當涉及到智能視頻分析(IVA)應用程序(如交通監控、倉庫安全和零售購物者分析)的感知時,最大的挑戰之一是閉塞。例如,人們可能會移動到結構障礙物后面,零售購物者可能由于貨架單元而無法完全看到,汽車可能會隱藏在大型卡車后面。
本文將解釋如何利用 NVIDIA DeepStream SDK 解決現實生活中 IVA 部署中常見的視覺感知遮擋問題。
視覺感知中的視角和投影?
在我們的物理世界中,通過相機鏡頭觀察到的一些物體的運動可能看起來不穩定。這是由于相機對 3D 世界的 2D 表示。
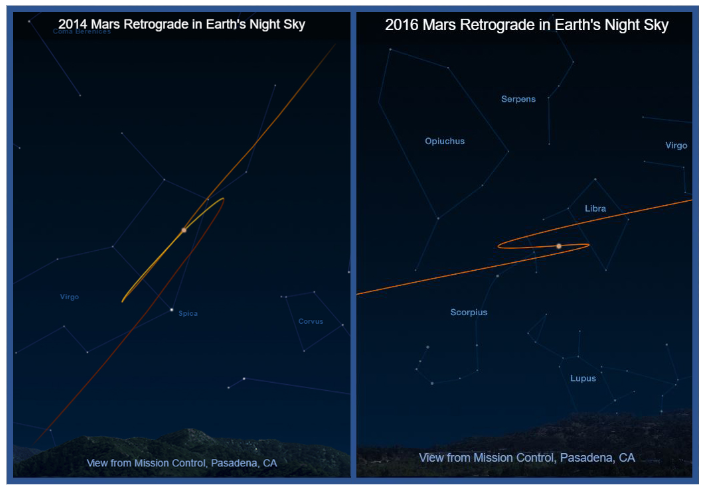
水星和火星等行星的逆行就是一個例子,這讓古希臘天文學家感到困惑。他們無法解釋為什么行星有時會向后移動(圖 1)。
所感知到的明顯退行是由于恒星和行星在夜空中的軌跡造成的。這些是宇宙三維空間中軌道運動在夜空二維畫布上的投影。如果古代天文學家知道三維空間的運動模式,他們就可以預測這些行星在二維夜空中的出現。
交通監控攝像頭提供了類似的例子。這些攝像頭通常用于監測大面積區域,其中車輛在近場和遠場的運動動力學可能截然不同。
在視頻 1 中,遠處的車輛顯得又小又慢。當車輛靠近攝像頭并轉彎時,可以觀察到物體運動的突然變化。這些變化使得難以在 2D 攝像機視圖中找到常見模式,因此難以預測車輛未來可能移動的位置。
物體跟蹤本質上是對物體物理狀態的連續估計,同時隨著時間的推移識別其獨特身份。該過程通常包括對物體運動動力學建模,并進行預測以抑制測量(檢測)中的固有噪聲。給定所提供的示例,很明顯,直接在原生 3D 空間中執行對象的狀態估計和預測將產生比在投影的 2D 相機圖像平面中執行更好的結果。這是因為對象存在于三維空間中。
使用 NVIDIA DeepStream 進行單視圖 3D 跟蹤?
NVIDIA DeepStream SDK 是一個基于 GStreamer 的完整流媒體分析工具包,旨在實現基于人工智能的多傳感器處理、視頻、音頻和圖像理解。最近,DeepStream 6.4 版本 引入了一種名為單視圖 3D 跟蹤(SV3DT)的新功能,該功能能夠在單相機視圖內估計 3D 物理世界中的對象狀態。
該過程包括使用每個相機的 3×4 投影矩陣或相機矩陣將 2D 相機圖像平面上的觀測測量轉換為 3D 世界坐標系。對象在三維世界地平面中的位置表示為對象底部的中心。因此,行人被建模為一個圓柱體(具有高度和半徑),站在世界地平面上,圓柱體模型底部的中心作為行人的腳部位置(圖 2)。

使用 3×4 投影矩陣和圓柱形人體模型,估計檢測到的物體的 3D 人體模型在 3D 世界地平面上的位置,從而使 2D 相機圖像平面上的投影 3D 人體模型與檢測到的對象的邊界框最佳匹配。
例如,在圖 3(左)中,灰色邊界框表示對象檢測器使用 NVIDIA TAO PeopleNet 模型檢測到的對象。紫色和黃色圓柱體指示從 3D 世界地平面上的估計位置投影到 2D 相機圖像平面的對應 3D 人體模型。投影的 3D 人體模型底部的綠點指示估計的腳部位置。盡管攝影機視圖具有透視和旋轉,但這些位置與實際腳部位置非常匹配。

新引入的 DeepStream SV3DT 功能的一個重要優點是,即使存在顯著的差異,也可以準確地找到物體的 2D 和 3D 腳部位置,即使在部分閉塞的情況下。這是現實世界 IVA 應用中最具挑戰性的問題之一。欲了解更多詳細信息,請參閱我們之前的帖子:采用 NVIDIA DeepStream SDK 6.2 的最先進實時多對象跟蹤器。
例如,圖 3(右)顯示了一個人在狹窄的過道里購物,相機只能看到上半身的一小部分。這將導致更小的對象邊界框,僅捕獲頭部和肩部區域。對于這種情況,在全球商店地圖上定位此人極具挑戰性,因為至少可以說,估計腳部位置是一項不平凡的任務。
使用邊界框的底部中心作為對象位置的代理將在軌跡估計中引入很大程度的誤差。即使使用相機校準信息將 2D 點轉換為 3D 點,尤其是當相機視角和旋轉較大時,也是如此。
DeepStream SDK 中的多對象跟蹤器模塊中的 SV3DT 算法通過在假設相機安裝在頭部上方的情況下利用 3D 人體建模信息來解決這個問題。這通常是部署在智能空間中的大多數大型相機網絡系統的情況。有了這個假設,在估計相應的 3D 人體模型位置時,可以使用頭部作為錨點。圖 3 顯示,即使在人被嚴重遮擋的情況下,SV3DT 算法也可以成功地找到匹配的三維人體模型位置。
視頻 2 顯示人們在便利店被跟蹤。請注意,使用的 3×4 投影矩陣沒有考慮鏡頭失真,盡管特定相機有一定程度的鏡頭失真,因為你可以看到水平線有點彎曲而不直。這導致 3D 人體模型位置估計更加不準確,尤其是當人位于視頻幀的邊緣時。
盡管如此,人們在便利店的 2D 和 3D 腳部位置(用綠點表示)被準確而穩健地跟蹤。這增強了額外分析的準確性,如隊列長度監控和占用圖等。
圖 4 顯示了如何在合成數據集中穩健地跟蹤每個行人的腳部位置,即使下半身的大部分被貨架等大型物體遮擋。
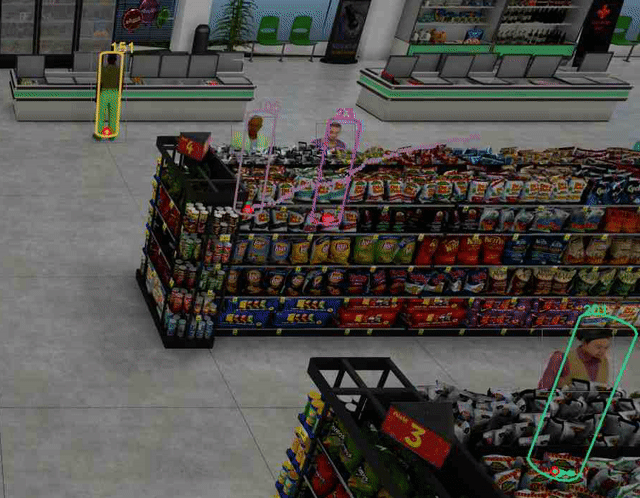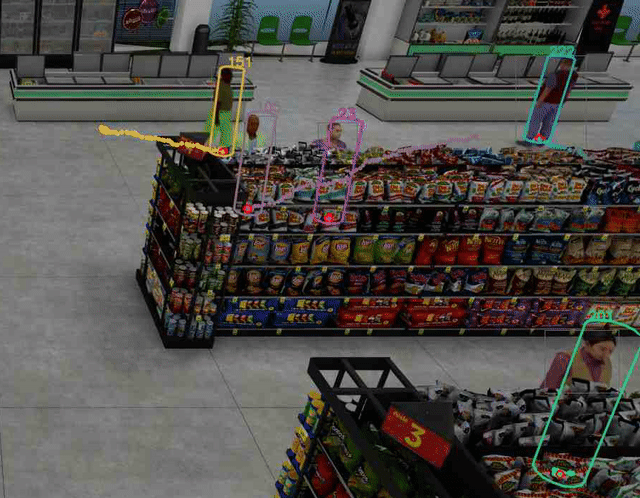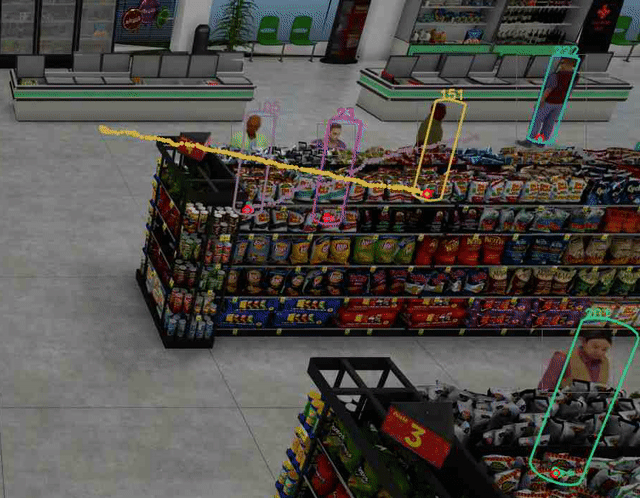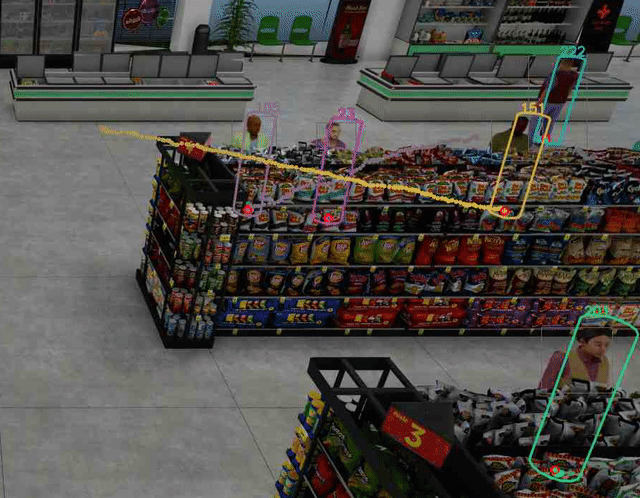
我們相信,解決部分遮擋問題將在現實應用中開辟許多可能性。SV3DT 目前處于阿爾法模式,因為其對象類型支持有限(僅限站立的人)。其他情況,如人們坐著和躺著,或其他對象類型可能在未來的版本中得到支持。您可以針對您的特定用例進行嘗試,并在 DeepStream 論壇 中提供反饋。我們計劃在未來版本中進行進一步改進。
DeepStream SV3DT 用例?
一個示例 DeepStream SV3DT 用例演示了如何在本文中介紹的零售商商店視頻上啟用單視圖 3D 跟蹤,并從管道中保存 3D 元數據。用戶可以從圖 4 和視頻 2 所示的數據中可視化凸起的船體和腳部位置。該自述還描述了如何在自定義視頻上運行此算法。欲了解更多詳細信息,請訪問 NVIDIA-AI-IOT/deepstream_reference_apps,或參閱 DeepStream 文檔。
總結?
NVIDIA DeepStream SDK 中的單視圖 3D 跟蹤有助于緩解現實生活中 IVA 應用程序和部署中的部分遮擋問題。該功能在 6.4 版本中首次引入,并在 7.0 版本中進行了增強。具體而言,SV3DT 能夠在局部遮擋的情況下估計腳部位置,并且能夠進行更穩健和準確的對象跟蹤,這將隨后導致在 3D 地平面中的準確定位。依賴或利用地理空間分析的企業預計將從這項技術中受益最大。
要開始,請先查看?DeepStream SDK 發布?的最新消息,然后在充滿挑戰的環境中嘗試。
?