Merlin HugeCTR(以下簡稱 HugeCTR)是 GPU 加速的推薦程序框架,旨在在多個 GPU 和節點之間分配訓練并估計點擊率(Click-through rate)。
此次 v3.5 更新涉及的模塊主要為:
相關介紹:
V3.5 版本新增內容
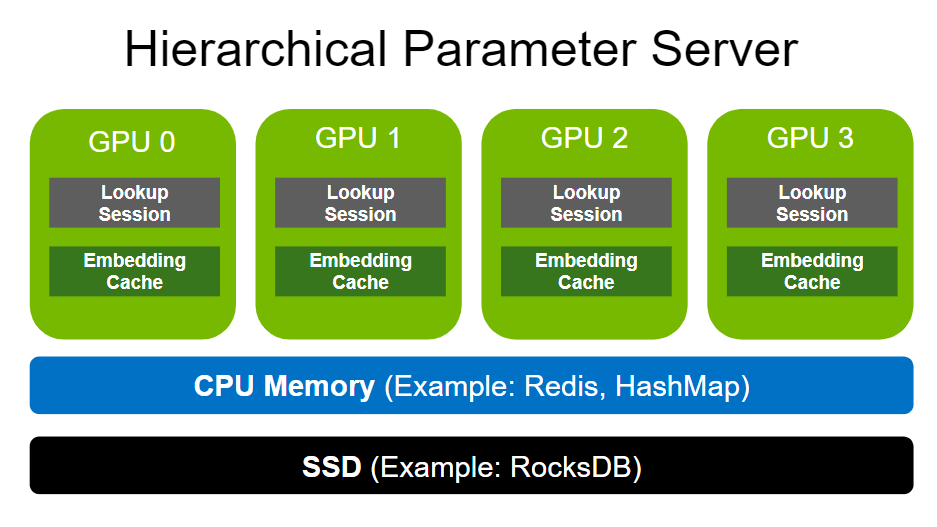
- HugeCTR 分級參數服務器(以下簡稱HPS)已被單獨封裝和導出為庫:
我們封裝了 HPS 的相關接口并將其作為獨立庫提供。此外,我們提供 HPS Python API 并通過 Jupyter nontebook 演示其用法。更多信息請參考分層參數服務器文檔和 HPS 演示。
- 新增了 HPS Triton 后端
HPS 后端是一個用于嵌入向量在大規模嵌入表上查找的框架,旨在通過將嵌入表和嵌入緩存與深度推薦模型的端到端推理管道。更多信息請參考分層參數服務器。
- SOK 已在 pypi 上發布(https://pypi.org/project/merlin-sok/):
用戶可以通過 `pip install merlin-sok` 安裝 SOK。
- 聯合損失函數和多任務訓練支持:
我們現已在訓練中支持聯合損失,以便用戶可以使用多個標簽和不同權重的任務進行訓練。 API 擴展允許用戶定義多個標簽、損失層和相應的權重。用戶可以根據需要在訓練迭代之間更改權重。添加了 MMoE 示例以顯示用法(https://github.com/NVIDIA-Merlin/HugeCTR/tree/master/samples/mmoe)
- HugeCTR 網頁版文檔:
現在用戶可以訪問網頁版文檔了(https://nvidia-merlin.github.io/HugeCTR/master/)。
- ONNX 轉換器優化:
我們啟用將 MultiCrossEntropyLoss 和 CrossEntropyLoss 層轉換為 ONNX 以支持多標簽推理。更多信息請參考 HugeCTR to ONNX Converter。
- HPS 性能優化:
在 HPS 中使用更好的方法來確定數據庫后端中的分區號。
- HDFS python API 優化:
簡化 DataSourceParams 以便用戶在真正需要之前無需提供所有路徑。現在用戶只需在創建求解器時傳遞一次 DataSourceParams。后續的路徑將根據 DataSourceParams 設置自動判斷本地路徑或 HDFS 路徑。
- 錯誤修復:
HugeCTR 輸入層現在可以接受維度大于等于 1000 的稠密部分了。
已知問題
- HugeCTR 使用 NCCL 在 rank 之間共享數據,并且 NCCL 可能需要共享系統內存用于 IPC 和固定(頁面鎖定)系統內存資源。在容器內使用 NCCL 時,建議您通過發出以下命令 (-shm-size=1g -ulimit memlock=-1) 來增加這些資源。
另見 NCCL 的 已知問題。還有 GitHub 問題。
- 目前即使目標 Kafka broker 無響應,KafkaProducers 啟動也會成功。為了避免與來自 Kafka 的流模型更新相關的數據丟失,您必須確保有足夠數量的 Kafka brokers 啟動、正常工作并且可以從運行 HugeCTR 的節點訪問。
- 文件列表中的數據文件數量應不小于數據讀取器的數量。否則,不同的 worker 將被映射到同一個文件,導致數據加載不會按預期進行。
- 聯合損失訓練暫不支持對每個損失層使用不同的正則化器。
- 聯合損失訓練暫不不支持動態損失權重。
NVIDIA Merlin HugeCTR 團隊正在積極招募 C++ 以及 CUDA 工程師(工作地點北京,上海,深圳),詳細 JD 請見 https://mp.weixin.qq.com/s/Tg8xtbs0HN7UbtSmRenJ1g。歡迎感興趣的同學掃描下方小程序二維碼進行申請!