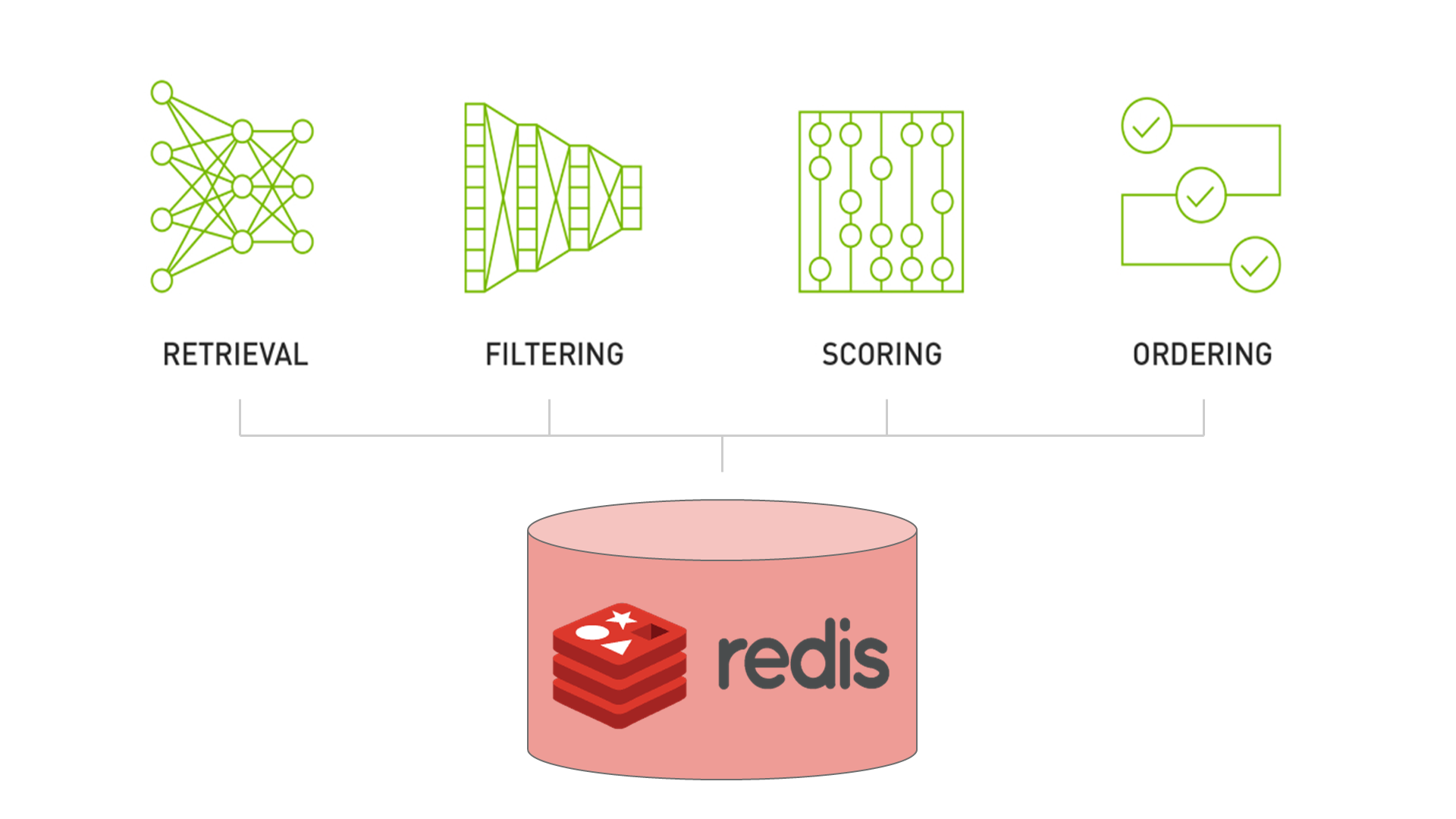
Merlin HugeCTR(以下簡稱 HugeCTR)是 GPU 加速的推薦程序框架,旨在在多個 GPU 和節點之間分配訓練并估計點擊率(Click-through rate)。
此次 v3.4 更新涉及的模塊主要為:
相關介紹:
V3.4 版本新增內容
- 使用 Merlin Unified Container 支持 HugeCTR 開發:
Merlin v22.02 開始,我們鼓勵您按照貢獻者 指南 中的說明在 Merlin Unified Container(發布容器)下開發 HugeCTR,以保持開發環境一致。
- 分層參數服務器的新增內容:
- 缺失鍵的插入功能: 通過一個簡單的標志,現在可以配置 HugeCTR,以便使在查找期間丟失的 Embedding 條目自動插入到 Redis 和 Hashmap 后端等數據庫層中。
- 異步時間戳刷新: 在上一個版本中,我們引入了傳遞時間感知驅逐策略。這些策略適用于通過刪除鍵來縮小數據庫分區,如果它們的增長超過了某些限制。但是,這些驅逐策略使用的時間信息代表了更新時間。因此,Embedding 是基于自上次更新以來經過的時間而被驅逐的。如果您在推理模式下操作 HugeCTR,則 Embedding table 通常是不可變的。通過上述缺失的密鑰插入功能,我們現在支持在查找期間主動調整數據庫層的內容以適應數據分布。為了允許基于時間的驅逐發生,現在可以為經常使用的 Embedding 啟用時間戳刷新。啟用后,將使用后臺線程異步處理刷新。因此,它不會阻塞您的推理工作。對于大多數應用程序,啟用此功能對性能的相關影響幾乎不明顯。
- 在訓練中支持導出到 HDFS(Hadoop Distributed File System)
- 提供了一個新的 Python API DataSourceParams 用于指定文件系統以及數據和模型文件的路徑。
- 支持將數據從 HDFS 加載到本地文件系統進行 HugeCTR 訓練。
- 支持將訓練好的模型和優化器狀態轉儲到 HDFS。
- 模型密集部分參數在線無縫更新
HugeCTR Backend 現已支持通過 Load API 在線更新模型版本(包括密集部分的無縫更新以及同一模型對應的嵌入推理緩存),并且 Load API 仍然完全兼容新模型的在線部署。
- SOK 的新增內容:
- 混合精度訓練:
現在可以通過 TF 的模式啟用混合精度訓練,以提高訓練性能并減少內存使用。
- DLRM 相關性能指標更新。
- 現已支持使用 Pypi 來 pip install。
- 現已支持 Uint32_t / int64_t 的 Embedding key dtype:
默認情況下,key dtype 為 int64。
- 添加了 TensorFlow 的初始化程序支持。
- 用戶體驗增強:
- 我們修改了幾個 Jupyter 筆記本和自述文件,以闡明使用說明并使 HugeCTR 更易用。
- 感謝 GitHub 用戶 @MuYu-zhi,他提醒我們,配置過少的共享內存會影響 HugeCTR 的正常運行。我們擴展了 SOK docker 設置說明,以解決如何使用 docker 的 `–shm-size` 設置解決此類問題。
- 盡管 HugeCTR 是為可擴展性而設計的,但對于較小的工作負載和測試來說,擁有強大的機器并不是必需的。我們在 README 中添加了有關 Jupyter 筆記本測試環境所需規范的信息。
- 多任務
我們現已支持多任務的 HugeCTR 推理。當標簽維度是二分類任務的數量并且 MultiCrossEntropyLoss 在訓練過程中使用了時,推理結果的維度將是 (batch_size*num_batches, label_dim)。有關更多信息,請參閱 推理 API。
- 修復了超小型 Embedding table 在 Embedding Cache 中的緩存問題
已知問題
- HugeCTR 使用 NCCL 在 rank 之間共享數據,并且 NCCL 可能需要共享系統內存用于 IPC 和固定(頁面鎖定)系統內存資源。在容器內使用 NCCL 時,建議您通過發出以下命令 (-shm-size=1g -ulimit memlock=-1) 來增加這些資源。
另見 NCCL 的已知問題 以及GitHub 問題。
- Softmax 層目前暫不支持 16 位浮點數模式。
- 目前即使目標 Kafka broker 無響應,KafkaProducers 啟動也會成功。為了避免與來自 Kafka 的流模型更新相關的數據丟失,您必須確保有足夠數量的 Kafka brokers 啟動、正常工作并且可以從運行 HugeCTR 的節點訪問。