多語言 自動語音識別?( ASR )模型因其能夠以多種語言轉錄語音而獲得了極大的興趣。這是由不斷增長的多語言社區以及減少復雜性的需求所推動的。您只需要一個模型來處理多種語言。
這篇文章解釋了如何使用 NGC 目錄中的 預訓練多語言 NeMo ASR 模型?。我們還分享了創建自己的多語言數據集和訓練自己的模型的最佳實踐。
多語言 ASR 模型的工作原理
ASR 模型在高級別上將語音轉換為文本。在推斷時,它們使用音頻文件作為輸入,并生成文本標記或字符作為輸出(圖 1 )。更準確地說,在每個音頻采樣時間步,該模型輸出總共num_classes 標記中每一個的對數概率。
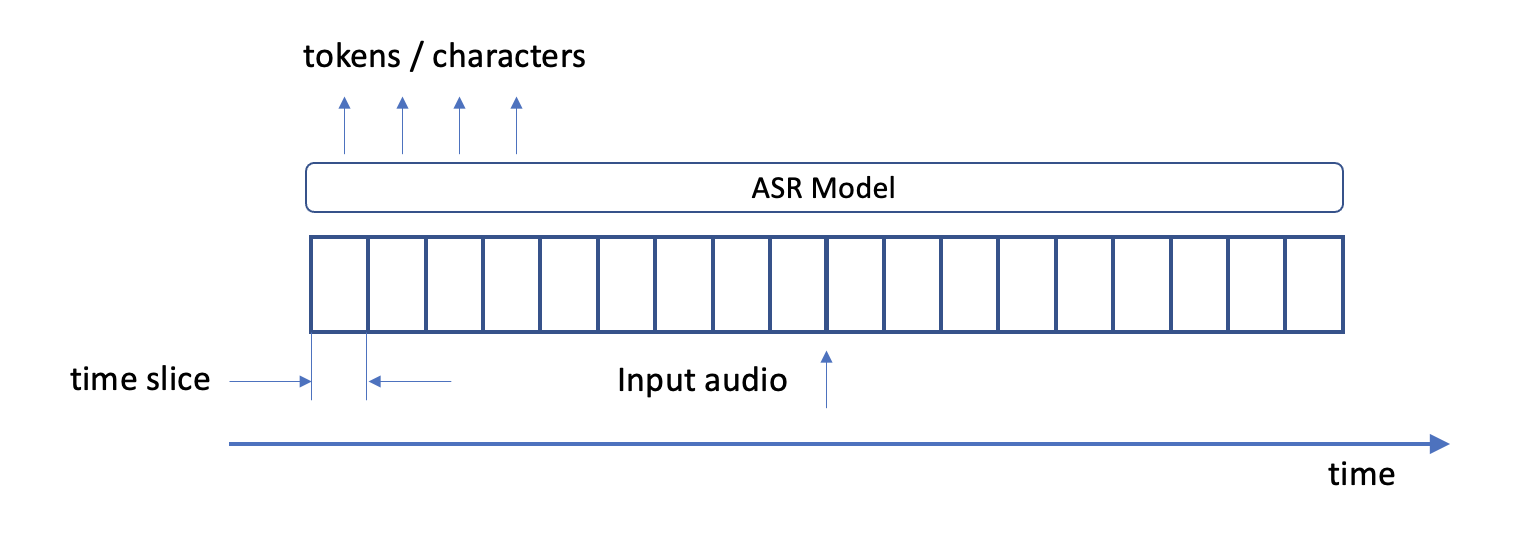
在培訓時,您提供文本記錄以及音頻文件作為輸入。當模型訓練時,它使用成績單來計算訓練損失。它逐漸減少了這種損失,并提高了其權重,使其輸出成績單盡可能接近原始。
多語言環境為這幅圖增添了幾個方面。在推斷過程中,您通常不知道音頻中包含的語言。但是,如果模型知道在音頻中遇到的語言 ID ( LID ),則輸出它可能很有用。
這可以用于將 ASR 模型下游的特定于語言的處理管道組合在一起。同樣,您可能需要在培訓期間提供每個樣本中的 LID 值。
代碼轉換指的是在對話過程中不同語言之間的轉換。這種模型必須預測每個樣本可能包含多個 LID 值,并需要相應地進行訓練。
更深的潛水
創建多語言模型有兩種基本方法。
在第一種方法中,您可以在很大程度上忽略數據集中存在多種語言這一事實,并按原樣對轉錄本進行排序,讓模型來解決所有問題。如果模型使用文本標記化,則只需確保標記化器詞匯表的大小足以覆蓋所有語言。你將不同語言的成績單結合起來,訓練標記器。
在第二種方法中,您使用適當的 LID 標記轉錄本中的每個文本樣本。如果模型使用標記器,您可以在每種語言上單獨訓練它們,然后使用 NeMo 聚合標記器功能來組合它們。
每種語言都獲得一個指定的令牌 ID 范圍,模型學習生成它們。在解碼過程中,要確定特定令牌的 LID ,請查看其 ID 范圍(圖 2 )。

在培訓期間,您使用適當的單語標記器標記輸入文本。然后移動令牌 ID 以確保沒有重疊,每種語言都有自己的數字范圍(圖 3 )。
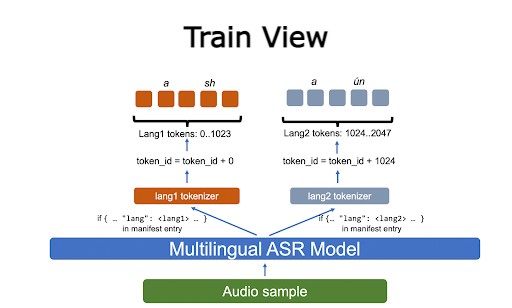
除了數據集準備之外,代碼切換并不構成挑戰。根據我們的經驗,為了擅長代碼轉換,模型必須專門針對由多種語言組成的樣本進行訓練。我們將在后續章節中返回到這個主題。
NeMo 多語言 ASR 模型的推理
預訓練的多語言 NeMo 模型可以以與單語模型幾乎相同的方式使用。首先從 NGC 初始化一個預訓練的檢查點。
該模型具有enes前綴,表示它接受了兩種語言的訓練:
asr_model = nemo_asr.models.EncDecRNNTBPEModel.from_pretrained(model_name="stt_enes_contextnet_large")
編譯輸入音頻文件列表:
en_files = ["./datasets/mini/LibriSpeech/dev-clean-2-processed/7976-110523-0000.wav", "./datasets/mini/LibriSpeech/dev-clean-2-processed/7976-110523-0001.wav"]
轉錄它們:
transcripts = asr_model.transcribe(paths2audio_files = en_files) [0]
要輸出 LID ,對模型的解碼策略做一個小改動:
decoding_cfg = OmegaConf.create({})
with open_dict(decoding_cfg):
decoding_cfg.compute_langs = True
asr_model.change_decoding_strategy(decoding_cfg)
現在可以執行推斷:
hyp, _ = asr_model.transcribe(paths2audio_files = es_files, return_hypotheses=True)
Hyp[0].langs變量包含批次(es) c中樣本0的 LID 的最佳估計值。hyp[0].langs_chars變量包含以下各項的 LID :
[{'char': 'a', 'lang': 'es'}]
代碼交換檢查點的工作方式相同。它們在 NGC 模型檢查點名稱中用codesw字符串標記。有關詳細信息,請參見 Multilingual ASR models with Subword Tokenization in NeMo 。
如何培養多語言模型?
正如我們已經提到的,構建多語言模型的最簡單方法是直接混合單語數據集,并在混合數據集上訓練模型。這種方法不保留 LID 信息,但它工作得很好,產生了高度精確的模型。
如果需要代碼切換功能,理想的場景將涉及使用真正的代碼切換訓練集。如果沒有,則創建一個合成的(圖 4 )。
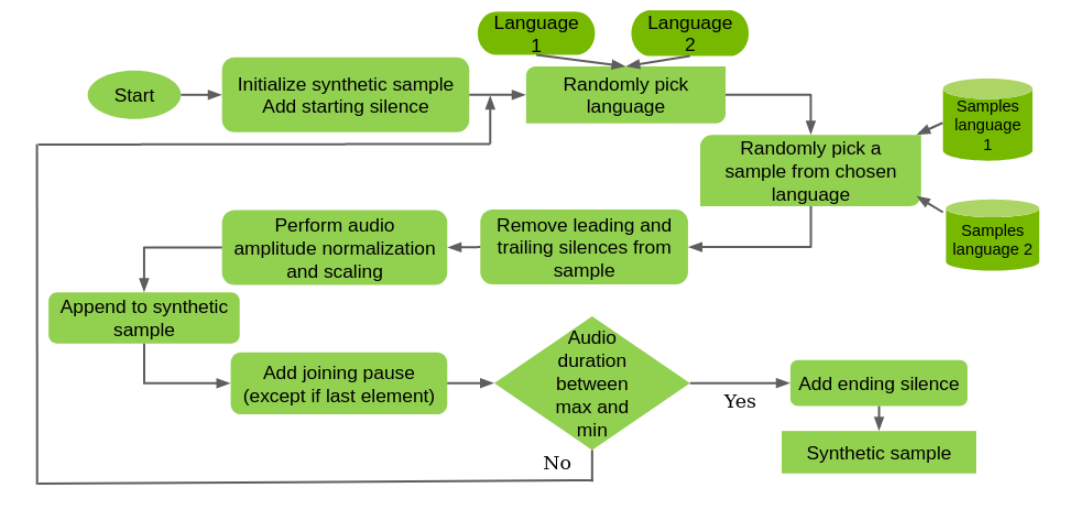
在本例中,您隨機組合來自不同語言的單語樣本,調整靜音,按音量標準化音頻,并引入隨機暫停。您只需不超過合成樣本的特定最大音頻長度,通常設置為 20 秒。
這也不是完美的,因為樣本之間的上下文丟失了。但是,模型可以在樣本中的語言之間切換。
如果保留 LID 很重要,可以使用 NeMo 清單中的樣本寬 lang 字段:
{"audio_filepath": "data1.wav", "duration": 7.04, "text": "by the time we had placed the cold fresh-smelling little tree in a corner of the sitting room it was already Christmas eve", "lang": "en"}
代碼切換數據集每個樣本有多個 LID ,因此您也可以使用以下代碼:
{"audio_filepath": "/data2.wav", "duration": 17.32425, "text": [{"lang": "en", "str": "the mentality is that of a slave-owning community with a mutilated multitude of men tied to its commercial and political treadmill "}, {"lang": "es", "str": "y este "}]}
接下來,使用由單語標記器組成的聚合標記器訓練模型。在模型配置文件中,它看起來像以下代碼示例:
tokenizer:
type:agg
langs:
en:
type: bpe
dir: english_tokenizer_dir
es:
type: bpe
dir: spanish_tokenizer_dir
在本例中,我們使用了英語(LID en)和西班牙語(LID es)。預訓練的標記器被放置在它們各自的目錄中,我們引用了這些目錄。
關于模型訓練的幾點注意事項:
- 理想情況下,在創建柏油或桶狀數據集之前,數據集必須充分混合。
- 數據集必須平衡。例如,它們在每種語言中應該包含大約相同的小時數。如果其中一個單語數據集明顯大于另一個,那么對較小的數據集進行過采樣可能是一個好主意,以防止模型優先學習較大的語言。
- 可以從單語檢查點之一開始訓練模型。這通常會加快收斂速度。然而,在這種情況下,對增量語言進行過采樣是一個好主意。
總結
在這篇文章中,我們介紹了多語言 NeMo ASR 模型的使用:
- 如何使用它們進行推斷
- 如何訓練他們
- 常見的多語言模型和代碼轉換模型之間的區別
- 如何保存和輸出 LID 信息
我們正在努力為我們的模型添加更多的語言,并將很快分享這些結果。
本文中引用的所有代碼都可以在 NeMo GitHub repo 中公開獲得,模型可以在 NGC 中獲得:
- English – Spanish Code-switched Transformer Large
- English – Spanish Code-switched CTC Large
- English – Spanish Multilingual Transformer Large
- English – Spanish Multilingual CTC Large
- English – Spanish Multilingual ContextNet Large
?






