介紹
通過封裝 NVIDIA Merlin HugeCTR,Sparse Operation Kit(以下簡稱 SOK)使得 TensorFlow用戶可以借助 HugeCTR 的一些相關特性和優化加速 GPU 上的分布式 Embedding訓練。
在以往文章中(Merlin HugeCTR Sparse Operation Kit 系列之一 – NVIDIA 技術博客, Merlin HugeCTR Sparse Operation Kit 系列之二 – NVIDIA 技術博客),我們對 HugeCTR SOK 的基本功能、性能、用法和原理做了詳細的介紹。近期 SOK 又發布了多個版本迭代,這篇博客對最新 v2.0 版本中的新特性 (尤其是動態Embedding 和在線訓練增量導出),用法進行了歸納總結和介紹,并在最后介紹了 SOK 在手機行業的應用案例。

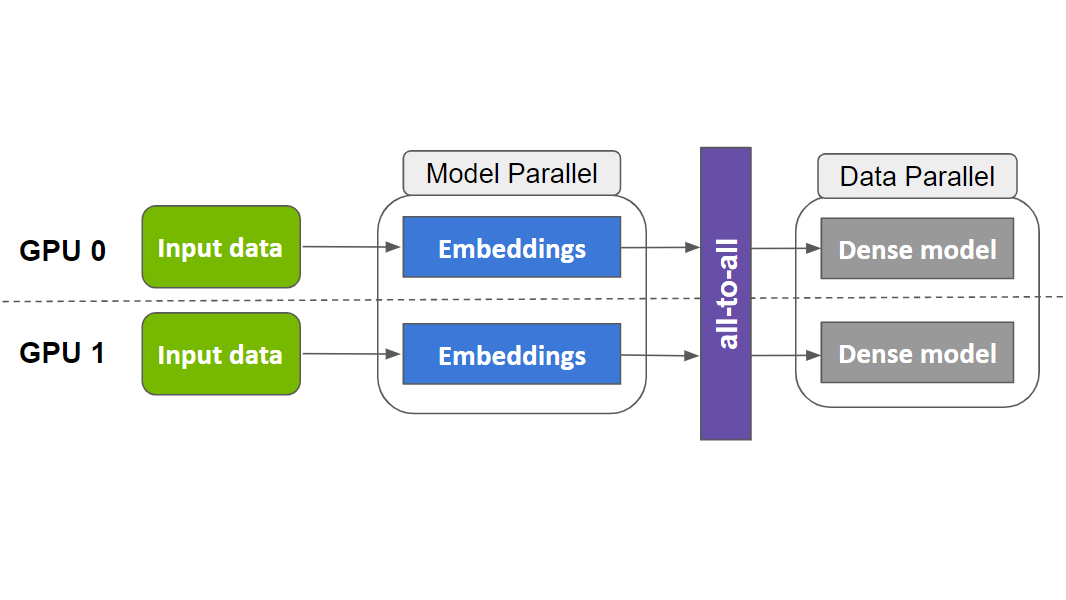
圖 1. SOK 訓練的數據并行-模型并行-數據并行流程
特性
SOK 作為 TensorFlow 的 plugin,專注于針對 embedding 的儲存和查詢過程進行優化,以下是目前 SOK 提供的主要功能:
- 提供 embedding 部分的多機多卡模型并行功能;
- 為 embedding table 提供了 hash table 的功能,并且該 hash table 可以將 embedding vector 存放到 device memory 和 Host memory 上,充分利用設備儲存;
- 為 embedding lookup 提供了高性能的 embedding lookup kernel, 采用 HugeCTR 的 cuda kernel 為后端,fuse 多個 lookup op 到一個 lookup op,提升 embedding lookup 性能;
- 提供增量導出功能,導出某個時間點后 embedding table 中更新過的 key 和 value,減少訓練權重推送到推理端的開銷。
立即使用 SOK
Embedding Table
SOK 基于 Tensorflow 的 Variable 的基礎上,提供了 Variable 和 DynamicVariable 來儲存 embedding table。
不同于 TensorFlow 的 Variable 將數據儲存到某個 GPU 中,SOK 的 Variable 可以將數據均勻儲存在訓練的所有 GPU 上,也可以將數據儲存到某一個 GPU 中,下面是使用 SOK 的 Variable 創建儲存在每一個 GPU 和 Variable 儲存到 GPU0 上的例子:
# Default method of sok.Variable is Distributed method,Variable evenly distributed to each GPU
v1 = sok.Variable(np.arange(15 * 16).reshape(15, 16), dtype=tf.float32)
#If you want to assign a sok.Variable to a specific GPU, add the parameter mode=“localized:gpu_id” when defining sok.variable, where gpu_id refers to the rank number of a GPU in Horovod
v2 = sok.Variable(np.arange(15 * 16).reshape(15, 16), dtype=tf.float32,mode="localized:0")v1 的申請中,SOK 會自動將 v1 的數據均勻儲存到訓練域中每一個 GPU 上,v2 的申請中,在參數中添加了mode=”localized:0″這個字符串參數,SOK 會將 v2 的數據放置在 GPU0 中。
SOK 中提供了 Variable 和 DynamicVariable 兩種不同的形式儲存 embedding table。Variable 可以簡稱為 static embedding table,一個是靜態的二維數據,在申請時需要確定 embedding table 的 shape,申請結束后,SOK 會相應申請好數據使用的空間(如果 static embedding table 分布在所有 GPU 上,那么所有 GPU 平分這個空間)。因為 static embedding table 是一個靜態的二維數組,這也意味著 lookup 時查找的 indice,是無法超出這個二維數組第一個 dimension 的長度的,否則會發生越界問題。
Static embedding table, 對于 lookup indice 存在范圍限制,很多用戶輸入的 lookup indice 又是 hash 過的 key,所以 SOK 提出 DynamicVariable 來解決 lookup indice 范圍限制的問題。 SOK 的 DynamicVariable 是使用 hash table 來儲存 embedding table 的,解決了這個問題。
SOK 的 DynamicVariable 封裝了 2 個基于 GPU 的 hash table(HierarchicalKV 和 Dynamic Embedding Table), 其中 HierarchicalKV(以下簡稱 HKV)是 NVIDIAMerlin 框架下的 hash table repo,它有以下 2 個特性:
- HKV 可以利用 GPU memory 和 Host memory 儲存 embedding table 中的 embedding vector,充分利用訓練中的內存資源;
- HKV 的 hash table 擁有 eviction 功能,hash table 滿了后不會繼續增長,繼續 insert? 會淘汰掉最不常用的key/value,提供 LRU、LFU 等常用淘汰策略,也可以自定義淘汰策略。
HKV 的 repo 地址為 HKV repo,提供了 C++ level 的 hash table API,也為推薦系統提供了組合 API,方便推薦系統用戶使用。SOK 中申請 HKV embedding table 的代碼如下:
?#init_capacity and max_capacity are parameters accepted by the HKV table. The meanings of these parameters can be found in the HKV documentation.
v2 = sok.DynamicVariable(
dimension=16, # embedding vector length
var_type="hybrid", # use HKV backend
initializer="uniform", # use uniform distribution random initializer
init_capacity=1024 * 1024, # The number of embedding vectors allocated initially in the hash table
max_capacity=1024 * 1024, # The number of embedding vectors allocated finally in the hash table
max_hbm_for_vectors=2, # how many GPU memory should this hash table use , unit is GB
)從上面代碼可見,SOK 申請 HKV hash table 時,需要設置一些參數,這些參數如何設置可以閱讀 SOK 和 HKV 的文檔(SOK documentation, HKV documentation)。
SOK 的 Variable 和 DynamicVariable 均繼承自 Tensorflow 的 ResourceVariable,除了 SOK 的自己定義的參數外,讀者和用戶可以按照使用 ResourceVariable 的習慣添加 ResourceVariable 的參數。
Embedding Lookup
SOK embedding lookup_sparse 提供與 tf.nn.embedding_lookup_sparse 相似的 API,與tf.nn.embedding_lookup_sparse 不同的是,SOK 的 embedding lookup_sparse 可以同時將多個 lookup fuse 到一起,代碼如下:
# Use SOK embedding lookup sparse to do 2 embedding lookups
emb1, emb2 = sok.lookup_sparse([sok_var1, sok_var2],[keys1, keys2],combiners=["sum", "mean"])
# equals to
emb1 = tf.nn.embedding_lookup_sparse(v1, indices1, combiner="sum")
emb2 = tf.nn.embedding_lookup_sparse(v2, indices2, combiner="mean")Embedding Table Dump/Load
SOK 關于embedding table 的權重提供了 dump/load 和增量導出 incremental dump 的功能。
dump/load 可以自動并行的進行 embedding table 的 key,value,optimizer 中狀態變量(可選)在文件系統中的讀寫,將 embedding table 的 key、value、optimizer 中的狀態變量儲存成二進制文件/從二進制文件中讀取,下面是 SOK 中 dump/load 的例子:
#optimizer states are optional. If they are unspecified in calling the APIs above, only the keys and values are loaded.
optimizer = tf.keras.optimizers.SGD(learning_rate=1.0)
sok_optimizer = sok.OptimizerWrapper(optimizer)
path = "./weights"
sok_vars = [sok_var1,sok_var2]
sok.dump(path, sok_vars, sok_optimizer)
sok.load(path, sok_vars, sok_optimizer)
在大部分推薦系統業務中,embedding table 的內存占用非常大,因此,在continued training中,用戶通常會將訓練一段時間后更新了的 key 和 value 推送到推理端,這樣可以避免推送整個 embedding table 產生的巨大開銷,SOK 同樣提供了 incremental_dump 的 API 來實現這個功能。incremental_dump 接受一個 UTC time threshold,可以將 time threshold 后更新的 key/value 導出到 numpy array 中:
?# sok incremental dump
import pytz
from datetime import datetime
#should convert datatime to utc time
utc_time_threshold = datetime.now(pytz.utc)
sok_vars = [sok_var1,sok_var2]
#keys and values are Numpy array
keys, values = sok.incremental_model_dump(sok_vars, utc_time_threshold)SOK 與 TensorFlow 的兼容性
SOK 目前兼容 TF2 的靜態圖,但是不支持 TensorFlow 的 XLA,如果開啟 TensorFlow 的 XLA,需要手動將 SOK 的 lookup 的 layer 排除在外,偽代碼如下所示:
?@tf.function
def sok_layer(inputs):
return sok.lookup_sparse(inputs)
@tf.function(jit_compile=True)
def xla_layer(inputs):
x = xla_layer(inputs)
return xSOK Example Notebook
讀者和用戶可以閱讀下面的 example notebook 來了解 SOK 如何進行端到端訓練 example:
SOK train DLRM demo
可以閱讀下面的 example notebook來了解如何在 SOK 完成訓練后使用 HugeCTR HPS 框架進行推理:
HPS inference DLRM with SOK weights demo
應用案例分享
以下是近期 NVIDIA 技術團隊開展的部分手機行業推薦場景高性能優化項目實踐經驗分享:
案例 1:通過 NVIDIA Merlin HugeCTR SOK 以及 NVTabular 實現了GPU 加速的推薦系統
- 應用背景:
- 客戶的推薦系統是針對客戶手機端的廣告和內容,該推薦系統之前是使用 CPU PS架構運行,客戶希望使用 GPU 架構來進行加速。
- 應用方案/效果以及影響:
- 通過 HugeCTR Sparse Operation Kit + NVTabular 實現了 GPU 加速的推薦系統,性能加速如下:
- 實驗性能對比:
- SOK 將原有只能單 GPU 訓練的任務擴展到多 GPU 訓練,并且達到了很好的弱擴展性,支持更大的模型。SOK+tfrecord 3GPU 耗時約 1.3 個小時 vs TF+tfrecord 1GPU 耗時約 3.4 個小時。
- 實驗性能對比:
- 業務性能對比:
- 由于業務系統輸入數據較大,因此客戶采取 parquet 數據格式進行 input 數據壓縮,業務性能提升如下,NVTabular load Parquet 耗時約1.8 個小時 vs TF load Parquet 耗時約 7.8 個小時。
- 在 SOK 加速的基礎上,NVTabular Parguet datareader 進一步解決了數據讀取瓶頸的問題,在實際務測試中,相比原生 TensorFlow Parquet datareader 達到了 400% 的速度提升。
- 通過 HugeCTR Sparse Operation Kit + NVTabular 實現了 GPU 加速的推薦系統,性能加速如下:
案例 2:通過 NVIDIA Merlin HugeCTR SOK 實現了 GPU 加速的推薦系統
- 應用背景:
- 客戶的推薦系統是針對客戶手機端的廣告和內容,該推薦系統使用 CPU+PS 和 GPU+PS 的架構運行。
- 應用方案/效果以及影響:
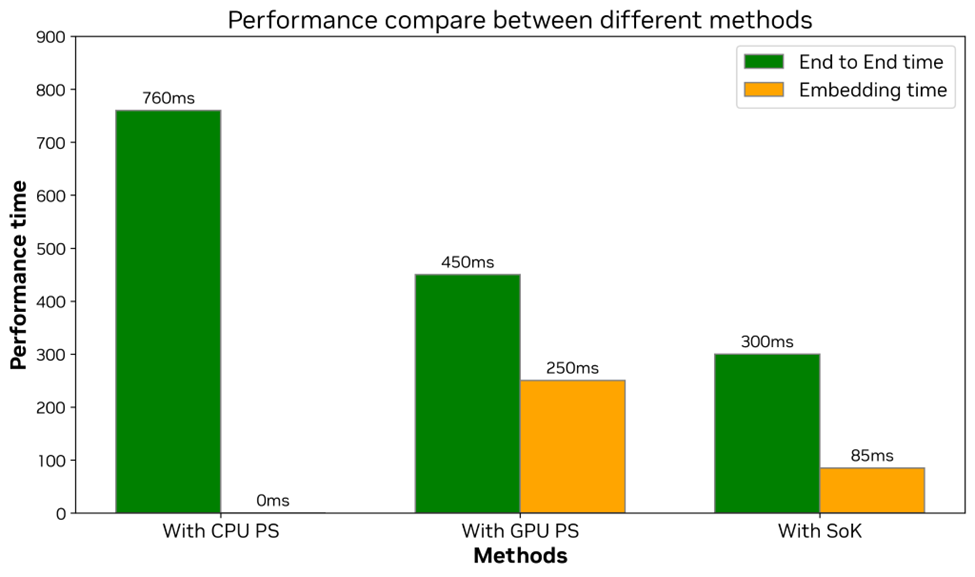
- 通過 HugeCTR Sparse Operation Kit 進行了 GPU 加速的推薦系統的實驗,性能加速如下:
- End to End 時間從 CPU+PS 的 760 毫秒優化至 300 毫秒,性能提升約 60%。GPU+PS 的 450 毫秒優化至 300 毫秒,性能提升約 33%。
- GPU+PS 架構的 embedding 部分耗時為 250 毫秒,SOK 的 embedding 部分耗時為 85 毫秒,性能提升 67%。
結束語
SOK v2.0 通過封裝 HKV 和 HugeCTR 的底層代碼提供了模型并行,且功能完善的動態 Embedding table 和高效的相關計算。在多個業內實際使用場景中,從速度效率、模型擴展、功能完善等角度,使用戶獲得了不錯的收益。
本博客的讀者可以參考 SOK 的官方文檔獲取更多內容:SOK Documentation。此外,您也可以查看 HugeCTR 的 Github repo 以及其他相關的文章,也歡迎更多朋友們的閱讀和反饋。 (更多文章詳見 HugeCTR README)