摘要
在上一期的 HugeCTR 分級參數服務器簡介中,我們介紹了傳統參數服務器的結構以及 HugeCTR 分級推理參數服務器是如何在其基礎上進行設計和改進的,我們還簡單介紹了我們的三級存儲結構以及相關配置使用。在這一期中,我們將詳細介紹 HPS 數據后端,其中包括 Volatile 數據存儲層,Persistent 數據存儲層以及流式在線模型更新的設計。
1. 概述
HPS 數據后端作為 GPU embedding 緩存架構的基石,同時也是 GPU embedding 緩存在 CPU 內存以及本地磁盤的進一步物理擴展。HPS 數據后端通過綁定不同物理層級的存儲從而提供了大型模型 embedding table 的緩存,查詢,更新以及容錯等服務,目的即為了保證在推理服務中 GPU embedding 緩存的高命中率,從而提高推理服務的吞吐大幅度降低端到端的延遲。

2. Volatile 數據后端
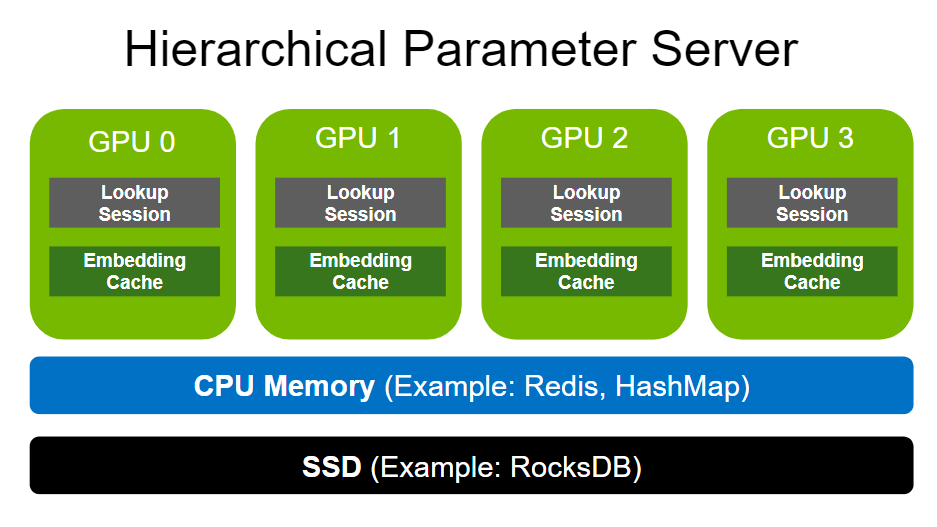
Volatile 數據后端以 RAM Memory 作為主要存儲介質,提供本地或者遠端更加快捷的參數讀寫服務。既可以作為 GPU embedding 緩存的擴展,也可以作為本地磁盤的(Persistent 后端)緩存。由于 Persistent 數據后端的存儲容量可以理解為無限巨大,但是同時也就意味著在實際的推理服務中的讀寫速度也是相對較慢的。因此 Volatile 數據后端彌補了 Persistent 數據庫的缺陷,極大擴展了有限的 GPU 內存。但是 Volatile 數據庫的容量本質上也是有限的,因此我們通過實現參數的分區,驅逐以及共享進一步提高 RAM Memory 帶來的上限。
- 為了保證 Volatile 數據后端可以適用于更廣泛的推薦部署場景,我們同樣實現了針對不同場景的本地化或者分布式存儲機制。從下圖中我們可以看到,針對 HashMap 此類常規的存儲結構,通過實例化 Volatile 數據后端,可以保證每個數據節點都將擁有一個獨立本地化的存儲實例。對于本地化的 Volatile 數據后端,我們不僅實現了分區優化的 HashMap 結構,還實現了高性能的 Parallel HashMap 數據結構,進而大幅度提升了本地參數的查詢和讀寫服務。
- 與之相反的,則是分布式共享 Volatile 數據后端,分布式的數據后端將參數通過邏輯分區保存在不同的網絡節點,即 Redis Cluster(既可以將參數分布式存儲在遠端的數據節點,同樣也可以是相同的推理節點)。通過使用集群中共享 RAM 內存進行參數的存儲和讀寫,進一步擴大了 Volatile 數據庫容量,也提供了 Redis 持久化特性(RDB 和 AOF 等 ),從而使得跨節點重啟之后的讀寫操作可以無縫進行。 由于共享的機制,也實現了 HugeCTR 模型訓練到推理的參數無縫更新。

為了最大限度地提高性能并避免由零星 RAM memory 在 Volatile 數據后端中的高效使用(即內存不足的情況),我們提供了溢出處理機制。 它允許限制每個分區存儲的最大嵌入量,從而限制分布式數據庫的內存消耗。當前我們允許用戶配置不同的驅逐更新策略(隨機驅逐以及 LRU)來保證內存最大限度的利用。對于本地化的參數分區以及查詢機制,用戶可以對數據后端顯式的配置分區數量以及分區大小來更加細粒度的提高數據后端的查詢讀寫服務。具體來說,用戶可以通過配置 max_get_batch_size,max_set_batch_size 以及并發線程數來精準控制讀寫開銷。
具體參數配置信息可以參考 HPS 配置詳解:https://github.com/triton-inference-server/hugectr_backend/blob/main/docs/hierarchical_parameter_server.md#6-configuration
3. Persistent 數據后端
Persistent 數據后端以本地 SSDs 作為持久化存儲介質,維護一個完整的模型參數部分,同時承載著模型參數的容錯的功能。相對于 GPU embedding 緩存與 Volatile RAM 緩存,Persistent 數據后端可以看作是一個擁有無限虛擬空間的存儲后端,同時也作為一個本地化的 Key-value 查詢引擎,在此我們引入了性能優化后的 RocksDB 作為 Persistent 后端的實現。
每個推理節點通過 HPS 的配置文件即可在本地磁盤保留所有模型 embedding table 的獨立完整副本。 Persistent 數據后端也是對分布式 Volatile 數據后端的進一步補充:1) 進一步擴展存儲容量的同時, 2) 實現高可用性。 特別是對于超大規模的模型(甚至超過了分布 Redis Cluster 的總 RAM 容量),或者由于網絡帶寬等硬件限制造成 Redis Cluster 不可用,RocksDB 的分成存儲結構 同樣可以完全滿足高并發參數查詢請求。

針對 Persistent 后端的 Rocksdb 會以分塊查詢機制來獲取最大性能。針對不同的硬件基礎設施,用戶可以進行定制化的配置,從而保證硬件資源的利用率以及推理性能的最大化。
4. 流式增量更新
通過優化后 Kafka 的發布更新機制,推理節點中的每個 HPS 實例所對應的不同層級的數據后端通過訂閱對應模型的 Topic,消費實時的增量模型參數,實現模型的異步更新。在具體實現中,我們提供兩個簡單易用的抽象接口,分別是 MessageSink 和 MessageSource,保證了增量模型從訓練端向推理端的無縫更新。
用戶可以通過 JSON 格式的配置文件,任意組合搭配適用于部署場景的數據后端,保證每個部署節點充分的利用上文所提到的所有存儲介質。由于 HPS 是構建于 Triton 推理架構之上。正如下圖所展示的完整 HPS 訓練推理數據流示意圖,每個 Triton 節點通過 Volatile 數據后端既可以維護高性能的本地 RAM 緩存,同時也可以負責維護對應 Redis 節點的參數分區,Redis cluster 中的分區參數既可以通過訓練與推理集群共享,也可以通過訂閱 Kafka 數據源來實現無縫的參數更新。模型在 HugeCTR 訓練平臺可以實時將在線訓練中的增量模型推向分布式的 Kafka 隊列,相同 JSON 配置的推理節點會自動檢測和監控消息隊列,從而保證了推理節點的 Persistent 數據后端始終維護完整的最新版本的參數副本,為推理服務的容錯提供了保障。

5. 結語
在這一期的 HugeCTR 分級參數服務器介紹中,我們介紹了 CPU 分布式緩存,本地緩存,以及在線更新的設計細節。在下一期中,我們將著重介紹 HugeCTR 分級參數服務器中最關鍵的組件:Embedding Cache 的設計細節,敬請期待。
以下是 HugeCTR 的 Github repo 以及其他發布的文章,歡迎感興趣的朋友閱讀和反饋。
Github: https://github.com/NVIDIA-Merlin/HugeCTR (更多文章詳見 README)
除此之外,NVIDIA Merlin HugeCTR 團隊正在積極招募 C++ 以及 CUDA 工程師,歡迎各位有意向的同學發郵件至 jershi@nvidia.com 或 yincanw@nvidia.com 積極申請!JD 請見 https://mp.weixin.qq.com/s/Tg8xtbs0HN7UbtSmRenJ1g