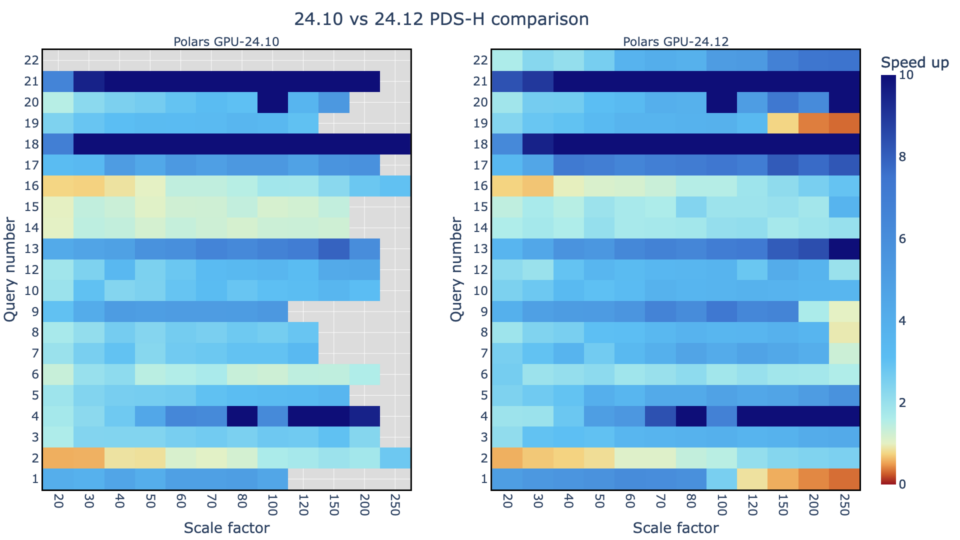
隨著 AI 功能的進步,了解硬件和軟件基礎架構選擇對工作負載性能的影響對于技術驗證和業務規劃都至關重要。組織需要一種更好的方法來評估現實世界中的端到端 AI 工作負載性能和總擁有成本,而不僅僅是比較原始 FLOPs 或每個 GPU 的每小時成本。實現出色的 AI 性能需要的不僅僅是強大的 GPU。它需要一個經過充分優化的平臺,包括基礎架構、軟件框架和應用級增強功能。
在評估 AI 性能時,請提出以下關鍵問題:您的實現是否正確,或者是否存在與參考架構相比減慢您速度的錯誤?集群的最佳規模是什么?選擇哪些軟件框架可以縮短上市時間?傳統的芯片級指標不足以完成這項任務,導致投資未得到充分利用,并且錯過了效率提升。衡量 AI 工作負載和基礎設施的性能至關重要。
本文將介紹 NVIDIA DGX 云基準測試,這是一套工具,用于評估跨 AI 工作負載和平臺的訓練和推理性能,其中包括基礎設施軟件、云平臺和應用配置,而不僅僅是 GPU。本文詳細介紹了 DGX 云基準測試的功能和應用,展示了訓練時間和訓練成本方面的改進結果。
借助 DGX Cloud Benchmarking,NVIDIA 旨在提供一種衡量平臺性能的標準化和客觀方法,類似于 NVIDIA 在自己的硬件和基礎設施上提供客觀且相關性能的方法。
TCO 優化的基準測試要求
經過廣泛的測試,我們團隊收集的數據表明,與 GPU 數量、數據精度和框架相關的時間和成本模式是一致的。組織可以利用這些數據來探索權衡取舍,并加快其決策和 AI 開發時間。
GPU 數量
在 AI 訓練集群中擴展 GPU 數量可以顯著減少總訓練時間,而不一定會增加成本。雖然增加更多 GPU 可以更快地完成 AI 工作,但團隊應探索擴展與項目成本和相關權衡之間的關系。
例如,在訓練 Llama 3 70B 時,您可以將訓練 1 萬億個 token 的時間縮短 97% (115.4 天 → 3.8 天),而成本僅增加 2.6%。
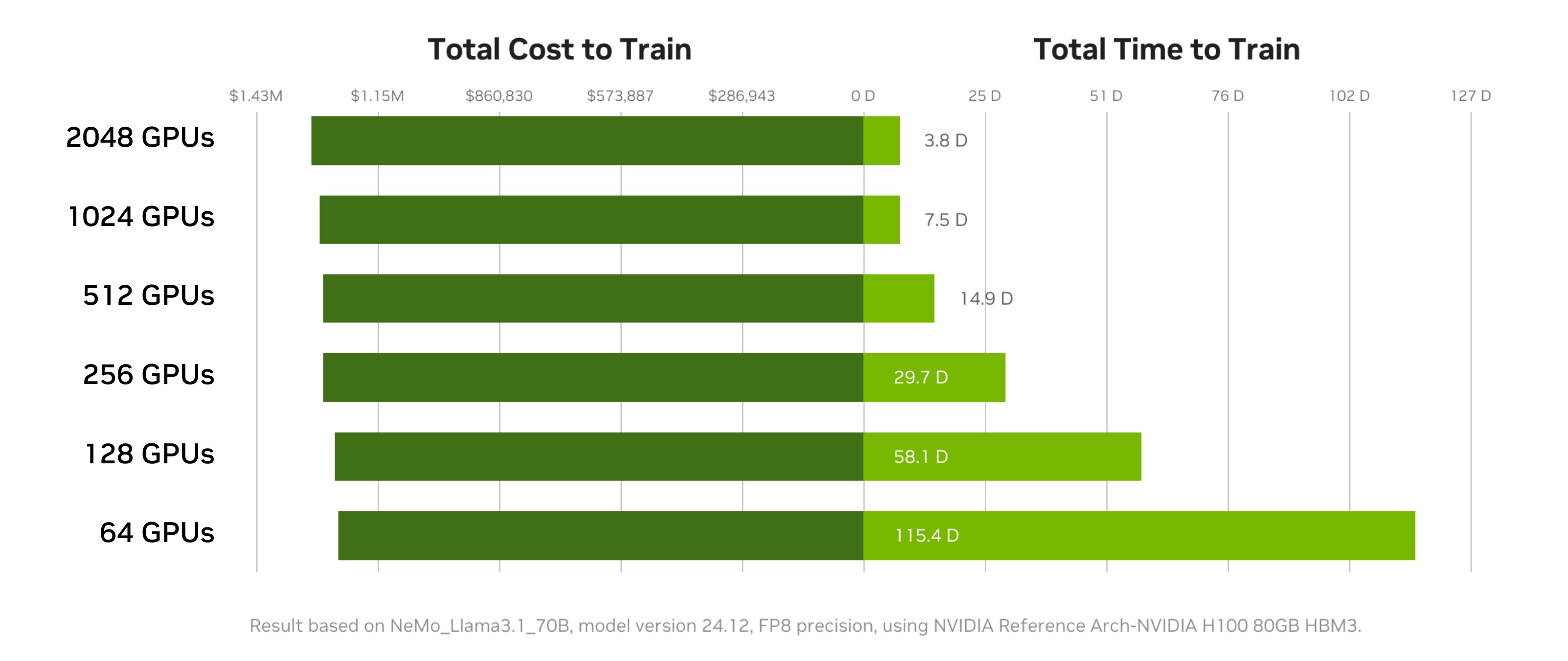
GPU 數量的增加為工作負載并行化提供了靈活性,從而實現更快的迭代周期和更快的假設驗證。更大規模的訓練可以加快整個 AI 開發時間線和開發者速度。當一個組織可以獲得額外的 GPU 時,他們可能可以在更短的時間內完成訓練工作,而不會按比例增加總成本。更快地完成訓練工作還意味著可以更快地投入市場,以便部署經過訓練的模型,為您的組織創造價值。
雖然在實踐中很少能實現完美的線性擴展,但經過充分優化的 AI 工作負載可能非常接近。在 GPU 數量增加的情況下,與完美線性度的細微偏差通常是由于通信開銷增加造成的。通過戰略性地擴展 GPU 數量,團隊可以根據項目目標、可用資源和優先級進行優化。
使用 NVIDIA DGX 云基準測試性能 Explorer,用戶可以確定理想的 GPU 數量,從而最大限度地減少總訓練時間和成本。其目標是針對給定的工作負載確定正確數量的 GPU,從而在項目和團隊中最大限度地提高吞吐量并最大限度地減少支出。
精度
使用 FP8 精度代替 BF16 可以顯著提高 AI 模型訓練的吞吐量和成本效益。在訓練中使用 FP8 精度可以加快模型時間到解決方案(time to solution)。由于數學或通信吞吐量更高且內存帶寬要求較低,這降低了訓練模型的總成本。FP8 精度還可以在更少的 GPU 上訓練更大的模型。
將 AI 工作負載遷移到您的平臺支持的最低精度類型可以節省大量成本。圖 2 顯示,在 NVIDIA Hopper 架構 的 GPU 上,FP8 可實現比 BF16 更高的吞吐量(tokens/秒)。
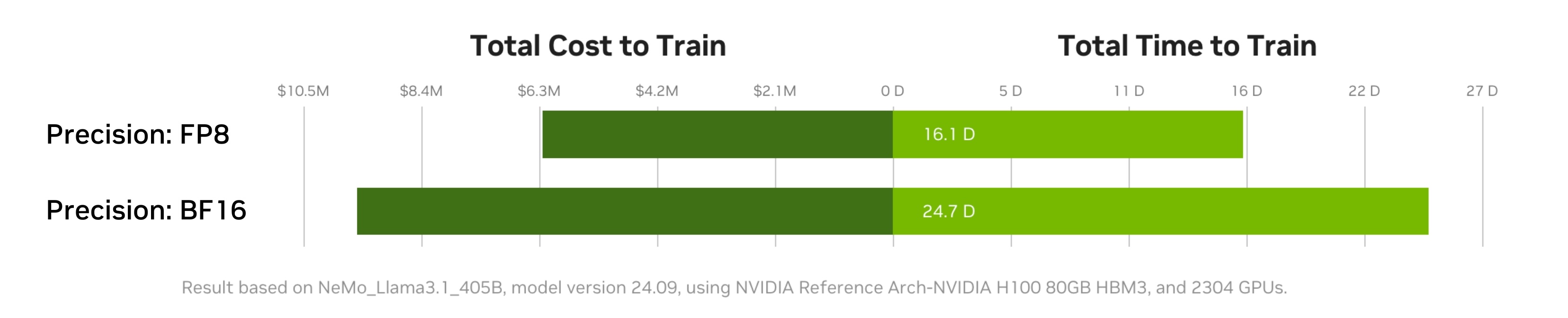
然而,使用 FP8 進行訓練會帶來一些挑戰,例如動態范圍變窄。這些可能會導致不穩定或差異。為了應對這些挑戰,需要使用專門的技術來識別可以使用 FP8 執行的運算——為 BF16 和 FP8 之間的轉換提供按張量或子塊擴展——以保持數值穩定性。此外,Hopper 和 Blackwell 架構中的 Transformer Engine 等功能可以幫助開發者在每層有選擇地使用 FP8,僅在不會對準確性產生不利影響的地方使用降低的精度。
除了訓練工作期間的吞吐量之外,在 FP8 中訓練模型還可以進一步降低推理成本,因為模型可以直接部署用于 FP8 推理。不過,在 BF16 中訓練的模型稍后可以使用量化感知訓練(QAT)或訓練后量化(PTQ)將其量化為 FP8/INT8,從而實現類似的推理性能優勢。
DGX 云基準測試方法提供調優最佳實踐,可借助 FP8 精度和示例基準結果更大限度地提高所交付的平臺性能,以供比較。
框架
選擇合適的 AI 框架可以顯著提高訓練速度并降低成本,即使模型和硬件配置相同。由于以下方面的差異,框架的選擇會影響性能:
- 工作負載基礎設施指紋:框架如何與底層基礎設施交互
- 通信模式:節點之間的數據交換效率
- 持續優化努力:框架開發者通過更新不斷提高性能
為了更大限度地提高性能,選擇符合不斷發展的 AI 生態系統并從持續優化中受益的框架至關重要。隨著時間的推移,框架優化可以顯著提高平臺的整體性能,并提高整體 TCO。
如圖 3 所示,采用新版 NVIDIA NeMo 框架可以顯著提高訓練吞吐量。例如,在 2024 年,NeMo 軟件優化使整體平臺性能提高了 25%,并且由于深度硬件和軟件協同設計,用戶可以按比例節省成本。

NVIDIA 為優化框架配置提供專家指導。NVIDIA Performance Architects 可以直接與團隊合作,對 DGX Cloud 基礎架構上的工作負載進行基準測試,分析結果,并針對特定工作負載提出量身定制的調整建議。 聯系我們,開始合作。
生態系統協作和未來展望
通過利用 DGX 云基準測試方法,NVIDIA 可以描述真實用戶工作負載,確保優化以實際場景為基礎。在初始基礎架構驗證之后,持續的性能評估可確保所提供的吞吐量與理論規格非常匹配。這些性能方案的早期采用者包括領先的云提供商 AWS、Google Cloud、Microsoft Azure 和 Oracle Cloud,以及 NVIDIA 云合作伙伴 CoreWeave、Crusoe 和 Nebius。
DGX 云基準測試旨在與快速發展的 AI 行業一起發展。定期更新包括新模型、新興硬件平臺和創新的軟件優化。這種持續演進可確保用戶始終能夠獲得最相關和最新的性能見解,這對于技術以前所未有的速度進步的行業至關重要。
開始使用
借助 DGX 云基準測試,組織可以依靠標準化的客觀指標來評估 AI 平臺的效率。無論您是負責規劃下一個項目的 AI 開發團隊,還是尋求驗證基礎架構性能的 IT 團隊,DGX 云基準測試都能為您提供所需的工具,幫助您實現峰值 AI 性能。
探索 DGX 云基準測試 ,了解您的平臺特征。 開始使用 LLM 基準測試集合 ,量化精度、集群規模等方面的權衡。與我們一起參加 NVIDIA GTC 2025 ,討論基準測試并探索 DGX 云基準測試。
?
?