供支持,通過 RAG 流程增強專家代理的相關性和有效性 (圖 2)。
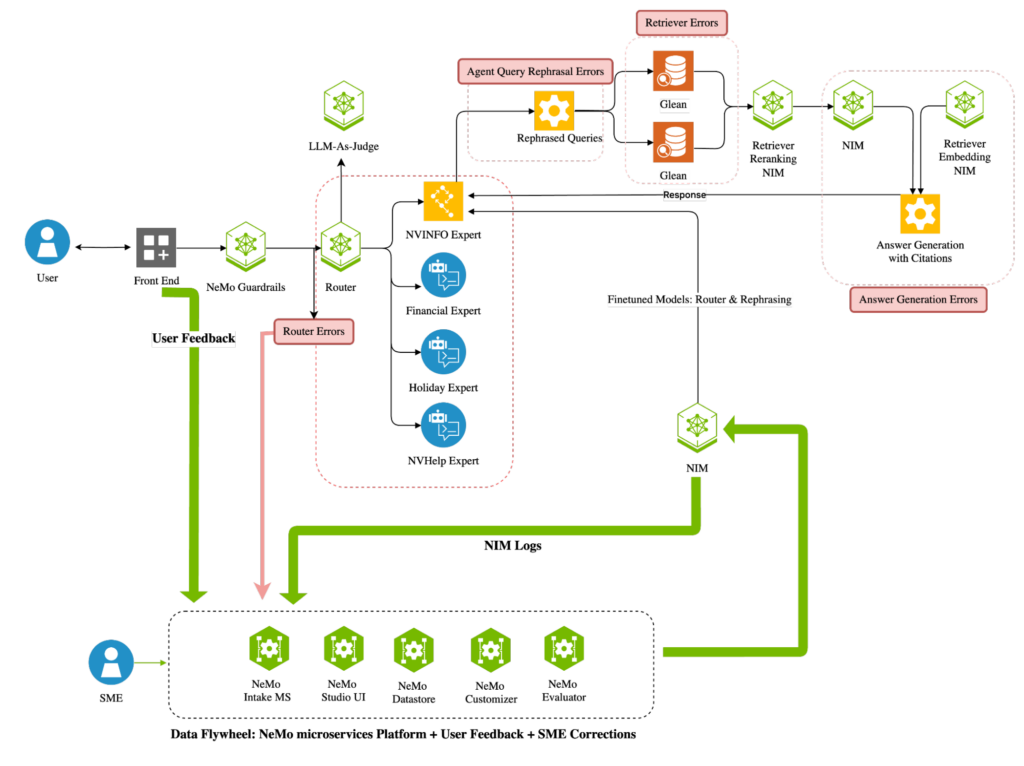
通過設置由 NVIDIA NeMo 微服務提供支持的數據飛輪,NVInfo 機器人的路由代理通過不斷調整和調整較小的 Llama-3.1-8B 模型與加速的 human-in-the-loop (HITL) 評估工作流程,同時匹配更大的 70B 模型的性能,實現了 96% 以上的準確率。這種優化使工作負載能夠在單個 GPU 上運行,而不是在兩個 GPU 上運行,從而降低總體擁有成本 (TCO) ,并將延遲降低 70% 以上。
這種方法使您能夠從較小的模型開始,同時通過持續優化實現卓越性能,從而獲得更低延遲和 TCO 的優勢。使用 NeMo Guardrails 確保機器人的交互始終專注于主題,同時調節語言、相關性和毒性。
使用 NVIDIA Blueprints 快速設置數據飛輪
NVIDIA Blueprints 是預定義、可自定義的 AI 參考工作流,針對特定用例進行定制,旨在幫助您創建和部署生成式 AI 應用程序。 它們包括使用 NVIDIA NIM 和合作伙伴微服務構建的示例應用程序、參考代碼、自定義文檔和用于部署的 Helm 圖表。
不久,NVIDIA 將提供 Data Flywheel Blueprint,在構建 AI 數據飛輪方面開創先河,這些應用可將模型與專有數據連接起來,并利用專有數據進行持續改進。 NVIDIA NeMo 可促進這一過程 ,而 NVIDIA AI Foundry 可作為運行飛輪的生產環境 。
LlamaStack 上的 NeMo
NVIDIA NeMo 微服務也將很快作為 LlamaStack 上現有 NVIDIA 發行版的一部分與 NIM 微服務一起提供。借助 LlamaStack 的統一 API,您可以無縫使用 NeMo 構建生成式 AI 應用并設置數據飛輪。
統一平臺上的模塊化方法
雖然 NeMo 微服務是用于構建數據飛輪的端到端平臺,但您還可以靈活地單獨部署微服務,以增強您的應用。
NeMo Curator
通過高效的數據管道整理高質量數據對于開發代理式 AI 至關重要,因為它可以確保模型基于準確、相關和多樣化的數據集進行訓 AI,從而提高性能和可靠性。
NeMo Curator 提供了一系列可擴展的數據管護模塊,用于管護高質量的多模態數據集,能夠將數據擴展至 100+ PB 以上。該工具使用 NVIDIA RAPIDS 庫中的 cuDF 和 cuML 進行 GPU 加速處理 ,與其他方法相比,文本處理速度提高了 16 倍,視頻處理速度提高了 89 倍 (圖 3)。
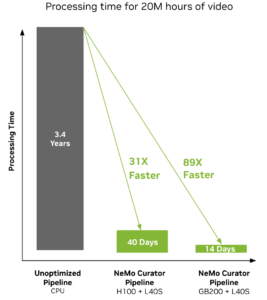
* 在 2K CPU 和 128 個 DGX 節點上與 ISO 功耗相比的性能
除了數據提取、處理和質量評估之外,NeMo Curator 還支持合成數據生成,為提示生成和對話創建等各種用例提供預構建的流程。借助此功能,您可以增強現有數據集,或在現實世界數據稀缺時創建全新的數據集。
通過生成高質量的精選數據集,NeMo Curator 可顯著提高 LLM 訓練效率,從而提高模型準確性和收斂速度。
NeMo Customizer
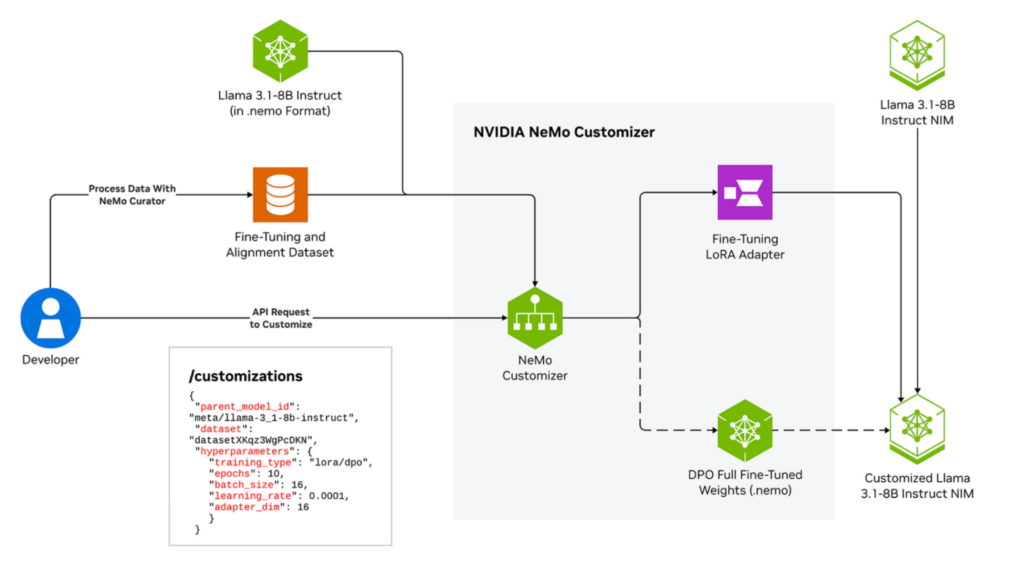
NeMo Customizer 是一項可擴展的微服務,可提供先進的高性能微調功能,包括監督式微調和 LoRA 。 它支持使用模型并行技術 (包括 tensor parallelism) 加速定制各種 LLM。它支持單節點多 GPU 和多節點配置,可靈活優化訓練時間和吞吐量,從而將性能提高 1.8 倍 (圖 4)。
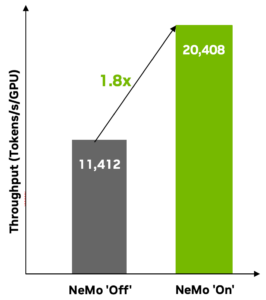
在 8 個 H100 80G SXM 上自定義 Llama-3-8B,并采用順序封裝 (封裝尺寸為 4096,封裝效率為 0.9958) 。開:使用 NeMo Customizer 定制;關:使用領先的市場替代方案定制。
NeMo Customizer 生成的模型可與 NVIDIA NIM 無縫部署,以實現高效推理 (圖 5) 。借助 Helm charts 的簡單配置,您只需調用一次 API 即可進行微調,確保使用 Kubernetes、Slurm 以及獨立的 Docker-only 設置在本地和云環境中輕松進行開發和部署。
NeMo Evaluator
持續一致的評估對于讓智能體保持最佳表現至關重要。這不僅需要在開發時評估模型和流程,而且還需要在生產中進行評估,因為評估基準已經過時。
NeMo Evaluator 通過提供靈活、可擴展的解決方案來評估 LLM、檢索模型、RAG 和代理流程,從而滿足這一需求。它支持自動評估自定義基準和 20 多個行業標準基準,包括 MMLU、GPQA、AIME 和 BBH (Hard)。
NeMo Evaluator 通過使用可共享配置文件,確保跨團隊高效且一致地評估重復性任務 (圖 6) 。借助 Evaluator 微服務,您可以在完全數據控制的情況下隨時隨地大規模運行評估,從而將多步驟評估流程簡化為單個 API 調用,取代 OSS 替代方案。

通過簡化評估流程,NeMo Evaluator 可助力企業組織優化模型性能并建立高效的數據飛輪。
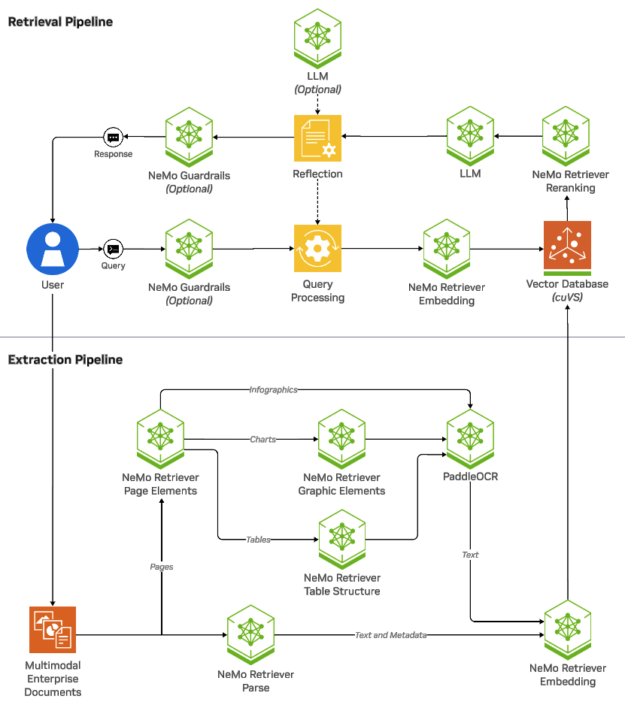
NeMo 檢索器
高效的數據檢索是維護有效數據飛輪的基石,可確保 AI 智能體通過訪問最相關的最新信息來不斷學習和改進。 NeMo Retriever 提供由 AI 驅動的加速系統,可實現高效的多模態數據提取和檢索,從而提供與上下文相關的精確響應。
借助先進的 提取、嵌入和重排序 NIM 微服務 ,NeMo Retriever 可提高檢索準確性和吞吐量,同時提供更快、可擴展和優化的性能。
除了支持多語種和跨語言問答檢索外 ,NeMo Retriever 還通過動態長度和長上下文支持提高存儲效率,將存儲需求降低 35%,并在不影響檢索速度的情況下降低 TCO。通過使用 GPU 加速索引,您還可以提高索引吞吐量,從而快速且經濟高效地擴展 RAG 操作。
立即在 NVIDIA API Catalog 中試用 NeMo Retriever。
NeMo Guardrails
隨著 AI 智能體推動決策制定和客戶互動等關鍵業務運營,確保 AI 模型保持安全并與組織策略保持一致至關重要。
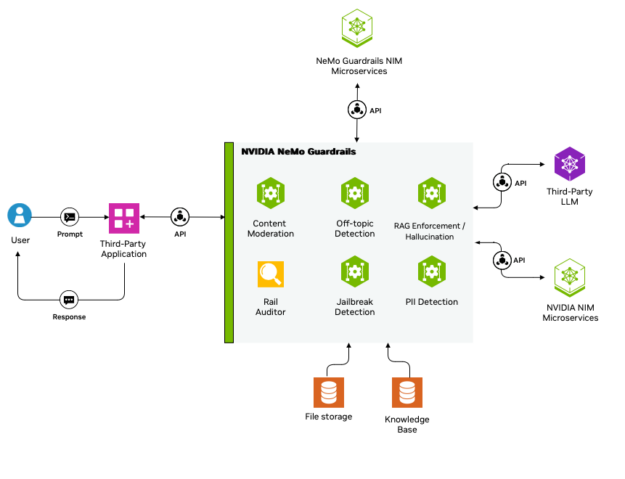
借助 NeMo Guardrails,您可以在代理式 AI 應用中輕松定義、編排和執行 AI 護欄,檢測高達 99% 的違反策略行為,并且只需在亞秒級延遲之間進行權衡。它實施各種安全措施,例如內容審核、離題對話審核、幻覺消除、越獄檢測和個人身份信息保護 (PII)。
NeMo Guardrails 支持在整個 AI 交互過程中添加可編程安全層,從而輕松將這些控制集成到應用中,包括輸入、對話、檢索、執行和輸出軌道,以確保與安全預期和政策保持一致。
NeMo Guardrails 可無縫擴展,支持具有不同 guardrail 配置的多個應用。它集成了第三方和社區安全模型以及 NemoGuard JailbreakDetect、Llama 3.1 NemoGuard 8B ContentSafety 和 Llama 3.1 NemoGuard 8B TopicControl NVIDIA 模型,可提供高度專業化、強大的保護。
NIM 運算符
可以使用容器化的 Kubernetes 發行版和 Helm 圖表單獨部署 NeMo 和 NIM 微服務。但是,當多個 NIM 和 NeMo 微服務相結合以創建復雜的代理式系統(例如 NVInfo Bot)時,管理這些微服務的端到端生命周期可能會給集群管理員和開發者帶來重大挑戰。
NVIDIA NIM Operator 通過 Kubernetes 原生 Operator 和自定義資源定義 (CRD) 簡化了 AI 推理工作流編排,實現了自動部署、生命周期管理、智能模型預緩存 (可降低延遲) 和簡化的自動擴展。通過消除基礎架構的復雜性,您可以專注于創新。
開始使用 NeMo 微服務
隨著 AI 不斷為各行各業帶來變革,保持 AI 智能體更新和發揮作用的重要性只會越來越高。借助 NVIDIA NeMo 微服務,您的組織可以設置數據飛輪,通過持續調整來更大限度地提高代理式 AI 系統的性能,同時提供更高的安全性、隱私性、控制性和集成性,使其能夠靈活地在任何地方運行。
注冊以在 NVIDIA NeMo 微服務可供下載時接收通知 ,并觀看“ 構建可擴展的數據飛輪以持續改進 AI 代理 ”GTC 會議以了解詳情。
?
?






